 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detection of out-of-distribution samples using binary neuron activation patterns
Dec 29, 2022
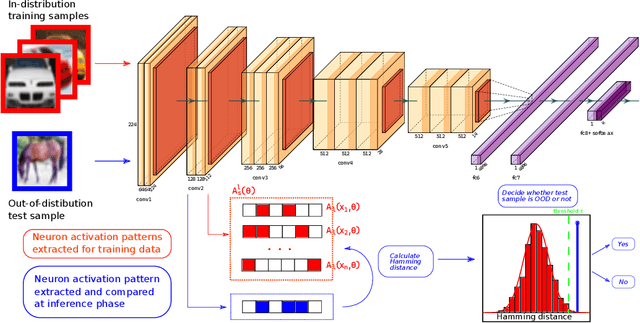
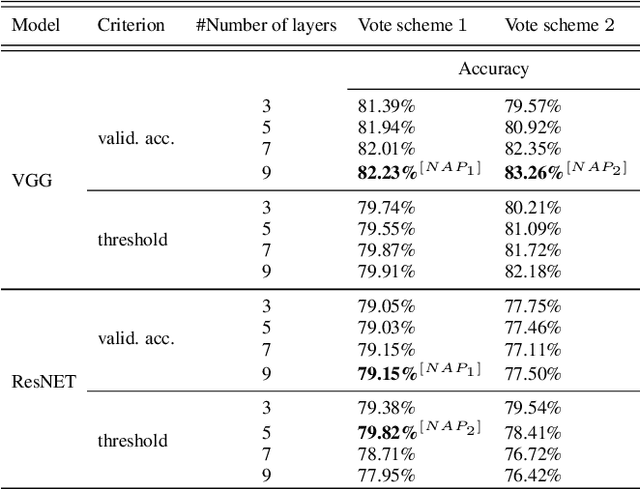
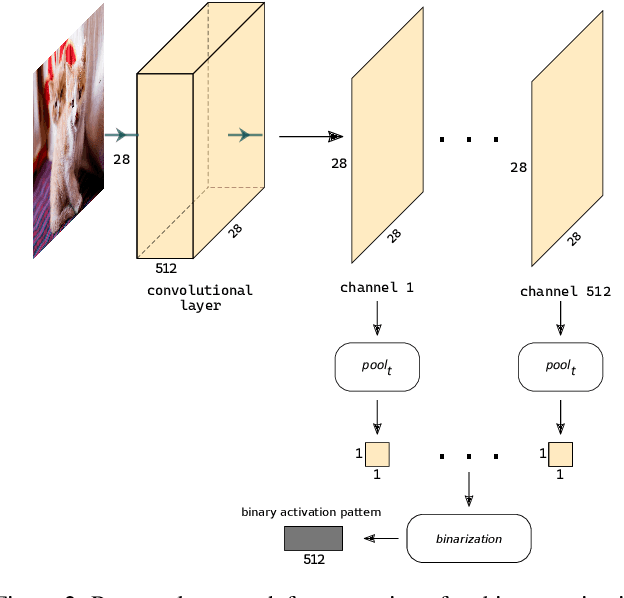
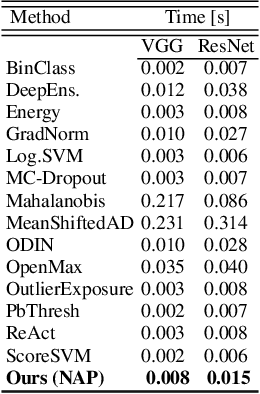
Deep neural networks (DNN) have outstanding performance in various applications. Despite numerous efforts of the research community, out-of-distribution (OOD) samples remain significant limitation of DNN classifiers. The ability to identify previously unseen inputs as novel is crucial in safety-critical applications such as self-driving cars, unmanned aerial vehicles and robots. Existing approaches to detect OOD samples treat a DNN as a black box and assess the confidence score of the output predictions. Unfortunately, this method frequently fails, because DNN are not trained to reduce their confidence for OOD inputs. In this work, we introduce a novel method for OOD detection. Our method is motivated by theoretical analysis of neuron activation patterns (NAP) in ReLU based architectures. The proposed method does not introduce high computational workload due to the binary representation of the activation patterns extracted from convolutional layers. The extensive empirical evaluation proves its high performance on various DNN architectures and seven image datasets. ion.
