 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explaining Classifiers by Constructing Familiar Concepts
Mar 07, 2022
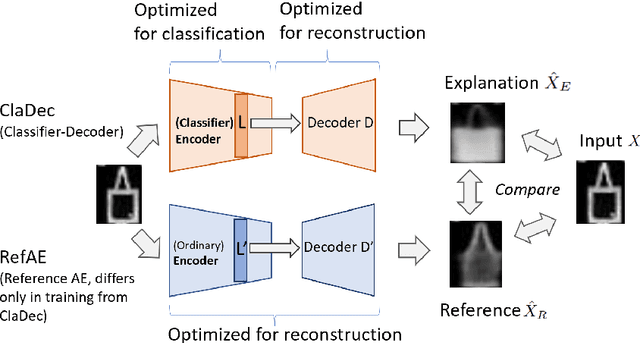
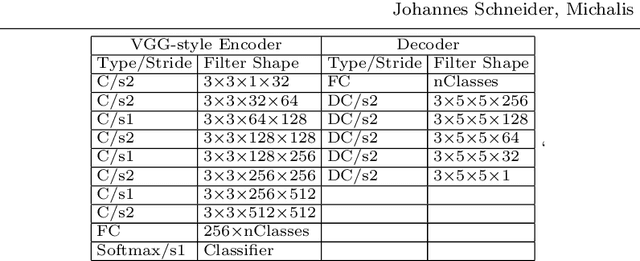
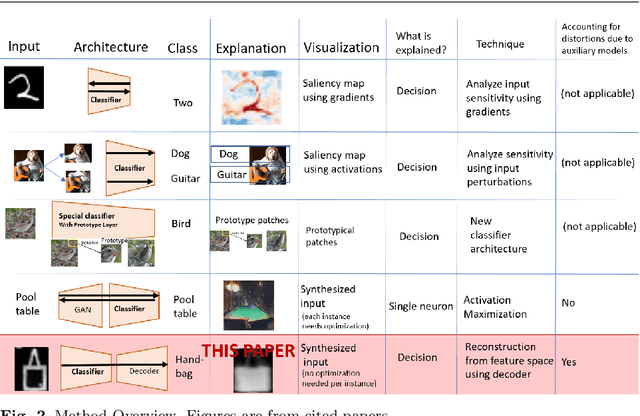
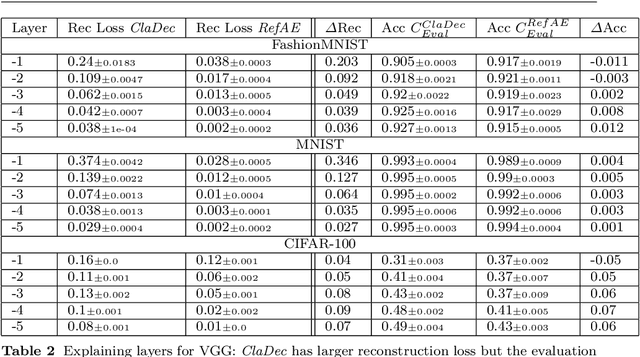
Interpreting a large number of neurons in deep learning is difficult. Our proposed `CLAssifier-DECoder' architecture (ClaDec) facilitates the understanding of the output of an arbitrary layer of neurons or subsets thereof. It uses a decoder that transforms the incomprehensible representation of the given neurons to a representation that is more similar to the domain a human is familiar with. In an image recognition problem, one can recognize what information (or concepts) a layer maintains by contrasting reconstructed images of ClaDec with those of a conventional auto-encoder(AE) serving as reference. An extension of ClaDec allows trading comprehensibility and fidelity. We evaluate our approach for image classification using convolutional neural networks. We show that reconstructed visualizations using encodings from a classifier capture more relevant classification information than conventional AEs. This holds although AEs contain more information on the original input. Our user study highlights that even non-experts can identify a diverse set of concepts contained in images that are relevant (or irrelevant) for the classifier. We also compare against saliency based methods that focus on pixel relevance rather than concepts. We show that ClaDec tends to highlight more relevant input areas to classification though outcomes depend on classifier architecture. Code is at \url{https://github.com/JohnTailor/ClaDec}
