 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The transport problem for non-additive measures
Nov 23, 2022
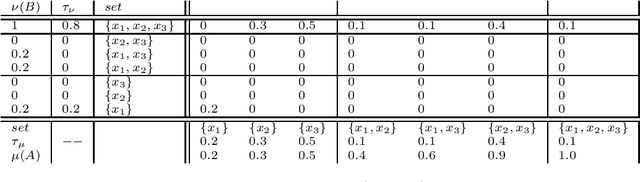
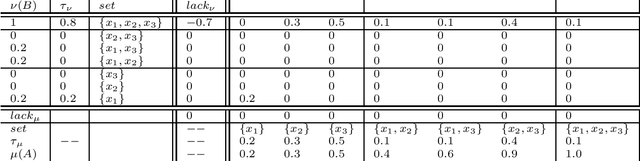
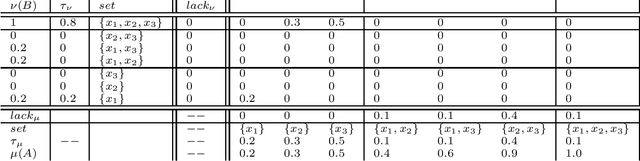

Non-additive measures, also known as fuzzy measures, capacities, and monotonic games, are increasingly used in different fields. Applications have been built within computer science and artificial intelligence related to e.g. decision making, image processing, machine learning for both classification, and regression. Tools for measure identification have been built. In short, as non-additive measures are more general than additive ones (i.e., than probabilities), they have better modeling capabilities allowing to model situations and problems that cannot be modelled by the latter. See e.g. the application of non-additive measures and the Choquet integral to model both Ellsberg paradox and Allais paradox. Because of that, there is an increasing need to analyze non-additive measures. The need for distances and similarities to compare them is no exception. Some work has been done for definining $f$-divergence for them. In this work we tackle the problem of definining the transport problem for non-additive measures, which has not been considered up to our knowledge up to now. Distances for pairs of probability distributions based on the optimal transport are extremely used in practical applications, and they are being studied extensively for the mathematical properties. We consider that it is necessary to provide appropriate definitions with a similar flavour, and that generalize the standard ones, for non-additive measures. We provide definitions based on the M\"obius transform, but also based on the $(\max, +)$-transform that we consider that has some advantages. We will discuss in this paper the problems that arise to define the transport problem for non-additive measures, and discuss ways to solve them. In this paper we provide the definitions of the optimal transport problem, and prove some properties.
RegionCLIP: Region-based Language-Image Pretraining
Dec 16, 2021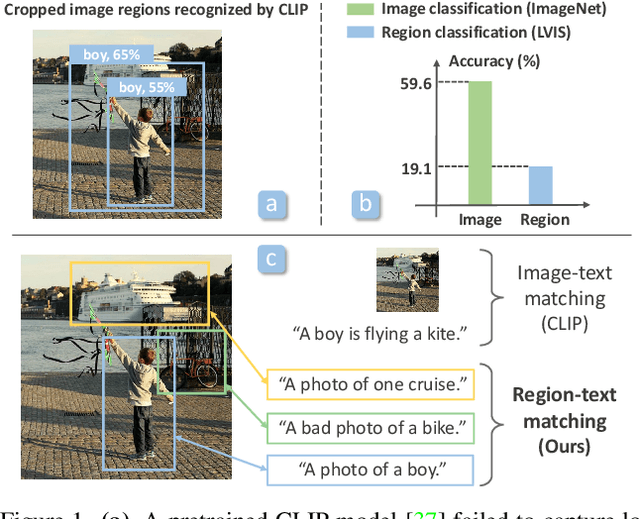
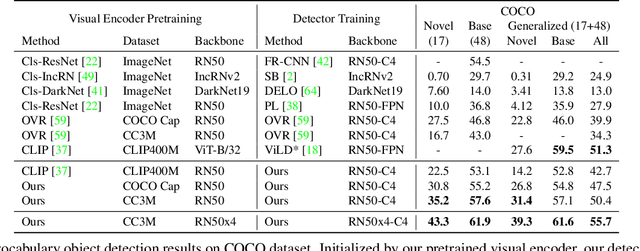
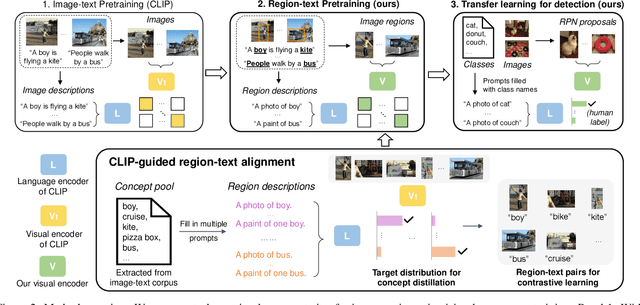
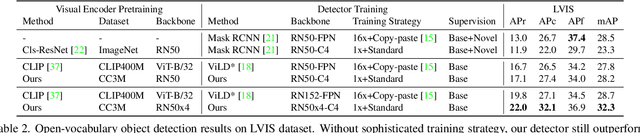
Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, we show that directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, we propose a new method called RegionCLIP that significantly extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. Our method leverages a CLIP model to match image regions with template captions and then pretrains our model to align these region-text pairs in the feature space. When transferring our pretrained model to the open-vocabulary object detection tasks, our method significantly outperforms the state of the art by 3.8 AP50 and 2.2 AP for novel categories on COCO and LVIS datasets, respectively. Moreoever, the learned region representations support zero-shot inference for object detection, showing promising results on both COCO and LVIS datasets. Our code is available at https://github.com/microsoft/RegionCLIP.
GLFF: Global and Local Feature Fusion for Face Forgery Detection
Nov 17, 2022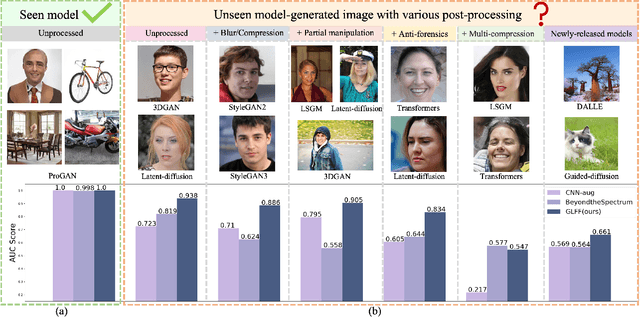
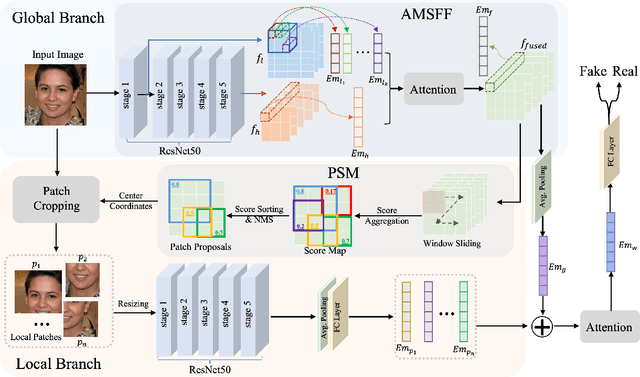
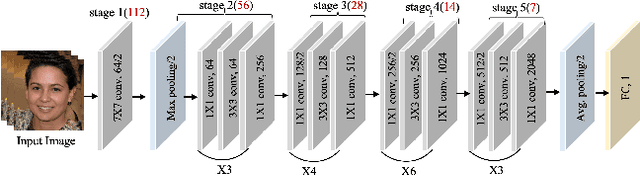

With the rapid development of deep generative models (such as Generative Adversarial Networks and Auto-encoders), AI-synthesized images of the human face are now of such high quality that humans can hardly distinguish them from pristine ones. Although existing detection methods have shown high performance in specific evaluation settings, e.g., on images from seen models or on images without real-world post-processings, they tend to suffer serious performance degradation in real-world scenarios where testing images can be generated by more powerful generation models or combined with various post-processing operations. To address this issue, we propose a Global and Local Feature Fusion (GLFF) to learn rich and discriminative representations by combining multi-scale global features from the whole image with refined local features from informative patches for face forgery detection. GLFF fuses information from two branches: the global branch to extract multi-scale semantic features and the local branch to select informative patches for detailed local artifacts extraction. Due to the lack of a face forgery dataset simulating real-world applications for evaluation, we further create a challenging face forgery dataset, named DeepFakeFaceForensics (DF^3), which contains 6 state-of-the-art generation models and a variety of post-processing techniques to approach the real-world scenarios. Experimental results demonstrate the superiority of our method to the state-of-the-art methods on the proposed DF^3 dataset and three other open-source datasets.
