 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstractive Text Summarization Using the BRIO Training Paradigm
May 23, 2023



Summary sentences produced by abstractive summarization models may be coherent and comprehensive, but they lack control and rely heavily on reference summaries. The BRIO training paradigm assumes a non-deterministic distribution to reduce the model's dependence on reference summaries, and improve model performance during inference. This paper presents a straightforward but effective technique to improve abstractive summaries by fine-tuning pre-trained language models, and training them with the BRIO paradigm. We build a text summarization dataset for Vietnamese, called VieSum. We perform experiments with abstractive summarization models trained with the BRIO paradigm on the CNNDM and the VieSum datasets. The results show that the models, trained on basic hardware, outperform all existing abstractive summarization models, especially for Vietnamese.
* 6 pages, Findings of the Association for Computational Linguistics: ACL 2023
Facial Expression Recognition and Image Description Generation in Vietnamese
Aug 12, 2022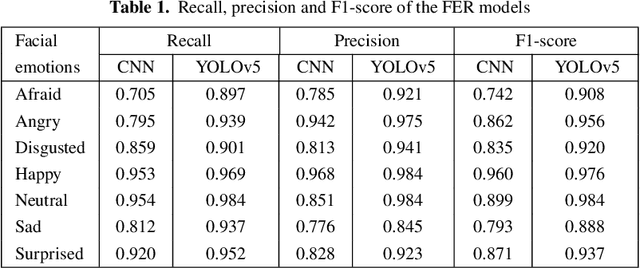
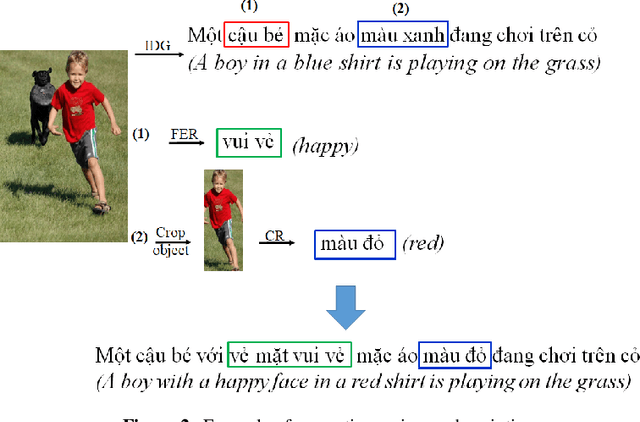

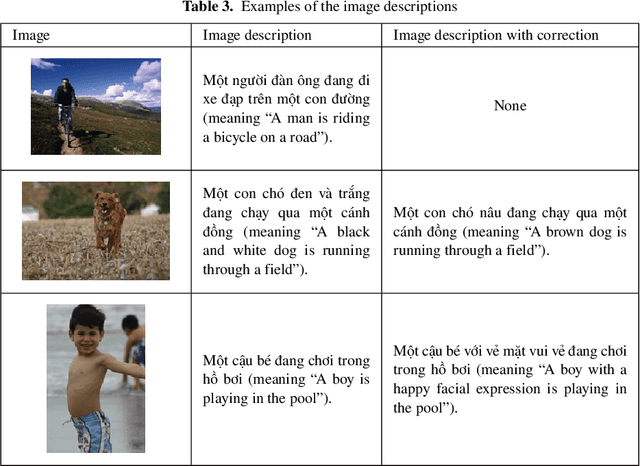
This paper discusses a facial expression recognition model and a description generation model to build descriptive sentences for images and facial expressions of people in images. Our study shows that YOLOv5 achieves better results than a traditional CNN for all emotions on the KDEF dataset. In particular, the accuracies of the CNN and YOLOv5 models for emotion recognition are 0.853 and 0.938, respectively. A model for generating descriptions for images based on a merged architecture is proposed using VGG16 with the descriptions encoded over an LSTM model. YOLOv5 is also used to recognize dominant colors of objects in the images and correct the color words in the descriptions generated if it is necessary. If the description contains words referring to a person, we recognize the emotion of the person in the image. Finally, we combine the results of all models to create sentences that describe the visual content and the human emotions in the images. Experimental results on the Flickr8k dataset in Vietnamese achieve BLEU-1, BLEU-2, BLEU-3, BLEU-4 scores of 0.628; 0.425; 0.280; and 0.174, respectively.
