 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVanilla Group Equivariant Vision Transformer: Simple and Effective
Feb 08, 2026Incorporating symmetry priors as inductive biases to design equivariant Vision Transformers (ViTs) has emerged as a promising avenue for enhancing their performance. However, existing equivariant ViTs often struggle to balance performance with equivariance, primarily due to the challenge of achieving holistic equivariant modifications across the diverse modules in ViTs-particularly in harmonizing the Self-Attention mechanism with Patch Embedding. To address this, we propose a straightforward framework that systematically renders key ViT components, including patch embedding, self-attention, positional encodings, and Down/Up-Sampling, equivariant, thereby constructing ViTs with guaranteed equivariance. The resulting architecture serves as a plug-and-play replacement that is both theoretically grounded and practically versatile, scaling seamlessly even to Swin Transformers. Extensive experiments demonstrate that our equivariant ViTs consistently improve performance and data efficiency across a wide spectrum of vision tasks.
Rotation Equivariant Arbitrary-scale Image Super-Resolution
Aug 07, 2025The arbitrary-scale image super-resolution (ASISR), a recent popular topic in computer vision, aims to achieve arbitrary-scale high-resolution recoveries from a low-resolution input image. This task is realized by representing the image as a continuous implicit function through two fundamental modules, a deep-network-based encoder and an implicit neural representation (INR) module. Despite achieving notable progress, a crucial challenge of such a highly ill-posed setting is that many common geometric patterns, such as repetitive textures, edges, or shapes, are seriously warped and deformed in the low-resolution images, naturally leading to unexpected artifacts appearing in their high-resolution recoveries. Embedding rotation equivariance into the ASISR network is thus necessary, as it has been widely demonstrated that this enhancement enables the recovery to faithfully maintain the original orientations and structural integrity of geometric patterns underlying the input image. Motivated by this, we make efforts to construct a rotation equivariant ASISR method in this study. Specifically, we elaborately redesign the basic architectures of INR and encoder modules, incorporating intrinsic rotation equivariance capabilities beyond those of conventional ASISR networks. Through such amelioration, the ASISR network can, for the first time, be implemented with end-to-end rotational equivariance maintained from input to output. We also provide a solid theoretical analysis to evaluate its intrinsic equivariance error, demonstrating its inherent nature of embedding such an equivariance structure. The superiority of the proposed method is substantiated by experiments conducted on both simulated and real datasets. We also validate that the proposed framework can be readily integrated into current ASISR methods in a plug \& play manner to further enhance their performance.
A Regularization-Guided Equivariant Approach for Image Restoration
May 26, 2025Equivariant and invariant deep learning models have been developed to exploit intrinsic symmetries in data, demonstrating significant effectiveness in certain scenarios. However, these methods often suffer from limited representation accuracy and rely on strict symmetry assumptions that may not hold in practice. These limitations pose a significant drawback for image restoration tasks, which demands high accuracy and precise symmetry representation. To address these challenges, we propose a rotation-equivariant regularization strategy that adaptively enforces the appropriate symmetry constraints on the data while preserving the network's representational accuracy. Specifically, we introduce EQ-Reg, a regularizer designed to enhance rotation equivariance, which innovatively extends the insights of data-augmentation-based and equivariant-based methodologies. This is achieved through self-supervised learning and the spatial rotation and cyclic channel shift of feature maps deduce in the equivariant framework. Our approach firstly enables a non-strictly equivariant network suitable for image restoration, providing a simple and adaptive mechanism for adjusting equivariance based on task. Extensive experiments across three low-level tasks demonstrate the superior accuracy and generalization capability of our method, outperforming state-of-the-art approaches.
Rotation-Equivariant Self-Supervised Method in Image Denoising
May 26, 2025Self-supervised image denoising methods have garnered significant research attention in recent years, for this kind of method reduces the requirement of large training datasets. Compared to supervised methods, self-supervised methods rely more on the prior embedded in deep networks themselves. As a result, most of the self-supervised methods are designed with Convolution Neural Networks (CNNs) architectures, which well capture one of the most important image prior, translation equivariant prior. Inspired by the great success achieved by the introduction of translational equivariance, in this paper, we explore the way to further incorporate another important image prior. Specifically, we first apply high-accuracy rotation equivariant convolution to self-supervised image denoising. Through rigorous theoretical analysis, we have proved that simply replacing all the convolution layers with rotation equivariant convolution layers would modify the network into its rotation equivariant version. To the best of our knowledge, this is the first time that rotation equivariant image prior is introduced to self-supervised image denoising at the network architecture level with a comprehensive theoretical analysis of equivariance errors, which offers a new perspective to the field of self-supervised image denoising. Moreover, to further improve the performance, we design a new mask mechanism to fusion the output of rotation equivariant network and vanilla CNN-based network, and construct an adaptive rotation equivariant framework. Through extensive experiments on three typical methods, we have demonstrated the effectiveness of the proposed method.
