 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
It's All About Your Sketch: Democratising Sketch Control in Diffusion Models
Mar 12, 2024
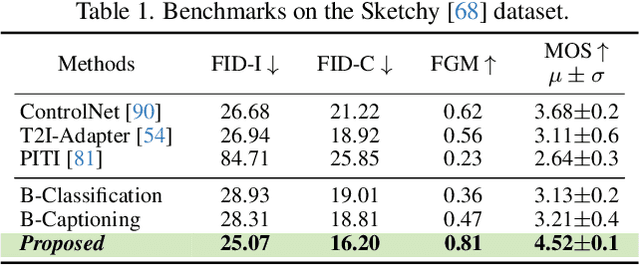

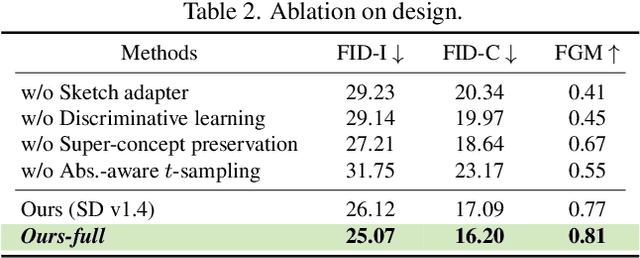

This paper unravels the potential of sketches for diffusion models, addressing the deceptive promise of direct sketch control in generative AI. We importantly democratise the process, enabling amateur sketches to generate precise images, living up to the commitment of "what you sketch is what you get". A pilot study underscores the necessity, revealing that deformities in existing models stem from spatial-conditioning. To rectify this, we propose an abstraction-aware framework, utilising a sketch adapter, adaptive time-step sampling, and discriminative guidance from a pre-trained fine-grained sketch-based image retrieval model, working synergistically to reinforce fine-grained sketch-photo association. Our approach operates seamlessly during inference without the need for textual prompts; a simple, rough sketch akin to what you and I can create suffices! We welcome everyone to examine results presented in the paper and its supplementary. Contributions include democratising sketch control, introducing an abstraction-aware framework, and leveraging discriminative guidance, validated through extensive experiments.
From Paper to Card: Transforming Design Implications with Generative AI
Mar 12, 2024
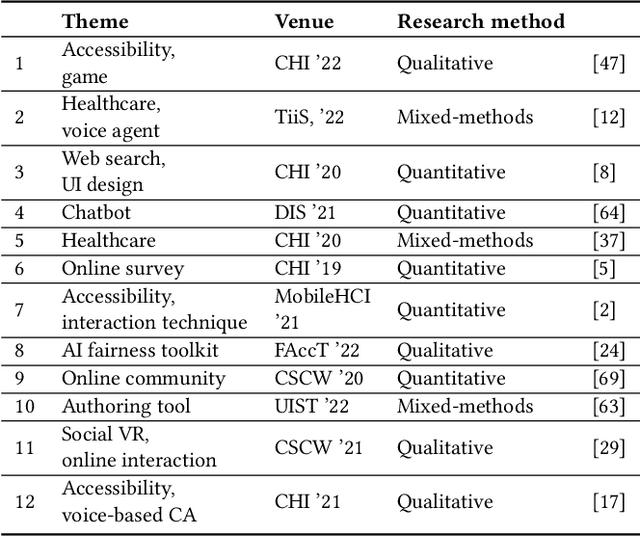
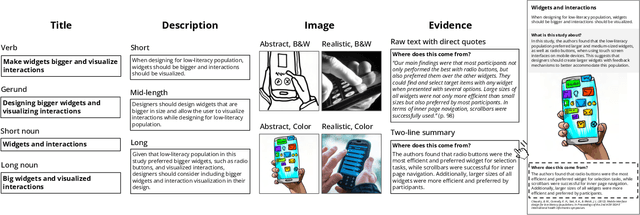
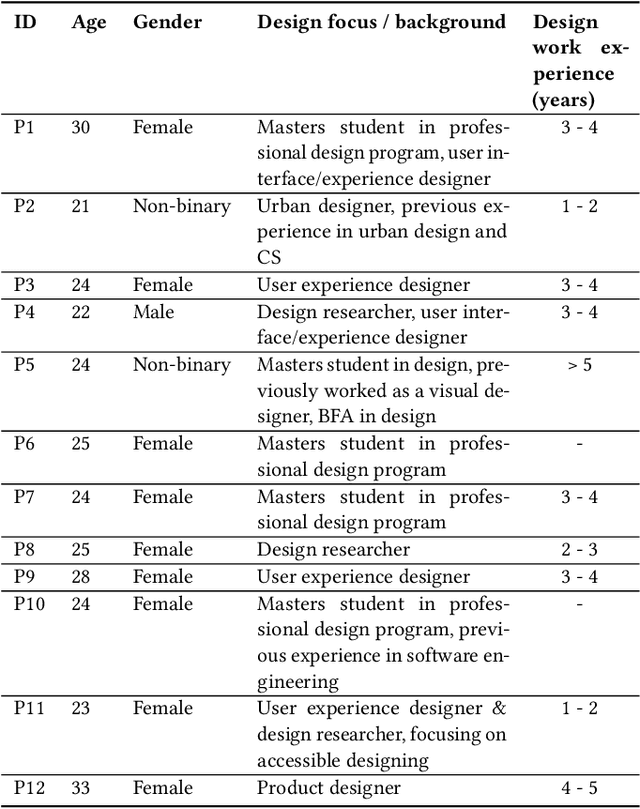
Communicating design implications is common within the HCI community when publishing academic papers, yet these papers are rarely read and used by designers. One solution is to use design cards as a form of translational resource that communicates valuable insights from papers in a more digestible and accessible format to assist in design