* 7 pages
Automatically Creating a Large Number of New Bilingual Dictionaries
Aug 12, 2022
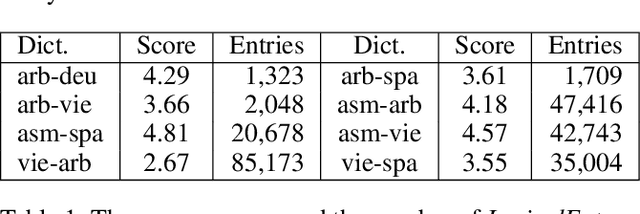
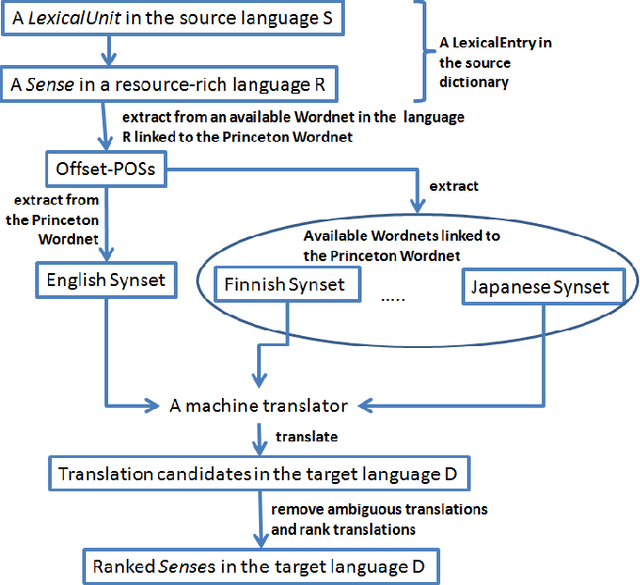
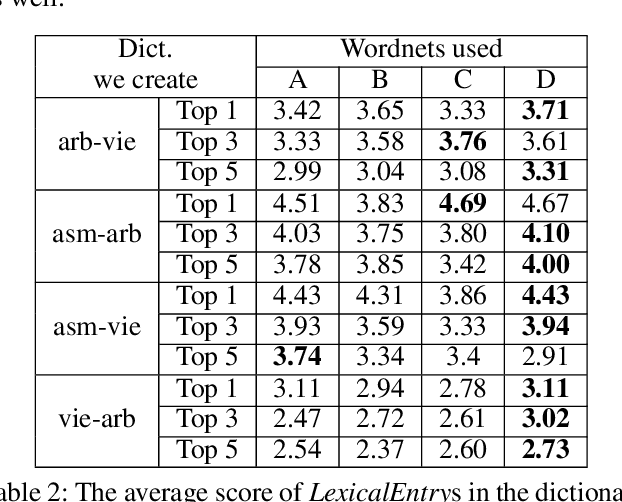
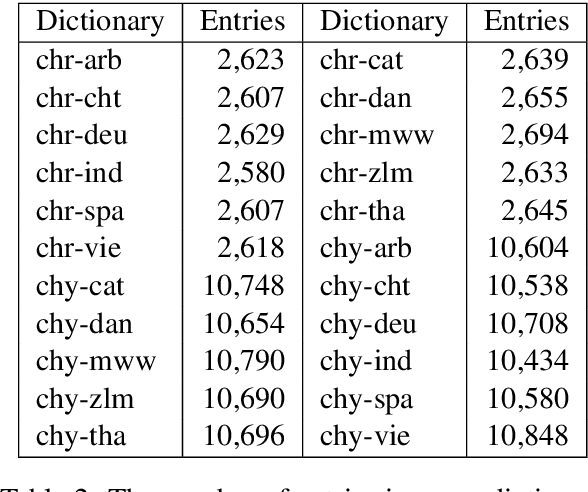
This paper proposes approaches to automatically create a large number of new bilingual dictionaries for low-resource languages, especially resource-poor and endangered languages, from a single input bilingual dictionary. Our algorithms produce translations of words in a source language to plentiful target languages using available Wordnets and a machine translator (MT). Since our approaches rely on just one input dictionary, available Wordnets and an MT, they are applicable to any bilingual dictionary as long as one of the two languages is English or has a Wordnet linked to the Princeton Wordnet. Starting with 5 available bilingual dictionaries, we create 48 new bilingual dictionaries. Of these, 30 pairs of languages are not supported by the popular MTs: Google and Bing.