RANA: Relightable Articulated Neural Avatars
Dec 06, 2022
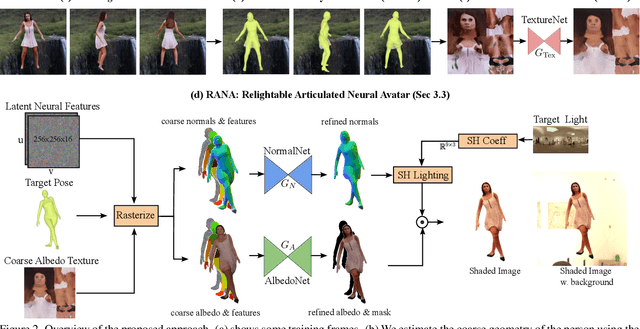
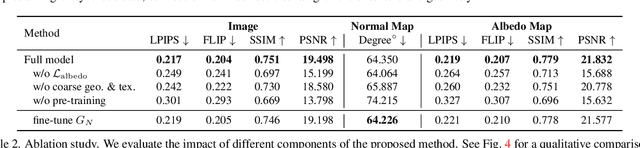

We propose RANA, a relightable and articulated neural avatar for the photorealistic synthesis of humans under arbitrary viewpoints, body poses, and lighting. We only require a short video clip of the person to create the avatar and assume no knowledge about the lighting environment. We present a novel framework to model humans while disentangling their geometry, texture, and also lighting environment from monocular RGB videos. To simplify this otherwise ill-posed task we first estimate the coarse geometry and texture of the person via SMPL+D model fitting and then learn an articulated neural representation for photorealistic image generation. RANA first generates the normal and albedo maps of the person in any given target body pose and then uses spherical harmonics lighting to generate the shaded image in the target lighting environment. We also propose to pretrain RANA using synthetic images and demonstrate that it leads to better disentanglement between geometry and texture while also improving robustness to novel body poses. Finally, we also present a new photorealistic synthetic dataset, Relighting Humans, to quantitatively evaluate the performance of the proposed approach.
3D-Augmented Contrastive Knowledge Distillation for Image-based Object Pose Estimation
Jun 02, 2022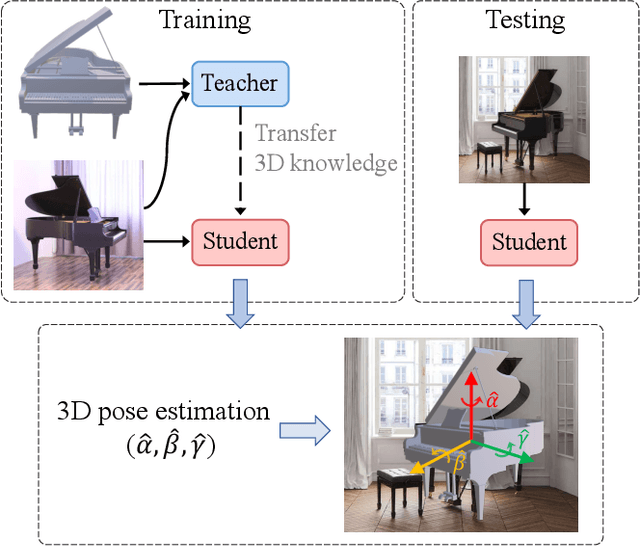
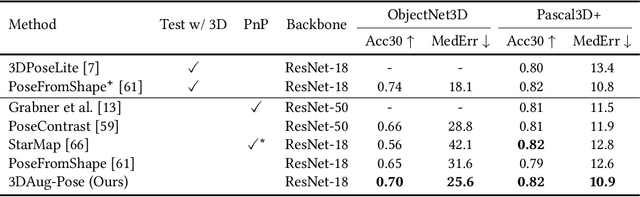
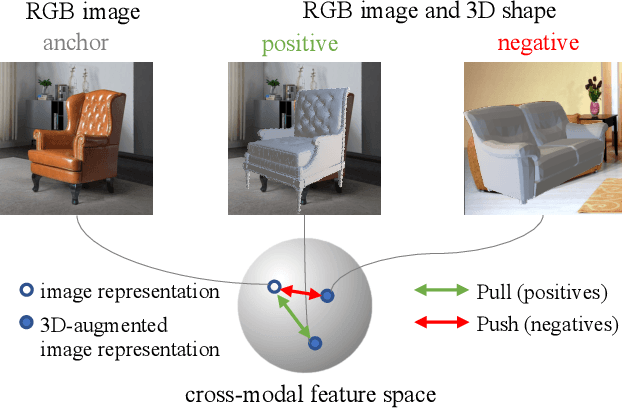
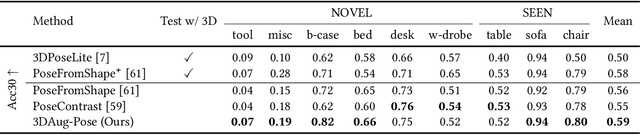
Image-based object pose estimation sounds amazing because in real applications the shape of object is oftentimes not available or not easy to take like photos. Although it is an advantage to some extent, un-explored shape information in 3D vision learning problem looks like "flaws in jade". In this paper, we deal with the problem in a reasonable new setting, namely 3D shape is exploited in the training process, and the testing is still purely image-based. We enhance the performance of image-based methods for