 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Effective Shortcut Technique for GAN
Jan 27, 2022
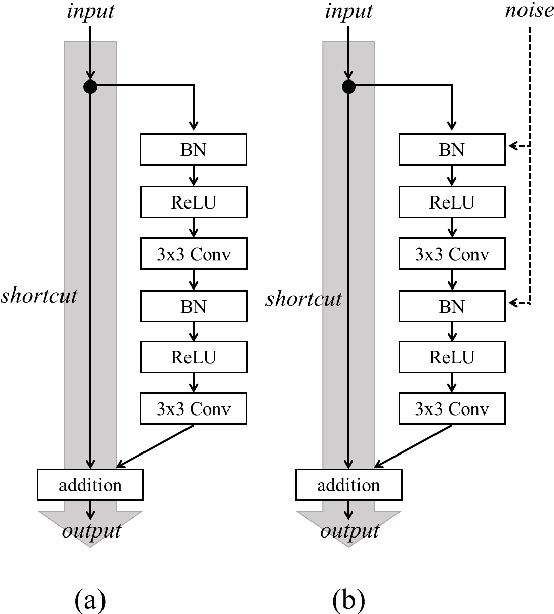
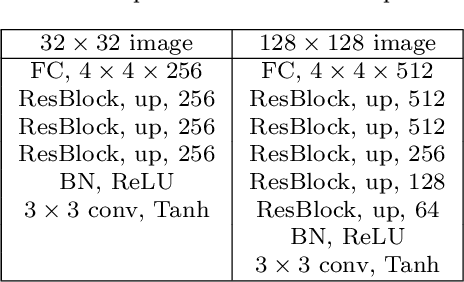
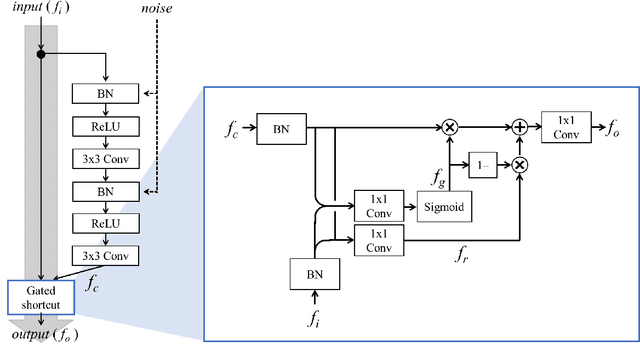
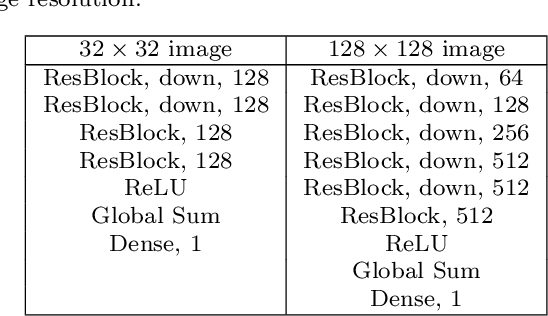
In recent years, generative adversarial network (GAN)-based image generation techniques design their generators by stacking up multiple residual blocks. The residual block generally contains a shortcut, \ie skip connection, which effectively supports information propagation in the network. In this paper, we propose a novel shortcut method, called the gated shortcut, which not only embraces the strength point of the residual block but also further boosts the GAN performance. More specifically, based on the gating mechanism, the proposed method leads the residual block to keep (or remove) information that is relevant (or irrelevant) to the image being generated. To demonstrate that the proposed method brings significant improvements in the GAN performance, this paper provides extensive experimental results on the various standard datasets such as CIFAR-10, CIFAR-100, LSUN, and tiny-ImageNet. Quantitative evaluations show that the gated shortcut achieves the impressive GAN performance in terms of Frechet inception distance (FID) and Inception score (IS). For instance, the proposed method improves the FID and IS scores on the tiny-ImageNet dataset from 35.13 to 27.90 and 20.23 to 23.42, respectively.
