 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Expediting Large-Scale Vision Transformer for Dense Prediction without Fine-tuning
Oct 03, 2022
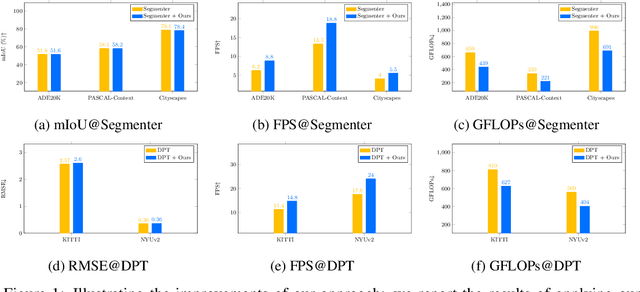

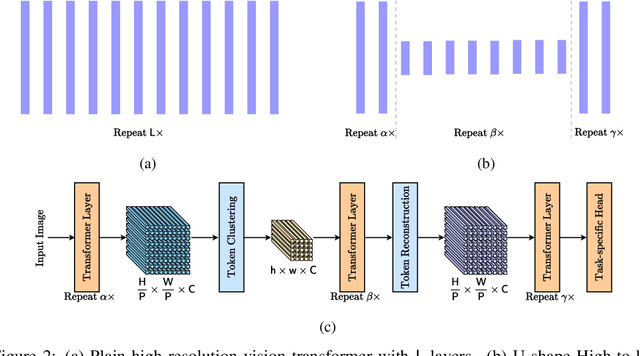
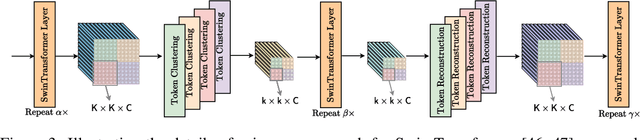
Vision transformers have recently achieved competitive results across various vision tasks but still suffer from heavy computation costs when processing a large number of tokens. Many advanced approaches have been developed to reduce the total number of tokens in large-scale vision transformers, especially for image classification tasks. Typically, they select a small group of essential tokens according to their relevance with the class token, then fine-tune the weights of the vision transformer. Such fine-tuning is less practical for dense prediction due to the much heavier computation and GPU memory cost than image classification. In this paper, we focus on a more challenging problem, i.e., accelerating large-scale vision transformers for dense prediction without any additional re-training or fine-tuning. In response to the fact that high-resolution representations are necessary for dense prediction, we present two non-parametric operators, a token clustering layer to decrease the number of tokens and a token reconstruction layer to increase the number of tokens. The following steps are performed to achieve this: (i) we use the token clustering layer to cluster the neighboring tokens together, resulting in low-resolution representations that maintain the spatial structures; (ii) we apply the following transformer layers only to these low-resolution representations or clustered tokens; and (iii) we use the token reconstruction layer to re-create the high-resolution representations from the refined low-resolution representations. The results obtained by our method are promising on five dense prediction tasks, including object detection, semantic segmentation, panoptic segmentation, instance segmentation, and depth estimation.