* 7 pages
Using Artificial Intelligence and IoT for Constructing a Smart Trash Bin
Aug 12, 2022The research reported in this paper transforms a normal trash bin into a smarter one by applying computer vision technology. With the support of sensors and actuator devices, the trash bin can automatically classify garbage. In particular, a camera on the trash bin takes pictures of trash, then the central processing unit analyzes and makes decisions regarding which bin to drop trash into. The accuracy of our trash bin system achieves 90%. Besides, our model is connected to the Internet to update the bin status for further management. A mobile application is developed for managing the bin.
* 8 pages
Building a Chatbot on a Closed Domain using RASA
Aug 12, 2022
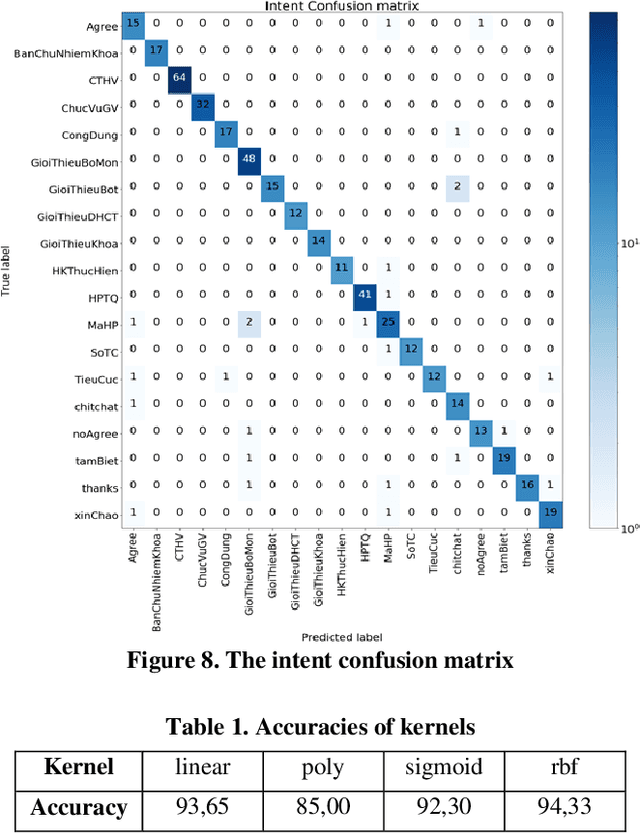

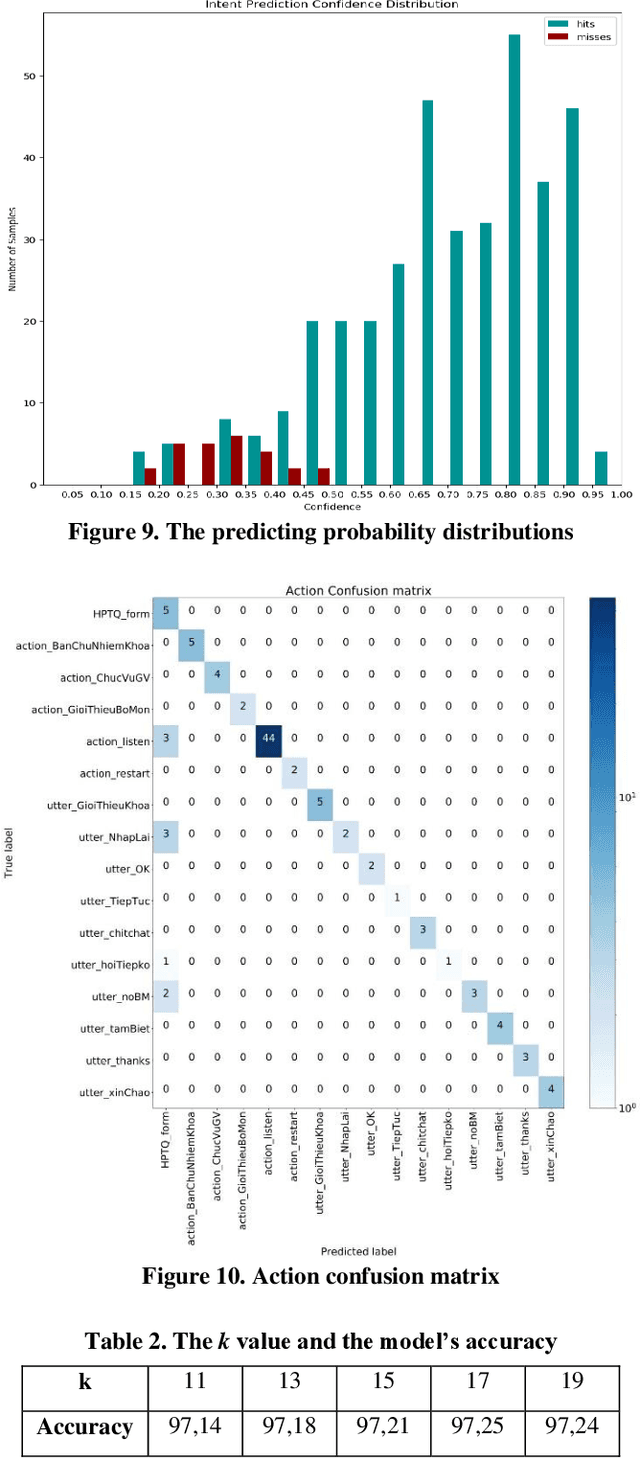
In this study, we build a chatbot system in a closed domain with the RASA framework, using several models such as SVM for classifying intents, CRF for extracting entities and LSTM for predicting action. To improve responses from the bot, the kNN algorithm is used to transform false entities extracted into true entities. The knowledge domain of our chatbot is about the College of Information and Communication Technology of Can Tho University, Vietnam. We manually construct a chatbot corpus with 19 intents, 441 sentence patterns of intents, 253 entities and 133 stories. Experiment results show that the bot responds well to relevant questions.
* 5 pages
Creating Lexical Resources for Endangered Languages
Aug 08, 2022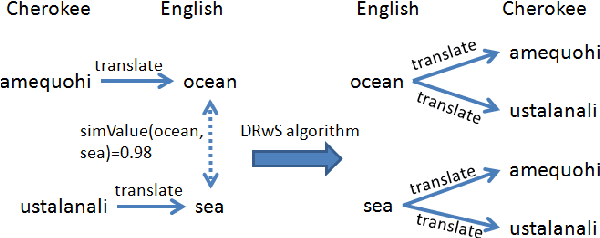
This paper examines approaches to generate lexical resources for endangered languages. Our algorithms construct bilingual dictionaries and multilingual thesauruses using public Wordnets and a machine translator (MT). Since our work relies on only one bilingual dictionary between an endangered language and an "intermediate helper" language, it is applicable to languages that lack many existing resources.