processes. However, creating design cards can be time-consuming, and authors may lack the resources/know-how to produce cards. Through an iterative design process, we built a system that helps create design cards from academic papers using an LLM and text-to-image model. Our evaluation with designers (N=21) and authors of selected papers (N=12) revealed that designers perceived the design implications from our design cards as more inspiring and generative, compared to reading original paper texts, and the authors viewed our system as an effective way of communicating their design implications. We also propose future enhancements for AI-generated design cards.
Multi-modal Auto-regressive Modeling via Visual Words
Mar 12, 2024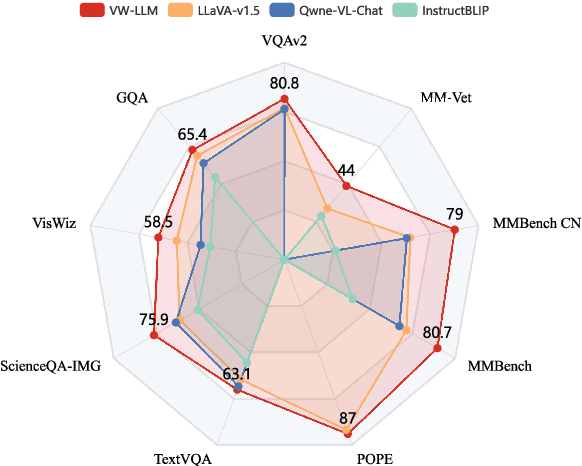
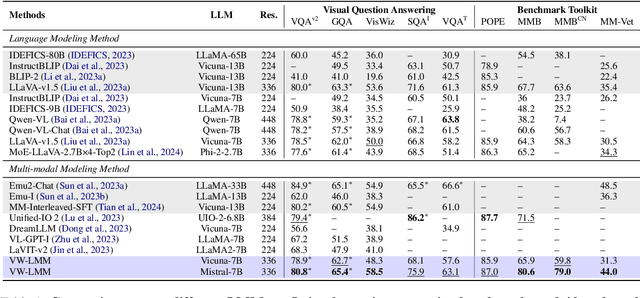


Large Language Models (LLMs), benefiting from the auto-regressive modelling approach performed on massive unannotated texts corpora, demonstrates powerful perceptual and reasoning capabilities. However, as for extending auto-regressive modelling to multi-modal scenarios to build Large Multi-modal Models (LMMs), there lies a great difficulty that the image information is processed in the LMM as continuous visual embeddings, which cannot obtain discrete supervised labels for classification. In this paper, we successfully perform multi-modal auto-regressive modeling with a unified objective for the first time. Specifically, we propose the concept of visual words, which maps the visual features to probability distributions over LLM's vocabulary, providing supervision information for visual modelling. We further explore the distribution of visual features in the semantic space within LMM and the possibility of using text embeddings to represent visual information. Experimental results and ablation studies on 5 VQA tasks and 4 benchmark toolkits validate the powerful performance of our proposed approach.