category-agnostic object pose estimation by exploiting 3D knowledge learned by a multi-modal method. Specifically, we propose a novel contrastive knowledge distillation framework that effectively transfers 3D-augmented image representation from a multi-modal model to an image-based model. We integrate contrastive learning into the two-stage training procedure of knowledge distillation, which formulates an advanced solution to combine these two approaches for cross-modal tasks. We experimentally report state-of-the-art results compared with existing category-agnostic image-based methods by a large margin (up to +5% improvement on ObjectNet3D dataset), demonstrating the effectiveness of our method.
More comprehensive facial inversion for more effective expression recognition
Nov 24, 2022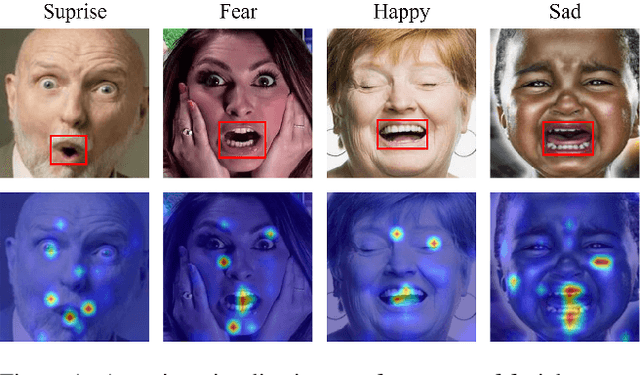
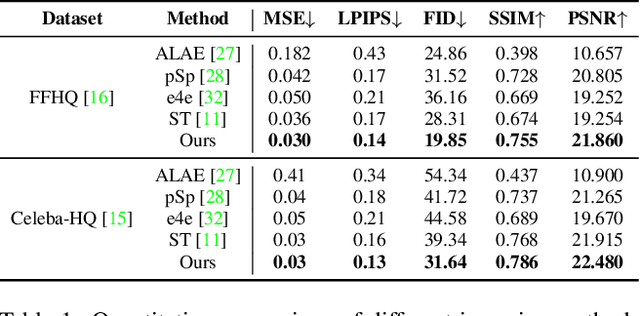

Facial expression recognition (FER) plays a significant role in the ubiquitous application of computer vision. We revisit this problem with a new perspective on whether it can acquire useful representations that improve FER performance in the image generation process, and propose a novel generative method based on the image inversion mechanism for the FER task, termed Inversion FER (IFER). Particularly, we devise a novel Adversarial Style Inversion Transformer (ASIT) towards IFER to comprehensively extract features of generated facial images. In addition, ASIT is equipped with an image inversion discriminator that measures the cosine similarity of semantic features between source and generated images, constrained by a distribution alignment loss. Finally, we introduce a feature modulation module to fuse the structural code and latent codes from ASIT for the subsequent FER work. We extensively evaluate ASIT on facial datasets such as FFHQ and CelebA-HQ, showing that our approach achieves state-of-the-art facial inversion performance. IFER also achieves competitive results in facial expression recognition datasets such as RAF-DB, SFEW and AffectNet. The code and models are available at https://github.com/Talented-Q/IFER-master.
