 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilinguality of Large Language Models From a Structural Perspective
Jun 01, 2026Large language models (LLMs) have excelled in processing multiple languages through pre- and post-training on multilingual data, even though English dominates the training data. Prior work focusing on token representations has revealed how those LLMs process non-English text. Although these analyses have provided insightful findings, they fail to capture a structural view, which is an inherent property of language. In this study, we explore the multilinguality of LLMs through representational structural analysis. Our findings reveal that low-resource languages are structurally more different from English than high- and mid-resource languages, and that language-specific post-training alters their structures while preserving inter-language relationships.
Enhancing Factuality through Consensus and Consistency in Summarization Using Minimum Bayes Risk Decoding
May 28, 2026Improving the quality of model-generated summaries, especially factuality, the accuracy of a summary with respect to its source content, remains a challenge. While reranking could select the optimal output from multiple generated candidates, it is limited to only using the source as guidance, resulting in unreliable summaries. To address this limitation, we propose ConSUM that reranks candidate summaries by considering two factors: consistency to the source document and consensus among the other candidates. Consensus is established using Minimum Bayes Risk (MBR) decoding over the set of generated summaries, while ensuring consistency by employing factuality-aware metrics that compare the summary against the source. Rigorous testing demonstrates that our system is competitive with existing methods, with human evaluations further confirming that its generated summaries are preferred over those from other systems. Our code is available at https://github.com/naist-nlp/ConSUM .
Revisiting Non-Verbatim Memorization in Large Language Models: The Role of Entity Surface Forms
Apr 23, 2026Understanding what kinds of factual knowledge large language models (LLMs) memorize is essential for evaluating their reliability and limitations. Entity-based QA is a common framework for analyzing non-verbatim memorization, but typical evaluations query each entity using a single canonical surface form, making it difficult to disentangle fact memorization from access through a particular name. We introduce RedirectQA, an entity-based QA dataset that uses Wikipedia redirect information to associate Wikidata factual triples with categorized surface forms for each entity, including alternative names, abbreviations, spelling variants, and common erroneous forms. Across 13 LLMs, we examine surface-conditioned factual memorization and find that prediction outcomes often change when only the entity surface form changes. This inconsistency is category-dependent: models are more robust to minor orthographic variations than to larger lexical variations such as aliases and abbreviations. Frequency analyses further suggest that both entity- and surface-level frequencies are associated with accuracy, and that entity frequency often contributes beyond surface frequency. Overall, factual memorization appears neither purely surface-specific nor fully surface-invariant, highlighting the importance of surface-form diversity in evaluating non-verbatim memorization.
XQ-MEval: A Dataset with Cross-lingual Parallel Quality for Benchmarking Translation Metrics
Apr 16, 2026Automatic evaluation metrics are essential for building multilingual translation systems. The common practice of evaluating these systems is averaging metric scores across languages, yet this is suspicious since metrics may suffer from cross-lingual scoring bias, where translations of equal quality receive different scores across languages. This problem has not been systematically studied because no benchmark exists that provides parallel-quality instances across languages, and expert annotation is not realistic. In this work, we propose XQ-MEval, a semi-automatically built dataset covering nine translation directions, to benchmark translation metrics. Specifically, we inject MQM-defined errors into gold translations automatically, filter them by native speakers for reliability, and merge errors to generate pseudo translations with controllable quality. These pseudo translations are then paired with corresponding sources and references to form triplets used in assessing the qualities of translation metrics. Using XQ-MEval, our experiments on nine representative metrics reveal the inconsistency between averaging and human judgment and provide the first empirical evidence of cross-lingual scoring bias. Finally, we propose a normalization strategy derived from XQ-MEval that aligns score distributions across languages, improving the fairness and reliability of multilingual metric evaluation.
