 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 07, 2021
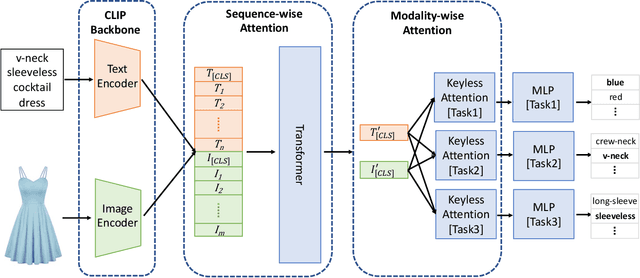

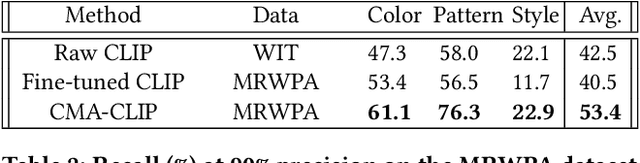

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
Spatial-context-aware deep neural network for multi-class image classification
Nov 24, 2021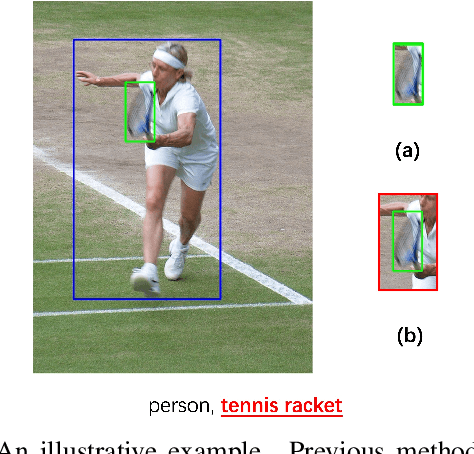
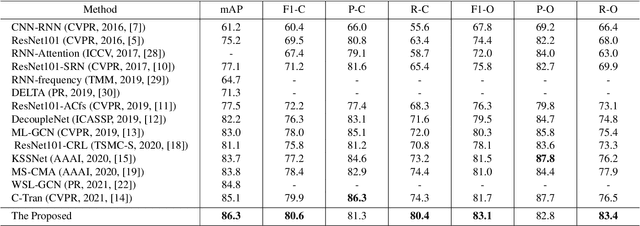
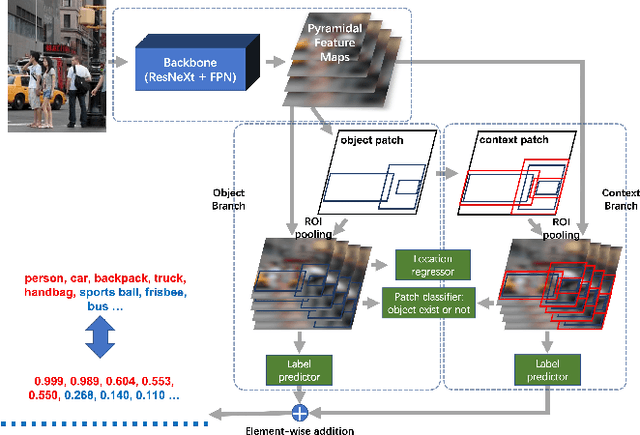

Multi-label image classification is a fundamental but challenging task in computer vision. Over the past few decades, solutions exploring relationships between semantic labels have made great progress. However, the underlying spatial-contextual information of labels is under-exploited. To tackle this problem, a spatial-context-aware deep neural network is proposed to predict labels taking into account both semantic and spatial information. This proposed framework is evaluated on Microsoft COCO and PASCAL VOC, two widely used benchmark datasets for image multi-labelling. The results show that the proposed approach is superior to the state-of-the-art solutions on dealing with the multi-label image classification problem.