The Spectral Bias of Polynomial Neural Networks
Feb 27, 2022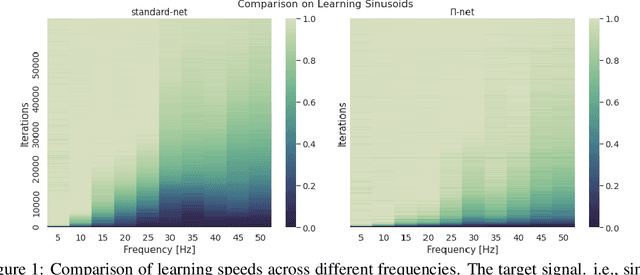
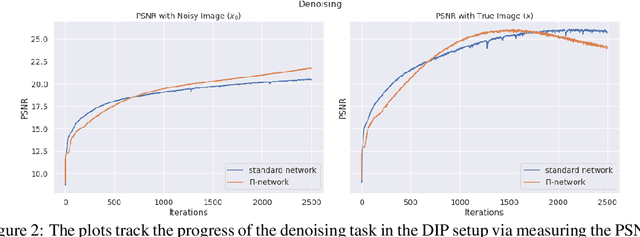
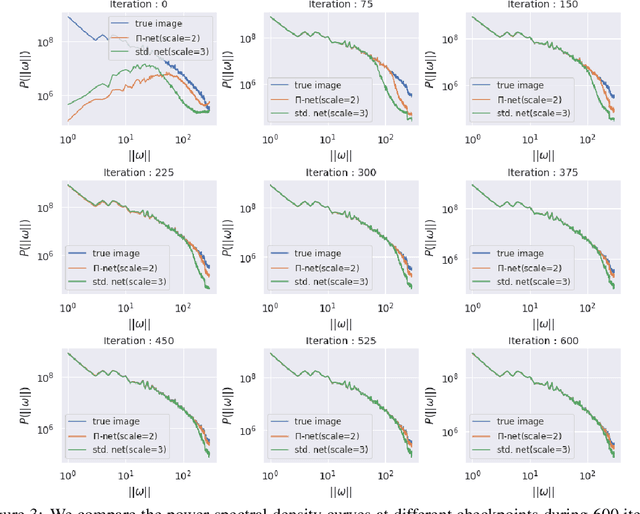
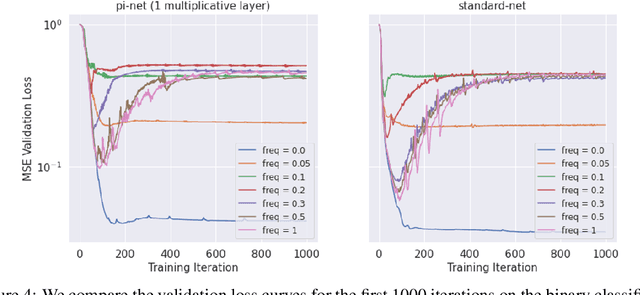
Polynomial neural networks (PNNs) have been recently shown to be particularly effective at image generation and face recognition, where high-frequency information is critical. Previous studies have revealed that neural networks demonstrate a $\textit{spectral bias}$ towards low-frequency functions, which yields faster learning of low-frequency components during training. Inspired by such studies, we conduct a spectral analysis of the Neural Tangent Kernel (NTK) of PNNs. We find that the $\Pi$-Net family, i.e., a recently proposed parametrization of PNNs, speeds up the learning of the higher frequencies. We verify the theoretical bias through extensive experiments. We expect our analysis to provide novel insights into designing architectures and learning frameworks by incorporating multiplicative interactions via polynomials.
A Comprehensive Study of Vision Transformers on Dense Prediction Tasks
Jan 21, 2022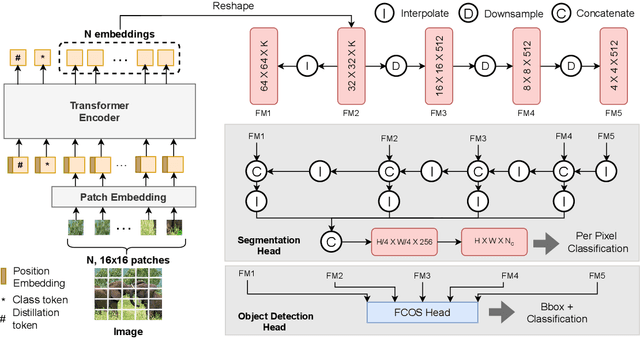
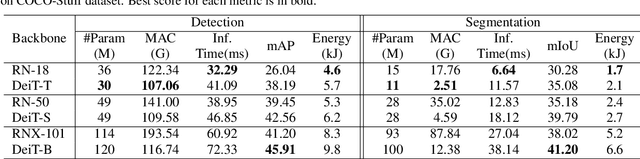
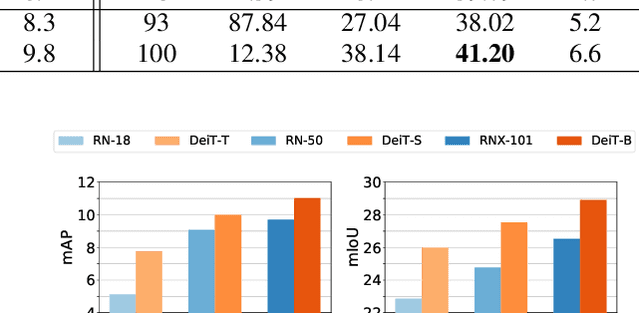
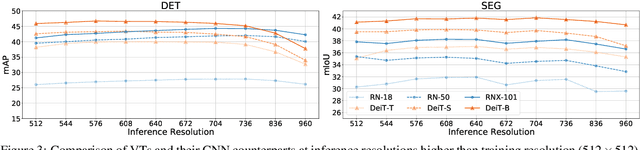
Convolutional Neural Networks (CNNs), architectures consisting of convolutional layers, have been the standard choice in vision tasks. Recent studies have shown that Vision Transformers (VTs), architectures based on self-attention modules, achieve comparable performance in challenging tasks such as object detection and semantic segmentation. However, the image processing mechanism of VTs is different from that of conventional CNNs. This poses several questions about their generalizability, robustness, reliability, and texture bias when used to extract features for complex tasks. To address these questions, we study and compare VT and CNN architectures as feature extractors in object detection and semantic segmentation. Our extensive empirical results show that the features generated by VTs are more robust to distribution shifts, natural corruptions, and adversarial attacks in both tasks, whereas CNNs perform better at higher image resolutions in object detection. Furthermore, our results demonstrate that VTs in dense prediction tasks produce more reliable and less texture-biased predictions.