Least Square Estimation Network for Depth Completion
Mar 07, 2022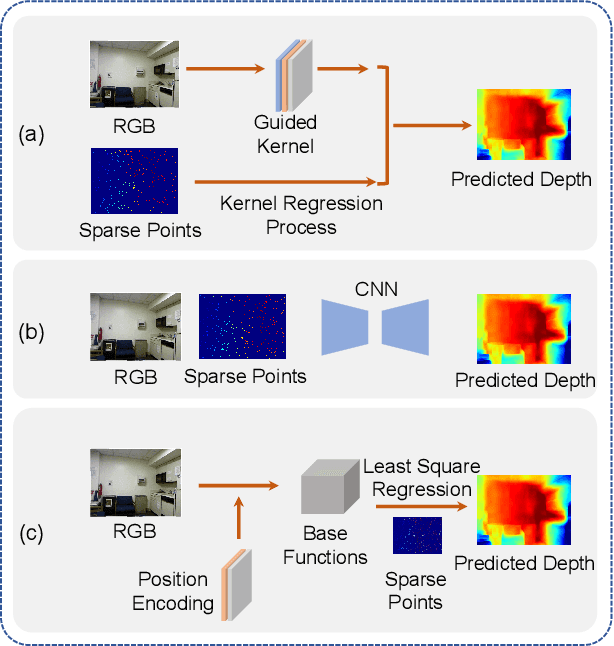
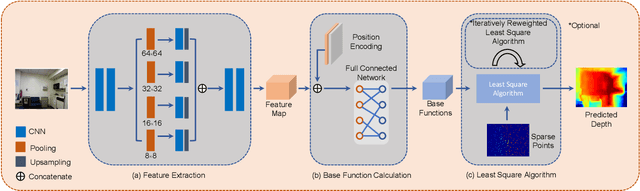
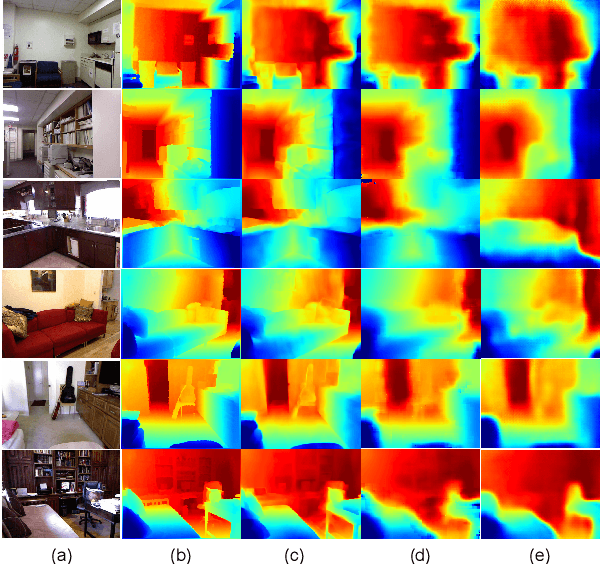
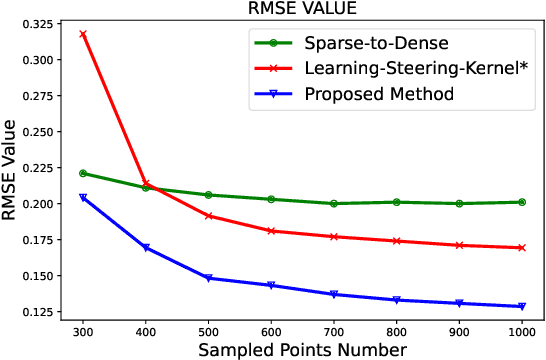
Depth completion is a fundamental task in computer vision and robotics research. Many previous works complete the dense depth map with neural networks directly but most of them are non-interpretable and can not generalize to different situations well. In this paper, we propose an effective image representation method for depth completion tasks. The input of our system is a monocular camera frame and the synchronous sparse depth map. The output of our system is a dense per-pixel depth map of the frame. First we use a neural network to transform each pixel into a feature vector, which we call base functions. Then we pick out the known pixels' base functions and their depth values. We use a linear least square algorithm to fit the base functions and the depth values. Then we get the weights estimated from the least square algorithm. Finally, we apply the weights to the whole image and predict the final depth map. Our method is interpretable so it can generalize well. Experiments show that our results beat the state-of-the-art on NYU-Depth-V2 dataset both in accuracy and runtime. Moreover, experiments show that our method can generalize well on different numbers of sparse points and different datasets.