PV3D: A 3D Generative Model for Portrait Video Generation
Dec 13, 2022
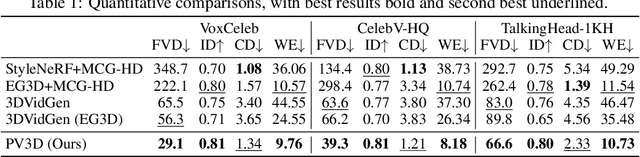
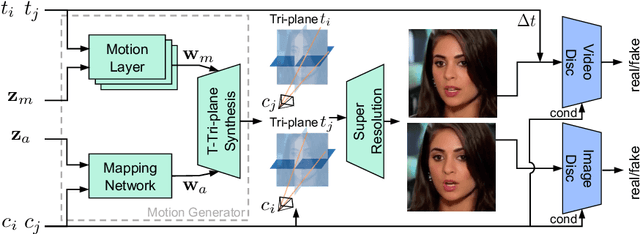
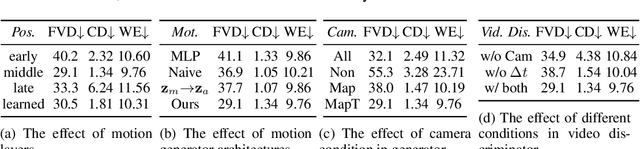
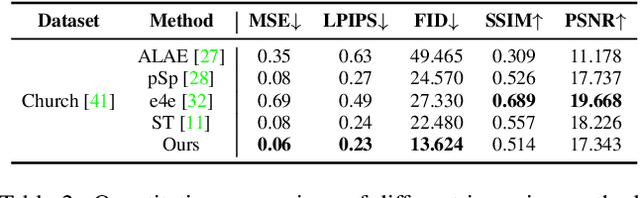
Recent advances in generative adversarial networks (GANs) have demonstrated the capabilities of generating stunning photo-realistic portrait images. While some prior works have applied such image GANs to unconditional 2D portrait video generation and static 3D portrait synthesis, there are few works successfully extending GANs for generating 3D-aware portrait videos. In this work, we propose PV3D, the first generative framework that can synthesize multi-view consistent portrait videos. Specifically, our method extends the recent static 3D-aware image GAN to the video domain by generalizing the 3D implicit neural representation to model the spatio-temporal space. To introduce motion dynamics to the generation process, we develop a motion generator by stacking multiple motion layers to generate motion features via modulated convolution. To alleviate motion ambiguities caused by camera/human motions, we propose a simple yet effective camera condition strategy for PV3D, enabling both temporal and multi-view consistent video generation. Moreover, PV3D introduces two discriminators for regularizing the spatial and temporal domains to ensure the plausibility of the generated portrait videos. These elaborated designs enable PV3D to generate 3D-aware motion-plausible portrait videos with high-quality appearance and geometry, significantly outperforming prior works. As a result, PV3D is able to support many downstream applications such as animating static portraits and view-consistent video motion editing. Code and models will be released at https://showlab.github.io/pv3d.
DifFace: Blind Face Restoration with Diffused Error Contraction
Dec 13, 2022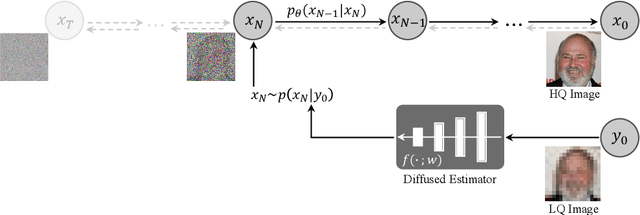

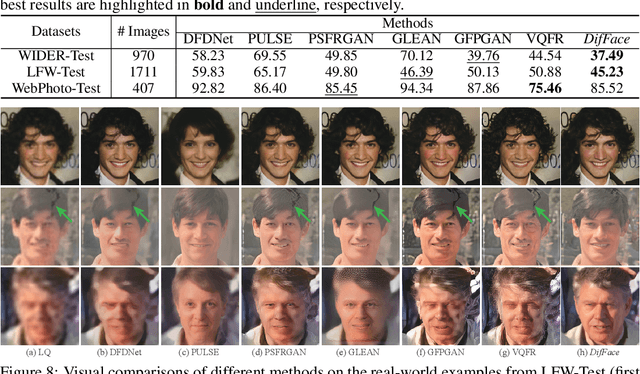

While deep learning-based methods for blind face restoration have achieved unprecedented success, they still suffer from two major limitations. First, most of them deteriorate when facing complex degradations out of their training data. Second, these methods require multiple constraints, e.g., fidelity, perceptual, and adversarial losses, which require laborious hyper-parameter tuning to stabilize and balance their influences. In this work, we propose a novel method named DifFace that is capable of coping with unseen and complex degradations more gracefully without complicated loss designs. The key of our method is to establish a posterior distribution from the observed low-quality (LQ) image to its high-quality (HQ) counterpart. In particular, we design a transition distribution from the LQ image to the intermediate state of a pre-trained diffusion model and then gradually transmit from this intermediate state to the HQ target by recursively applying a pre-trained diffusion model. The transition distribution only relies on a restoration backbone that is trained with $L_2$ loss on some synthetic data, which favorably avoids the cumbersome training process in existing methods. Moreover, the transition distribution can contract the error of the restoration backbone and thus makes our method more robust to unknown degradations. Comprehensive experiments show that DifFace is superior to current state-of-the-art methods, especially in cases with severe degradations. Our code and model are available at https://github.com/zsyOAOA/DifFace.
