 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cloud gap-filling with deep learning for improved grassland monitoring
Mar 14, 2024
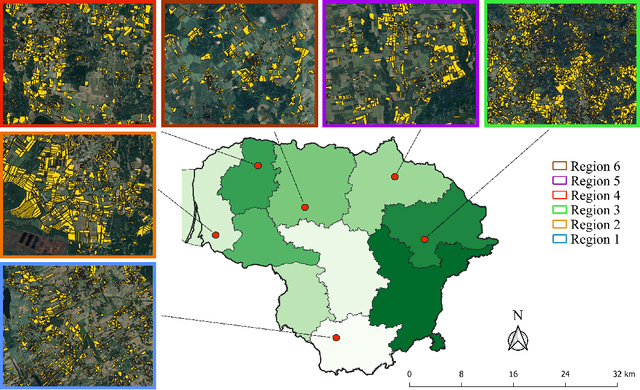
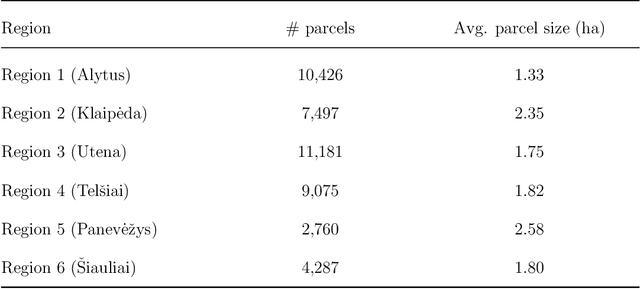

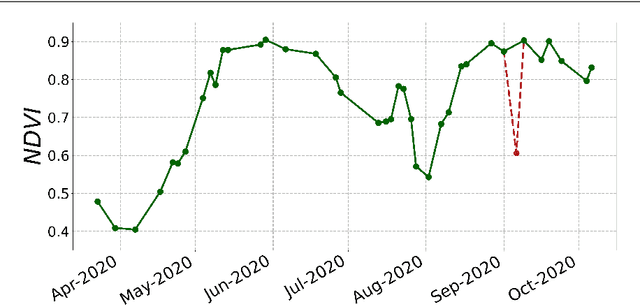
Uninterrupted optical image time series are crucial for the timely monitoring of agricultural land changes. However, the continuity of such time series is often disrupted by clouds. In response to this challenge, we propose a deep learning method that integrates cloud-free optical (Sentinel-2) observations and weather-independent (Sentinel-1) Synthetic Aperture Radar (SAR) data, using a combined Convolutional Neural Network (CNN)-Recurrent Neural Network (RNN) architecture to generate continuous Normalized Difference Vegetation Index (NDVI) time series. We emphasize the significance of observation continuity by assessing the impact of the generated time series on the detection of grassland mowing events. We focus on Lithuania, a country characterized by extensive cloud coverage, and compare our approach with alternative interpolation techniques (i.e., linear, Akima, quadratic). Our method surpasses these techniques, with an average MAE of 0.024 and R^2 of 0.92. It not only improves the accuracy of event detection tasks by employing a continuous time series, but also effectively filters out sudden shifts and noise originating from cloudy observations that cloud masks often fail to detect.