BppAttack: Stealthy and Efficient Trojan Attacks against Deep Neural Networks via Image Quantization and Contrastive Adversarial Learning
May 26, 2022
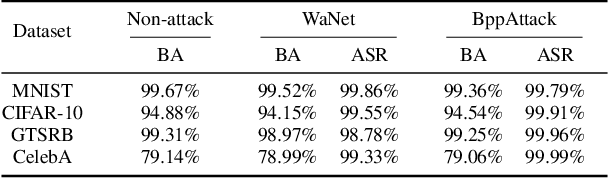
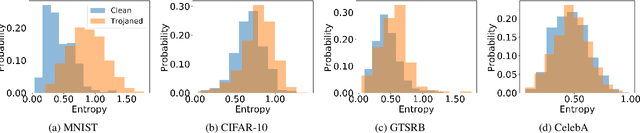
Deep neural networks are vulnerable to Trojan attacks. Existing attacks use visible patterns (e.g., a patch or image transformations) as triggers, which are vulnerable to human inspection. In this paper, we propose stealthy and efficient Trojan attacks, BppAttack. Based on existing biology literature on human visual systems, we propose to use image quantization and dithering as the Trojan trigger, making imperceptible changes. It is a stealthy and efficient attack without training auxiliary models. Due to the small changes made to images, it is hard to inject such triggers during training. To alleviate this problem, we propose a contrastive learning based approach that leverages adversarial attacks to generate negative sample pairs so that the learned trigger is precise and accurate. The proposed method achieves high attack success rates on four benchmark datasets, including MNIST, CIFAR-10, GTSRB, and CelebA. It also effectively bypasses existing Trojan defenses and human inspection. Our code can be found in https://github.com/RU-System-Software-and-Security/BppAttack.