CREPE: Can Vision-Language Foundation Models Reason Compositionally?
Dec 13, 2022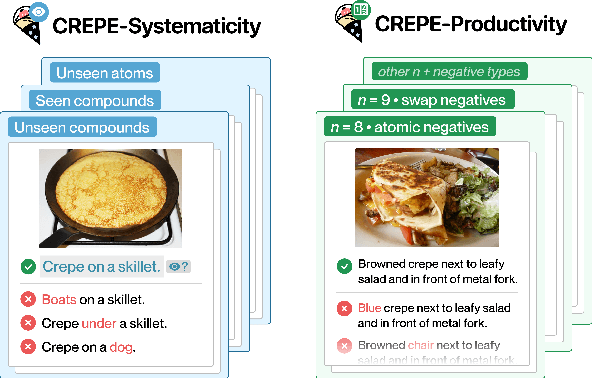

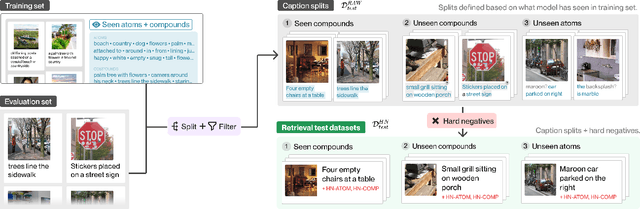
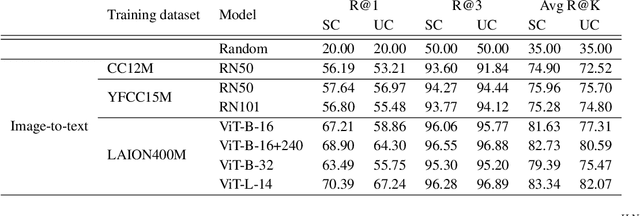
A fundamental characteristic common to both human vision and natural language is their compositional nature. Yet, despite the performance gains contributed by large vision and language pretraining, we find that - across 6 architectures trained with 4 algorithms on massive datasets - they exhibit little compositionality. To arrive at this conclusion, we introduce a new compositionality evaluation benchmark CREPE which measures two important aspects of compositionality identified by cognitive science literature: systematicity and productivity. To measure systematicity, CREPE consists of three test datasets. The three test sets are designed to test models trained on three of the popular training datasets: CC-12M, YFCC-15M, and LAION-400M. They contain 385K, 385K, and 373K image-text pairs and 237K, 210K, and 178K hard negative captions. To test productivity, CREPE contains 17K image-text pairs with nine different complexities plus 246K hard negative captions with atomic, swapping, and negation foils. The datasets are generated by repurposing the Visual Genome scene graphs and region descriptions and applying handcrafted templates and GPT-3. For systematicity, we find that model performance decreases consistently when novel compositions dominate the retrieval set, with Recall@1 dropping by up to 8%. For productivity, models' retrieval success decays as complexity increases, frequently nearing random chance at high complexity. These results hold regardless of model and training dataset size.