Unleashing Network Potentials for Semantic Scene Completion
Mar 14, 2024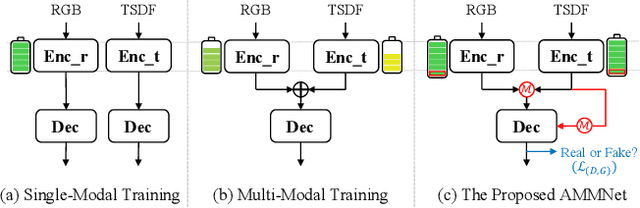
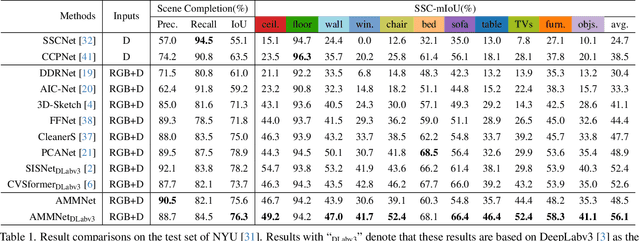
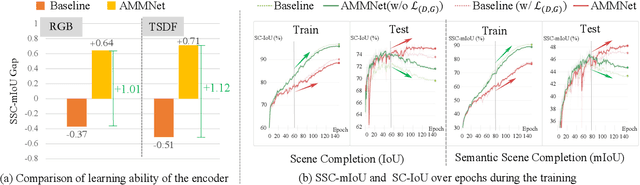
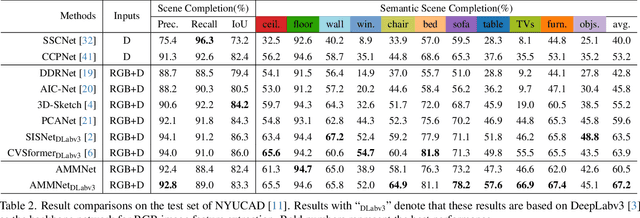
Semantic scene completion (SSC) aims to predict complete 3D voxel occupancy and semantics from a single-view RGB-D image, and recent SSC methods commonly adopt multi-modal inputs. However, our investigation reveals two limitations: ineffective feature learning from single modalities and overfitting to limited datasets. To address these issues, this paper proposes a novel SSC framework - Adversarial Modality Modulation Network (AMMNet) - with a fresh perspective of optimizing gradient updates. The proposed AMMNet introduces two core modules: a cross-modal modulation enabling the interdependence of gradient flows between modalities, and a customized adversarial training scheme leveraging dynamic gradient competition. Specifically, the cross-modal modulation adaptively re-calibrates the features to better excite representation potentials from each single modality. The adversarial training employs a minimax game of evolving gradients, with customized guidance to strengthen the generator's perception of visual fidelity from both geometric completeness and semantic correctness. Extensive experimental results demonstrate that AMMNet outperforms state-of-the-art SSC methods by a large margin, providing a promising direction for improving the effectiveness and generalization of SSC methods.
Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
Mar 15, 2024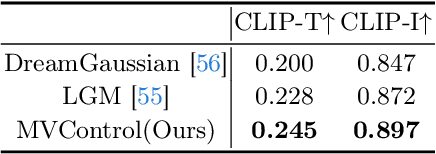
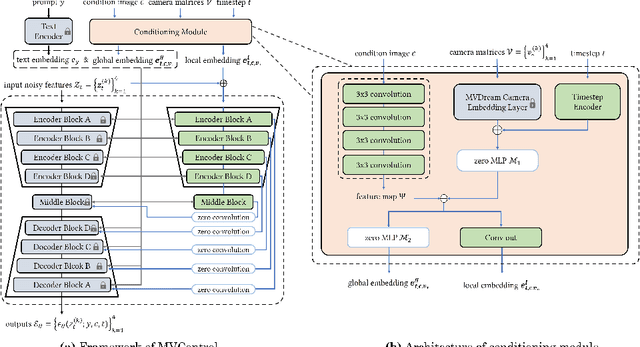
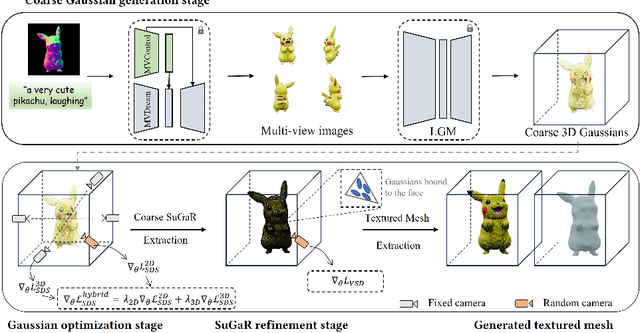

While text-to-3D and image-to-3D generation tasks have received considerable attention, one important but under-explored field between them is controllable text-to-3D generation, which we mainly focus on in this work. To address this task, 1) we introduce Multi-view ControlNet (MVControl), a novel neural network architecture designed to enhance existing pre-trained multi-view diffusion models by integrating additional input conditions, such as edge, depth, normal, and scribble maps. Our innovation lies in the introduction of a conditioning module that controls the base diffusion model using both local and global embeddings, which are computed from the input condition images and camera poses. Once trained, MVControl is able to offer 3D diffusion guidance for optimization-based 3D generation. And, 2) we propose an efficient multi-stage 3D generation pipeline that leverages the benefits of recent large reconstruction models and score distillation algorithm. Building upon our MVControl architecture, we employ a unique hybrid diffusion guidance method to direct the optimization process. In pursuit of efficiency, we adopt 3D Gaussians as our representation instead of the commonly used implicit representations. We also pioneer the use of SuGaR, a hybrid representation that binds Gaussians to mesh triangle faces. This approach alleviates the issue of poor geometry in 3D Gaussians and enables the direct sculpting of fine-grained geometry on the mesh. Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content.