LAVT: Language-Aware Vision Transformer for Referring Image Segmentation
Dec 04, 2021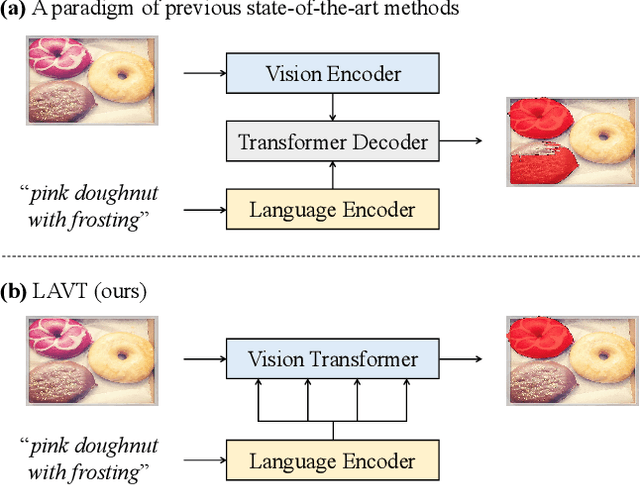
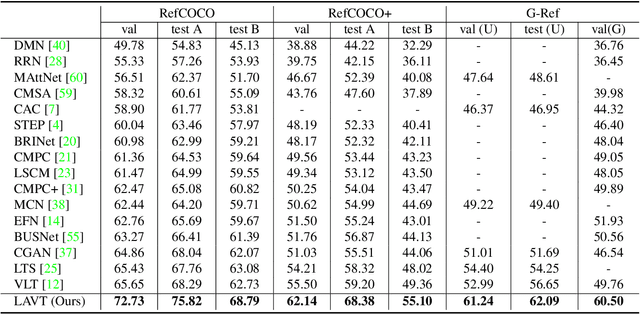
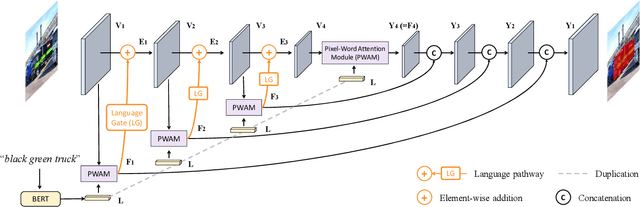
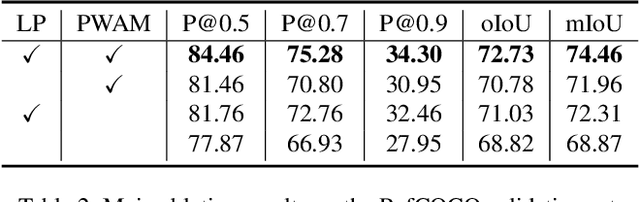
Referring image segmentation is a fundamental vision-language task that aims to segment out an object referred to by a natural language expression from an image. One of the key challenges behind this task is leveraging the referring expression for highlighting relevant positions in the image. A paradigm for tackling this problem is to leverage a powerful vision-language ("cross-modal") decoder to fuse features independently extracted from a vision encoder and a language encoder. Recent methods have made remarkable advancements in this paradigm by exploiting Transformers as cross-modal decoders, concurrent to the Transformer's overwhelming success in many other vision-language tasks. Adopting a different approach in this work, we show that significantly better cross-modal alignments can be achieved through the early fusion of linguistic and visual features in intermediate layers of a vision Transformer encoder network. By conducting cross-modal feature fusion in the visual feature encoding stage, we can leverage the well-proven correlation modeling power of a Transformer encoder for excavating helpful multi-modal context. This way, accurate segmentation results are readily harvested with a light-weight mask predictor. Without bells and whistles, our method surpasses the previous state-of-the-art methods on RefCOCO, RefCOCO+, and G-Ref by large margins.
