 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRISP: Rank-Guided Iterative Squeezing for Robust Medical Image Segmentation under Domain Shift
Apr 07, 2026Distribution shift in medical imaging remains a central bottleneck for the clinical translation of medical AI. Failure to address it can lead to severe performance degradation in unseen environments and exacerbate health inequities. Existing methods for domain adaptation are inherently limited by exhausting predefined possibilities through simulated shifts or pseudo-supervision. Such strategies struggle in the open-ended and unpredictable real world, where distribution shifts are effectively infinite. To address this challenge, we introduce an empirical law called ``Rank Stability of Positive Regions'', which states that the relative rank of predicted probabilities for positive voxels remains stable under distribution shift. Guided by this principle, we propose CRISP, a parameter-free and model-agnostic framework requiring no target-domain information. CRISP is the first framework to make segmentation based on rank rather than probabilities. CRISP simulates model behavior under distribution shift via latent feature perturbation, where voxel probability rankings exhibit two stable patterns: regions that consistently retain high probabilities (destined positives according to the principle) and those that remain low-probability (can be safely classified as negatives). Based on these patterns, we construct high-precision (HP) and high-recall (HR) priors and recursively refine them under perturbation. We then design an iterative training framework, making HP and HR progressively ``squeeze'' to the final segmentation. Extensive evaluations on multi-center cardiac MRI and CT-based lung vessel segmentation demonstrate CRISP's superior robustness, significantly outperforming state-of-the-art methods with striking HD95 reductions of up to 0.14 (7.0\% improvement), 1.90 (13.1\% improvement), and 8.39 (38.9\% improvement) pixels across multi-center, demographic, and modality shifts, respectively.
4DEquine: Disentangling Motion and Appearance for 4D Equine Reconstruction from Monocular Video
Mar 10, 20264D reconstruction of equine family (e.g. horses) from monocular video is important for animal welfare. Previous mainstream 4D animal reconstruction methods require joint optimization of motion and appearance over a whole video, which is time-consuming and sensitive to incomplete observation. In this work, we propose a novel framework called 4DEquine by disentangling the 4D reconstruction problem into two sub-problems: dynamic motion reconstruction and static appearance reconstruction. For motion, we introduce a simple yet effective spatio-temporal transformer with a post-optimization stage to regress smooth and pixel-aligned pose and shape sequences from video. For appearance, we design a novel feed-forward network that reconstructs a high-fidelity, animatable 3D Gaussian avatar from as few as a single image. To assist training, we create a large-scale synthetic motion dataset, VarenPoser, which features high-quality surface motions and diverse camera trajectories, as well as a synthetic appearance dataset, VarenTex, comprising realistic multi-view images generated through multi-view diffusion. While training only on synthetic datasets, 4DEquine achieves state-of-the-art performance on real-world APT36K and AiM datasets, demonstrating the superiority of 4DEquine and our new datasets for both geometry and appearance reconstruction. Comprehensive ablation studies validate the effectiveness of both the motion and appearance reconstruction network. Project page: https://luoxue-star.github.io/4DEquine_Project_Page/.
AniMer+: Unified Pose and Shape Estimation Across Mammalia and Aves via Family-Aware Transformer
Aug 01, 2025In the era of foundation models, achieving a unified understanding of different dynamic objects through a single network has the potential to empower stronger spatial intelligence. Moreover, accurate estimation of animal pose and shape across diverse species is essential for quantitative analysis in biological research. However, this topic remains underexplored due to the limited network capacity of previous methods and the scarcity of comprehensive multi-species datasets. To address these limitations, we introduce AniMer+, an extended version of our scalable AniMer framework. In this paper, we focus on a unified approach for reconstructing mammals (mammalia) and birds (aves). A key innovation of AniMer+ is its high-capacity, family-aware Vision Transformer (ViT) incorporating a Mixture-of-Experts (MoE) design. Its architecture partitions network layers into taxa-specific components (for mammalia and aves) and taxa-shared components, enabling efficient learning of both distinct and common anatomical features within a single model. To overcome the critical shortage of 3D training data, especially for birds, we introduce a diffusion-based conditional image generation pipeline. This pipeline produces two large-scale synthetic datasets: CtrlAni3D for quadrupeds and CtrlAVES3D for birds. To note, CtrlAVES3D is the first large-scale, 3D-annotated dataset for birds, which is crucial for resolving single-view depth ambiguities. Trained on an aggregated collection of 41.3k mammalian and 12.4k avian images (combining real and synthetic data), our method demonstrates superior performance over existing approaches across a wide range of benchmarks, including the challenging out-of-domain Animal Kingdom dataset. Ablation studies confirm the effectiveness of both our novel network architecture and the generated synthetic datasets in enhancing real-world application performance.