Knowledge-Free Black-Box Watermark and Ownership Proof for Image Classification Neural Networks
Apr 09, 2022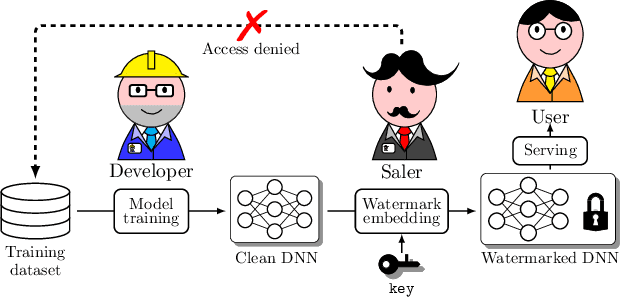

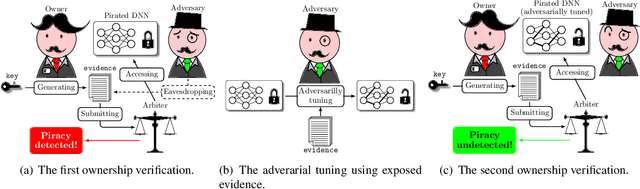

Watermarking has become a plausible candidate for ownership verification and intellectual property protection of deep neural networks. Regarding image classification neural networks, current watermarking schemes uniformly resort to backdoor triggers. However, injecting a backdoor into a neural network requires knowledge of the training dataset, which is usually unavailable in the real-world commercialization. Meanwhile, established watermarking schemes oversight the potential damage of exposed evidence during ownership verification and the watermarking algorithms themselves. Those concerns decline current watermarking schemes from industrial applications. To confront these challenges, we propose a knowledge-free black-box watermarking scheme for image classification neural networks. The image generator obtained from a data-free distillation process is leveraged to stabilize the network's performance during the backdoor injection. A delicate encoding and verification protocol is designed to ensure the scheme's security against knowledgable adversaries. We also give a pioneering analysis of the capacity of the watermarking scheme. Experiment results proved the functionality-preserving capability and security of the proposed watermarking scheme.
Deep Convolutional Pooling Transformer for Deepfake Detection
Sep 12, 2022



Recently, Deepfake has drawn considerable public attention due to security and privacy concerns in social media digital forensics. As the wildly spreading Deepfake videos on the Internet become more realistic, traditional detection techniques have failed in distinguishing between the real and fake. Most existing deep learning methods mainly focus on local features and relations within the face image using convolutional neural networks as a backbone. However, local features and relations are insufficient for model training to learn enough general information for Deepfake detection. Therefore, the existing Deepfake detection methods have reached a bottleneck to further improving the detection performance. To address this issue, we propose a deep convolutional Transformer to incorporate the decisive image features both locally and globally. Specifically, we apply convolutional pooling and re-attention