* 9 pages
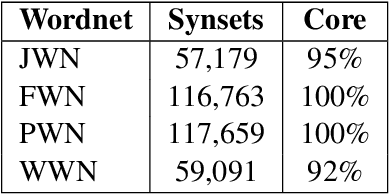
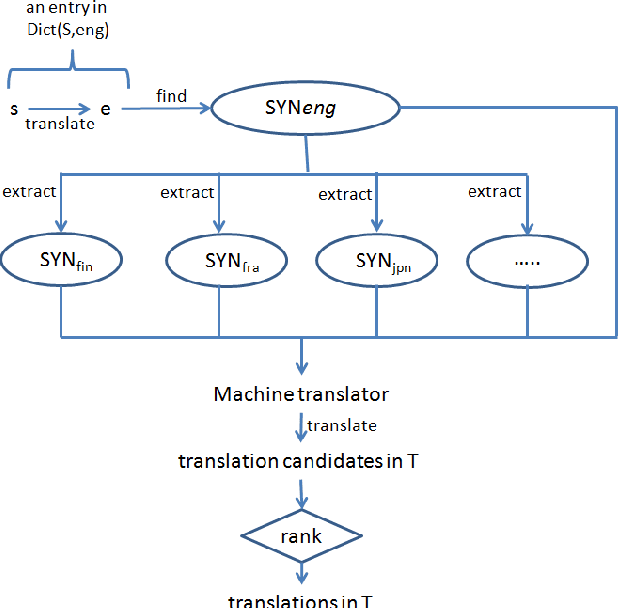
Automatically constructing Wordnet synsets
Aug 08, 2022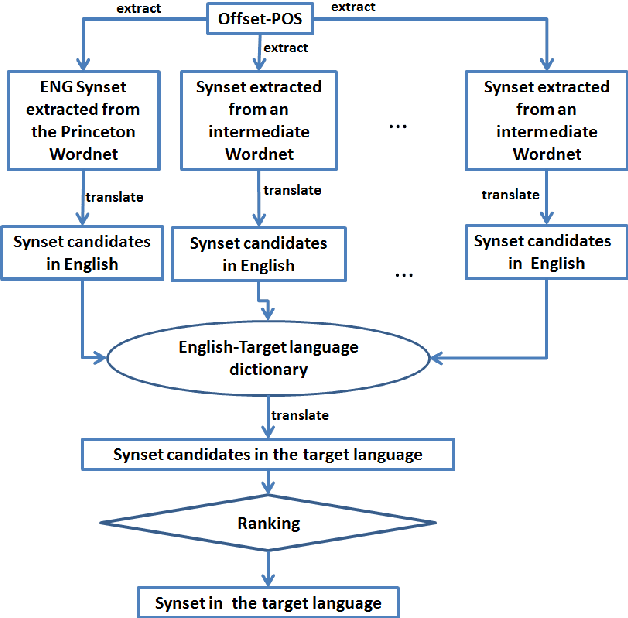
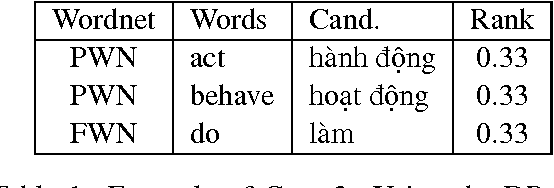
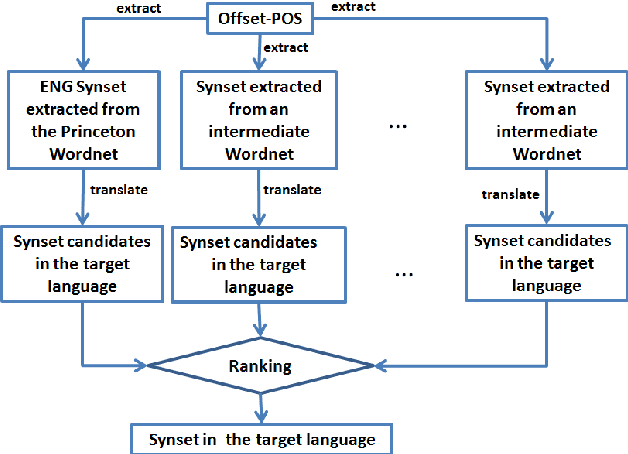
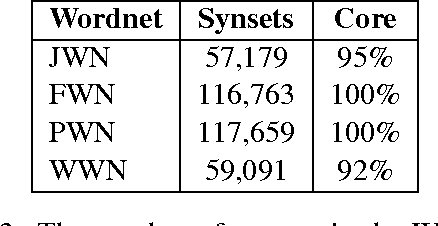
Manually constructing a Wordnet is a difficult task, needing years of experts' time. As a first step to automatically construct full Wordnets, we propose approaches to generate Wordnet synsets for languages both resource-rich and resource-poor, using publicly available Wordnets, a machine translator and/or a single bilingual dictionary. Our algorithms translate synsets of existing Wordnets to a target language T, then apply a ranking method on the translation candidates to find best translations in T. Our approaches are applicable to any language which has at least one existing bilingual dictionary translating from English to it.
* 6 pages
Creating Reverse Bilingual Dictionaries
Aug 08, 2022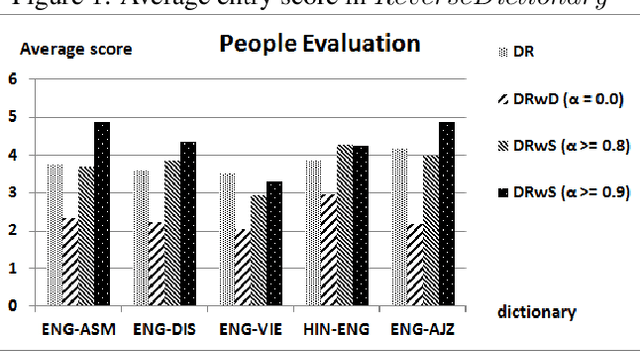
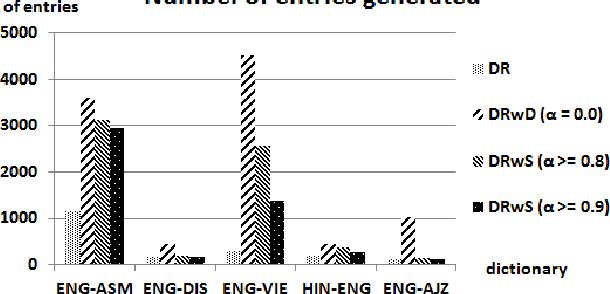
Bilingual dictionaries are expensive resources and not many are available when one of the languages is resource-poor. In this paper, we propose algorithms for creation of new reverse bilingual dictionaries from existing bilingual dictionaries in which English is one of the two languages. Our algorithms exploit the similarity between word-concept pairs using the English Wordnet to produce reverse dictionary entries. Since our algorithms rely on available bilingual dictionaries, they are applicable to any bilingual dictionary as long as one of the two languages has Wordnet type lexical ontology.
* 5 pages
Phrase translation using a bilingual dictionary and n-gram data: A case study from Vietnamese to English
Aug 05, 2022
Past approaches to translate a phrase in a language L1 to a language L2 using a dictionary-based approach require grammar rules to restructure initial translations. This paper introduces a novel method without using any grammar rules to translate a given phrase in L1, which does not exist in the dictionary, to L2. We require at least one L1-L2 bilingual dictionary and n-gram data in L2. The average manual evaluation score of our translations is 4.29/5.00, which implies very high quality.
* 5 pages