Generalized Classification of Satellite Image Time Series with Thermal Positional Encoding
Mar 17, 2022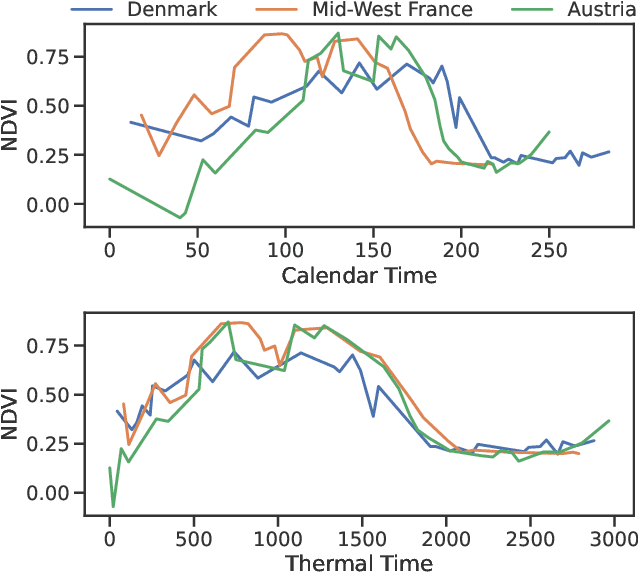
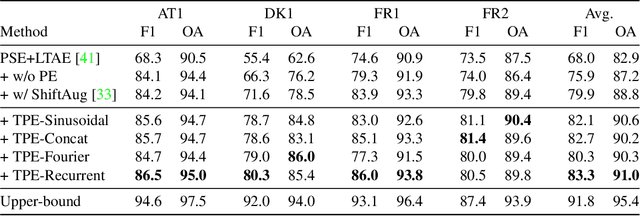
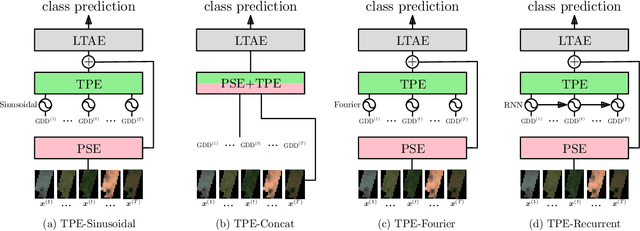
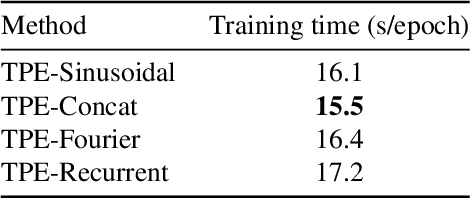
Large-scale crop type classification is a task at the core of remote sensing efforts with applications of both economic and ecological importance. Current state-of-the-art deep learning methods are based on self-attention and use satellite image time series (SITS) to discriminate crop types based on their unique growth patterns. However, existing methods generalize poorly to regions not seen during training mainly due to not being robust to temporal shifts of the growing season caused by variations in climate. To this end, we propose Thermal Positional Encoding (TPE) for attention-based crop classifiers. Unlike previous positional encoding based on calendar time (e.g. day-of-year), TPE is based on thermal time, which is obtained by accumulating daily average temperatures over the growing season. Since crop growth is directly related to thermal time, but not calendar time, TPE addresses the temporal shifts between different regions to improve generalization. We propose multiple TPE strategies, including learnable methods, to further improve results compared to the common fixed positional encodings. We demonstrate our approach on a crop classification task across four different European regions, where we obtain state-of-the-art generalization results.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022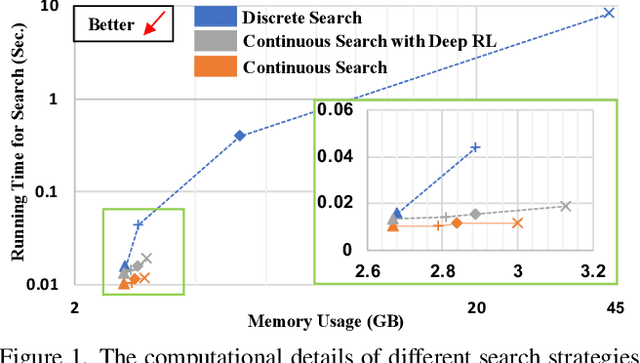

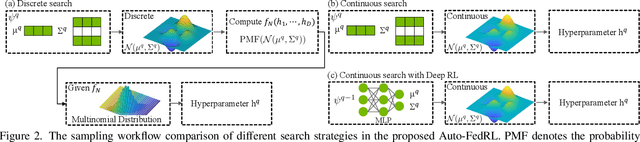

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
TISE: A Toolbox for Text-to-Image Synthesis Evaluation
Dec 02, 2021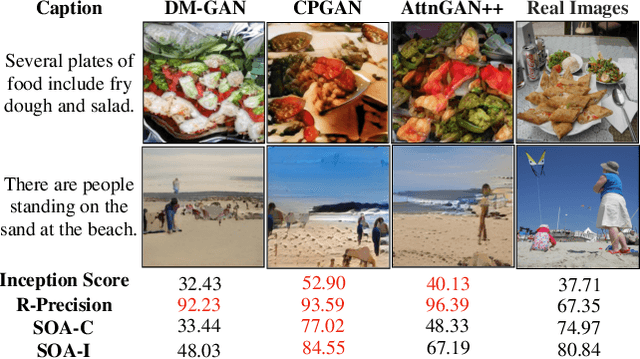
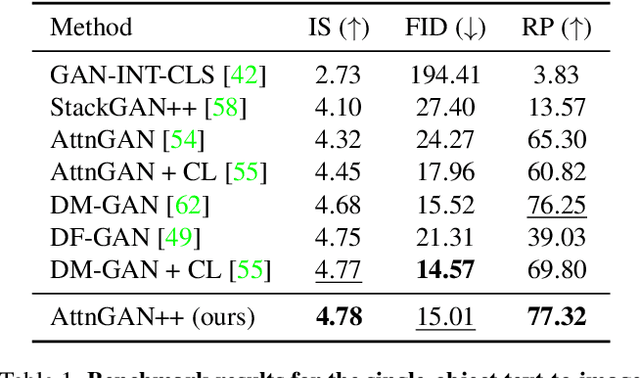

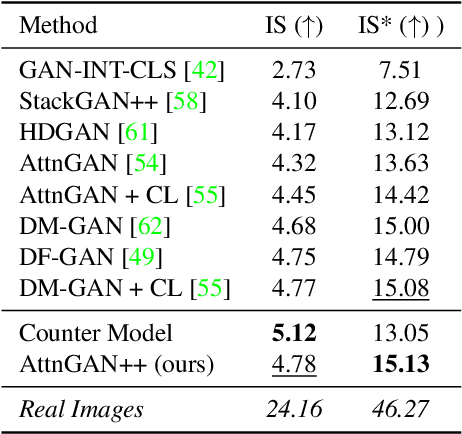