KXNet: A Model-Driven Deep Neural Network for Blind Super-Resolution
Sep 22, 2022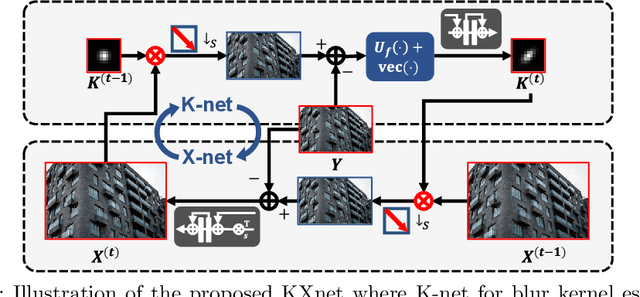
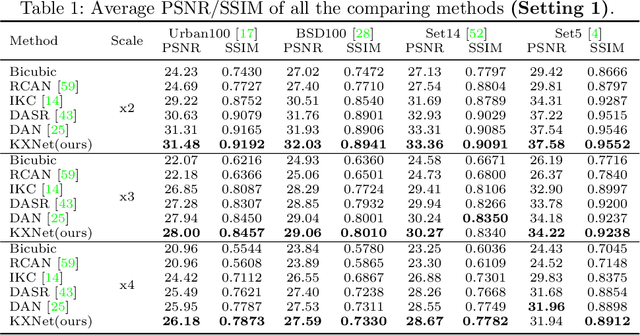
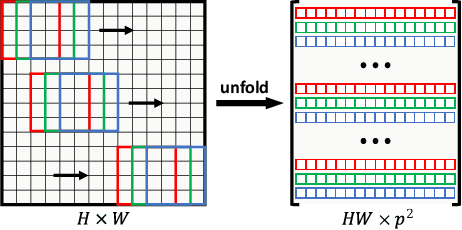
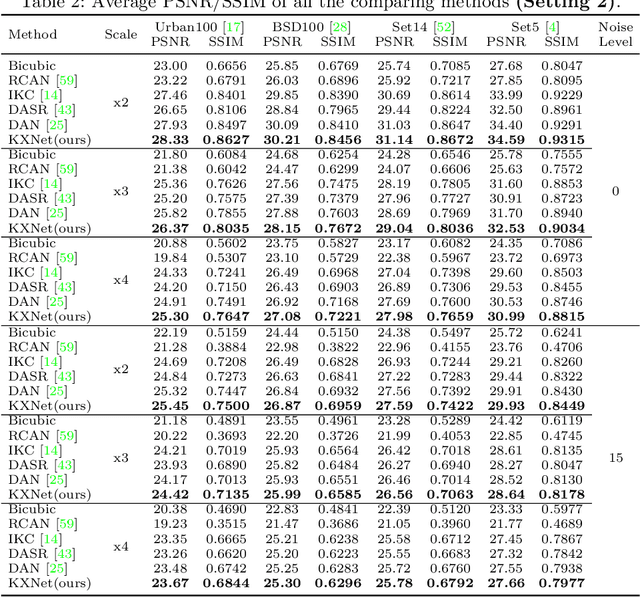
Although current deep learning-based methods have gained promising performance in the blind single image super-resolution (SISR) task, most of them mainly focus on heuristically constructing diverse network architectures and put less emphasis on the explicit embedding of the physical generation mechanism between blur kernels and high-resolution (HR) images. To alleviate this issue, we propose a model-driven deep neural network, called KXNet, for blind SISR. Specifically, to solve the classical SISR model, we propose a simple-yet-effective iterative algorithm. Then by unfolding the involved iterative steps into the corresponding network module, we naturally construct the KXNet. The main specificity of the proposed KXNet is that the entire learning process is fully and explicitly integrated with the inherent physical mechanism underlying this SISR task. Thus, the learned blur kernel has clear physical patterns and the mutually iterative process between blur kernel and HR image can soundly guide the KXNet to be evolved in the right direction. Extensive experiments on synthetic and real data finely demonstrate the superior accuracy and generality of our method beyond the current representative state-of-the-art blind SISR methods. Code is available at: https://github.com/jiahong-fu/KXNet.
Towards End-to-End Image Compression and Analysis with Transformers
Dec 17, 2021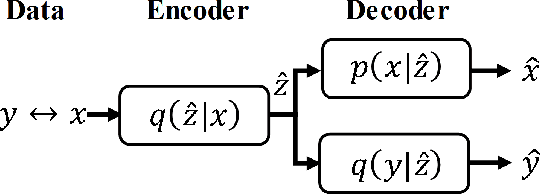
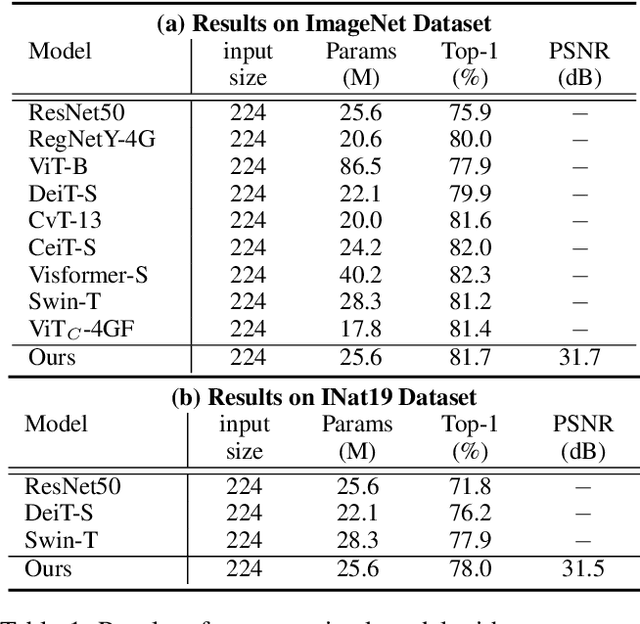
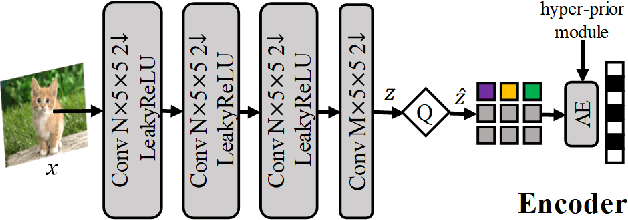
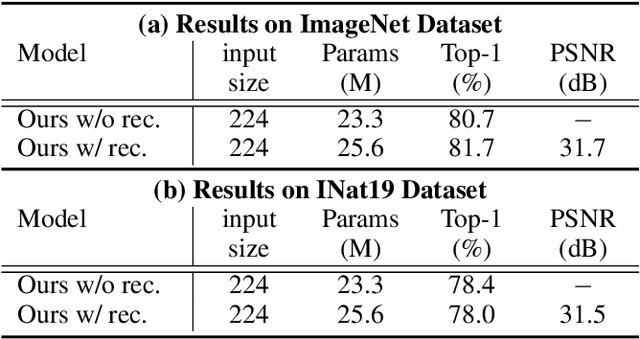
We propose an end-to-end image compression and analysis model with Transformers, targeting to the cloud-based image classification application. Instead of placing an existing Transformer-based image classification model directly after an image codec, we aim to redesign the Vision Transformer (ViT) model to perform image classification from the compressed features and facilitate image compression with the long-term information from the Transformer. Specifically, we first replace the patchify stem (i.e., image splitting and embedding) of the ViT model with a lightweight image encoder modelled by a convolutional neural network. The compressed features generated by