Distributionally Generative Augmentation for Fair Facial Attribute Classification
Mar 11, 2024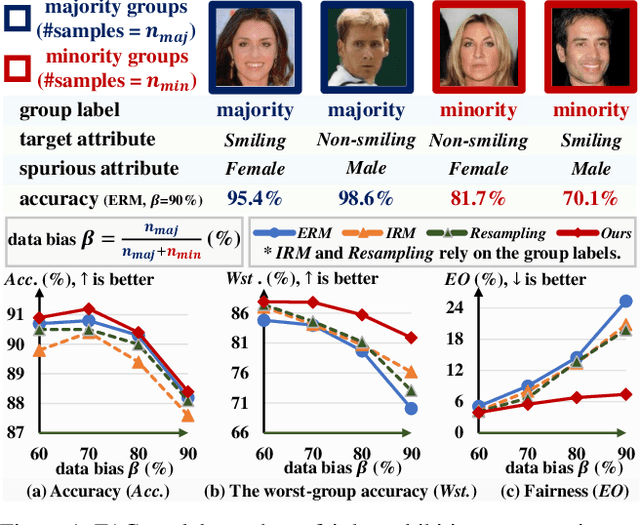
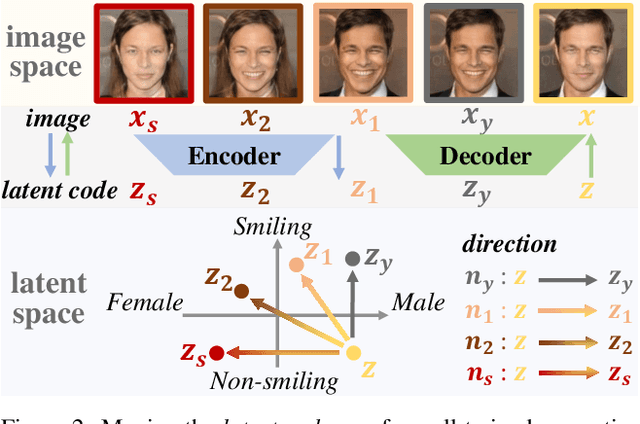

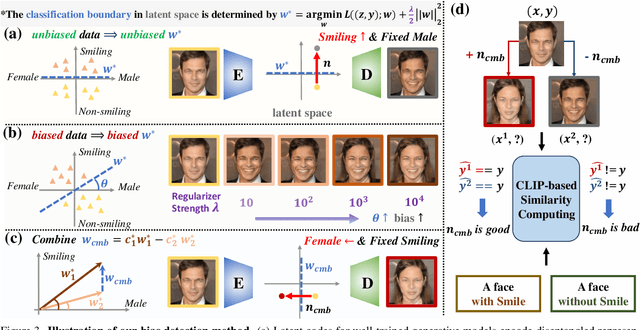
Facial Attribute Classification (FAC) holds substantial promise in widespread applications. However, FAC models trained by traditional methodologies can be unfair by exhibiting accuracy inconsistencies across varied data subpopulations. This unfairness is largely attributed to bias in data, where some spurious attributes (e.g., Male) statistically correlate with the target attribute (e.g., Smiling). Most of existing fairness-aware methods rely on the labels of spurious attributes, which may be unavailable in practice. This work proposes a novel, generation-based two-stage framework to train a fair FAC model on biased data without additional annotation. Initially, we identify the potential spurious attributes based on generative models. Notably, it enhances interpretability by explicitly showing the spurious attributes in image space. Following this, for each image, we first edit the spurious attributes with a random degree sampled from a uniform distribution, while keeping target attribute unchanged. Then we train a fair FAC model by fostering model invariance to these augmentation. Extensive experiments on three common datasets demonstrate the effectiveness of our method in promoting fairness in FAC without compromising accuracy. Codes are in https://github.com/heqianpei/DiGA.