CArtBench: Evaluating Vision-Language Models on Chinese Art Understanding, Interpretation, and Authenticity
Apr 13, 2026We introduce CARTBENCH, a museum-grounded benchmark for evaluating vision-language models (VLMs) on Chinese artworks beyond short-form recognition and QA. CARTBENCH comprises four subtasks: CURATORQA for evidence-grounded recognition and reasoning, CATALOGCAPTION for structured four-section expert-style appreciation, REINTERPRET for defensible reinterpretation with expert ratings, and CONNOISSEURPAIRS for diagnostic authenticity discrimination under visually similar confounds. CARTBENCH is built by aligning image-bearing Palace Museum objects from Wikidata with authoritative catalog pages, spanning five art categories across multiple dynasties. Across nine representative VLMs, we find that high overall CURATORQA accuracy can mask sharp drops on hard evidence linking and style-to-period inference; long-form appreciation remains far from expert references; and authenticity-oriented diagnostic discrimination stays near chance, underscoring the difficulty of connoisseur-level reasoning for current models.
Identifying Influential N-grams in Confidence Calibration via Regression Analysis
Apr 07, 2026While large language models (LLMs) improve performance by explicit reasoning, their responses are often overconfident, even though they include linguistic expressions demonstrating uncertainty. In this work, we identify what linguistic expressions are related to confidence by applying the regression method. Specifically, we predict confidence of those linguistic expressions in the reasoning parts of LLMs as the dependent variables and analyze the relationship between a specific $n$-gram and confidence. Across multiple models and QA benchmarks, we show that LLMs remain overconfident when reasoning is involved and attribute this behavior to specific linguistic information. Interestingly, several of the extracted expressions coincide with cue phrases intentionally inserted on test-time scaling to improve reasoning performance. Through our test on causality and verification that the extracted linguistic information truly affects confidence, we reveal that confidence calibration is possible by simply suppressing those overconfident expressions without drops in performance.
HalluCitation Matters: Revealing the Impact of Hallucinated References with 300 Hallucinated Papers in ACL Conferences
Jan 26, 2026Recently, we have often observed hallucinated citations or references that do not correspond to any existing work in papers under review, preprints, or published papers. Such hallucinated citations pose a serious concern to scientific reliability. When they appear in accepted papers, they may also negatively affect the credibility of conferences. In this study, we refer to hallucinated citations as "HalluCitation" and systematically investigate their prevalence and impact. We analyze all papers published at ACL, NAACL, and EMNLP in 2024 and 2025, including main conference, Findings, and workshop papers. Our analysis reveals that nearly 300 papers contain at least one HalluCitation, most of which were published in 2025. Notably, half of these papers were identified at EMNLP 2025, the most recent conference, indicating that this issue is rapidly increasing. Moreover, more than 100 such papers were accepted as main conference and Findings papers at EMNLP 2025, affecting the credibility.
Who Laughs with Whom? Disentangling Influential Factors in Humor Preferences across User Clusters and LLMs
Jan 06, 2026Humor preferences vary widely across individuals and cultures, complicating the evaluation of humor using large language models (LLMs). In this study, we model heterogeneity in humor preferences in Oogiri, a Japanese creative response game, by clustering users with voting logs and estimating cluster-specific weights over interpretable preference factors using Bradley-Terry-Luce models. We elicit preference judgments from LLMs by prompting them to select the funnier response and found that user clusters exhibit distinct preference patterns and that the LLM results can resemble those of particular clusters. Finally, we demonstrate that, by persona prompting, LLM preferences can be directed toward a specific cluster. The scripts for data collection and analysis will be released to support reproducibility.
Routing by Analogy: kNN-Augmented Expert Assignment for Mixture-of-Experts
Jan 05, 2026Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric "router" to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning.