Evaluating Image Review Ability of Vision Language Models
Feb 19, 2024Large-scale vision language models (LVLMs) are language models that are capable of processing images and text inputs by a single model. This paper explores the use of LVLMs to generate review texts for images. The ability of LVLMs to review images is not fully understood, highlighting the need for a methodical evaluation of their review abilities. Unlike image captions, review texts can be written from various perspectives such as image composition and exposure. This diversity of review perspectives makes it difficult to uniquely determine a single correct review for an image. To address this challenge, we introduce an evaluation method based on rank correlation analysis, in which review texts are ranked by humans and LVLMs, then, measures the correlation between these rankings. We further validate this approach by creating a benchmark dataset aimed at assessing the image review ability of recent LVLMs. Our experiments with the dataset reveal that LVLMs, particularly those with proven superiority in other evaluative contexts, excel at distinguishing between high-quality and substandard image reviews.
From Registration Uncertainty to Segmentation Uncertainty
Mar 08, 2024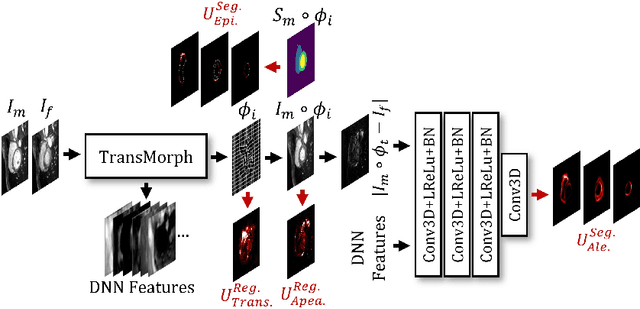
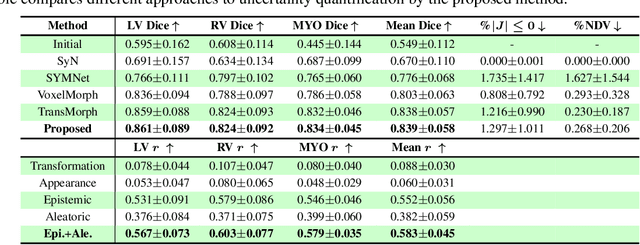
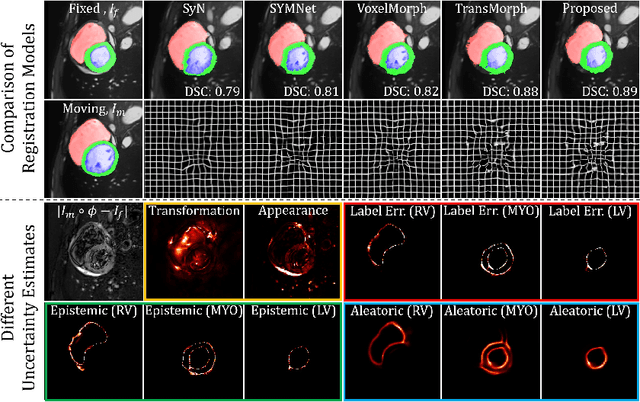
Understanding the uncertainty inherent in deep learning-based image registration models has been an ongoing area of research. Existing methods have been developed to quantify both transformation and appearance uncertainties related to the registration process, elucidating areas where the model may exhibit ambiguity regarding the generated deformation. However, our study reveals that neither uncertainty effectively estimates the potential errors when the registration model is used for label propagation. Here, we propose a novel framework to concurrently estimate both the epistemic and aleatoric segmentation uncertainties for image registration. To this end, we implement a compact deep neural network (DNN) designed to transform the appearance discrepancy in the warping into aleatoric segmentation uncertainty by minimizing a negative log-likelihood loss function. Furthermore, we present epistemic segmentation uncertainty within the label propagation process as the entropy of the propagated labels. By introducing segmentation uncertainty along with existing methods for estimating registration uncertainty, we offer vital insights into the potential uncertainties at different stages of image registration. We validated our proposed framework using publicly available datasets, and the results prove that the segmentation uncertainties estimated with the proposed method correlate well with errors in label propagation, all while achieving superior registration performance.