the image encoder are injected convolutional inductive bias and are fed to the Transformer for image classification bypassing image reconstruction. Meanwhile, we propose a feature aggregation module to fuse the compressed features with the selected intermediate features of the Transformer, and feed the aggregated features to a deconvolutional neural network for image reconstruction. The aggregated features can obtain the long-term information from the self-attention mechanism of the Transformer and improve the compression performance. The rate-distortion-accuracy optimization problem is finally solved by a two-step training strategy. Experimental results demonstrate the effectiveness of the proposed model in both the image compression and the classification tasks.
Rare Wildlife Recognition with Self-Supervised Representation Learning
Oct 29, 2022

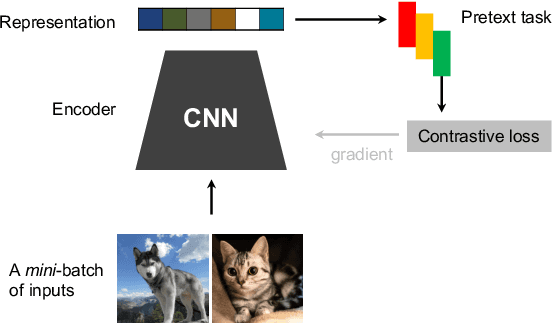
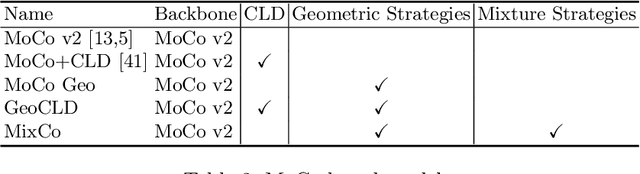
Automated animal censuses with aerial imagery are a vital ingredient towards wildlife conservation. Recent models are generally based on supervised learning and thus require vast amounts of training data. Due to their scarcity and minuscule size, annotating animals in aerial imagery is a highly tedious process. In this project, we present a methodology to reduce the amount of required training data by resorting to self-supervised pretraining. In detail, we examine a combination of recent contrastive learning methodologies like Momentum Contrast (MoCo) and Cross-Level Instance-Group Discrimination (CLD) to condition our model on the aerial images without the requirement for labels. We show that a combination of MoCo, CLD, and geometric augmentations outperforms conventional models pretrained on ImageNet by a large margin. Meanwhile, strategies for smoothing label or prediction distribution in supervised learning have been proven useful in preventing the model from overfitting. We combine the self-supervised contrastive models with image mixup strategies and find that it is useful for learning more robust visual representations. Crucially, our methods still yield favorable results even if we reduce the number of training animals to just 10%, at which point our best model scores double the recall of the baseline at similar precision. This effectively allows reducing the number of required annotations to a fraction while still being able to train high-accuracy models in such highly challenging settings.