OccamNets: Mitigating Dataset Bias by Favoring Simpler Hypotheses
Apr 11, 2022
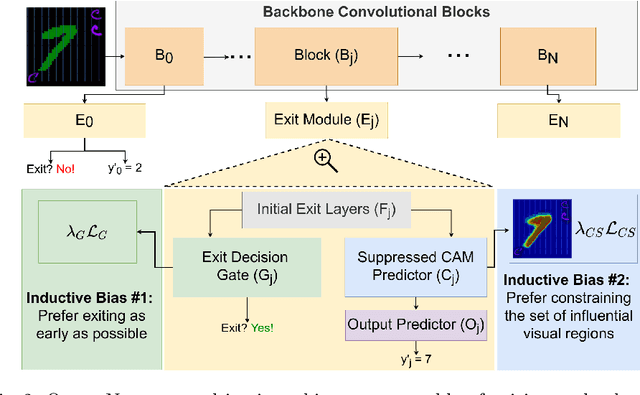


Dataset bias and spurious correlations can significantly impair generalization in deep neural networks. Many prior efforts have addressed this problem using either alternative loss functions or sampling strategies that focus on rare patterns. We propose a new direction: modifying the network architecture to impose inductive biases that make the network robust to dataset bias. Specifically, we propose OccamNets, which are biased to favor simpler solutions by design. OccamNets have two inductive biases. First, they are biased to use as little network depth as needed for an individual example. Second, they are biased toward using fewer image locations for prediction. While OccamNets are biased toward simpler hypotheses, they can learn more complex hypotheses if necessary. In experiments, OccamNets outperform or rival state-of-the-art methods run on architectures that do not incorporate these inductive biases. Furthermore, we demonstrate that when the state-of-the-art debiasing methods are combined with OccamNets results further improve.
Automatic Detection of Interplanetary Coronal Mass Ejections in Solar Wind In Situ Data
May 07, 2022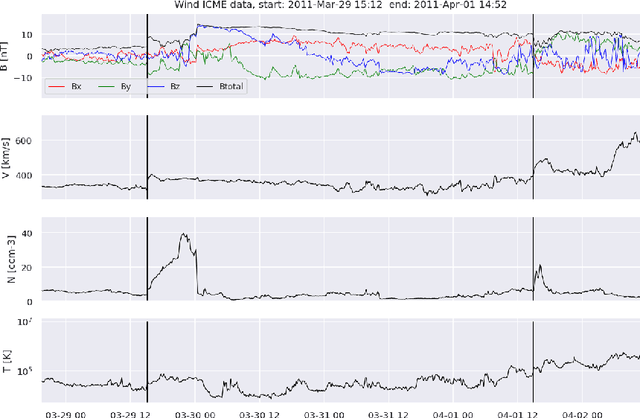
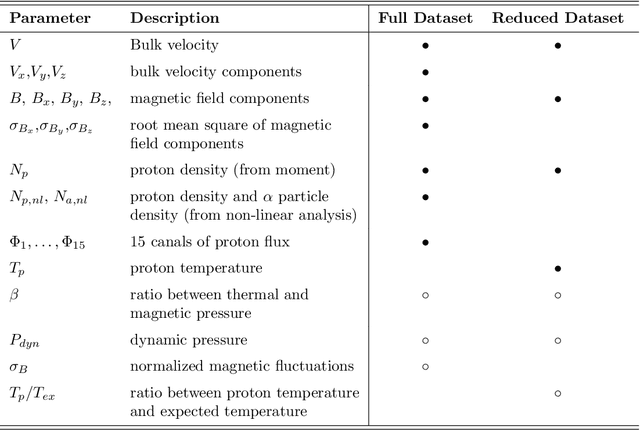
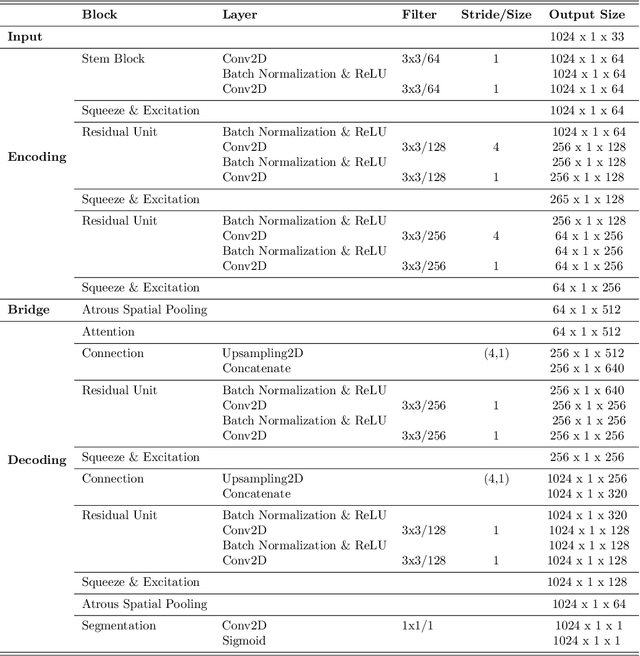
Interplanetary coronal mass ejections (ICMEs) are one of the main drivers for space weather disturbances. In the past, different approaches have been used to automatically detect events in existing time series resulting from solar wind in situ observations. However, accurate and fast detection still remains a challenge when facing the large amount of data from different instruments. For the automatic detection of ICMEs we propose a pipeline using a method that has recently proven successful in medical image segmentation. Comparing it to an existing method, we find that while achieving similar results, our model outperforms the baseline regarding training time by a factor of approximately 