to enrich the extracted features and enhance the efficacy. Moreover, we employ the barely discussed image keyframes in model training for performance improvement and visualize the feature quantity gap between the key and normal image frames caused by video compression. We finally illustrate the transferability with extensive experiments on several Deepfake benchmark datasets. The proposed solution consistently outperforms several state-of-the-art baselines on both within- and cross-dataset experiments.
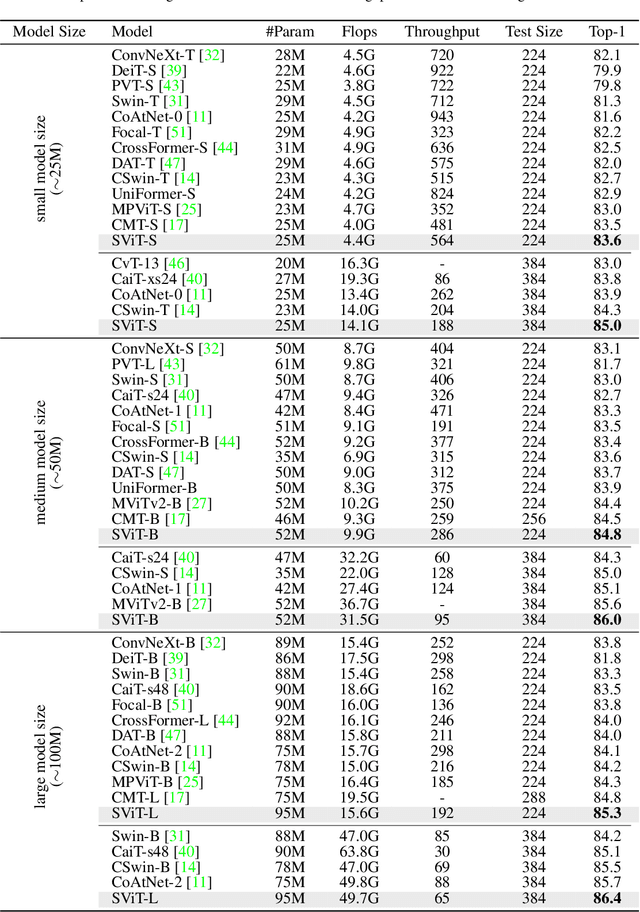
Vision Transformer with Super Token Sampling
Nov 21, 2022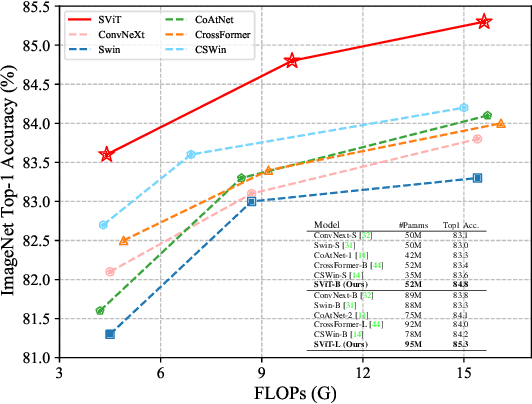

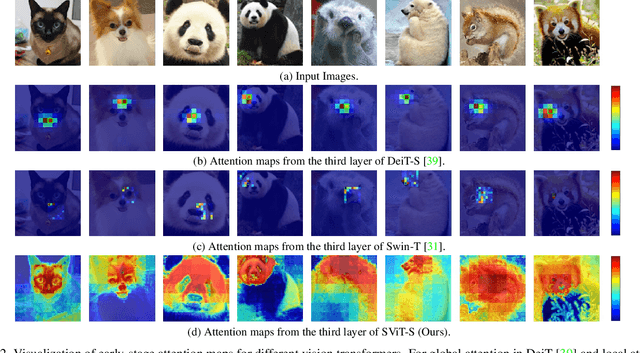
Vision transformer has achieved impressive performance for many vision tasks. However, it may suffer from high redundancy in capturing local features for shallow layers. Local self-attention or early-stage convolutions are thus utilized, which sacrifice the capacity to capture long-range dependency. A challenge then arises: can we access efficient and effective global context modeling at the early stages of a neural network? To address this issue, we draw inspiration from the design of superpixels, which reduces the number of image primitives in subsequent processing, and introduce super tokens into vision transformer. Super tokens attempt to provide a semantically meaningful tessellation of visual content, thus reducing the token number in self-attention as well as preserving global modeling. Specifically, we propose a simple yet strong super token attention (STA) mechanism with three steps: the first samples super tokens from visual tokens via sparse association learning, the second performs self-attention on super tokens, and the last maps them back to the original token space. STA decomposes vanilla global attention into multiplications of a sparse association map and a low-dimensional attention, leading to high efficiency in capturing global dependencies. Based on STA, we develop a hierarchical vision transformer. Extensive experiments demonstrate its strong performance on various vision tasks. In particular, without any extra training data or label, it achieves 86.4% top-1 accuracy on ImageNet-1K with less than 100M parameters. It also achieves 53.9 box AP and 46.8 mask AP on the COCO detection task, and 51.9 mIOU on the ADE20K semantic segmentation task. Code will be released at https://github.com/hhb072/SViT.