BEV2PR: BEV-Enhanced Visual Place Recognition with Structural Cues
Mar 11, 2024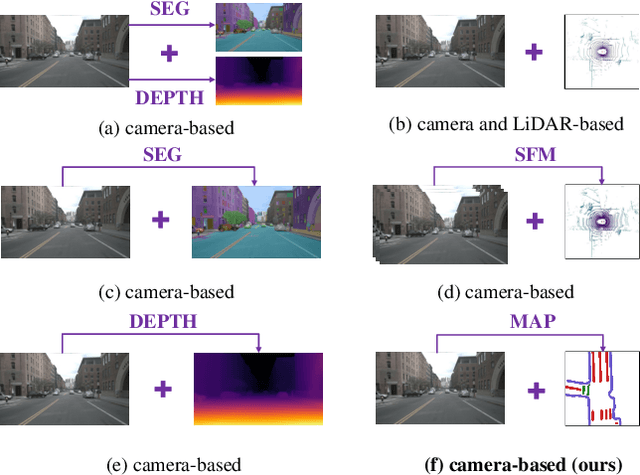
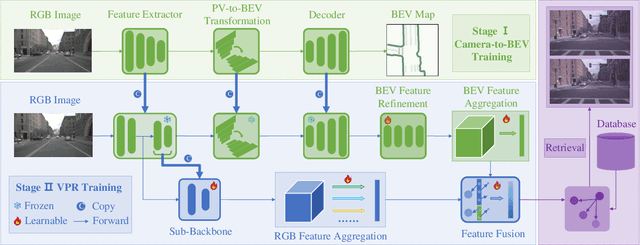

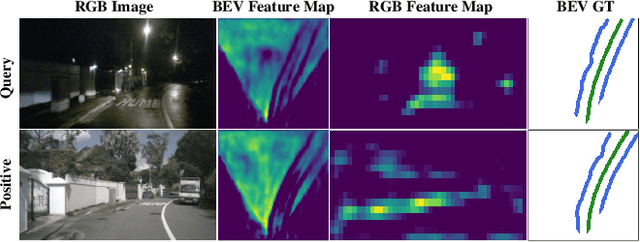
In this paper, we propose a new image-based visual place recognition (VPR) framework by exploiting the structural cues in bird's-eye view (BEV) from a single monocular camera. The motivation arises from two key observations about VPR: 1) For the methods based on both camera and LiDAR sensors, the integration of LiDAR in robotic systems has led to increased expenses, while the alignment of data between different sensors is also a major challenge. 2) Other image-/camera-based methods, involving integrating RGB images and their derived variants (e.g., pseudo depth images, pseudo 3D point clouds), exhibit several limitations, such as the failure to effectively exploit the explicit spatial relationships between different objects. To tackle the above issues, we design a new BEV-enhanced VPR framework, nemely BEV2PR, which can generate a composite descriptor with both visual cues and spatial awareness solely based on a single camera. For the visual cues, any popular aggregation module for RGB global features can be integrated into our framework. The key points lie in: 1) We use BEV segmentation features as an explicit source of structural knowledge in constructing global features. 2) The lower layers of the pre-trained backbone from BEV map generation are shared for visual and structural streams in VPR, facilitating the learning of fine-grained local features in the visual stream. 3) The complementary visual features and structural features can jointly enhance VPR performance. Our BEV2PR framework enables consistent performance improvements over several popular camera-based VPR aggregation modules when integrating them. The experiments on our collected VPR-NuScenes dataset demonstrate an absolute gain of 2.47% on Recall@1 for the strong Conv-AP baseline to achieve the best performance in our setting, and notably, a 18.06% gain on the hard set.