20, thus making it more applicable for other datasets. The method has been tested on in situ data from the Wind spacecraft between 1997 and 2015 with a True Skill Statistic (TSS) of 0.64. Out of the 640 ICMEs, 466 were detected correctly by our algorithm, producing a total of 254 False Positives. Additionally, it produced reasonable results on datasets with fewer features and smaller training sets from Wind, STEREO-A and STEREO-B with True Skill Statistics of 0.56, 0.57 and 0.53, respectively. Our pipeline manages to find the start of an ICME with a mean absolute error (MAE) of around 2 hours and 56 minutes, and the end time with a MAE of 3 hours and 20 minutes. The relatively fast training allows straightforward tuning of hyperparameters and could therefore easily be used to detect other structures and phenomena in solar wind data, such as corotating interaction regions.
Frequency Domain Image Translation: More Photo-realistic, Better Identity-preserving
Dec 01, 2020
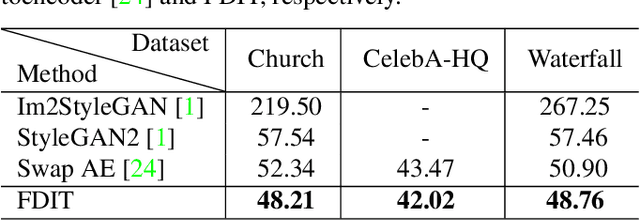
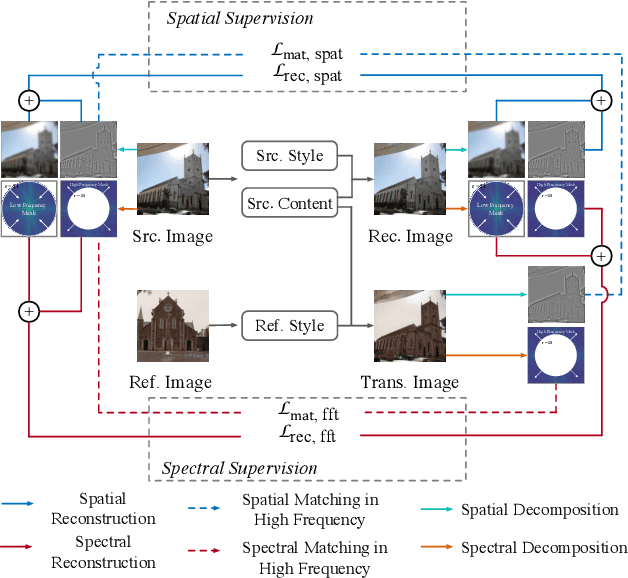
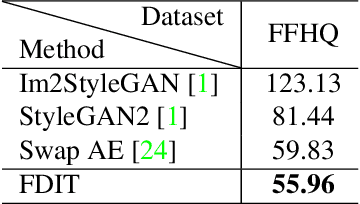
Image-to-image translation aims at translating a particular style of an image to another. The synthesized images can be more photo-realistic and identity-preserving by decomposing the image into content and style in a disentangled manner. While existing models focus on designing specialized network architecture to separate the two components, this paper investigates how to explicitly constrain the content and style statistics of images. We achieve this goal by transforming the input image into high frequency and low frequency information, which correspond to the content and style, respectively. We regulate the frequency distribution from two aspects: a) a spatial level restriction to locally restrict the frequency distribution of images; b) a spectral level regulation to enhance the global consistency among images. On multiple datasets we show that the proposed approach consistently leads to significant improvements on top of various state-of-the-art image translation models.