You Need Multiple Exiting: Dynamic Early Exiting for Accelerating Unified Vision Language Model
Nov 21, 2022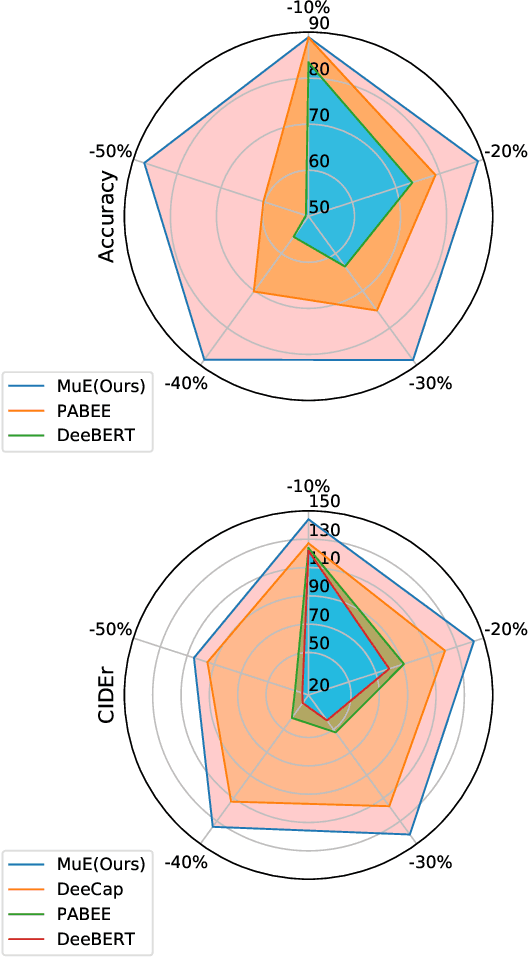
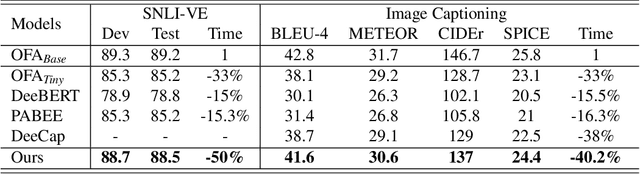
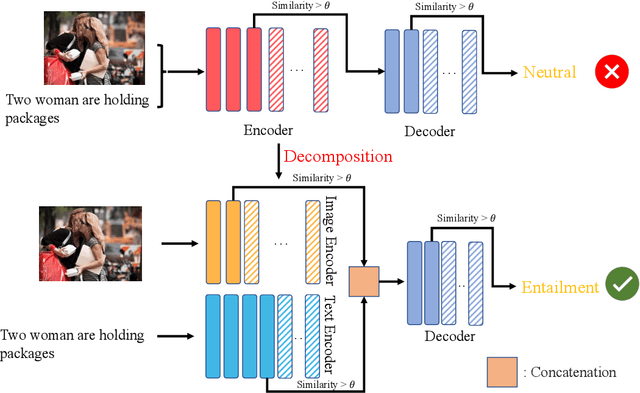
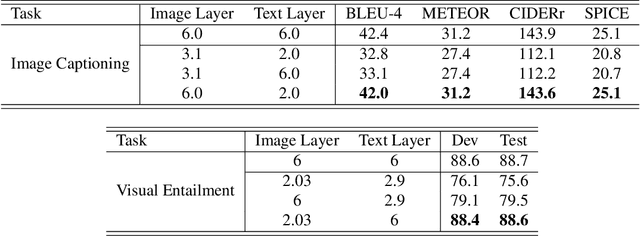
Large-scale Transformer models bring significant improvements for various downstream vision language tasks with a unified architecture. The performance improvements come with increasing model size, resulting in slow inference speed and increased cost for severing. While some certain predictions benefit from the full complexity of the large-scale model, not all of inputs need the same amount of computation to conduct, potentially leading to computation resource waste. To handle this challenge, early exiting is proposed to adaptively allocate computational power in term of input complexity to improve inference efficiency. The existing early exiting strategies usually adopt output confidence based on intermediate layers as a proxy of input complexity to incur the decision of skipping following layers. However, such strategies cannot apply to encoder in the widely-used unified architecture with both encoder and decoder due to difficulty of output confidence estimation in the encoder. It is suboptimal in term of saving computation power to ignore the early exiting in encoder component. To handle this challenge, we propose a novel early exiting strategy for unified visual language models, which allows dynamically skip the layers in encoder and decoder simultaneously in term of input layer-wise similarities with multiple times of early exiting, namely \textbf{MuE}. By decomposing the image and text modalities in the encoder, MuE is flexible and can skip different layers in term of modalities, advancing the inference efficiency while minimizing performance drop. Experiments on the SNLI-VE and MS COCO datasets show that the proposed approach MuE can reduce expected inference time by up to 50\% and 40\% while maintaining 99\% and 96\% performance respectively.