FriendNet: Detection-Friendly Dehazing Network
Mar 07, 2024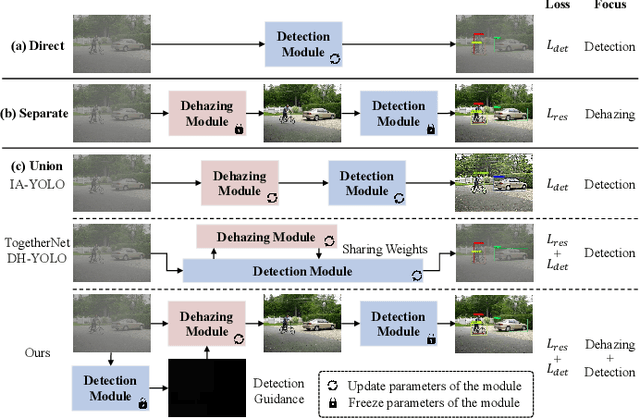
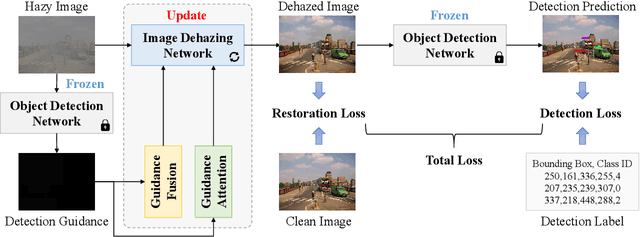
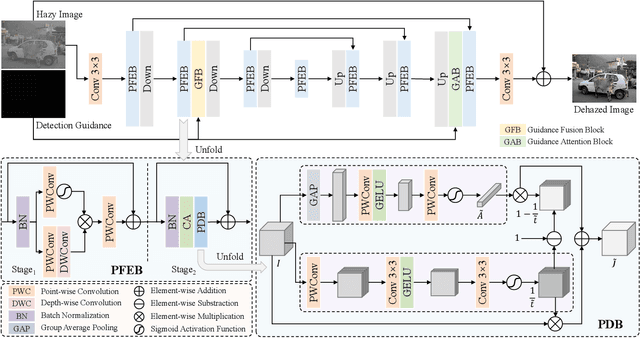
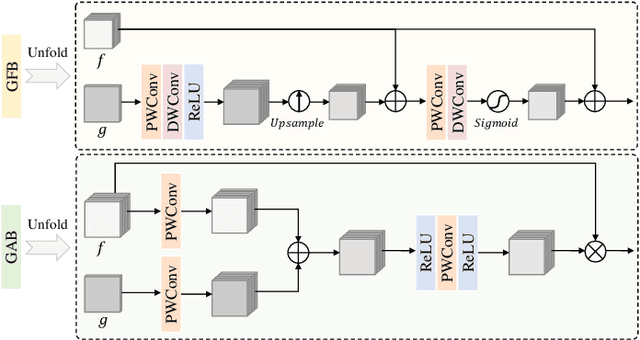
Adverse weather conditions often impair the quality of captured images, inevitably inducing cutting-edge object detection models for advanced driver assistance systems (ADAS) and autonomous driving. In this paper, we raise an intriguing question: can the combination of image restoration and object detection enhance detection performance in adverse weather conditions? To answer it, we propose an effective architecture that bridges image dehazing and object detection together via guidance information and task-driven learning to achieve detection-friendly dehazing, termed FriendNet. FriendNet aims to deliver both high-quality perception and high detection capacity. Different from existing efforts that intuitively treat image dehazing as pre-processing, FriendNet establishes a positive correlation between these two tasks. Clean features generated by the dehazing network potentially contribute to improvements in object detection performance. Conversely, object detection crucially guides the learning process of the image dehazing network under the task-driven learning scheme. We shed light on how downstream tasks can guide upstream dehazing processes, considering both network architecture and learning objectives. We design Guidance Fusion Block (GFB) and Guidance Attention Block (GAB) to facilitate the integration of detection information into the network. Furthermore, the incorporation of the detection task loss aids in refining the optimization process. Additionally, we introduce a new Physics-aware Feature Enhancement Block (PFEB), which integrates physics-based priors to enhance the feature extraction and representation capabilities. Extensive experiments on synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art methods on both image quality and detection precision. Our source code is available at https://github.com/fanyihua0309/FriendNet.
