 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prompting through Prototype: A Prototype-based Prompt Learning on Pretrained Vision-Language Models
Oct 19, 2022
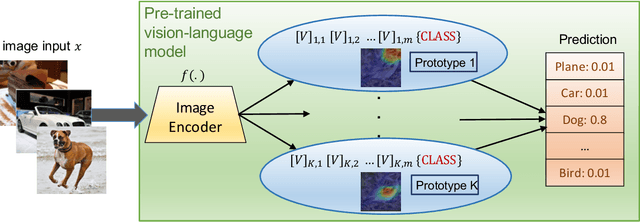
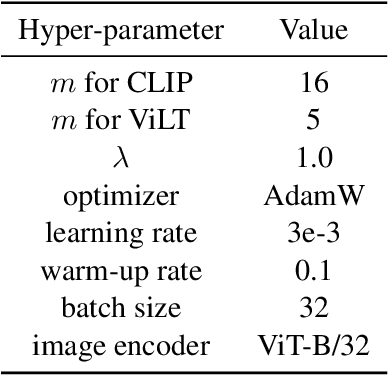
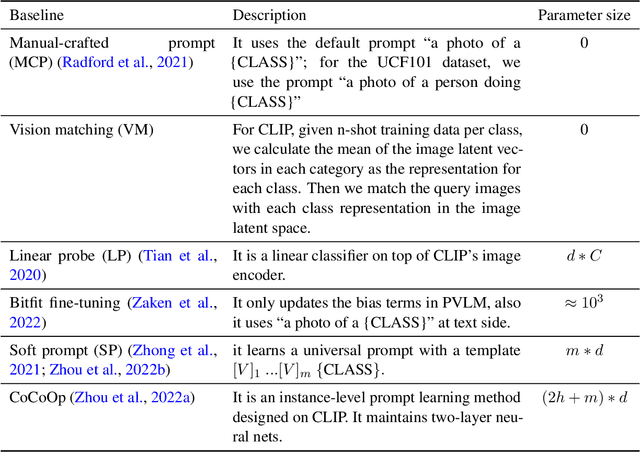
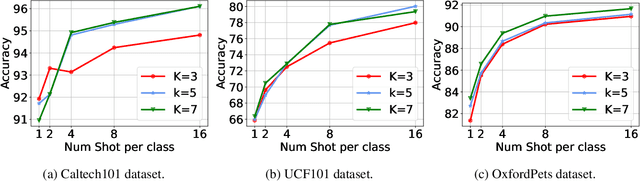
Prompt learning is a new learning paradigm which reformulates downstream tasks as similar pretraining tasks on pretrained models by leveraging textual prompts. Recent works have demonstrated that prompt learning is particularly useful for few-shot learning, where there is limited training data. Depending on the granularity of prompts, those methods can be roughly divided into task-level prompting and instance-level prompting. Task-level prompting methods learn one universal prompt for all input samples, which is efficient but ineffective to capture subtle differences among different classes. Instance-level prompting methods learn a specific prompt for each input, though effective but inefficient. In this work, we develop a novel prototype-based prompt learning method to overcome the above limitations. In particular, we focus on few-shot image recognition tasks on pretrained vision-language models (PVLMs) and develop a method of prompting through prototype (PTP), where we define $K$ image prototypes and $K$ prompt prototypes. In PTP, the image prototype represents a centroid of a certain image cluster in the latent space and a prompt prototype is defined as a soft prompt in the continuous space. The similarity between a query image and an image prototype determines how much this prediction relies on the corresponding prompt prototype. Hence, in PTP, similar images will utilize similar prompting ways. Through extensive experiments on seven real-world benchmarks, we show that PTP is an effective method to leverage the latent knowledge and adaptive to various PVLMs. Moreover, through detailed analysis, we discuss pros and cons for prompt learning and parameter-efficient fine-tuning under the context of few-shot learning.