In this paper, we conduct a study on state-of-the-art methods for single- and multi-object text-to-image synthesis and propose a common framework for evaluating these methods. We first identify several common issues in the current evaluation of text-to-image models, which are: (i) a commonly used metric for image quality assessment, e.g., Inception Score (IS), is often either miscalibrated for the single-object case or misused for the multi-object case; (ii) the overfitting phenomenon appears in the existing R-precision (RP) and SOA metrics, which are used to assess text relevance and object accuracy aspects, respectively; (iii) many vital factors in the evaluation of the multi-object case are primarily dismissed, e.g., object fidelity, positional alignment, counting alignment; (iv) the ranking of the methods based on current metrics is highly inconsistent with real images. Then, to overcome these limitations, we propose a combined set of existing and new metrics to systematically evaluate the methods. For existing metrics, we develop an improved version of IS named IS* by using temperature scaling to calibrate the confidence of the classifier used by IS; we also propose a solution to mitigate the overfitting issues of RP and SOA. Regarding a set of new metrics compensating for the lacking of vital evaluating factors in the multi-object case, we develop CA for counting alignment, PA for positional alignment, object-centric IS (O-IS), object-centric FID (O-FID) for object fidelity. Our benchmark, therefore, results in a highly consistent ranking among existing methods, being well-aligned to human evaluation. We also create a strong baseline model (AttnGAN++) for the benchmark by a simple modification from the well-known AttnGAN. We will release this toolbox for unified evaluation, so-called TISE, to standardize the evaluation of the text-to-image synthesis models.