PFStorer: Personalized Face Restoration and Super-Resolution
Mar 13, 2024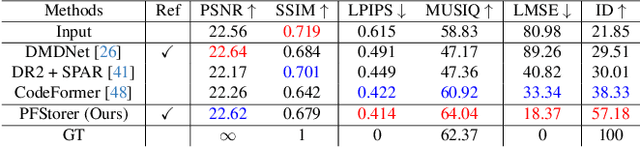
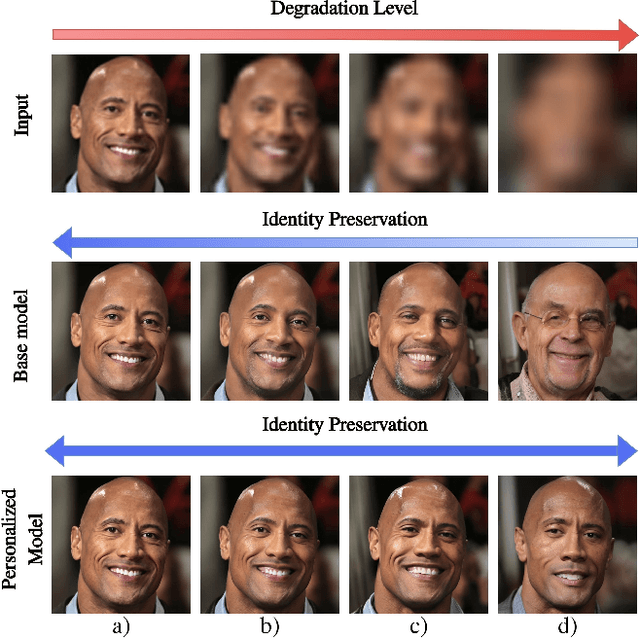
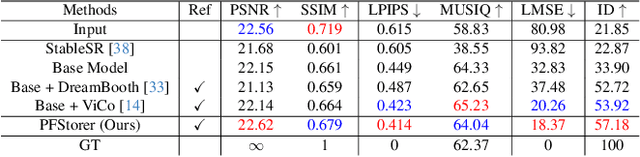
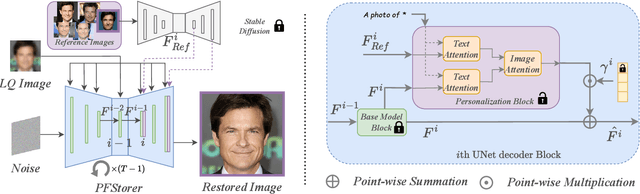
Recent developments in face restoration have achieved remarkable results in producing high-quality and lifelike outputs. The stunning results however often fail to be faithful with respect to the identity of the person as the models lack necessary context. In this paper, we explore the potential of personalized face restoration with diffusion models. In our approach a restoration model is personalized using a few images of the identity, leading to tailored restoration with respect to the identity while retaining fine-grained details. By using independent trainable blocks for personalization, the rich prior of a base restoration model can be exploited to its fullest. To avoid the model relying on parts of identity left in the conditioning low-quality images, a generative regularizer is employed. With a learnable parameter, the model learns to balance between the details generated based on the input image and the degree of personalization. Moreover, we improve the training pipeline of face restoration models to enable an alignment-free approach. We showcase the robust capabilities of our approach in several real-world scenarios with multiple identities, demonstrating our method's ability to generate fine-grained details with faithful restoration. In the user study we evaluate the perceptual quality and faithfulness of the genereated details, with our method being voted best 61% of the time compared to the second best with 25% of the votes.