Unsupervised Contrastive Learning based Transformer for Lung Nodule Detection
Apr 30, 2022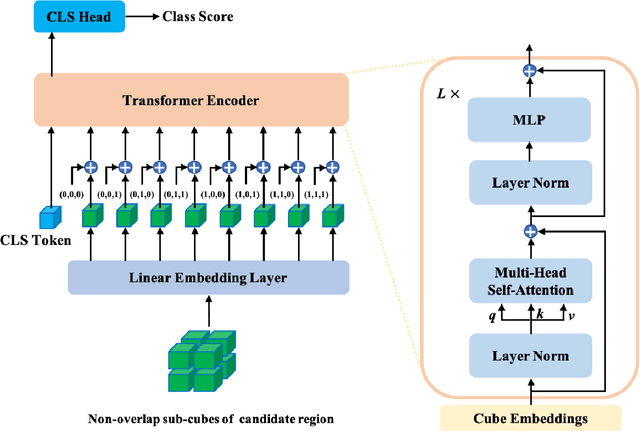
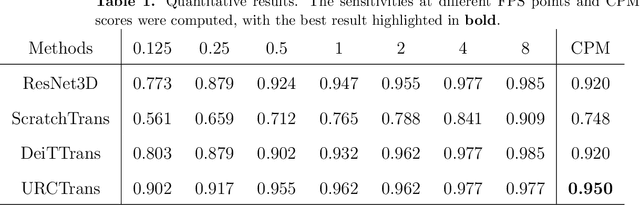
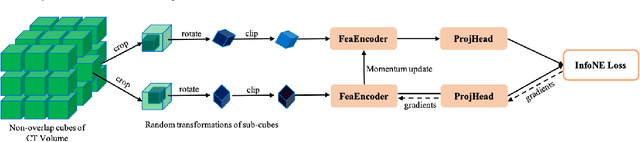
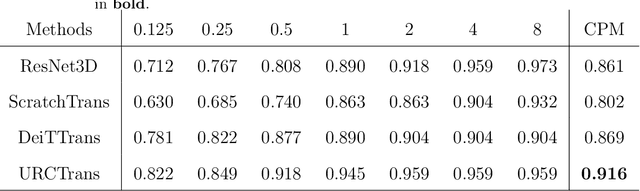
Early detection of lung nodules with computed tomography (CT) is critical for the longer survival of lung cancer patients and better quality of life. Computer-aided detection/diagnosis (CAD) is proven valuable as a second or concurrent reader in this context. However, accurate detection of lung nodules remains a challenge for such CAD systems and even radiologists due to not only the variability in size, location, and appearance of lung nodules but also the complexity of lung structures. This leads to a high false-positive rate with CAD, compromising its clinical efficacy. Motivated by recent computer vision techniques, here we present a self-supervised region-based 3D transformer model to identify lung nodules among a set of candidate regions. Specifically, a 3D vision transformer (ViT) is developed that divides a CT image volume into a sequence of non-overlap cubes, extracts embedding features from each cube with an embedding layer, and analyzes all embedding features with a self-attention mechanism for the prediction. To effectively train the transformer model on a relatively small dataset, the region-based contrastive learning method is used to boost the performance by pre-training the 3D transformer with public CT images. Our experiments show that the proposed method can significantly improve the performance of lung nodule screening in comparison with the commonly used 3D convolutional neural networks.