A Differentiable Distance Approximation for Fairer Image Classification
Oct 09, 2022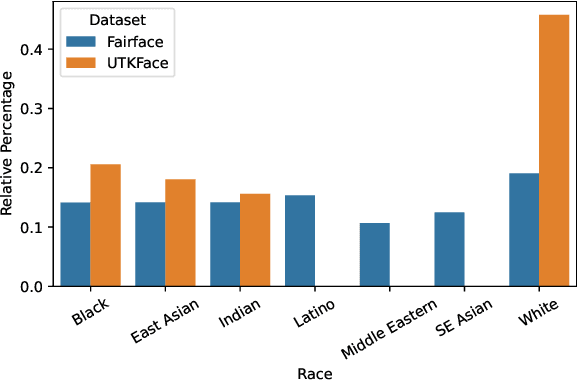
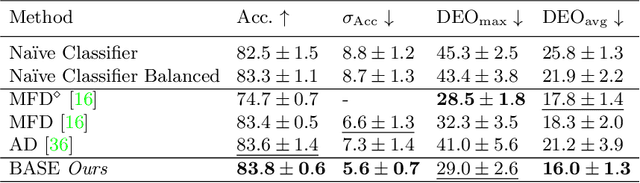
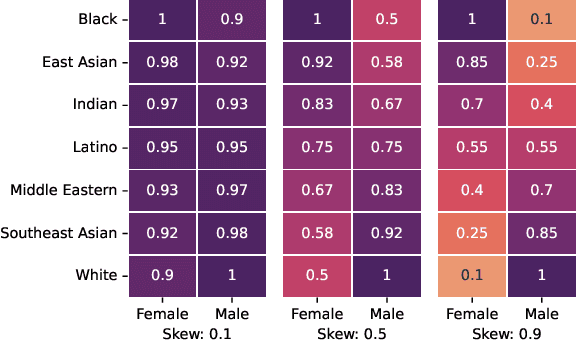

Naively trained AI models can be heavily biased. This can be particularly problematic when the biases involve legally or morally protected attributes such as ethnic background, age or gender. Existing solutions to this problem come at the cost of extra computation, unstable adversarial optimisation or have losses on the feature space structure that are disconnected from fairness measures and only loosely generalise to fairness. In this work we propose a differentiable approximation of the variance of demographics, a metric that can be used to measure the bias, or unfairness, in an AI model. Our approximation can be optimised alongside the regular training objective which eliminates the need for any extra models during training and directly improves the fairness of the regularised models. We demonstrate that our approach improves the fairness of AI models in varied task and dataset scenarios, whilst still maintaining a high level of classification accuracy. Code is available at https://bitbucket.org/nelliottrosa/base_fairness.
DiT: Self-supervised Pre-training for Document Image Transformer
Apr 12, 2022
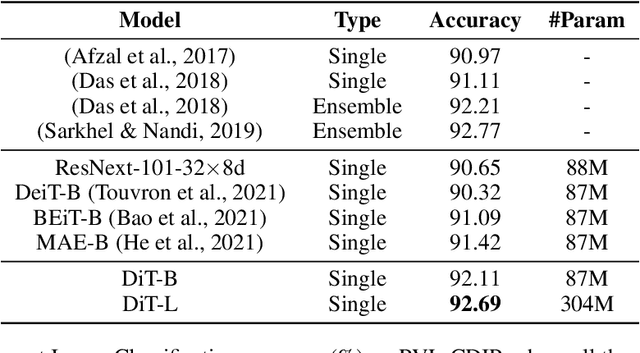

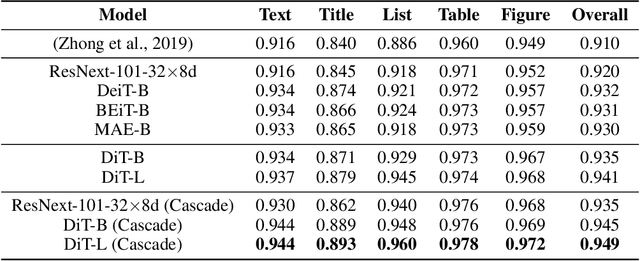
Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, table detection as well as text detection for OCR. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 $\rightarrow$ 92.69), document layout analysis (91.0 $\rightarrow$ 94.9), table detection (94.23 $\rightarrow$ 96.55) and text detection for OCR (93.07 $\rightarrow$ 94.29). The code and pre-trained models are publicly available at \url{https://aka.ms/msdit}.