SATA: Sparsity-Aware Training Accelerator for Spiking Neural Networks
Apr 11, 2022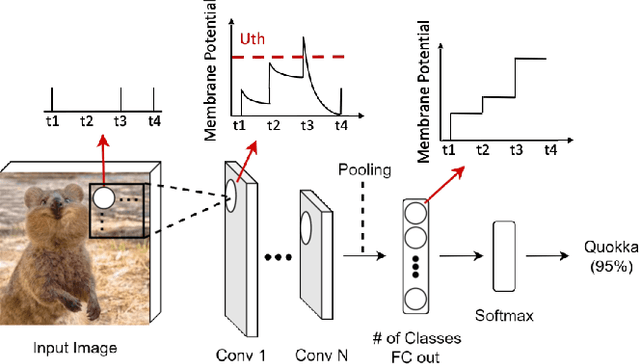
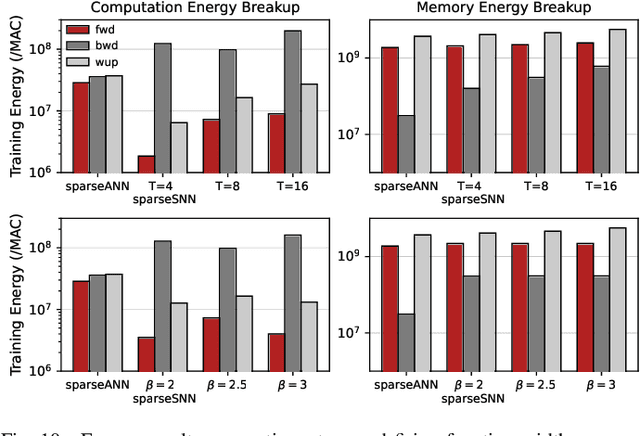
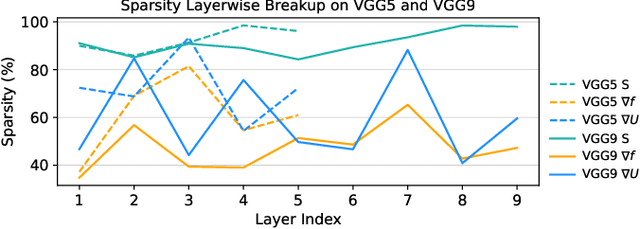
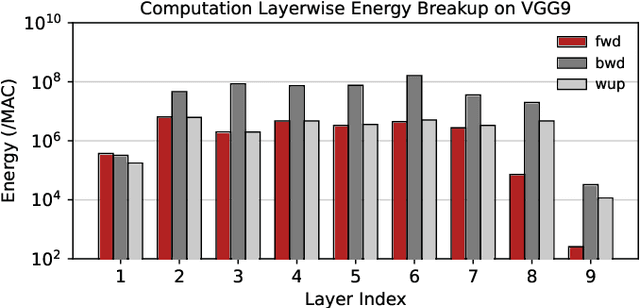
Spiking Neural Networks (SNNs) have gained huge attention as a potential energy-efficient alternative to conventional Artificial Neural Networks (ANNs) due to their inherent high-sparsity activation. Recently, SNNs with backpropagation through time (BPTT) have achieved a higher accuracy result on image recognition tasks compared to other SNN training algorithms. Despite the success on the algorithm perspective, prior works neglect the evaluation of the hardware energy overheads of BPTT, due to the lack of a hardware evaluation platform for SNN training algorithm design. Moreover, although SNNs have been long seen as an energy-efficient counterpart of ANNs, a quantitative comparison between the training cost of SNNs and ANNs is missing. To address the above-mentioned issues, in this work, we introduce SATA (Sparsity-Aware Training Accelerator), a BPTT-based training accelerator for SNNs. The proposed SATA provides a simple and re-configurable accelerator architecture for the general-purpose hardware evaluation platform, which makes it easier to analyze the training energy for SNN training algorithms. Based on SATA, we show quantitative analyses on the energy efficiency of SNN training and make a comparison between the training cost of SNNs and ANNs. The results show that SNNs consume $1.27\times$ more total energy with considering sparsity (spikes, gradient of firing function, and gradient of membrane potential) when compared to ANNs. We find that such high training energy cost is from time-repetitive convolution operations and data movements during backpropagation. Moreover, to guide the future SNN training algorithm design, we provide several observations on energy efficiency with respect to different SNN-specific training parameters.