Effect of Instance Normalization on Fine-Grained Control for Sketch-Based Face Image Generation
Jul 17, 2022

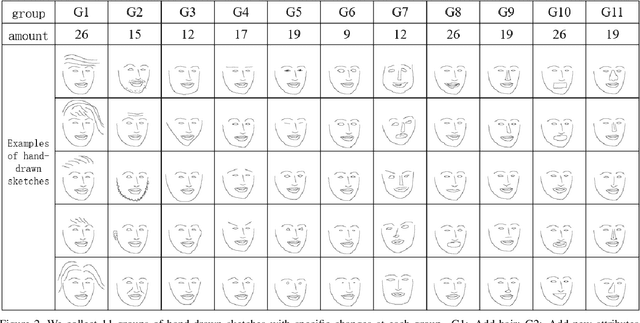
Sketching is an intuitive and effective way for content creation. While significant progress has been made for photorealistic image generation by using generative adversarial networks, it remains challenging to take a fine-grained control on synthetic content. The instance normalization layer, which is widely adopted in existing image translation networks, washes away details in the input sketch and leads to loss of precise control on the desired shape of the generated face images. In this paper, we comprehensively investigate the effect of instance normalization on generating photorealistic face images from hand-drawn sketches. We first introduce a visualization approach to analyze the feature embedding for sketches with a group of specific changes. Based on the visual analysis, we modify the instance normalization layers in the baseline image translation model. We elaborate a new set of hand-drawn sketches with 11 categories of specially designed changes and conduct extensive experimental analysis. The results and user studies demonstrate that our method markedly improve the quality of synthesized images and the conformance with user intention.
Facial Expression Recognition and Image Description Generation in Vietnamese
Aug 12, 2022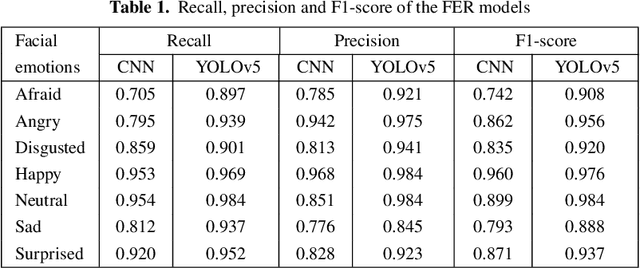
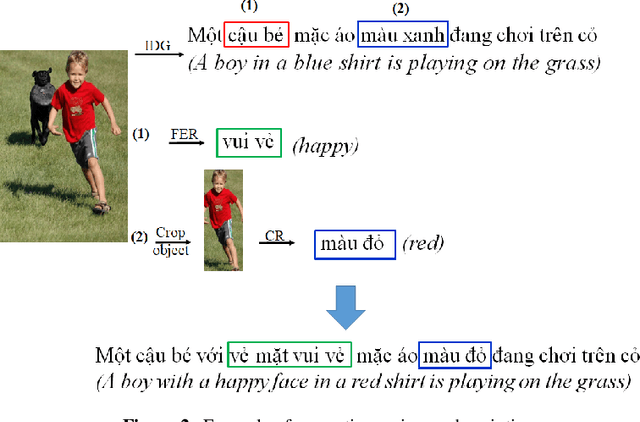

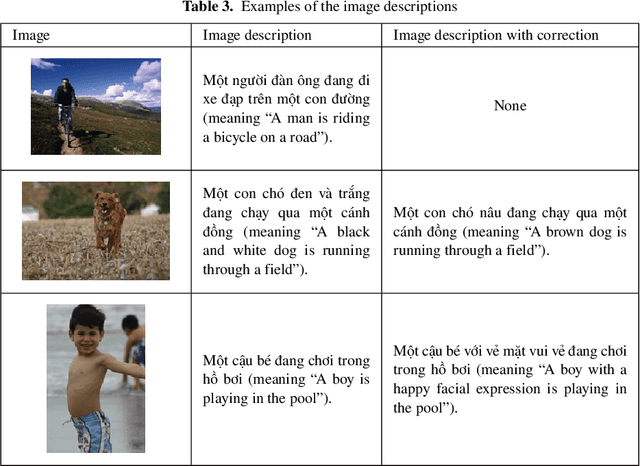
This paper discusses a facial expression recognition model and a description generation model to build descriptive sentences for images and facial expressions of people in images. Our study shows that YOLOv5 achieves better results than a traditional CNN for all emotions on the KDEF dataset. In particular, the accuracies of the CNN and YOLOv5 models for emotion recognition are 0.853 and 0.938, respectively. A model for generating descriptions for images based on a merged architecture is proposed using VGG16 with the descriptions encoded over an LSTM model. YOLOv5 is also used to recognize dominant colors of objects in the images and correct the color words in the descriptions generated if it is necessary. If the description contains words referring to a person, we recognize the emotion of the person in the image. Finally, we combine the results of all models to create sentences that describe the visual content and the human emotions in the images. Experimental results on the Flickr8k dataset in Vietnamese achieve BLEU-1, BLEU-2, BLEU-3, BLEU-4 scores of 0.628; 0.425; 0.280; and 0.174, respectively.