Find Someone Who: Visual Commonsense Understanding in Human-Centric Grounding
Dec 14, 2022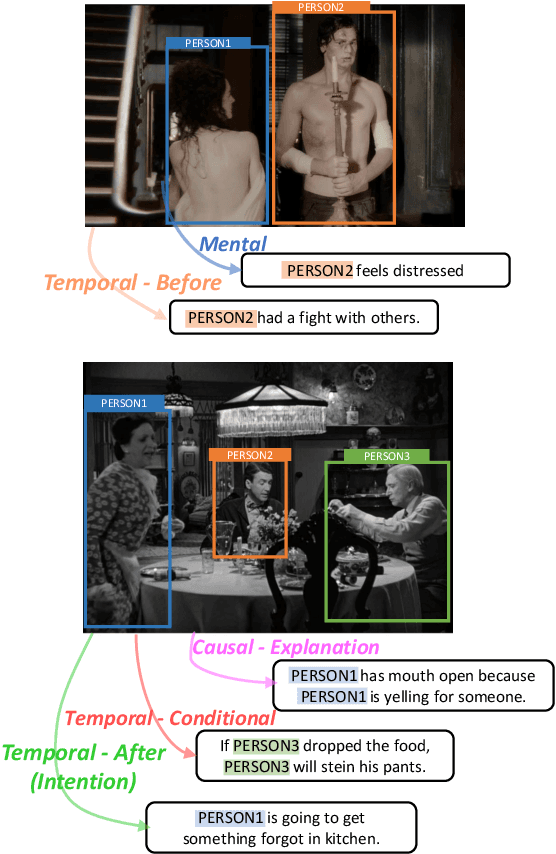


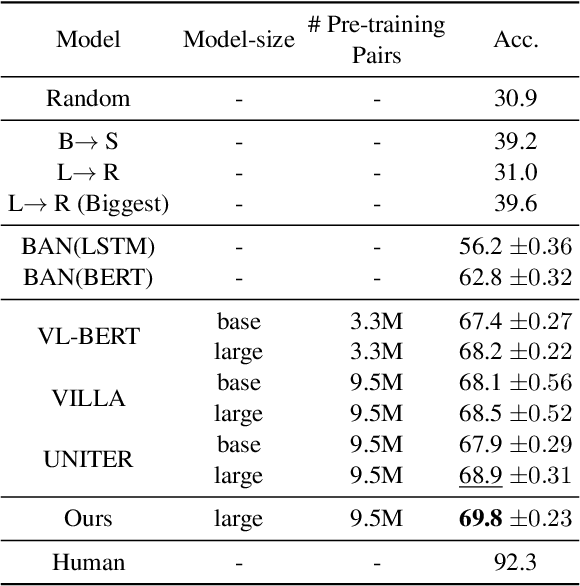
From a visual scene containing multiple people, human is able to distinguish each individual given the context descriptions about what happened before, their mental/physical states or intentions, etc. Above ability heavily relies on human-centric commonsense knowledge and reasoning. For example, if asked to identify the "person who needs healing" in an image, we need to first know that they usually have injuries or suffering expressions, then find the corresponding visual clues before finally grounding the person. We present a new commonsense task, Human-centric Commonsense Grounding, that tests the models' ability to ground individuals given the context descriptions about what happened before, and their mental/physical states or intentions. We further create a benchmark, HumanCog, a dataset with 130k grounded commonsensical descriptions annotated on 67k images, covering diverse types of commonsense and visual scenes. We set up a context-object-aware method as a strong baseline that outperforms previous pre-trained and non-pretrained models. Further analysis demonstrates that rich visual commonsense and powerful integration of multi-modal commonsense are essential, which sheds light on future works. Data and code will be available https://github.com/Hxyou/HumanCog.