Conversion Between CT and MRI Images Using Diffusion and Score-Matching Models
Sep 24, 2022


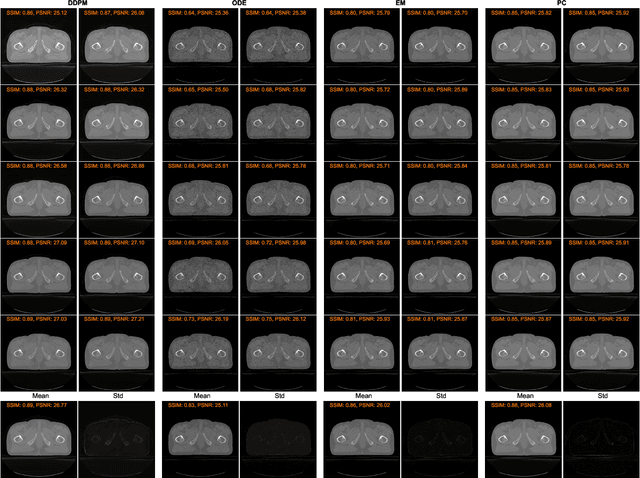
MRI and CT are most widely used medical imaging modalities. It is often necessary to acquire multi-modality images for diagnosis and treatment such as radiotherapy planning. However, multi-modality imaging is not only costly but also introduces misalignment between MRI and CT images. To address this challenge, computational conversion is a viable approach between MRI and CT images, especially from MRI to CT images. In this paper, we propose to use an emerging deep learning framework called diffusion and score-matching models in this context. Specifically, we adapt denoising diffusion probabilistic and score-matching models, use four different sampling strategies, and compare their performance metrics with that using a convolutional neural network and a generative adversarial network model. Our results show that the diffusion and score-matching models generate better synthetic CT images than the CNN and GAN models. Furthermore, we investigate the uncertainties associated with the diffusion and score-matching networks using the Monte-Carlo method, and improve the results by averaging their Monte-Carlo outputs. Our study suggests that diffusion and score-matching models are powerful to generate high quality images conditioned on an image obtained using a complementary imaging modality, analytically rigorous with clear explainability, and highly competitive with CNNs and GANs for image synthesis.
VEViD: Vision Enhancement via Virtual diffraction and coherent Detection
Aug 25, 2022



The history of computing started with analog computers consisting of physical devices performing specialized functions such as predicting the trajectory of cannon balls. In modern times, this idea has been extended, for example, to ultrafast nonlinear optics serving as a surrogate analog computer to probe the behavior of complex phenomena such as rogue waves. Here we discuss a new paradigm where physical phenomena coded as an algorithm perform computational imaging tasks. Specifically, diffraction followed by coherent detection, not in its analog realization but when coded as an algorithm, becomes an image enhancement tool. Vision Enhancement via Virtual diffraction and coherent Detection (VEViD) introduced here reimagines a digital image as a spatially varying metaphoric light field and then subjects the field to the physical processes akin to diffraction and coherent detection. The term "Virtual" captures the deviation from the physical world. The light field is pixelated and the propagation imparts a phase with an arbitrary dependence on frequency which can be different from the quadratic behavior of physical diffraction. Temporal frequencies exist in three bands corresponding to the RGB color channels of a digital image. The phase of the output, not the intensity, represents the output image. VEViD is a high-performance low-light-level and color enhancement tool that emerges from this paradigm. The algorithm is interpretable and computationally efficient. We demonstrate image enhancement of 4k video at 200frames per second and show the utility of this physical algorithm in improving the accuracy of object detection by neural networks without having to retrain model for low-light conditions. The application of VEViD to color enhancement is also demonstrated.