FuseVis: Interpreting neural networks for image fusion using per-pixel saliency visualization
Dec 06, 2020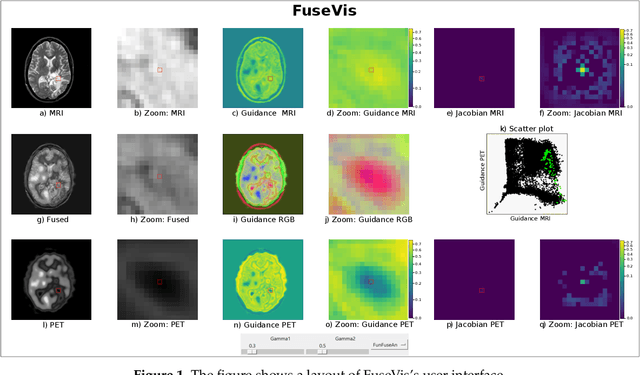

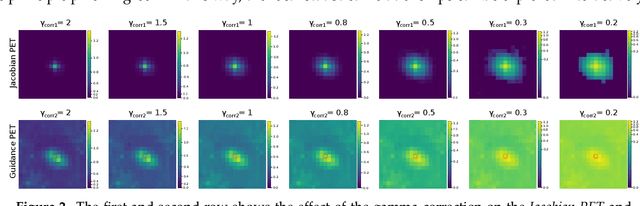

Image fusion helps in merging two or more images to construct a more informative single fused image. Recently, unsupervised learning based convolutional neural networks (CNN) have been utilized for different types of image fusion tasks such as medical image fusion, infrared-visible image fusion for autonomous driving as well as multi-focus and multi-exposure image fusion for satellite imagery. However, it is challenging to analyze the reliability of these CNNs for the image fusion tasks since no groundtruth is available. This led to the use of a wide variety of model architectures and optimization functions yielding quite different fusion results. Additionally, due to the highly opaque nature of such neural networks, it is difficult to explain the internal mechanics behind its fusion results. To overcome these challenges, we present a novel real-time visualization tool, named FuseVis, with which the end-user can compute per-pixel saliency maps that examine the influence of the input image pixels on each pixel of the fused image. We trained several image fusion based CNNs on medical image pairs and then using our FuseVis tool, we performed case studies on a specific clinical application by interpreting the saliency maps from each of the fusion methods. We specifically visualized the relative influence of each input image on the predictions of the fused image and showed that some of the evaluated image fusion methods are better suited for the specific clinical application. To the best of our knowledge, currently, there is no approach for visual analysis of neural networks for image fusion. Therefore, this work opens up a new research direction to improve the interpretability of deep fusion networks. The FuseVis tool can also be adapted in other deep neural network based image processing applications to make them interpretable.