Diff4MMLiTS: Advanced Multimodal Liver Tumor Segmentation via Diffusion-Based Image Synthesis and Alignment
Dec 29, 2024



Multimodal learning has been demonstrated to enhance performance across various clinical tasks, owing to the diverse perspectives offered by different modalities of data. However, existing multimodal segmentation methods rely on well-registered multimodal data, which is unrealistic for real-world clinical images, particularly for indistinct and diffuse regions such as liver tumors. In this paper, we introduce Diff4MMLiTS, a four-stage multimodal liver tumor segmentation pipeline: pre-registration of the target organs in multimodal CTs; dilation of the annotated modality's mask and followed by its use in inpainting to obtain multimodal normal CTs without tumors; synthesis of strictly aligned multimodal CTs with tumors using the latent diffusion model based on multimodal CT features and randomly generated tumor masks; and finally, training the segmentation model, thus eliminating the need for strictly aligned multimodal data. Extensive experiments on public and internal datasets demonstrate the superiority of Diff4MMLiTS over other state-of-the-art multimodal segmentation methods.
AniMer: Animal Pose and Shape Estimation Using Family Aware Transformer
Dec 01, 2024



Quantitative analysis of animal behavior and biomechanics requires accurate animal pose and shape estimation across species, and is important for animal welfare and biological research. However, the small network capacity of previous methods and limited multi-species dataset leave this problem underexplored. To this end, this paper presents AniMer to estimate animal pose and shape using family aware Transformer, enhancing the reconstruction accuracy of diverse quadrupedal families. A key insight of AniMer is its integration of a high-capacity Transformer-based backbone and an animal family supervised contrastive learning scheme, unifying the discriminative understanding of various quadrupedal shapes within a single framework. For effective training, we aggregate most available open-sourced quadrupedal datasets, either with 3D or 2D labels. To improve the diversity of 3D labeled data, we introduce CtrlAni3D, a novel large-scale synthetic dataset created through a new diffusion-based conditional image generation pipeline. CtrlAni3D consists of about 10k images with pixel-aligned SMAL labels. In total, we obtain 41.3k annotated images for training and validation. Consequently, the combination of a family aware Transformer network and an expansive dataset enables AniMer to outperform existing methods not only on 3D datasets like Animal3D and CtrlAni3D, but also on out-of-distribution Animal Kingdom dataset. Ablation studies further demonstrate the effectiveness of our network design and CtrlAni3D in enhancing the performance of AniMer for in-the-wild applications. The project page of AniMer is https://luoxue-star.github.io/AniMer_project_page/.
FPT+: A Parameter and Memory Efficient Transfer Learning Method for High-resolution Medical Image Classification
Aug 05, 2024



The success of large-scale pre-trained models has established fine-tuning as a standard method for achieving significant improvements in downstream tasks. However, fine-tuning the entire parameter set of a pre-trained model is costly. Parameter-efficient transfer learning (PETL) has recently emerged as a cost-effective alternative for adapting pre-trained models to downstream tasks. Despite its advantages, the increasing model size and input resolution present challenges for PETL, as the training memory consumption is not reduced as effectively as the parameter usage. In this paper, we introduce Fine-grained Prompt Tuning plus (FPT+), a PETL method designed for high-resolution medical image classification, which significantly reduces memory consumption compared to other PETL methods. FPT+ performs transfer learning by training a lightweight side network and accessing pre-trained knowledge from a large pre-trained model (LPM) through fine-grained prompts and fusion modules. Specifically, we freeze the LPM and construct a learnable lightweight side network. The frozen LPM processes high-resolution images to extract fine-grained features, while the side network employs the corresponding down-sampled low-resolution images to minimize the memory usage. To enable the side network to leverage pre-trained knowledge, we propose fine-grained prompts and fusion modules, which collaborate to summarize information through the LPM's intermediate activations. We evaluate FPT+ on eight medical image datasets of varying sizes, modalities, and complexities. Experimental results demonstrate that FPT+ outperforms other PETL methods, using only 1.03% of the learnable parameters and 3.18% of the memory required for fine-tuning an entire ViT-B model. Our code is available at https://github.com/YijinHuang/FPT.