SpeechCLIP: Integrating Speech with Pre-Trained Vision and Language Model
Oct 03, 2022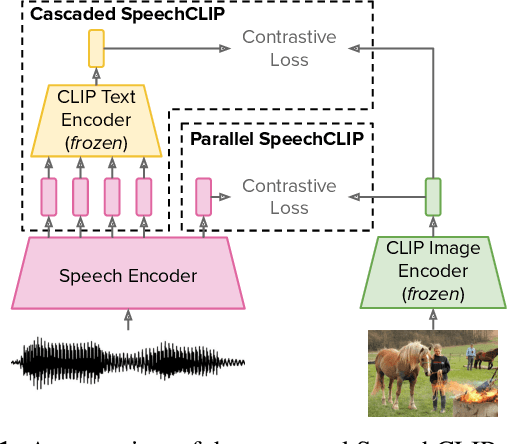

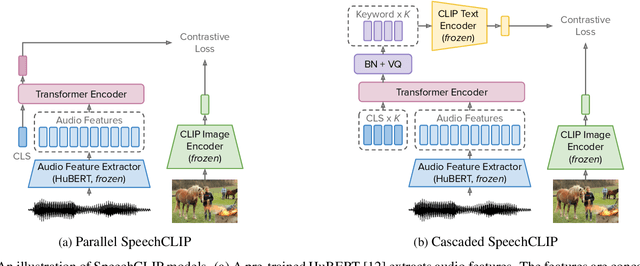
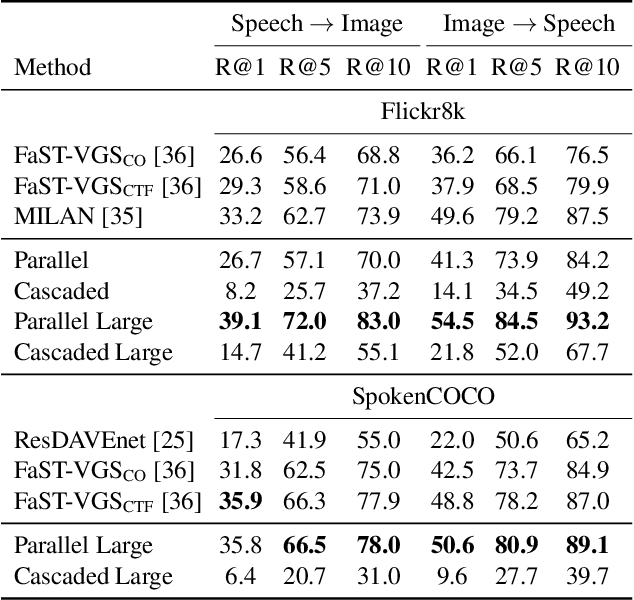
Data-driven speech processing models usually perform well with a large amount of text supervision, but collecting transcribed speech data is costly. Therefore, we propose SpeechCLIP, a novel framework bridging speech and text through images to enhance speech models without transcriptions. We leverage state-of-the-art pre-trained HuBERT and CLIP, aligning them via paired images and spoken captions with minimal fine-tuning. SpeechCLIP outperforms prior state-of-the-art on image-speech retrieval and performs zero-shot speech-text retrieval without direct supervision from transcriptions. Moreover, SpeechCLIP can directly retrieve semantically related keywords from speech.