Objective quality assessment of medical images and videos: Review and challenges
Dec 14, 2022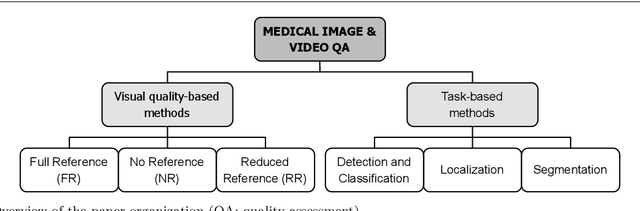
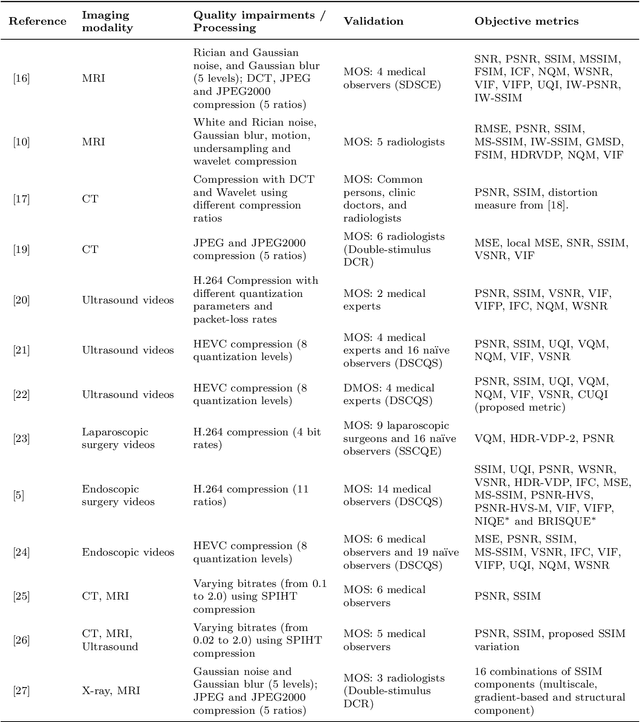
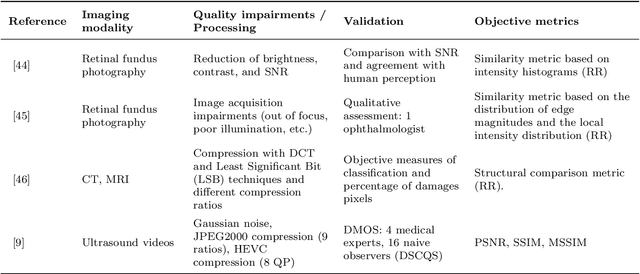
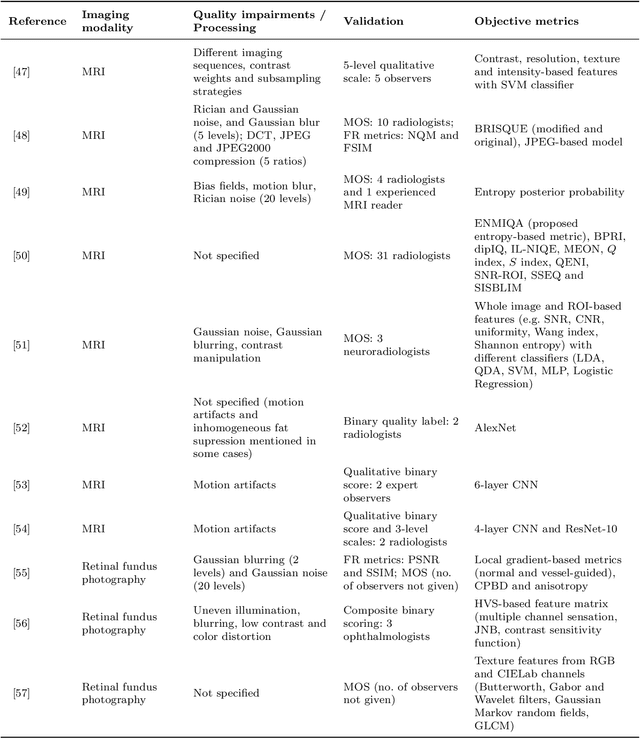
Quality assessment is a key element for the evaluation of hardware and software involved in image and video acquisition, processing, and visualization. In the medical field, user-based quality assessment is still considered more reliable than objective methods, which allow the implementation of automated and more efficient solutions. Regardless of increasing research in this topic in the last decade, defining quality standards for medical content remains a non-trivial task, as the focus should be on the diagnostic value assessed from expert viewers rather than the perceived quality from na\"{i}ve viewers, and objective quality metrics should aim at estimating the first rather than the latter. In this paper, we present a survey of methodologies used for the objective quality assessment of medical images and videos, dividing them into visual quality-based and task-based approaches. Visual quality based methods compute a quality index directly from visual attributes, while task-based methods, being increasingly explored, measure the impact of quality impairments on the performance of a specific task. A discussion on the limitations of state-of-the-art research on this topic is also provided, along with future challenges to be addressed.