Detecting Adversarial Perturbations in Multi-Task Perception
Mar 02, 2022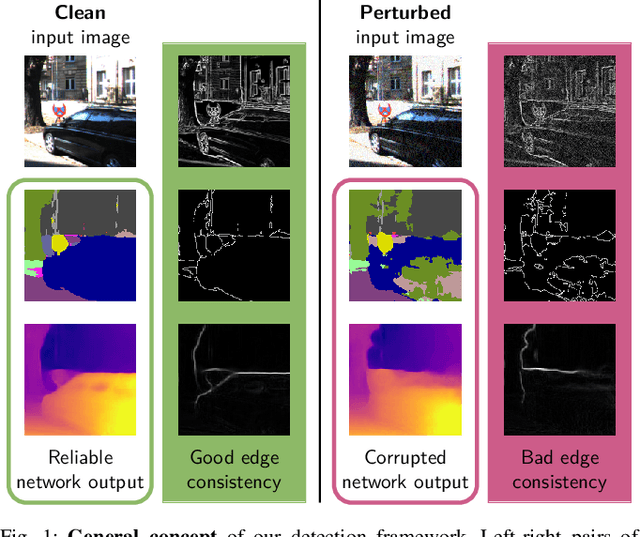
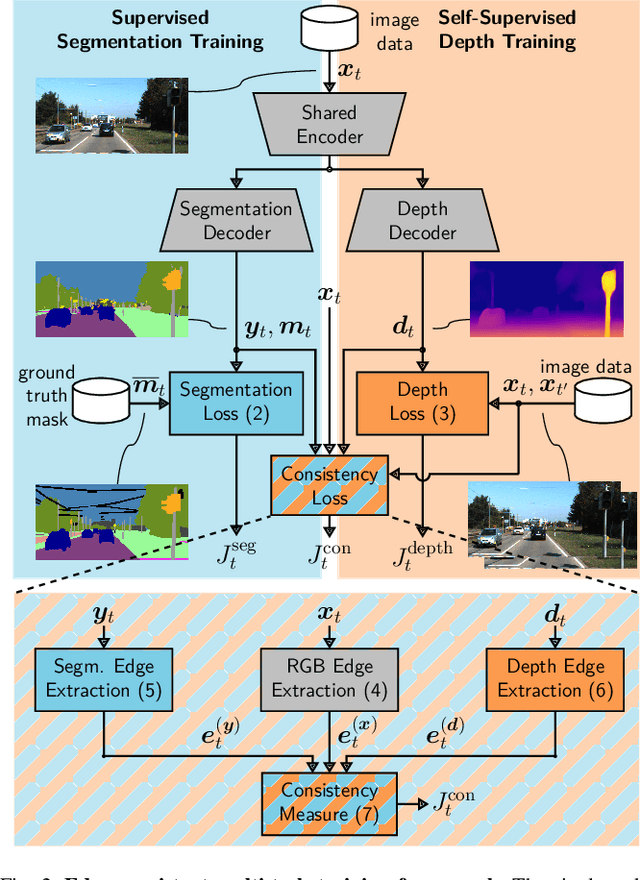
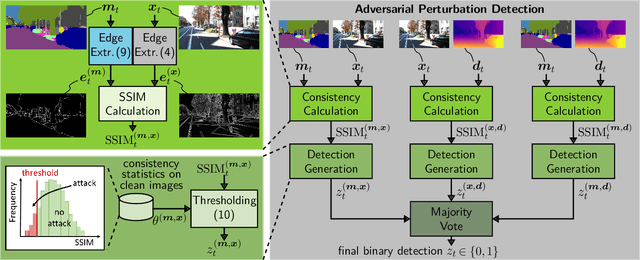
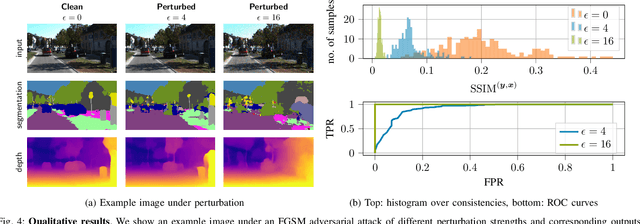
While deep neural networks (DNNs) achieve impressive performance on environment perception tasks, their sensitivity to adversarial perturbations limits their use in practical applications. In this paper, we (i) propose a novel adversarial perturbation detection scheme based on multi-task perception of complex vision tasks (i.e., depth estimation and semantic segmentation). Specifically, adversarial perturbations are detected by inconsistencies between extracted edges of the input image, the depth output, and the segmentation output. To further improve this technique, we (ii) develop a novel edge consistency loss between all three modalities, thereby improving their initial consistency which in turn supports our detection scheme. We verify our detection scheme's effectiveness by employing various known attacks and image noises. In addition, we (iii) develop a multi-task adversarial attack, aiming at fooling both tasks as well as our detection scheme. Experimental evaluation on the Cityscapes and KITTI datasets shows that under an assumption of a 5% false positive rate up to 100% of images are correctly detected as adversarially perturbed, depending on the strength of the perturbation. Code will be available on github. A short video at https://youtu.be/KKa6gOyWmH4 provides qualitative results.