* 7 pages
Position-guided Text Prompt for Vision-Language Pre-training
Dec 19, 2022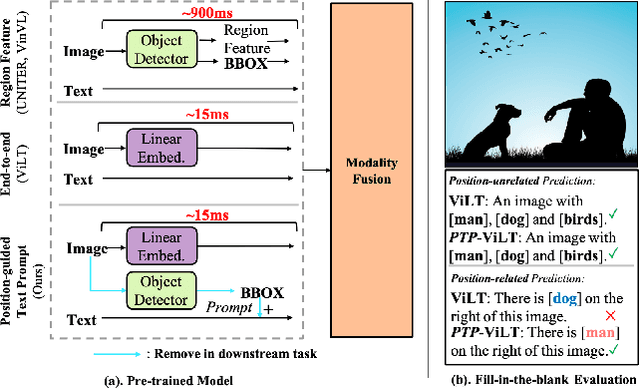
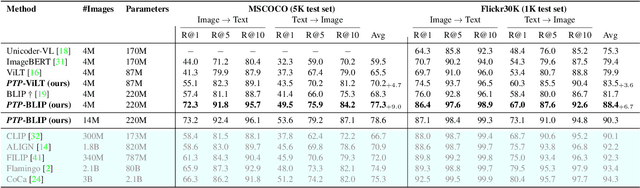
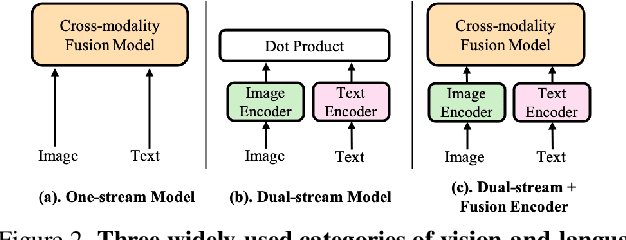
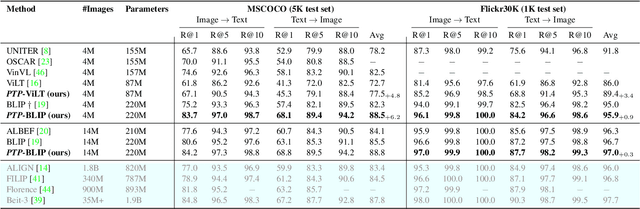
Vision-Language Pre-Training (VLP) has shown promising capabilities to align image and text pairs, facilitating a broad variety of cross-modal learning tasks. However, we observe that VLP models often lack the visual grounding/localization capability which is critical for many downstream tasks such as visual reasoning. In this work, we propose a novel Position-guided Text Prompt (PTP) paradigm to enhance the visual grounding ability of cross-modal models trained with VLP. Specifically, in the VLP phase, PTP divides the image into $N\times N$ blocks, and identifies the objects in each block through the widely used object detector in VLP. It then reformulates the visual grounding task into a fill-in-the-blank problem given a PTP by encouraging the model to predict the objects in the given blocks or regress the blocks of a given object, e.g. filling `P" or ``O" in aPTP ``The block P has a O". This mechanism improves the visual grounding capability of VLP models and thus helps them better handle various downstream tasks. By introducing PTP into several state-of-the-art VLP frameworks, we observe consistently significant improvements across representative cross-modal learning model architectures and several benchmarks, e.g. zero-shot Flickr30K Retrieval (+4.8 in average recall@1) for ViLT \cite{vilt} baseline, and COCO Captioning (+5.3 in CIDEr) for SOTA BLIP \cite{blip} baseline. Moreover, PTP achieves comparable results with object-detector based methods, and much faster inference speed since PTP discards its object detector for inference while the later cannot. Our code and pre-trained weight will be released at \url{https://github.com/sail-sg/ptp}.