Oogiri-Master: Benchmarking Humor Understanding via Oogiri
Dec 25, 2025
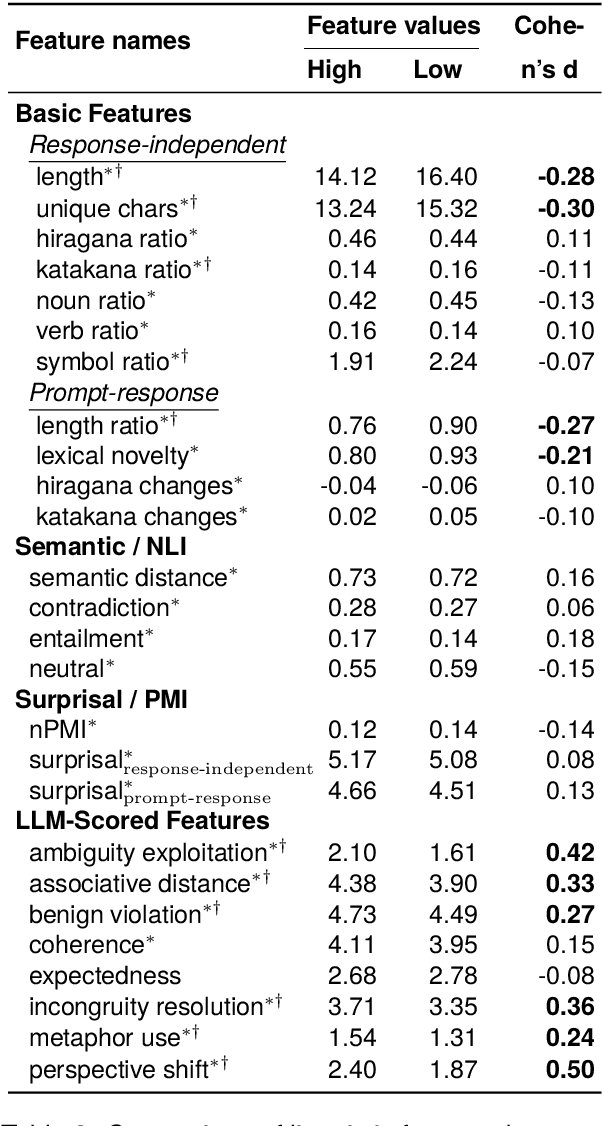

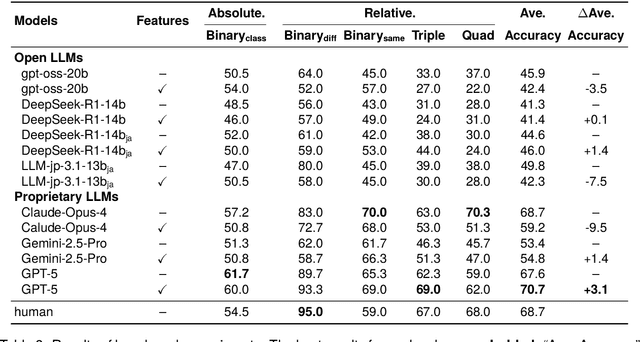
Humor is a salient testbed for human-like creative thinking in large language models (LLMs). We study humor using the Japanese creative response game Oogiri, in which participants produce witty responses to a given prompt, and ask the following research question: What makes such responses funny to humans? Previous work has offered only limited reliable means to answer this question. Existing datasets contain few candidate responses per prompt, expose popularity signals during ratings, and lack objective and comparable metrics for funniness. Thus, we introduce Oogiri-Master and Oogiri-Corpus, which are a benchmark and dataset designed to enable rigorous evaluation of humor understanding in LLMs. Each prompt is paired with approximately 100 diverse candidate responses, and funniness is rated independently by approximately 100 human judges without access to others' ratings, reducing popularity bias and enabling robust aggregation. Using Oogiri-Corpus, we conduct a quantitative analysis of the linguistic factors associated with funniness, such as text length, ambiguity, and incongruity resolution, and derive objective metrics for predicting human judgments. Subsequently, we benchmark a range of LLMs and human baselines in Oogiri-Master, demonstrating that state-of-the-art models approach human performance and that insight-augmented prompting improves the model performance. Our results provide a principled basis for evaluating and advancing humor understanding in LLMs.