FedLPPA: Learning Personalized Prompt and Aggregation for Federated Weakly-supervised Medical Image Segmentation
Feb 27, 2024Federated learning (FL) effectively mitigates the data silo challenge brought about by policies and privacy concerns, implicitly harnessing more data for deep model training. However, traditional centralized FL models grapple with diverse multi-center data, especially in the face of significant data heterogeneity, notably in medical contexts. In the realm of medical image segmentation, the growing imperative to curtail annotation costs has amplified the importance of weakly-supervised techniques which utilize sparse annotations such as points, scribbles, etc. A pragmatic FL paradigm shall accommodate diverse annotation formats across different sites, which research topic remains under-investigated. In such context, we propose a novel personalized FL framework with learnable prompt and aggregation (FedLPPA) to uniformly leverage heterogeneous weak supervision for medical image segmentation. In FedLPPA, a learnable universal knowledge prompt is maintained, complemented by multiple learnable personalized data distribution prompts and prompts representing the supervision sparsity. Integrated with sample features through a dual-attention mechanism, those prompts empower each local task decoder to adeptly adjust to both the local distribution and the supervision form. Concurrently, a dual-decoder strategy, predicated on prompt similarity, is introduced for enhancing the generation of pseudo-labels in weakly-supervised learning, alleviating overfitting and noise accumulation inherent to local data, while an adaptable aggregation method is employed to customize the task decoder on a parameter-wise basis. Extensive experiments on three distinct medical image segmentation tasks involving different modalities underscore the superiority of FedLPPA, with its efficacy closely parallels that of fully supervised centralized training. Our code and data will be available.
Pix2Gif: Motion-Guided Diffusion for GIF Generation
Mar 08, 2024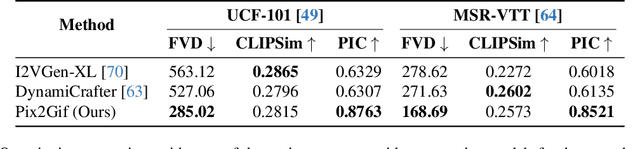
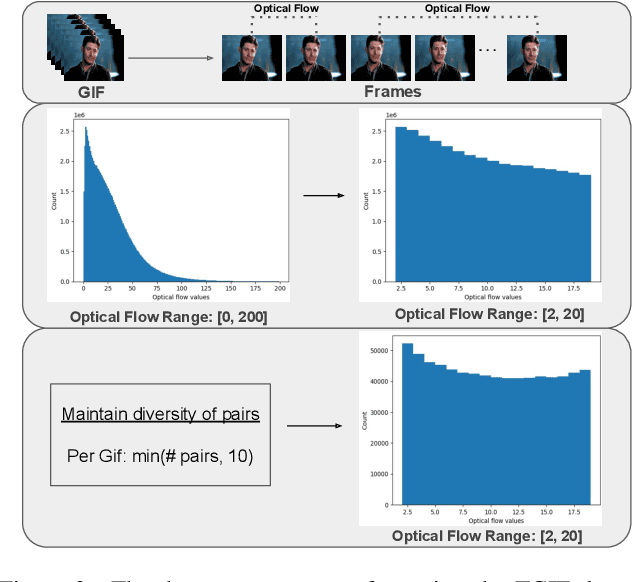
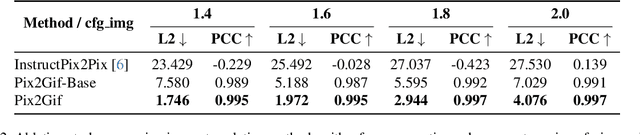

We present Pix2Gif, a motion-guided diffusion model for image-to-GIF (video) generation. We tackle this problem differently by formulating the task as an image translation problem steered by text and motion magnitude prompts, as shown in teaser fig. To ensure that the model adheres to motion guidance, we propose a new motion-guided warping module to spatially transform the features of the source image conditioned on the two types of prompts. Furthermore, we introduce a perceptual loss to ensure the transformed feature map remains within the same space as the target image, ensuring content consistency and coherence. In preparation for the model training, we meticulously curated data by extracting coherent image frames from the TGIF video-caption dataset, which provides rich information about the temporal changes of subjects. After pretraining, we apply our model in a zero-shot manner to a number of video datasets. Extensive qualitative and quantitative experiments demonstrate the effectiveness of our model -- it not only captures the semantic prompt from text but also the spatial ones from motion guidance. We train all our models using a single node of 16xV100 GPUs. Code, dataset and models are made public at: https://hiteshk03.github.io/Pix2Gif/.