Saliency-guided and Patch-based Mixup for Long-tailed Skin Cancer Image Classification
Jun 16, 2024



Medical image datasets often exhibit long-tailed distributions due to the inherent challenges in medical data collection and annotation. In long-tailed contexts, some common disease categories account for most of the data, while only a few samples are available in the rare disease categories, resulting in poor performance of deep learning methods. To address this issue, previous approaches have employed class re-sampling or re-weighting techniques, which often encounter challenges such as overfitting to tail classes or difficulties in optimization during training. In this work, we propose a novel approach, namely \textbf{S}aliency-guided and \textbf{P}atch-based \textbf{Mix}up (SPMix) for long-tailed skin cancer image classification. Specifically, given a tail-class image and a head-class image, we generate a new tail-class image by mixing them under the guidance of saliency mapping, which allows for preserving and augmenting the discriminative features of the tail classes without any interference of the head-class features. Extensive experiments are conducted on the ISIC2018 dataset, demonstrating the superiority of SPMix over existing state-of-the-art methods.
FPT: Fine-grained Prompt Tuning for Parameter and Memory Efficient Fine Tuning in High-resolution Medical Image Classification
Mar 12, 2024Parameter-efficient fine-tuning (PEFT) is proposed as a cost-effective way to transfer pre-trained models to downstream tasks, avoiding the high cost of updating entire large-scale pre-trained models (LPMs). In this work, we present Fine-grained Prompt Tuning (FPT), a novel PEFT method for medical image classification. FPT significantly reduces memory consumption compared to other PEFT methods, especially in high-resolution contexts. To achieve this, we first freeze the weights of the LPM and construct a learnable lightweight side network. The frozen LPM takes high-resolution images as input to extract fine-grained features, while the side network is fed low-resolution images to reduce memory usage. To allow the side network to access pre-trained knowledge, we introduce fine-grained prompts that summarize information from the LPM through a fusion module. Important tokens selection and preloading techniques are employed to further reduce training cost and memory requirements. We evaluate FPT on four medical datasets with varying sizes, modalities, and complexities. Experimental results demonstrate that FPT achieves comparable performance to fine-tuning the entire LPM while using only 1.8% of the learnable parameters and 13% of the memory costs of an encoder ViT-B model with a 512 x 512 input resolution.
FedLPPA: Learning Personalized Prompt and Aggregation for Federated Weakly-supervised Medical Image Segmentation
Feb 27, 2024



Federated learning (FL) effectively mitigates the data silo challenge brought about by policies and privacy concerns, implicitly harnessing more data for deep model training. However, traditional centralized FL models grapple with diverse multi-center data, especially in the face of significant data heterogeneity, notably in medical contexts. In the realm of medical image segmentation, the growing imperative to curtail annotation costs has amplified the importance of weakly-supervised techniques which utilize sparse annotations such as points, scribbles, etc. A pragmatic FL paradigm shall accommodate diverse annotation formats across different sites, which research topic remains under-investigated. In such context, we propose a novel personalized FL framework with learnable prompt and aggregation (FedLPPA) to uniformly leverage heterogeneous weak supervision for medical image segmentation. In FedLPPA, a learnable universal knowledge prompt is maintained, complemented by multiple learnable personalized data distribution prompts and prompts representing the supervision sparsity. Integrated with sample features through a dual-attention mechanism, those prompts empower each local task decoder to adeptly adjust to both the local distribution and the supervision form. Concurrently, a dual-decoder strategy, predicated on prompt similarity, is introduced for enhancing the generation of pseudo-labels in weakly-supervised learning, alleviating overfitting and noise accumulation inherent to local data, while an adaptable aggregation method is employed to customize the task decoder on a parameter-wise basis. Extensive experiments on three distinct medical image segmentation tasks involving different modalities underscore the superiority of FedLPPA, with its efficacy closely parallels that of fully supervised centralized training. Our code and data will be available.