How to Robustify Black-Box ML Models? A Zeroth-Order Optimization Perspective
Mar 27, 2022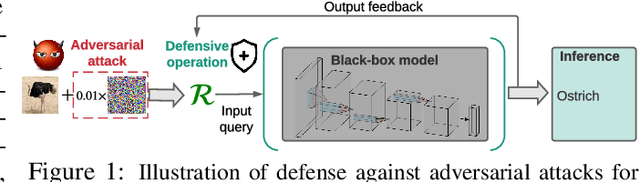
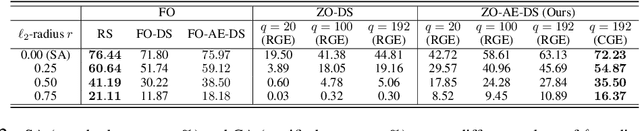
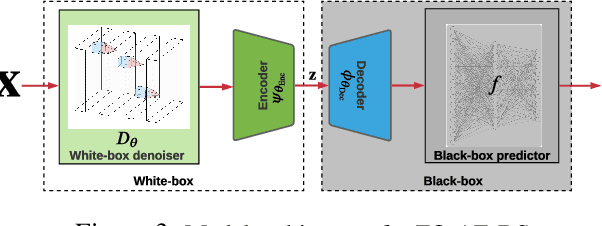
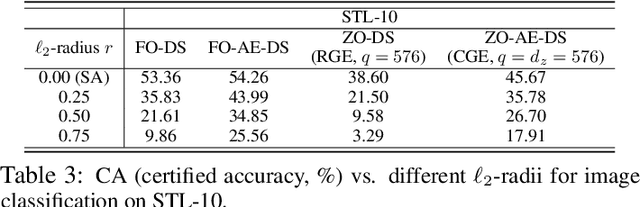
The lack of adversarial robustness has been recognized as an important issue for state-of-the-art machine learning (ML) models, e.g., deep neural networks (DNNs). Thereby, robustifying ML models against adversarial attacks is now a major focus of research. However, nearly all existing defense methods, particularly for robust training, made the white-box assumption that the defender has the access to the details of an ML model (or its surrogate alternatives if available), e.g., its architectures and parameters. Beyond existing works, in this paper we aim to address the problem of black-box defense: How to robustify a black-box model using just input queries and output feedback? Such a problem arises in practical scenarios, where the owner of the predictive model is reluctant to share model information in order to preserve privacy. To this end, we propose a general notion of defensive operation that can be applied to black-box models, and design it through the lens of denoised smoothing (DS), a first-order (FO) certified defense technique. To allow the design of merely using model queries, we further integrate DS with the zeroth-order (gradient-free) optimization. However, a direct implementation of zeroth-order (ZO) optimization suffers a high variance of gradient estimates, and thus leads to ineffective defense. To tackle this problem, we next propose to prepend an autoencoder (AE) to a given (black-box) model so that DS can be trained using variance-reduced ZO optimization. We term the eventual defense as ZO-AE-DS. In practice, we empirically show that ZO-AE- DS can achieve improved accuracy, certified robustness, and query complexity over existing baselines. And the effectiveness of our approach is justified under both image classification and image reconstruction tasks. Codes are available at https://github.com/damon-demon/Black-Box-Defense.
US-GAN: On the importance of Ultimate Skip Connection for Facial Expression Synthesis
Dec 24, 2021


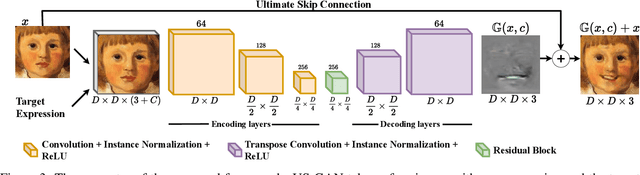
Recent studies have shown impressive results in multi-domain image-to-image translation for facial expression synthesis. While effective, these methods require a large number of labelled samples for plausible results. Their performance significantly degrades when we train them on smaller datasets. To address this limitation, in this work, we present US-GAN, a smaller and effective method for synthesizing plausible expressions by employing notably smaller datasets. The proposed method comprises of encoding layers, single residual block, decoding layers and an ultimate skip connection that links the input image to an output image. It has three times lesser parameters as compared to state-of-the-art facial expression synthesis methods. Experimental results demonstrate the quantitative and qualitative effectiveness of our proposed method. In addition, we also show that an ultimate skip connection is sufficient for recovering rich facial and overall color details of the input face image that a larger state-of-the-art model fails to recover.