Learning Omni-frequency Region-adaptive Representations for Real Image Super-Resolution
Dec 11, 2020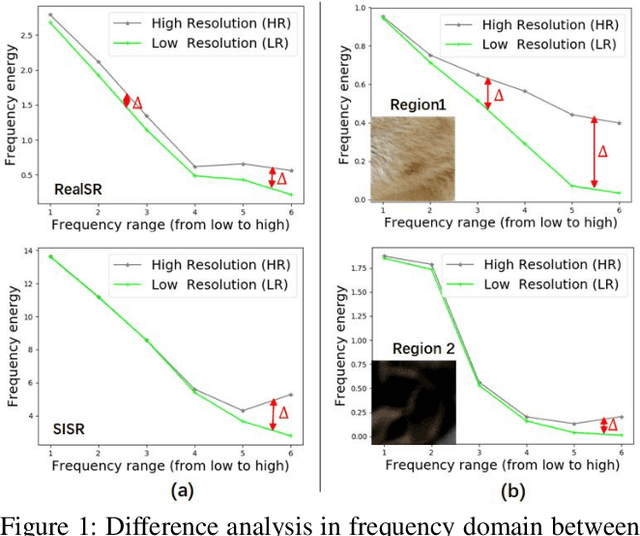
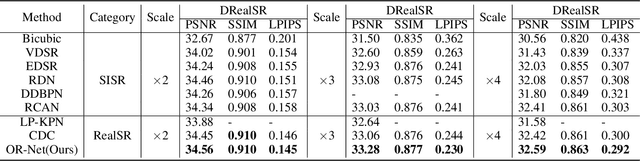
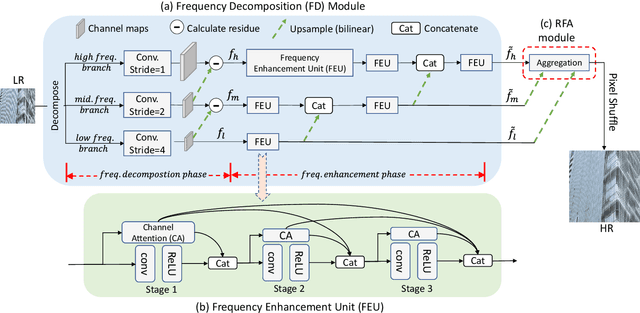
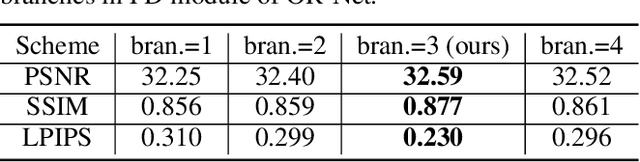
Traditional single image super-resolution (SISR) methods that focus on solving single and uniform degradation (i.e., bicubic down-sampling), typically suffer from poor performance when applied into real-world low-resolution (LR) images due to the complicated realistic degradations. The key to solving this more challenging real image super-resolution (RealSR) problem lies in learning feature representations that are both informative and content-aware. In this paper, we propose an Omni-frequency Region-adaptive Network (ORNet) to address both challenges, here we call features of all low, middle and high frequencies omni-frequency features. Specifically, we start from the frequency perspective and design a Frequency Decomposition (FD) module to separate different frequency components to comprehensively compensate the information lost for real LR image. Then, considering the different regions of real LR image have different frequency information lost, we further design a Region-adaptive Frequency Aggregation (RFA) module by leveraging dynamic convolution and spatial attention to adaptively restore frequency components for different regions. The extensive experiments endorse the effective, and scenario-agnostic nature of our OR-Net for RealSR.