Improving Image-recognition Edge Caches with a Generative Adversarial Network
Feb 11, 2022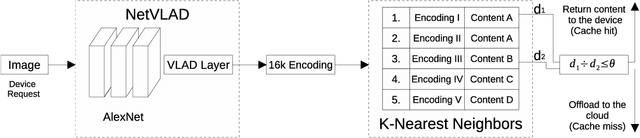
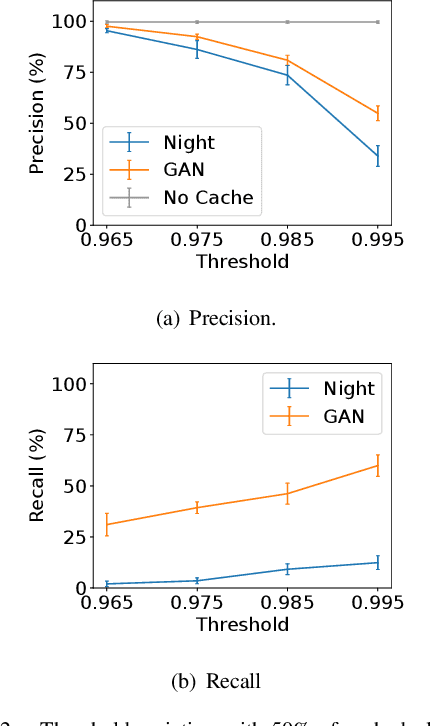
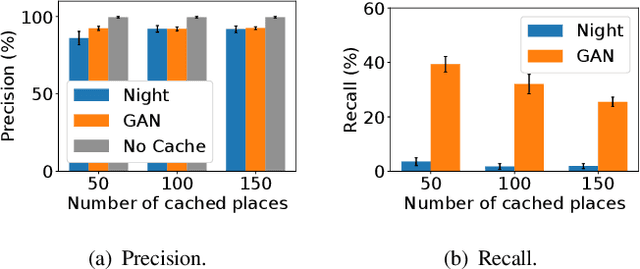
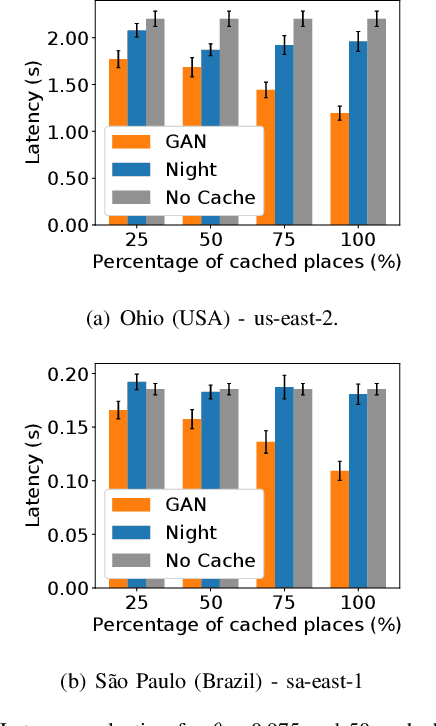
Image recognition is an essential task in several mobile applications. For instance, a smartphone can process a landmark photo to gather more information about its location. If the device does not have enough computational resources available, it offloads the processing task to a cloud infrastructure. Although this approach solves resource shortages, it introduces a communication delay. Image-recognition caches on the Internet's edge can mitigate this problem. These caches run on servers close to mobile devices and stores information about previously recognized images. If the server receives a request with a photo stored in its cache, it replies to the device, avoiding cloud offloading. The main challenge for this cache is to verify if the received image matches a stored one. Furthermore, for outdoor photos, it is difficult to compare them if one was taken in the daytime and the other at nighttime. In that case, the cache might wrongly infer that they refer to different places, offloading the processing to the cloud. This work shows that a well-known generative adversarial network, called ToDayGAN, can solve this problem by generating daytime images using nighttime ones. We can thus use this translation to populate a cache with synthetic photos that can help image matching. We show that our solution reduces cloud offloading and, therefore, the application's latency.