SDF2Net: Shallow to Deep Feature Fusion Network for PolSAR Image Classification
Feb 27, 2024Polarimetric synthetic aperture radar (PolSAR) images encompass valuable information that can facilitate extensive land cover interpretation and generate diverse output products. Extracting meaningful features from PolSAR data poses challenges distinct from those encountered in optical imagery. Deep learning (DL) methods offer effective solutions for overcoming these challenges in PolSAR feature extraction. Convolutional neural networks (CNNs) play a crucial role in capturing PolSAR image characteristics by leveraging kernel capabilities to consider local information and the complex-valued nature of PolSAR data. In this study, a novel three-branch fusion of complex-valued CNN, named the Shallow to Deep Feature Fusion Network (SDF2Net), is proposed for PolSAR image classification. To validate the performance of the proposed method, classification results are compared against multiple state-of-the-art approaches using the airborne synthetic aperture radar (AIRSAR) datasets of Flevoland and San Francisco, as well as the ESAR Oberpfaffenhofen dataset. The results indicate that the proposed approach demonstrates improvements in overallaccuracy, with a 1.3% and 0.8% enhancement for the AIRSAR datasets and a 0.5% improvement for the ESAR dataset. Analyses conducted on the Flevoland data underscore the effectiveness of the SDF2Net model, revealing a promising overall accuracy of 96.01% even with only a 1% sampling ratio.
An Analysis of Human Alignment of Latent Diffusion Models
Mar 13, 2024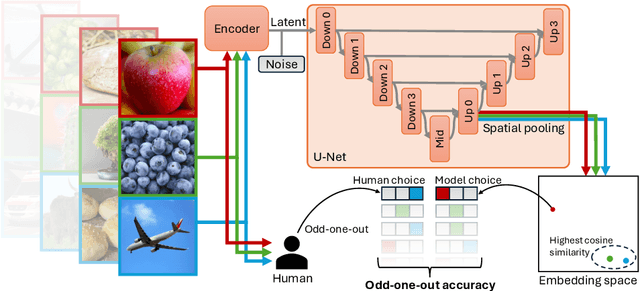
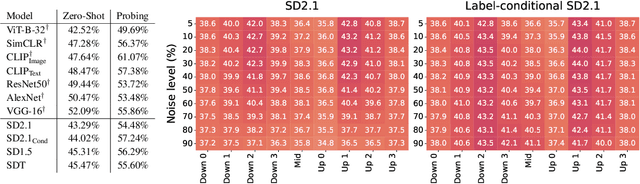
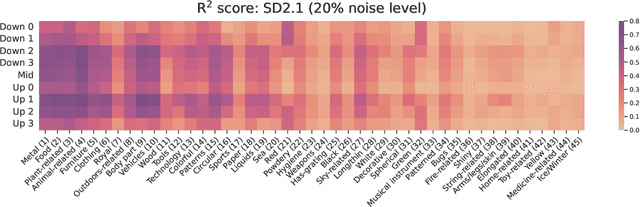
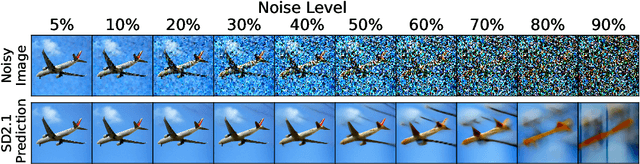
Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.
A Cognitive Evaluation Benchmark of Image Reasoning and Description for Large Vision Language Models
Feb 29, 2024Large Vision Language Models (LVLMs), despite their recent success, are hardly comprehensively tested for their cognitive abilities. Inspired by the prevalent use of the "Cookie Theft" task in human cognition test, we propose a novel evaluation benchmark to evaluate high-level cognitive ability of LVLMs using images with rich semantics. It defines eight reasoning capabilities and consists of an image description task and a visual question answering task. Our evaluation on well-known LVLMs shows that there is still a large gap in cognitive ability between LVLMs and humans.