BEVT: BERT Pretraining of Video Transformers
Dec 02, 2021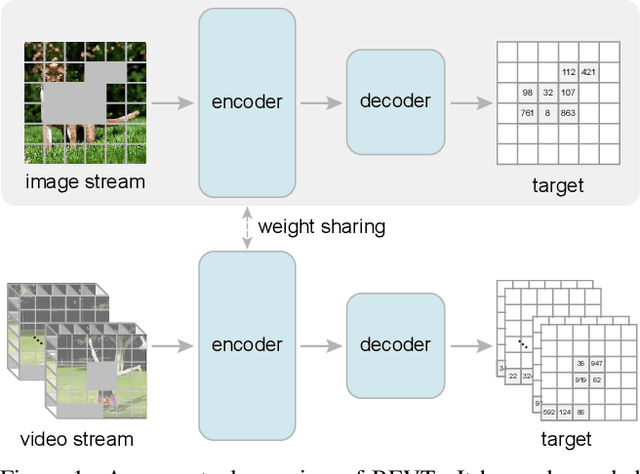
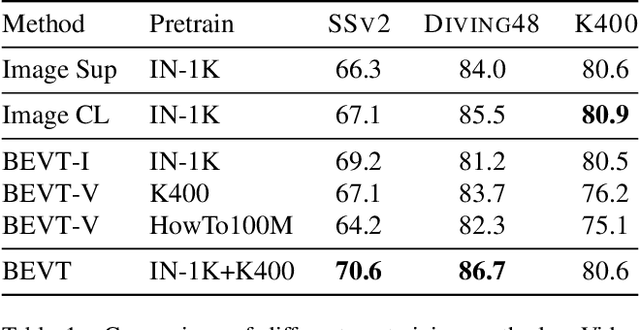
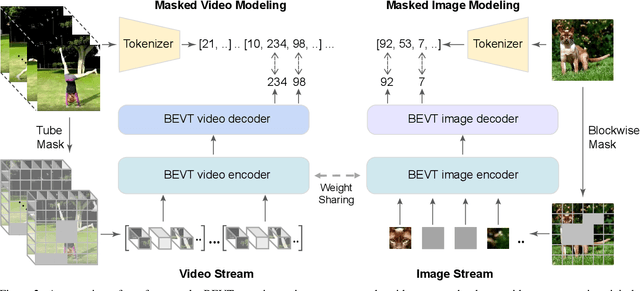

This paper studies the BERT pretraining of video transformers. It is a straightforward but worth-studying extension given the recent success from BERT pretraining of image transformers. We introduce BEVT which decouples video representation learning into spatial representation learning and temporal dynamics learning. In particular, BEVT first performs masked image modeling on image data, and then conducts masked image modeling jointly with masked video modeling on video data. This design is motivated by two observations: 1) transformers learned on image datasets provide decent spatial priors that can ease the learning of video transformers, which are often times computationally-intensive if trained from scratch; 2) discriminative clues, i.e., spatial and temporal information, needed to make correct predictions vary among different videos due to large intra-class and inter-class variations. We conduct extensive experiments on three challenging video benchmarks where BEVT achieves very promising results. On Kinetics 400, for which recognition mostly relies on discriminative spatial representations, BEVT achieves comparable results to strong supervised baselines. On Something-Something-V2 and Diving 48, which contain videos relying on temporal dynamics, BEVT outperforms by clear margins all alternative baselines and achieves state-of-the-art performance with a 70.6% and 86.7% Top-1 accuracy respectively.
Neuroplastic graph attention networks for nuclei segmentation in histopathology images
Jan 10, 2022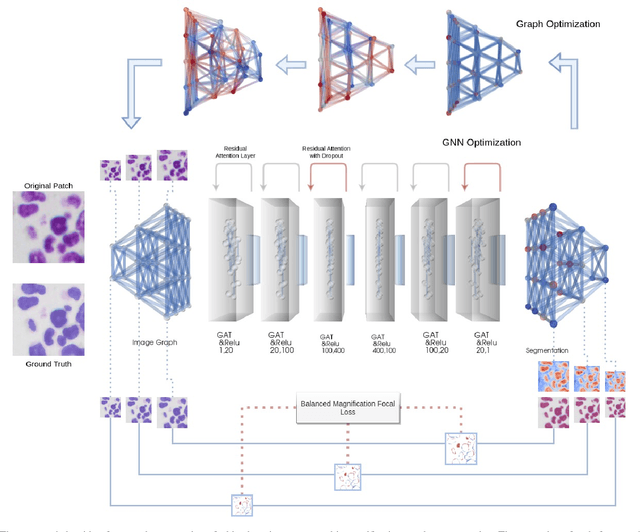
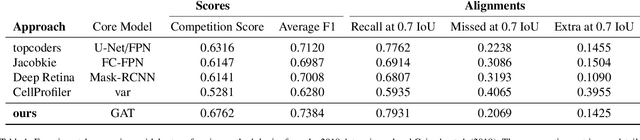

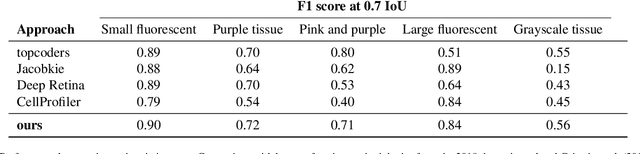
Modern histopathological image analysis relies on the segmentation of cell structures to derive quantitative metrics required in biomedical research and clinical diagnostics. State-of-the-art deep learning approaches predominantly apply convolutional layers in segmentation and are typically highly customized for a specific experimental configuration; often unable to generalize to unknown data. As the model capacity of classical convolutional layers is limited by a finite set of learned kernels, our approach uses a graph representation of the image and focuses on the node transitions in multiple magnifications. We propose a novel architecture for semantic segmentation of cell nuclei robust to differences in experimental configuration such as staining and variation of cell types. The architecture is comprised of a novel neuroplastic graph attention network based on residual graph attention layers and concurrent optimization of the graph structure representing multiple magnification levels of the histopathological image. The modification of graph structure, which generates the node features by projection, is as important to the architecture as the graph neural network itself. It determines the possible message flow and critical properties to optimize attention, graph structure, and node updates in a balanced magnification loss. In experimental evaluation, our framework outperforms ensembles of state-of-the-art neural networks, with a fraction of the neurons typically required, and sets new standards for the segmentation of new nuclei datasets.
Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning
Mar 05, 2021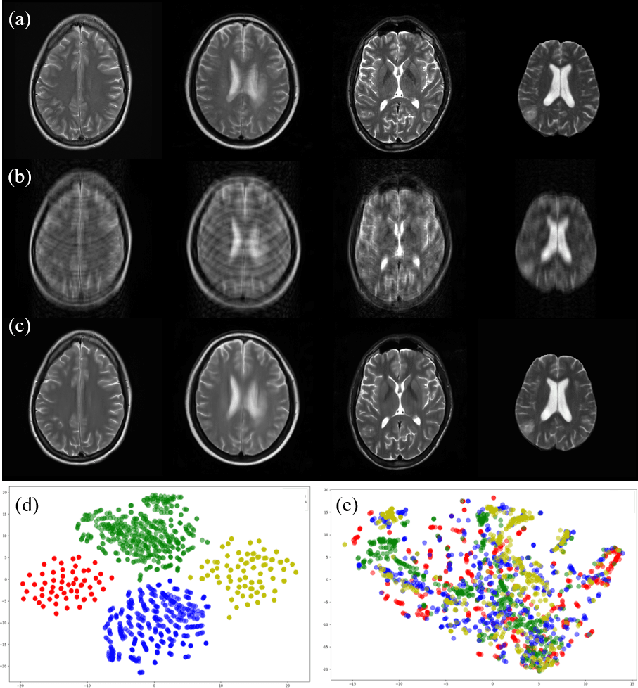
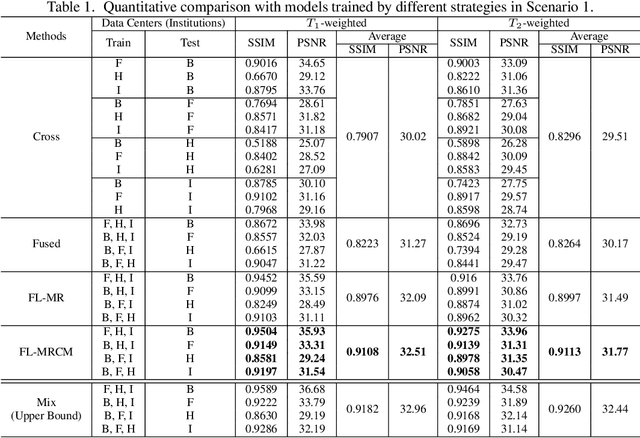
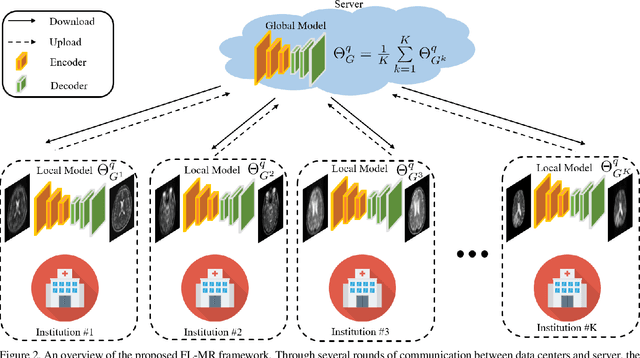
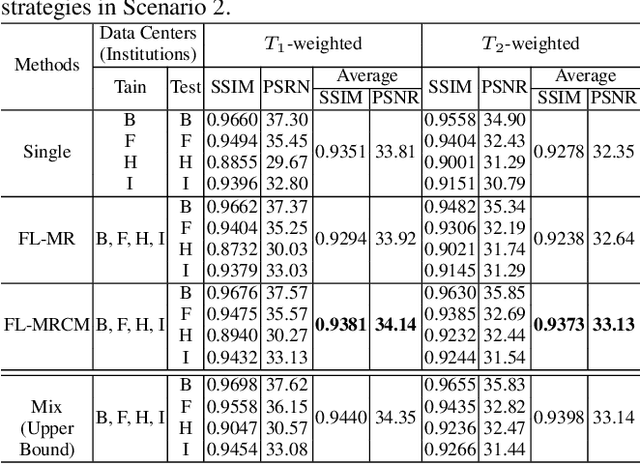
Fast and accurate reconstruction of magnetic resonance (MR) images from under-sampled data is important in many clinical applications. In recent years, deep learning-based methods have been shown to produce superior performance on MR image reconstruction. However, these methods require large amounts of data which is difficult to collect and share due to the high cost of acquisition and medical data privacy regulations. In order to overcome this challenge, we propose a federated learning (FL) based solution in which we take advantage of the MR data available at different institutions while preserving patients' privacy. However, the generalizability of models trained with the FL setting can still be suboptimal due to domain shift, which results from the data collected at multiple institutions with different sensors, disease types, and acquisition protocols, etc. With the motivation of circumventing this challenge, we propose a cross-site modeling for MR image reconstruction in which the learned intermediate latent features among different source sites are aligned with the distribution of the latent features at the target site. Extensive experiments are conducted to provide various insights about FL for MR image reconstruction. Experimental results demonstrate that the proposed framework is a promising direction to utilize multi-institutional data without compromising patients' privacy for achieving improved MR image reconstruction. Our code will be available at https://github.com/guopengf/FLMRCM.