Post-hoc Uncertainty Learning using a Dirichlet Meta-Model
Dec 14, 2022
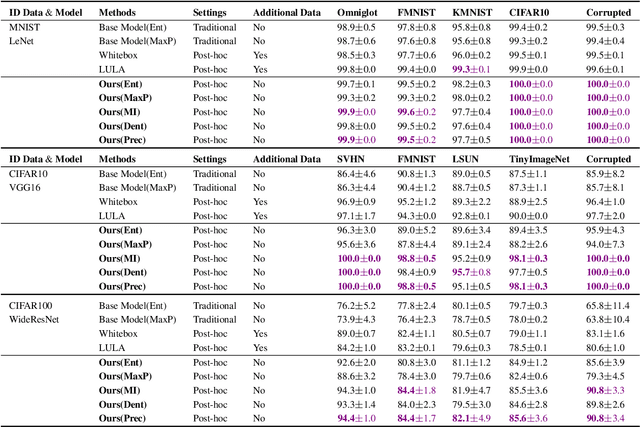
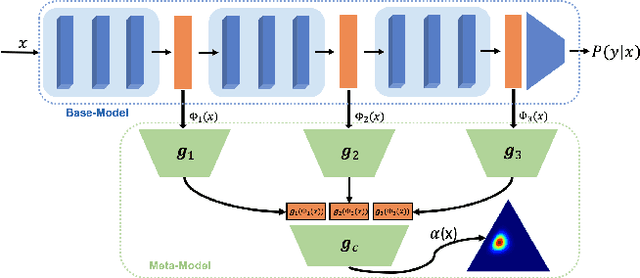
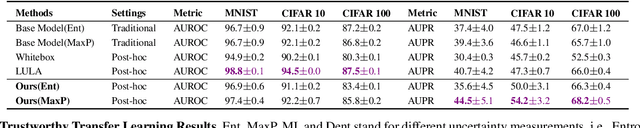
It is known that neural networks have the problem of being over-confident when directly using the output label distribution to generate uncertainty measures. Existing methods mainly resolve this issue by retraining the entire model to impose the uncertainty quantification capability so that the learned model can achieve desired performance in accuracy and uncertainty prediction simultaneously. However, training the model from scratch is computationally expensive and may not be feasible in many situations. In this work, we consider a more practical post-hoc uncertainty learning setting, where a well-trained base model is given, and we focus on the uncertainty quantification task at the second stage of training. We propose a novel Bayesian meta-model to augment pre-trained models with better uncertainty quantification abilities, which is effective and computationally efficient. Our proposed method requires no additional training data and is flexible enough to quantify different uncertainties and easily adapt to different application settings, including out-of-domain data detection, misclassification detection, and trustworthy transfer learning. We demonstrate our proposed meta-model approach's flexibility and superior empirical performance on these applications over multiple representative image classification benchmarks.