Attention Spiking Neural Networks
Sep 28, 2022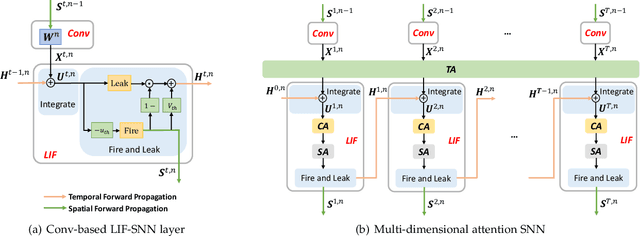
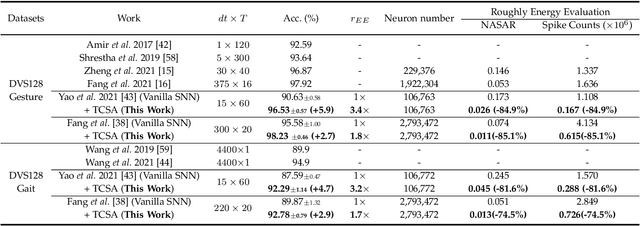
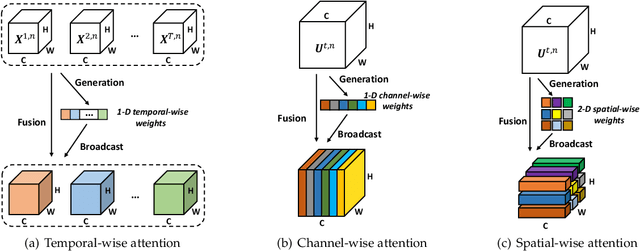
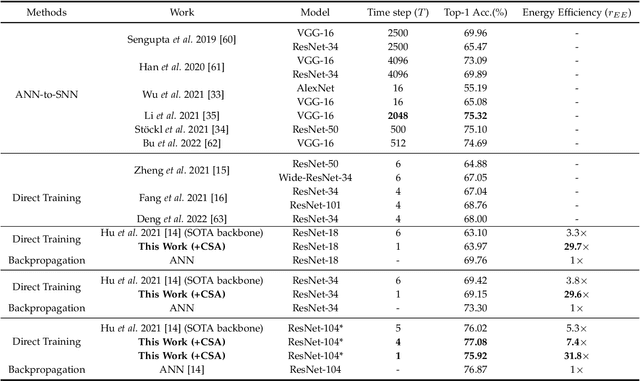
Benefiting from the event-driven and sparse spiking characteristics of the brain, spiking neural networks (SNNs) are becoming an energy-efficient alternative to artificial neural networks (ANNs). However, the performance gap between SNNs and ANNs has been a great hindrance to deploying SNNs ubiquitously for a long time. To leverage the full potential of SNNs, we study the effect of attention mechanisms in SNNs. We first present our idea of attention with a plug-and-play kit, termed the Multi-dimensional Attention (MA). Then, a new attention SNN architecture with end-to-end training called "MA-SNN" is proposed, which infers attention weights along the temporal, channel, as well as spatial dimensions separately or simultaneously. Based on the existing neuroscience theories, we exploit the attention weights to optimize membrane potentials, which in turn regulate the spiking response in a data-dependent way. At the cost of negligible additional parameters, MA facilitates vanilla SNNs to achieve sparser spiking activity, better performance, and energy efficiency concurrently. Experiments are conducted in event-based DVS128 Gesture/Gait action recognition and ImageNet-1k image classification. On Gesture/Gait, the spike counts are reduced by 84.9%/81.6%, and the task accuracy and energy efficiency are improved by 5.9%/4.7% and 3.4$\times$/3.2$\times$. On ImageNet-1K, we achieve top-1 accuracy of 75.92% and 77.08% on single/4-step Res-SNN-104, which are state-of-the-art results in SNNs. To our best knowledge, this is for the first time, that the SNN community achieves comparable or even better performance compared with its ANN counterpart in the large-scale dataset. Our work lights up SNN's potential as a general backbone to support various applications for SNNs, with a great balance between effectiveness and efficiency.