Deep Triplet Hashing Network for Case-based Medical Image Retrieval
Jan 29, 2021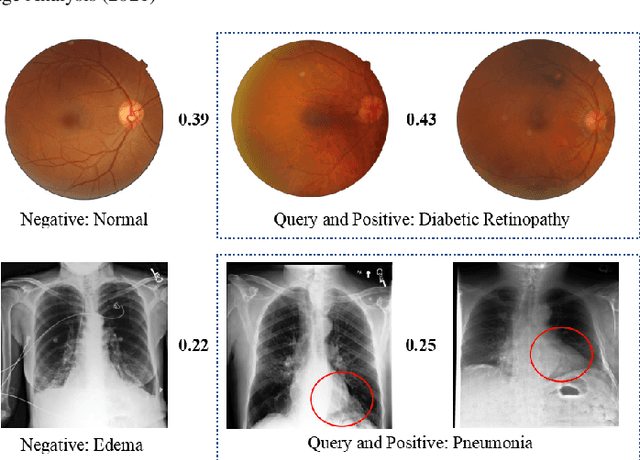
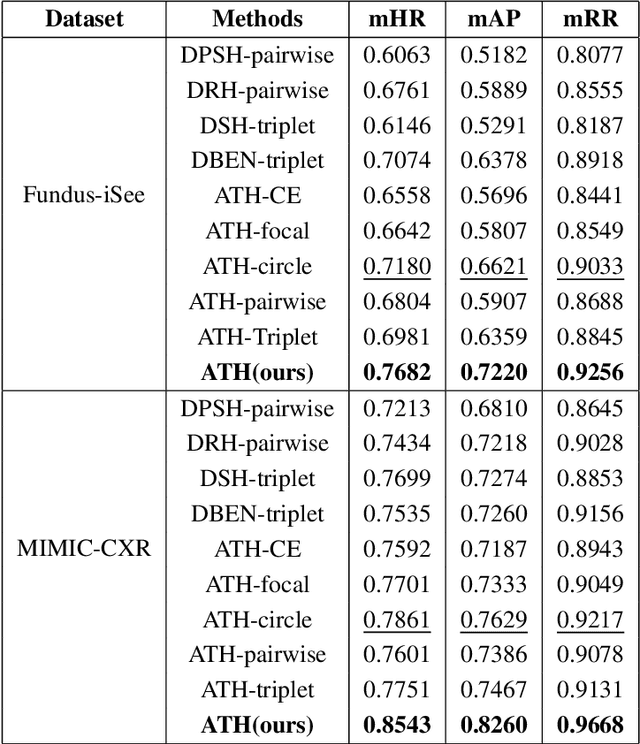
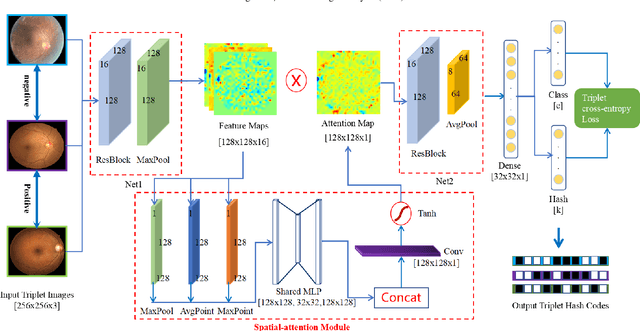
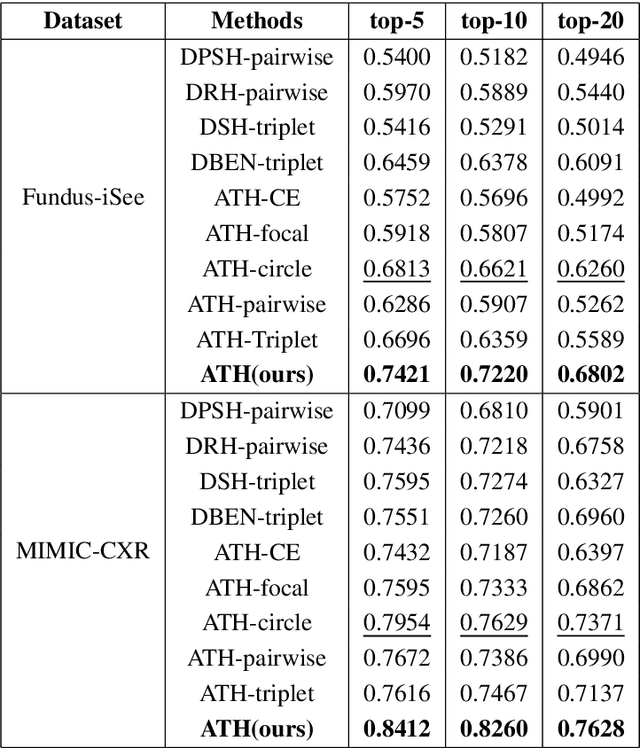
Deep hashing methods have been shown to be the most efficient approximate nearest neighbor search techniques for large-scale image retrieval. However, existing deep hashing methods have a poor small-sample ranking performance for case-based medical image retrieval. The top-ranked images in the returned query results may be as a different class than the query image. This ranking problem is caused by classification, regions of interest (ROI), and small-sample information loss in the hashing space. To address the ranking problem, we propose an end-to-end framework, called Attention-based Triplet Hashing (ATH) network, to learn low-dimensional hash codes that preserve the classification, ROI, and small-sample information. We embed a spatial-attention module into the network structure of our ATH to focus on ROI information. The spatial-attention module aggregates the spatial information of feature maps by utilizing max-pooling, element-wise maximum, and element-wise mean operations jointly along the channel axis. The triplet cross-entropy loss can help to map the classification information of images and similarity between images into the hash codes. Extensive experiments on two case-based medical