Object-fabrication Targeted Attack for Object Detection
Dec 14, 2022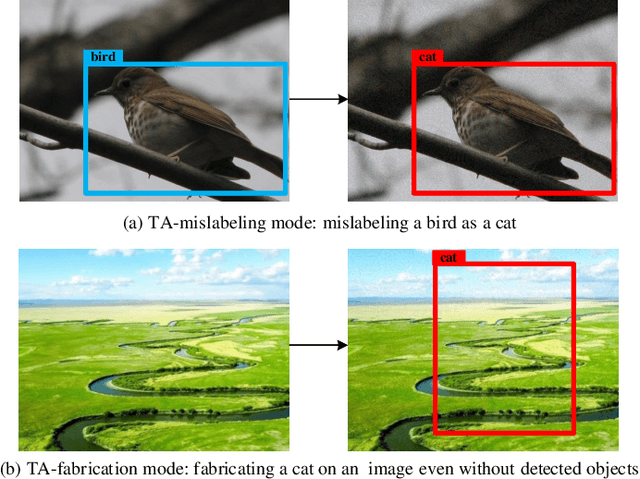
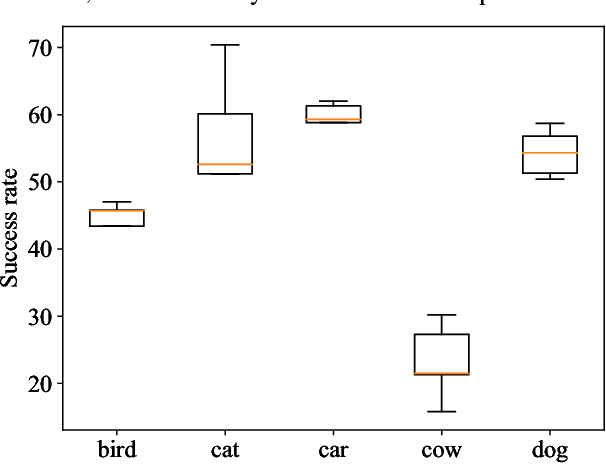
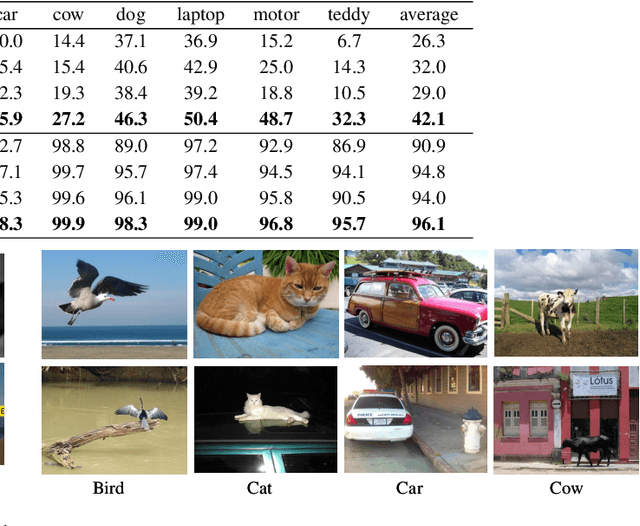
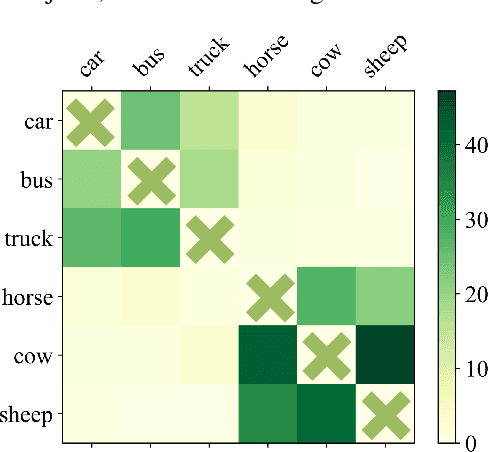
Recent researches show that the deep learning based object detection is vulnerable to adversarial examples. Generally, the adversarial attack for object detection contains targeted attack and untargeted attack. According to our detailed investigations, the research on the former is relatively fewer than the latter and all the existing methods for the targeted attack follow the same mode, i.e., the object-mislabeling mode that misleads detectors to mislabel the detected object as a specific wrong label. However, this mode has limited attack success rate, universal and generalization performances. In this paper, we propose a new object-fabrication targeted attack mode which can mislead detectors to `fabricate' extra false objects with specific target labels. Furthermore, we design a dual attention based targeted feature space attack method to implement the proposed targeted attack mode. The attack performances of the proposed mode and method are evaluated on MS COCO and BDD100K datasets using FasterRCNN and YOLOv5. Evaluation results demonstrate that, the proposed object-fabrication targeted attack mode and the corresponding targeted feature space attack method show significant improvements in terms of image-specific attack, universal performance and generalization capability, compared with the previous targeted attack for object detection. Code will be made available.