Deep Image Prior using Stein's Unbiased Risk Estimator: SURE-DIP
Nov 21, 2021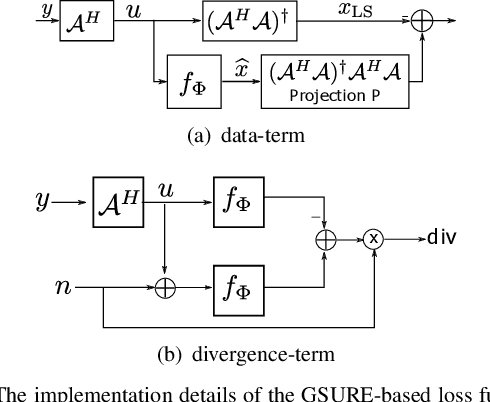
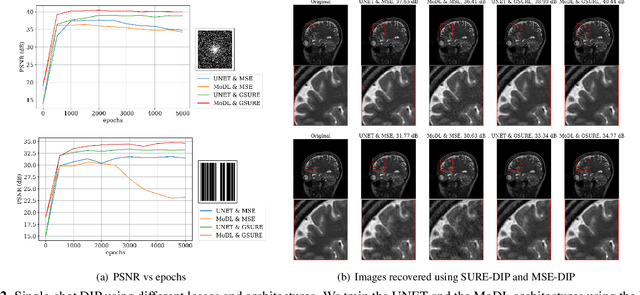
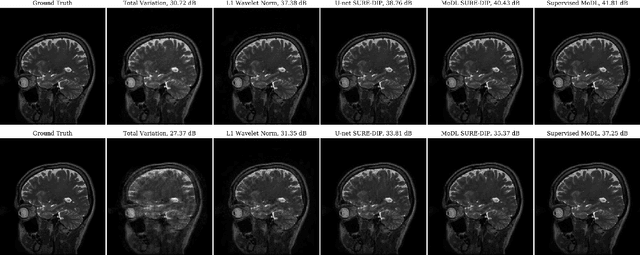
Deep learning algorithms that rely on extensive training data are revolutionizing image recovery from ill-posed measurements. Training data is scarce in many imaging applications, including ultra-high-resolution imaging. The deep image prior (DIP) algorithm was introduced for single-shot image recovery, completely eliminating the need for training data. A challenge with this scheme is the need for early stopping to minimize the overfitting of the CNN parameters to the noise in the measurements. We introduce a generalized Stein's unbiased risk estimate (GSURE) loss metric to minimize the overfitting. Our experiments show that the SURE-DIP approach minimizes the overfitting issues, thus offering significantly improved performance over classical DIP schemes. We also use the SURE-DIP approach with model-based unrolling architectures, which offers improved performance over direct inversion schemes.
Semantic Unfolding of StyleGAN Latent Space
Jun 29, 2022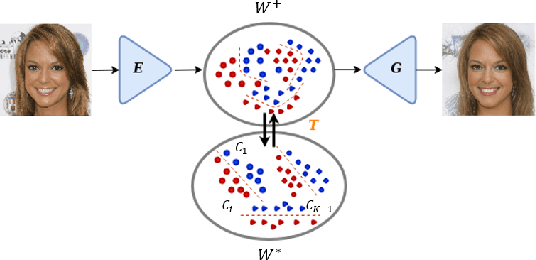
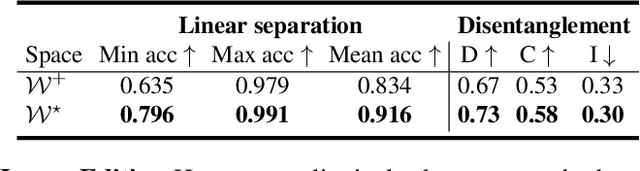

Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to an input real image. This editing property emerges from the disentangled nature of the latent space. In this paper, we identify that the facial attribute disentanglement is not optimal, thus facial editing relying on linear attribute separation is flawed. We thus propose to improve semantic disentanglement with supervision. Our method consists in learning a proxy latent representation using normalizing flows, and we show that this leads to a more efficient space for face image editing.