When can we Approximate Wide Contrastive Models with Neural Tangent Kernels and Principal Component Analysis?
Mar 13, 2024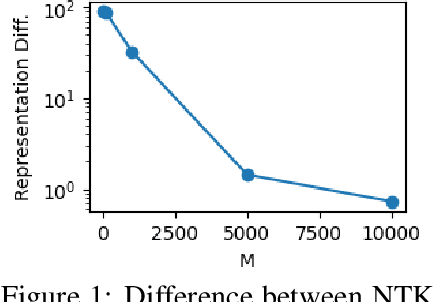
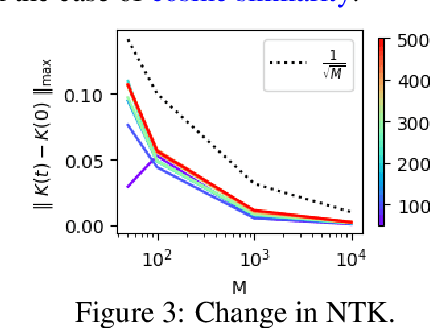


Contrastive learning is a paradigm for learning representations from unlabelled data that has been highly successful for image and text data. Several recent works have examined contrastive losses to claim that contrastive models effectively learn spectral embeddings, while few works show relations between (wide) contrastive models and kernel principal component analysis (PCA). However, it is not known if trained contrastive models indeed correspond to kernel methods or PCA. In this work, we analyze the training dynamics of two-layer contrastive models, with non-linear activation, and answer when these models are close to PCA or kernel methods. It is well known in the supervised setting that neural networks are equivalent to neural tangent kernel (NTK) machines, and that the NTK of infinitely wide networks remains constant during training. We provide the first convergence results of NTK for contrastive losses, and present a nuanced picture: NTK of wide networks remains almost constant for cosine similarity based contrastive losses, but not for losses based on dot product similarity. We further study the training dynamics of contrastive models with orthogonality constraints on output layer, which is implicitly assumed in works relating contrastive learning to spectral embedding. Our deviation bounds suggest that representations learned by contrastive models are close to the principal components of a certain matrix computed from random features. We empirically show that our theoretical results possibly hold beyond two-layer networks.
Task Specific Pretraining with Noisy Labels for Remote sensing Image Segmentation
Feb 25, 2024In recent years, self-supervision has drawn a lot of attention in remote sensing society due to its ability to reduce the demand of exact labels in supervised deep learning model training. Self-supervision methods generally utilize image-level information to pretrain models in an unsupervised fashion. Though these pretrained encoders show effectiveness in many downstream tasks, their performance on segmentation tasks is often not as good as that on classification tasks. On the other hand, many easily available label sources (e.g., automatic labeling tools and land cover land use products) exist, which can provide a large amount of noisy labels for segmentation model training. In this work, we propose to explore the under-exploited potential of noisy labels for segmentation task specific pretraining, and exam its robustness when confronted with mismatched categories and different decoders during fine-tuning. Specifically, we inspect the impacts of noisy labels on different layers in supervised model training to serve as the basis of our work. Experiments on two datasets indicate the effectiveness of task specific supervised pretraining with noisy labels. The findings are expected to shed light on new avenues for improving the accuracy and versatility of pretraining strategies for remote sensing image segmentation.