Conformer and Blind Noisy Students for Improved Image Quality Assessment
Apr 27, 2022

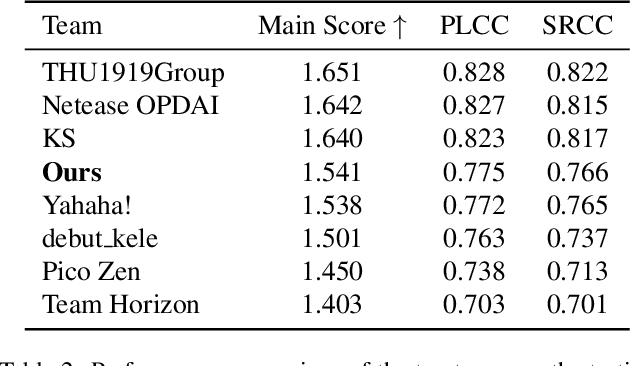
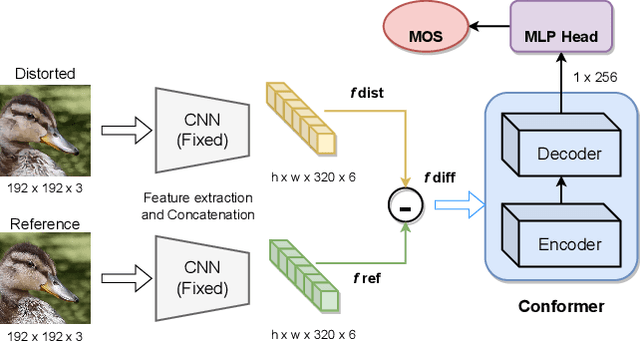
Generative models for image restoration, enhancement, and generation have significantly improved the quality of the generated images. Surprisingly, these models produce more pleasant images to the human eye than other methods, yet, they may get a lower perceptual quality score using traditional perceptual quality metrics such as PSNR or SSIM. Therefore, it is necessary to develop a quantitative metric to reflect the performance of new algorithms, which should be well-aligned with the person's mean opinion score (MOS). Learning-based approaches for perceptual image quality assessment (IQA) usually require both the distorted and reference image for measuring the perceptual quality accurately. However, commonly only the distorted or generated image is available. In this work, we explore the performance of transformer-based full-reference IQA models. We also propose a method for IQA based on semi-supervised knowledge distillation from full-reference teacher models into blind student models using noisy pseudo-labeled data. Our approaches achieved competitive results on the NTIRE 2022 Perceptual Image Quality Assessment Challenge: our full-reference model was ranked 4th, and our blind noisy student was ranked 3rd among 70 participants, each in their respective track.
USLN: A statistically guided lightweight network for underwater image enhancement via dual-statistic white balance and multi-color space stretch
Sep 06, 2022



Underwater images are inevitably affected by color distortion and reduced contrast. Traditional statistic-based methods such as white balance and histogram stretching attempted to adjust the imbalance of color channels and narrow distribution of intensities a priori thus with limited performance. Recently, deep-learning-based methods have achieved encouraging results. However, the involved complicate architecture and high computational costs may hinder their deployment in practical constrained platforms. Inspired by above works, we propose a statistically guided lightweight underwater image enhancement network (USLN). Concretely, we first develop a dual-statistic white balance module which can learn to use both average and maximum of images to compensate the color distortion for each specific pixel. Then this is followed by a multi-color space stretch module to adjust the histogram distribution in RGB, HSI, and Lab color spaces adaptively. Extensive experiments show that, with the guidance of statistics, USLN significantly reduces the required network capacity (over98%) and achieves state-of-the-art performance. The code and relevant resources are available at https://github.com/deepxzy/USLN.
