 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation
May 07, 2025Recently, Large Language Models (LLMs) have achieved significant success, prompting increased interest in expanding their generative capabilities beyond general text into domain-specific areas. This study investigates the generation of parametric sequences for computer-aided design (CAD) models using LLMs. This endeavor represents an initial step towards creating parametric 3D shapes with LLMs, as CAD model parameters directly correlate with shapes in three-dimensional space. Despite the formidable generative capacities of LLMs, this task remains challenging, as these models neither encounter parametric sequences during their pretraining phase nor possess direct awareness of 3D structures. To address this, we present CAD-Llama, a framework designed to enhance pretrained LLMs for generating parametric 3D CAD models. Specifically, we develop a hierarchical annotation pipeline and a code-like format to translate parametric 3D CAD command sequences into Structured Parametric CAD Code (SPCC), incorporating hierarchical semantic descriptions. Furthermore, we propose an adaptive pretraining approach utilizing SPCC, followed by an instruction tuning process aligned with CAD-specific guidelines. This methodology aims to equip LLMs with the spatial knowledge inherent in parametric sequences. Experimental results demonstrate that our framework significantly outperforms prior autoregressive methods and existing LLM baselines.
PanoSwin: a Pano-style Swin Transformer for Panorama Understanding
Aug 28, 2023



In panorama understanding, the widely used equirectangular projection (ERP) entails boundary discontinuity and spatial distortion. It severely deteriorates the conventional CNNs and vision Transformers on panoramas. In this paper, we propose a simple yet effective architecture named PanoSwin to learn panorama representations with ERP. To deal with the challenges brought by equirectangular projection, we explore a pano-style shift windowing scheme and novel pitch attention to address the boundary discontinuity and the spatial distortion, respectively. Besides, based on spherical distance and Cartesian coordinates, we adapt absolute positional embeddings and relative positional biases for panoramas to enhance panoramic geometry information. Realizing that planar image understanding might share some common knowledge with panorama understanding, we devise a novel two-stage learning framework to facilitate knowledge transfer from the planar images to panoramas. We conduct experiments against the state-of-the-art on various panoramic tasks, i.e., panoramic object detection, panoramic classification, and panoramic layout estimation. The experimental results demonstrate the effectiveness of PanoSwin in panorama understanding.
3D-Augmented Contrastive Knowledge Distillation for Image-based Object Pose Estimation
Jun 02, 2022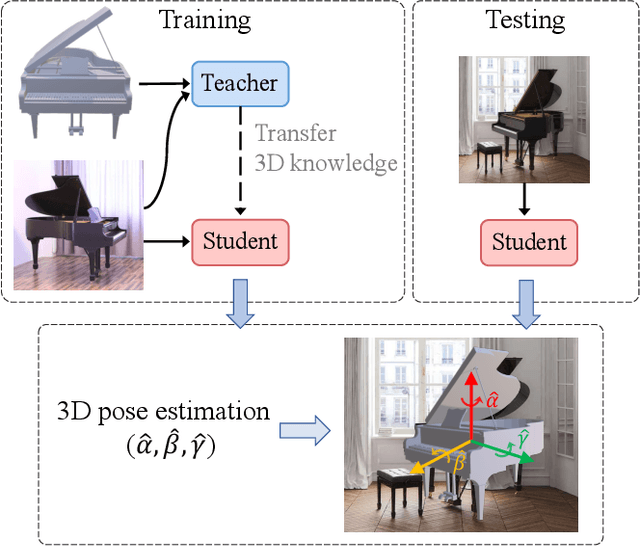
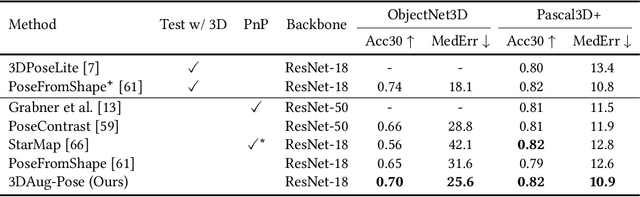
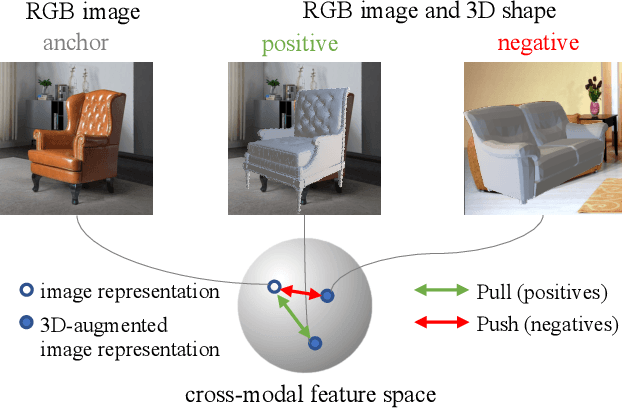
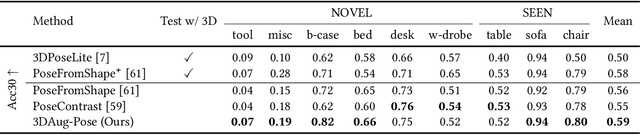
Image-based object pose estimation sounds amazing because in real applications the shape of object is oftentimes not available or not easy to take like photos. Although it is an advantage to some extent, un-explored shape information in 3D vision learning problem looks like "flaws in jade". In this paper, we deal with the problem in a reasonable new setting, namely 3D shape is exploited in the training process, and the testing is still purely image-based. We enhance the performance of image-based methods for category-agnostic object pose estimation by exploiting 3D knowledge learned by a multi-modal method. Specifically, we propose a novel contrastive knowledge distillation framework that effectively transfers 3D-augmented image representation from a multi-modal model to an image-based model. We integrate contrastive learning into the two-stage training procedure of knowledge distillation, which formulates an advanced solution to combine these two approaches for cross-modal tasks. We experimentally report state-of-the-art results compared with existing category-agnostic image-based methods by a large margin (up to +5% improvement on ObjectNet3D dataset), demonstrating the effectiveness of our method.