BIQ2021: A Large-Scale Blind Image Quality Assessment Database
Feb 08, 2022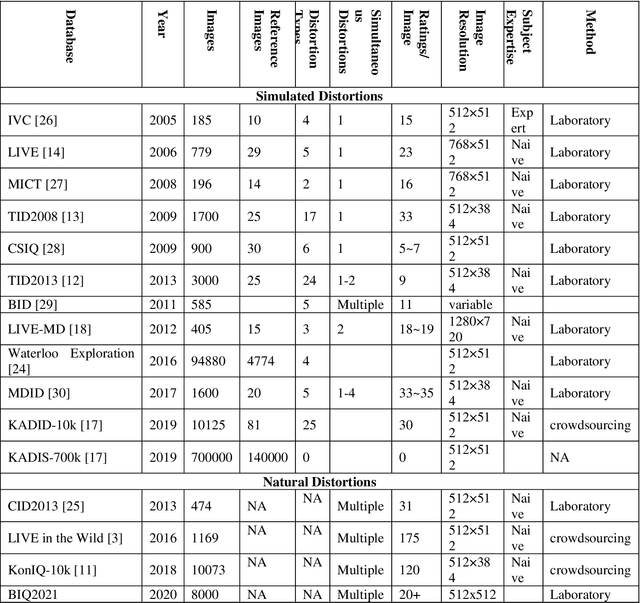


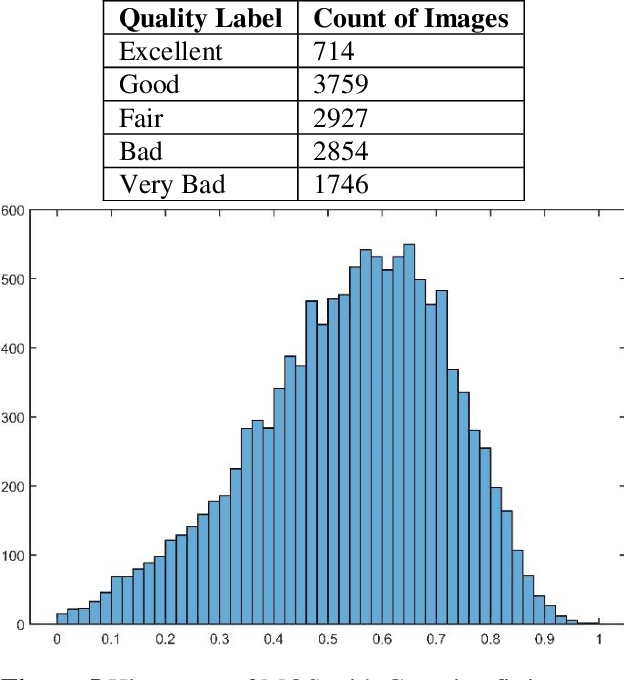
The assessment of the perceptual quality of digital images is becoming increasingly important as a result of the widespread use of digital multimedia devices. Smartphones and high-speed internet are just two examples of technologies that have multiplied the amount of multimedia content available. Thus, obtaining a representative dataset, which is required for objective quality assessment training, is a significant challenge. The Blind Image Quality Assessment Database, BIQ2021, is presented in this article. By selecting images with naturally occurring distortions and reliable labeling, the dataset addresses the challenge of obtaining representative images for no-reference image quality assessment. The dataset consists of three sets of images: those taken without the intention of using them for image quality assessment, those taken with intentionally introduced natural distortions, and those taken from an open-source image-sharing platform. It is attempted to maintain a diverse collection of images from various devices, containing a variety of different types of objects and varying degrees of foreground and background information. To obtain reliable scores, these images are subjectively scored in a laboratory environment using a single stimulus method. The database contains information about subjective scoring, human subject statistics, and the standard deviation of each image. The dataset's Mean Opinion Scores (MOS) make it useful for assessing visual quality. Additionally, the proposed database is used to evaluate existing blind image quality assessment approaches, and the scores are analyzed using Pearson and Spearman's correlation coefficients. The image database and MOS are freely available for use and benchmarking.
Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
Nov 19, 2022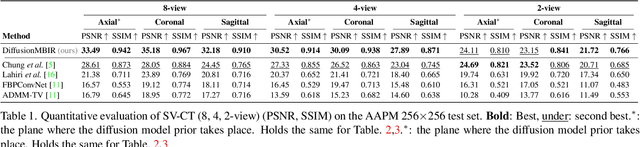
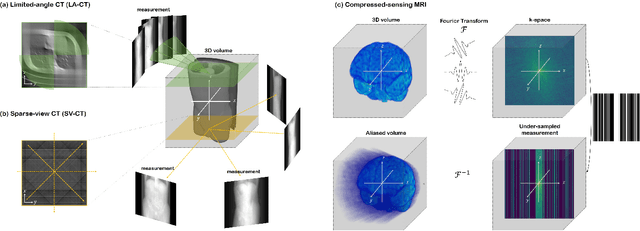
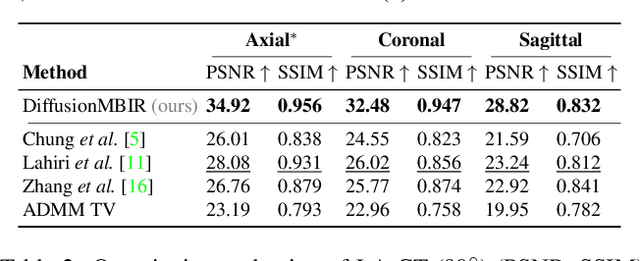
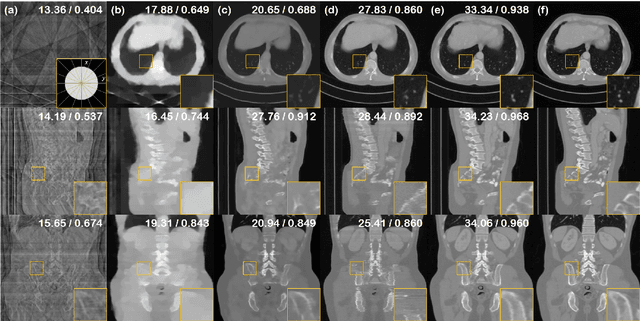
Diffusion models have emerged as the new state-of-the-art generative model with high quality samples, with intriguing properties such as mode coverage and high flexibility. They have also been shown to be effective inverse problem solvers, acting as the prior of the distribution, while the information of the forward model can be granted at the sampling stage. Nonetheless, as the generative process remains in the same high dimensional (i.e. identical to data dimension) space, the models have not been extended to 3D inverse problems due to the extremely high memory and computational cost. In this paper, we combine the ideas from the conventional model-based iterative reconstruction with the modern diffusion models, which leads to a highly effective method for solving 3D medical image reconstruction tasks such as sparse-view tomography, limited angle tomography, compressed sensing MRI from pre-trained 2D diffusion models. In essence, we propose to augment the 2D diffusion prior with a model-based prior in the remaining direction at test time, such that one can achieve coherent reconstructions across all dimensions. Our method can be run in a single commodity GPU, and establishes the new state-of-the-art, showing that the proposed method can perform reconstructions of high fidelity and accuracy even in the most extreme cases (e.g. 2-view 3D tomography). We further reveal that the generalization capacity of the proposed method is surprisingly high, and can be used to reconstruct volumes that are entirely different from the training dataset.