Rotation Equivariant Proximal Operator for Deep Unfolding Methods in Image Restoration
Dec 25, 2023



The deep unfolding approach has attracted significant attention in computer vision tasks, which well connects conventional image processing modeling manners with more recent deep learning techniques. Specifically, by establishing a direct correspondence between algorithm operators at each implementation step and network modules within each layer, one can rationally construct an almost ``white box'' network architecture with high interpretability. In this architecture, only the predefined component of the proximal operator, known as a proximal network, needs manual configuration, enabling the network to automatically extract intrinsic image priors in a data-driven manner. In current deep unfolding methods, such a proximal network is generally designed as a CNN architecture, whose necessity has been proven by a recent theory. That is, CNN structure substantially delivers the translational invariant image prior, which is the most universally possessed structural prior across various types of images. However, standard CNN-based proximal networks have essential limitations in capturing the rotation symmetry prior, another universal structural prior underlying general images. This leaves a large room for further performance improvement in deep unfolding approaches. To address this issue, this study makes efforts to suggest a high-accuracy rotation equivariant proximal network that effectively embeds rotation symmetry priors into the deep unfolding framework. Especially, we deduce, for the first time, the theoretical equivariant error for such a designed proximal network with arbitrary layers under arbitrary rotation degrees. This analysis should be the most refined theoretical conclusion for such error evaluation to date and is also indispensable for supporting the rationale behind such networks with intrinsic interpretability requirements.
KXNet: A Model-Driven Deep Neural Network for Blind Super-Resolution
Sep 22, 2022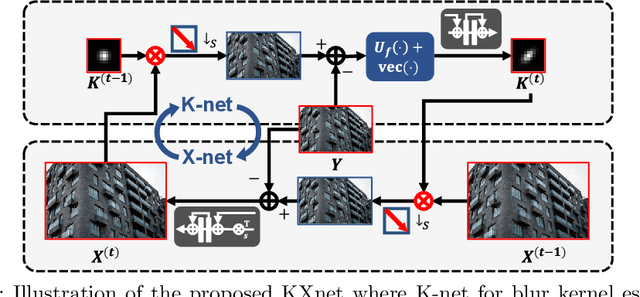
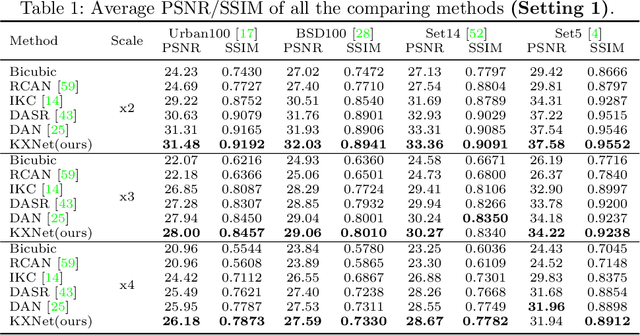
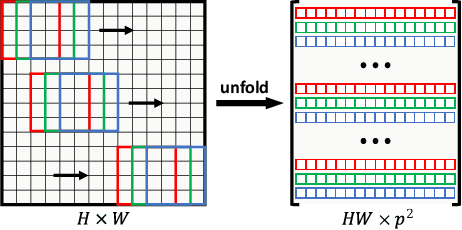
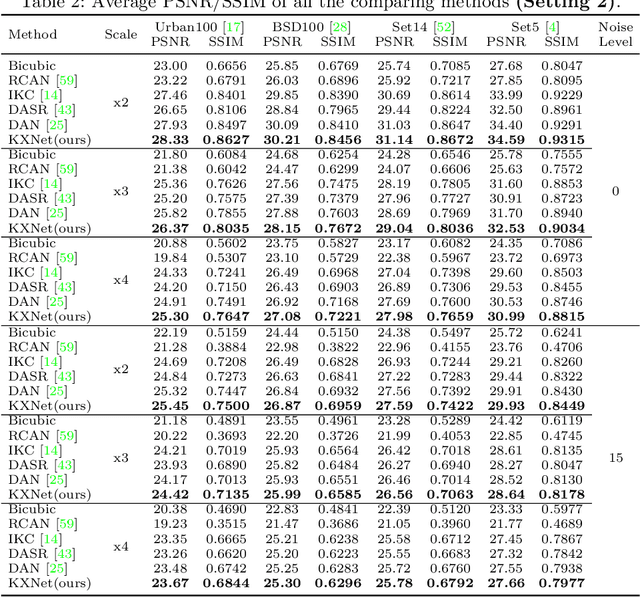
Although current deep learning-based methods have gained promising performance in the blind single image super-resolution (SISR) task, most of them mainly focus on heuristically constructing diverse network architectures and put less emphasis on the explicit embedding of the physical generation mechanism between blur kernels and high-resolution (HR) images. To alleviate this issue, we propose a model-driven deep neural network, called KXNet, for blind SISR. Specifically, to solve the classical SISR model, we propose a simple-yet-effective iterative algorithm. Then by unfolding the involved iterative steps into the corresponding network module, we naturally construct the KXNet. The main specificity of the proposed KXNet is that the entire learning process is fully and explicitly integrated with the inherent physical mechanism underlying this SISR task. Thus, the learned blur kernel has clear physical patterns and the mutually iterative process between blur kernel and HR image can soundly guide the KXNet to be evolved in the right direction. Extensive experiments on synthetic and real data finely demonstrate the superior accuracy and generality of our method beyond the current representative state-of-the-art blind SISR methods. Code is available at: https://github.com/jiahong-fu/KXNet.