Frequency Attention for Knowledge Distillation
Mar 09, 2024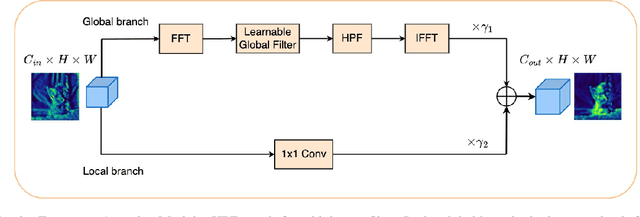
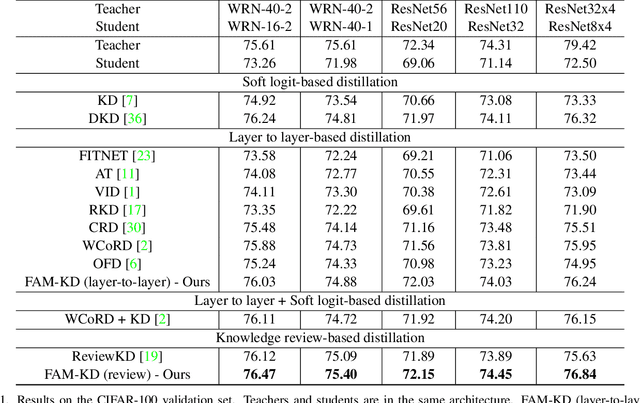
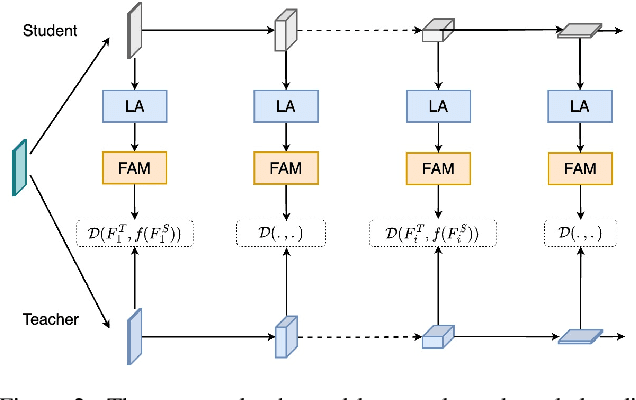
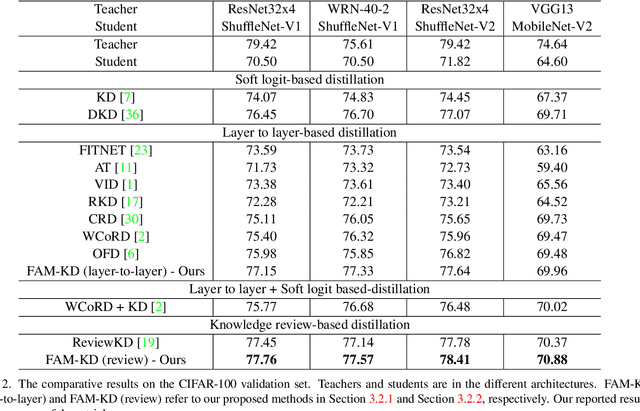
Knowledge distillation is an attractive approach for learning compact deep neural networks, which learns a lightweight student model by distilling knowledge from a complex teacher model. Attention-based knowledge distillation is a specific form of intermediate feature-based knowledge distillation that uses attention mechanisms to encourage the student to better mimic the teacher. However, most of the previous attention-based distillation approaches perform attention in the spatial domain, which primarily affects local regions in the input image. This may not be sufficient when we need to capture the broader context or global information necessary for effective knowledge transfer. In frequency domain, since each frequency is determined from all pixels of the image in spatial domain, it can contain global information about the image. Inspired by the benefits of the frequency domain, we propose a novel module that functions as an attention mechanism in the frequency domain. The module consists of a learnable global filter that can adjust the frequencies of student's features under the guidance of the teacher's features, which encourages the student's features to have patterns similar to the teacher's features. We then propose an enhanced knowledge review-based distillation model by leveraging the proposed frequency attention module. The extensive experiments with various teacher and student architectures on image classification and object detection benchmark datasets show that the proposed approach outperforms other knowledge distillation methods.