datasets demonstrate that our proposed ATH can further improve the retrieval performance compared to the state-of-the-art deep hashing methods and boost the ranking performance for small samples. Compared to the other loss methods, the triplet cross-entropy loss can enhance the classification performance and hash code-discriminability
Temporal Difference Learning for Model Predictive Control
Mar 09, 2022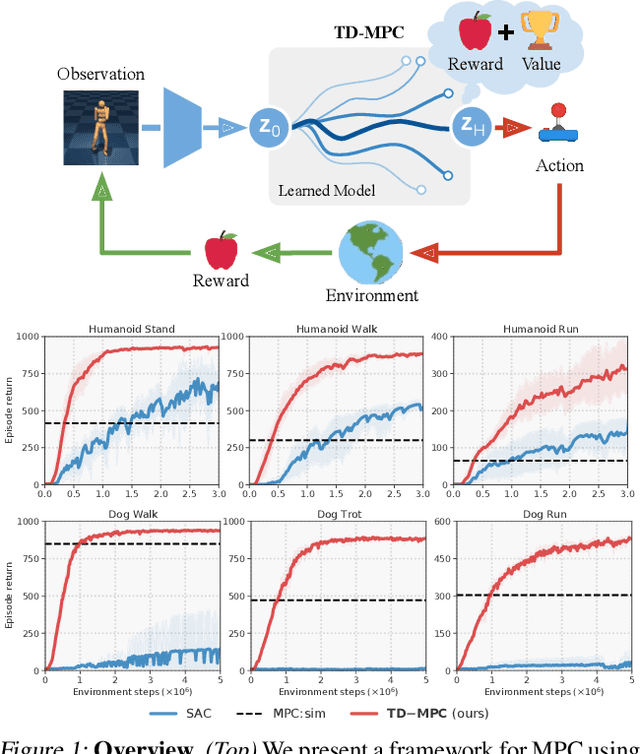

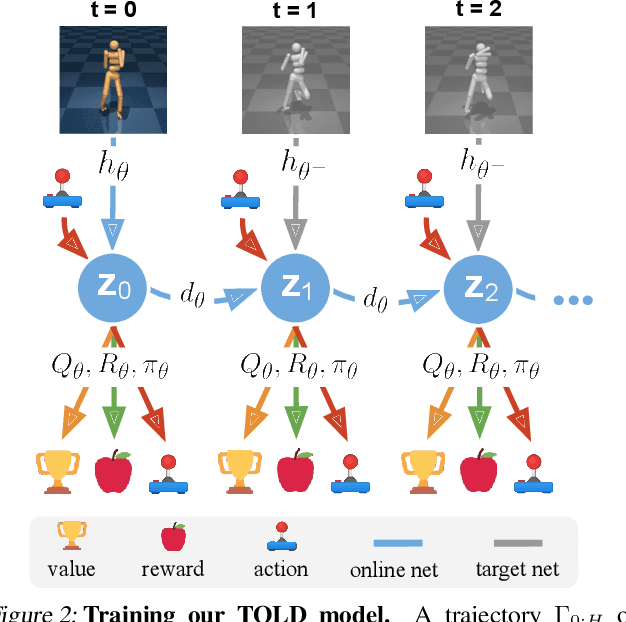
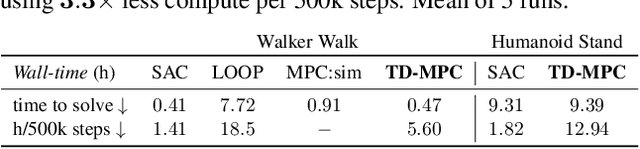
Data-driven model predictive control has two key advantages over model-free methods: a potential for improved sample efficiency through model learning, and better performance as computational budget for planning increases. However, it is both costly to plan over long horizons and challenging to obtain an accurate model of the environment. In this work, we combine the strengths of model-free and model-based methods. We use a learned task-oriented latent dynamics model for local trajectory optimization over a short horizon, and use a learned terminal value function to estimate long-term return, both of which are learned jointly by temporal difference learning. Our method, TD-MPC, achieves superior sample efficiency and asymptotic performance over prior work on both state and image-based continuous control tasks from DMControl and Meta-World. Code and video results are available at https://nicklashansen.github.io/td-mpc.