Brain Imaging Generation with Latent Diffusion Models
Sep 15, 2022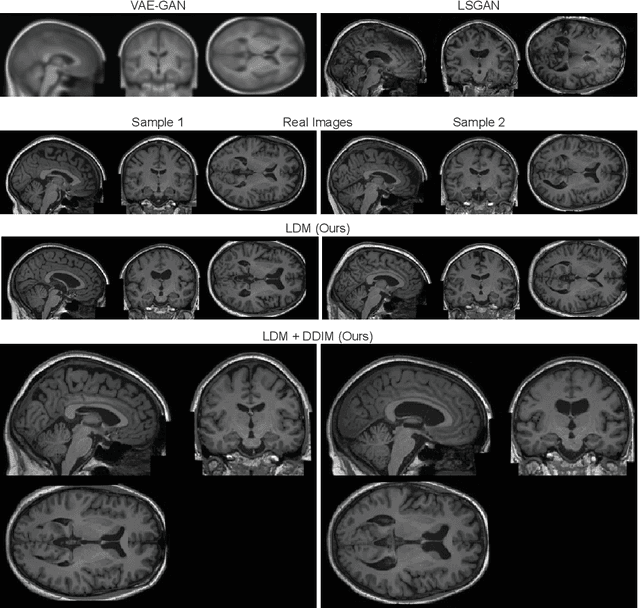
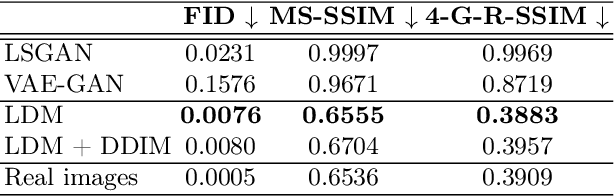
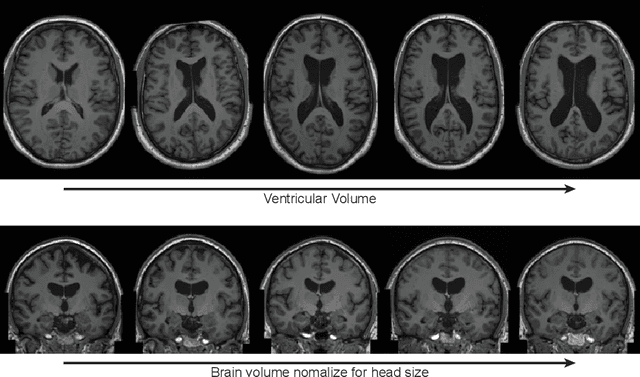
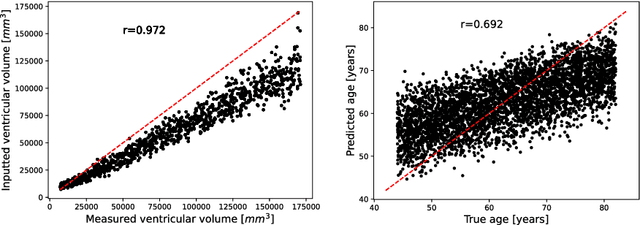
Deep neural networks have brought remarkable breakthroughs in medical image analysis. However, due to their data-hungry nature, the modest dataset sizes in medical imaging projects might be hindering their full potential. Generating synthetic data provides a promising alternative, allowing to complement training datasets and conducting medical image research at a larger scale. Diffusion models recently have caught the attention of the computer vision community by producing photorealistic synthetic images. In this study, we explore using Latent Diffusion Models to generate synthetic images from high-resolution 3D brain images. We used T1w MRI images from the UK Biobank dataset (N=31,740) to train our models to learn about the probabilistic distribution of brain images, conditioned on covariables, such as age, sex, and brain structure volumes. We found that our models created realistic data, and we could use the conditioning variables to control the data generation effectively. Besides that, we created a synthetic dataset with 100,000 brain images and made it openly available to the scientific community.
Adaptive Non-linear Filtering Technique for Image Restoration
Apr 20, 2022
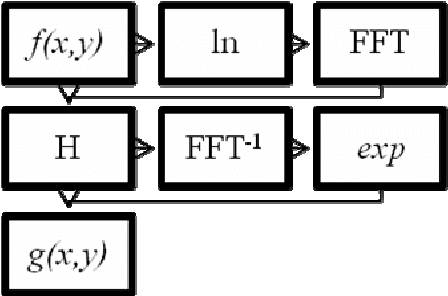
Removing noise from the any processed images is very important. Noise should be removed in such a way that important information of image should be preserved. A decisionbased nonlinear algorithm for elimination of band lines, drop lines, mark, band lost and impulses in images is presented in this paper. The algorithm performs two simultaneous operations, namely, detection of corrupted pixels and evaluation of new pixels for replacing the corrupted pixels. Removal of these artifacts is achieved without damaging edges and details. However, the restricted window size renders median operation less effective whenever noise is excessive in that case the proposed algorithm automatically switches to mean filtering. The performance of the algorithm is analyzed in terms of Mean Square Error [MSE], Peak-Signal-to-Noise Ratio [PSNR], Signal-to-Noise Ratio Improved [SNRI], Percentage Of Noise Attenuated [PONA], and Percentage Of Spoiled Pixels [POSP]. This is compared with standard algorithms already in use and improved performance of the proposed algorithm is presented. The advantage of the proposed algorithm is that a single algorithm can replace several independent algorithms which are required for removal of different artifacts.
* Accepted. arXiv admin note: text overlap with arXiv:1003.1827 by other authors