Toward Unpaired Multi-modal Medical Image Segmentation via Learning Structured Semantic Consistency
Jun 21, 2022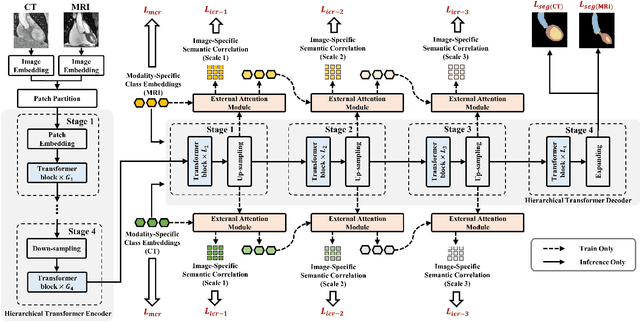
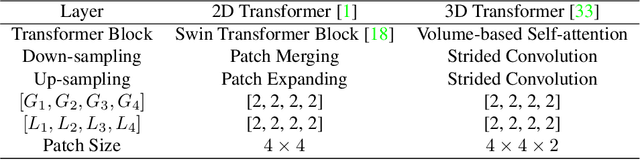
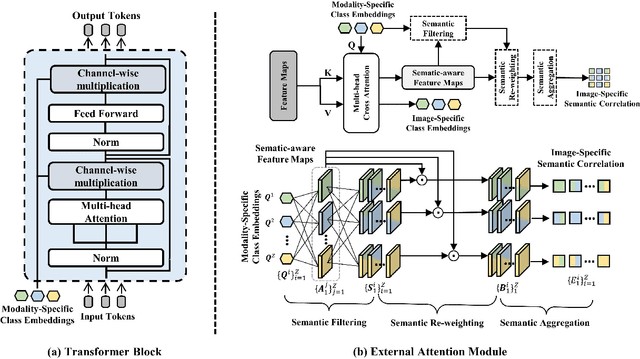
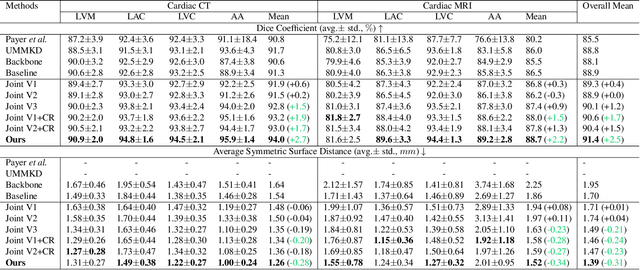
Integrating multi-modal data to improve medical image analysis has received great attention recently. However, due to the modal discrepancy, how to use a single model to process the data from multiple modalities is still an open issue. In this paper, we propose a novel scheme to achieve better pixel-level segmentation for unpaired multi-modal medical images. Different from previous methods which adopted both modality-specific and modality-shared modules to accommodate the appearance variance of different modalities while extracting the common semantic information, our method is based on a single Transformer with a carefully designed External Attention Module (EAM) to learn the structured semantic consistency (i.e. semantic class representations and their correlations) between modalities in the training phase. In practice, the above-mentioned structured semantic consistency across modalities can be progressively achieved by implementing the consistency regularization at the modality-level and image-level respectively. The proposed EAMs are adopted to learn the semantic consistency for different scale representations and can be discarded once the model is optimized. Therefore, during the testing phase, we only need to maintain one Transformer for all modal predictions, which nicely balances the model's ease of use and simplicity. To demonstrate the effectiveness of the proposed method, we conduct the experiments on two medical image segmentation scenarios: (1) cardiac structure segmentation, and (2) abdominal multi-organ segmentation. Extensive results show that the proposed method outperforms the state-of-the-art methods by a wide margin, and even achieves competitive performance with extremely limited training samples (e.g., 1 or 3 annotated CT or MRI images) for one specific modality.