Fuse and Attend: Generalized Embedding Learning for Art and Sketches
Aug 20, 2022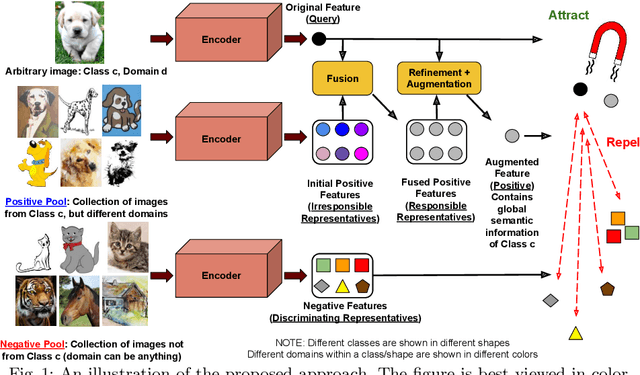
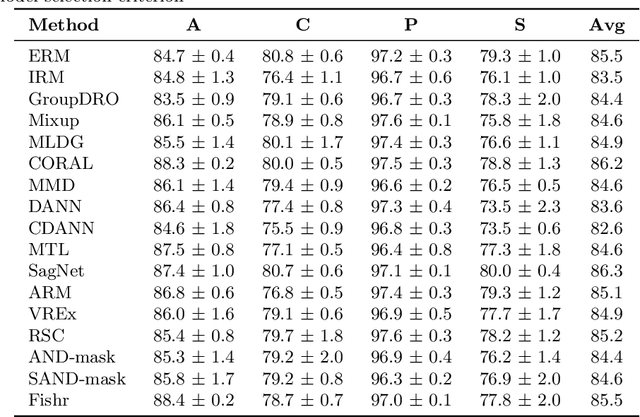
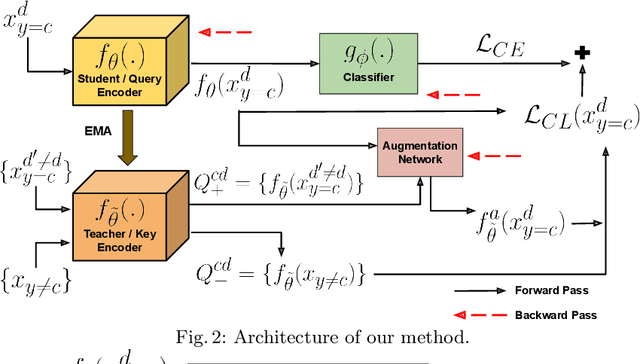
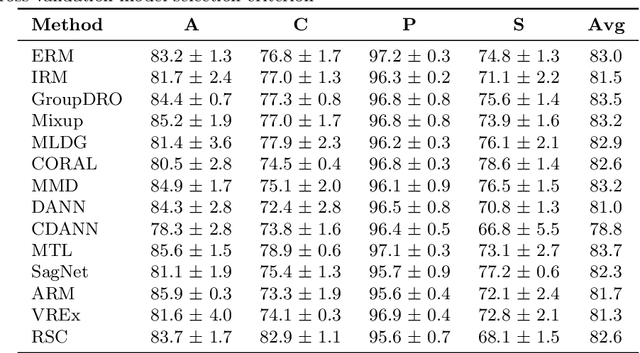
While deep Embedding Learning approaches have witnessed widespread success in multiple computer vision tasks, the state-of-the-art methods for representing natural images need not necessarily perform well on images from other domains, such as paintings, cartoons, and sketch. This is because of the huge shift in the distribution of data from across these domains, as compared to natural images. Domains like sketch often contain sparse informative pixels. However, recognizing objects in such domains is crucial, given multiple relevant applications leveraging such data, for instance, sketch to image retrieval. Thus, achieving an Embedding Learning model that could perform well across multiple domains is not only challenging, but plays a pivotal role in computer vision. To this end, in this paper, we propose a novel Embedding Learning approach with the goal of generalizing across different domains. During training, given a query image from a domain, we employ gated fusion and attention to generate a positive example, which carries a broad notion of the semantics of the query object category (from across multiple domains). By virtue of Contrastive Learning, we pull the embeddings of the query and positive, in order to learn a representation which is robust across domains. At the same time, to teach the model to be discriminative against examples from different semantic categories (across domains), we also maintain a pool of negative embeddings (from different categories). We show the prowess of our method using the DomainBed framework, on the popular PACS (Photo, Art painting, Cartoon, and Sketch) dataset.