ASLseg: Adapting SAM in the Loop for Semi-supervised Liver Tumor Segmentation
Dec 13, 2023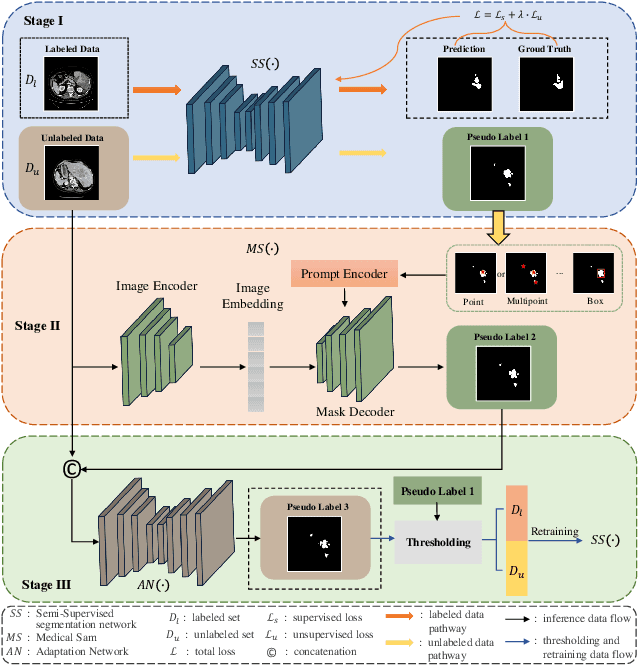
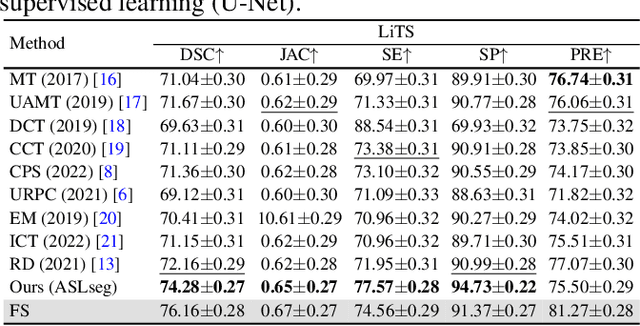
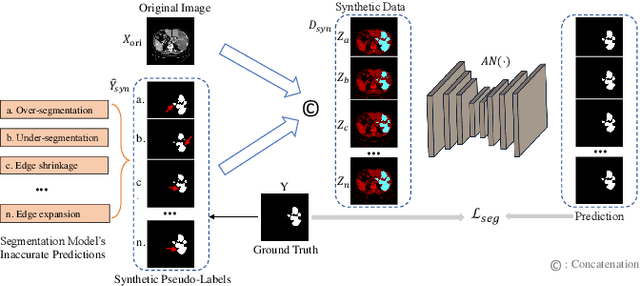
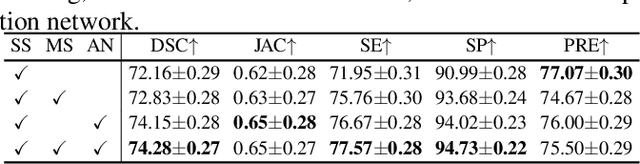
Liver tumor segmentation is essential for computer-aided diagnosis, surgical planning, and prognosis evaluation. However, obtaining and maintaining a large-scale dataset with dense annotations is challenging. Semi-Supervised Learning (SSL) is a common technique to address these challenges. Recently, Segment Anything Model (SAM) has shown promising performance in some medical image segmentation tasks, but it performs poorly for liver tumor segmentation. In this paper, we propose a novel semi-supervised framework, named ASLseg, which can effectively adapt the SAM to the SSL setting and combine both domain-specific and general knowledge of liver tumors. Specifically, the segmentation model trained with a specific SSL paradigm provides the generated pseudo-labels as prompts to the fine-tuned SAM. An adaptation network is then used to refine the SAM-predictions and generate higher-quality pseudo-labels. Finally, the reliable pseudo-labels are selected to expand the labeled set for iterative training. Extensive experiments on the LiTS dataset demonstrate overwhelming performance of our ASLseg.