 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Connectivity-constrained Interactive Panoptic Segmentation
Dec 13, 2022

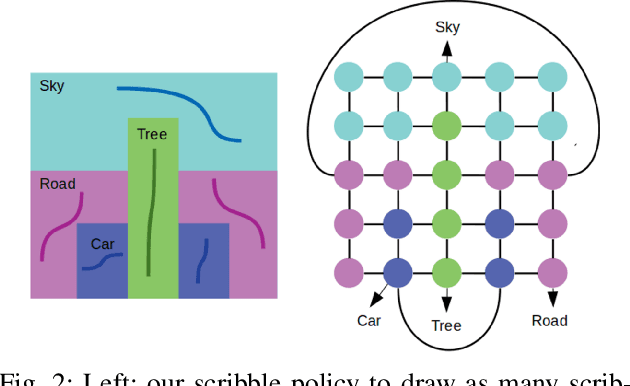

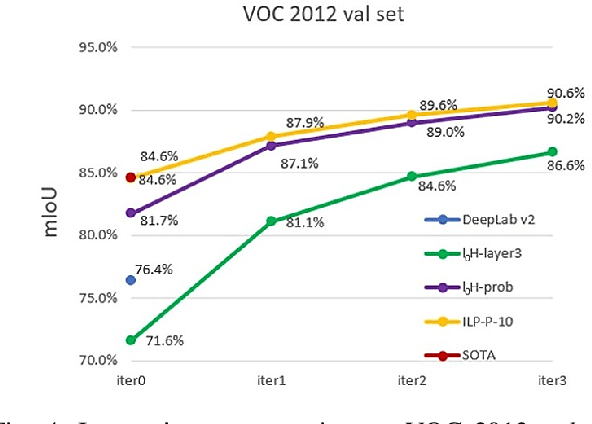
We address interactive panoptic annotation, where one segment all object and stuff regions in an image. We investigate two graph-based segmentation algorithms that both enforce connectivity of each region, with a notable class-aware Integer Linear Programming (ILP) formulation that ensures global optimum. Both algorithms can take RGB, or utilize the feature maps from any DCNN, whether trained on the target dataset or not, as input. We then propose an interactive, scribble-based annotation framework.
Active learning using adaptable task-based prioritisation
Dec 03, 2022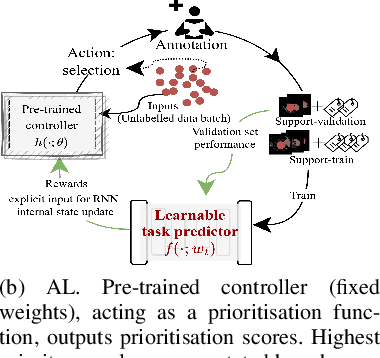
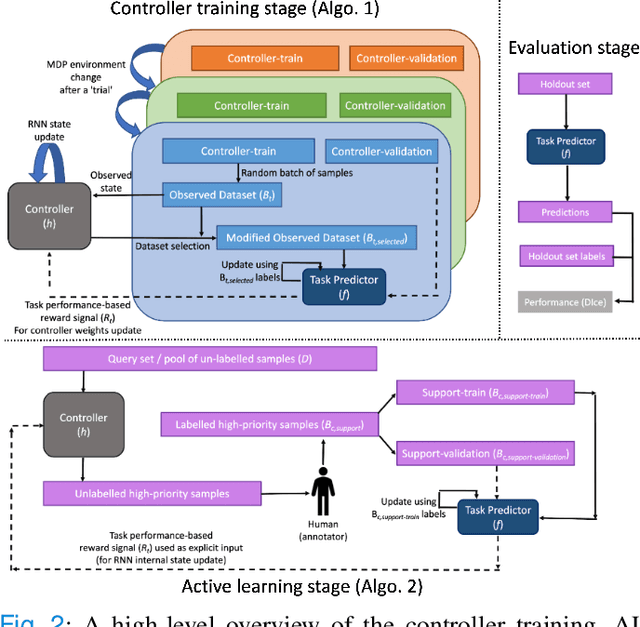
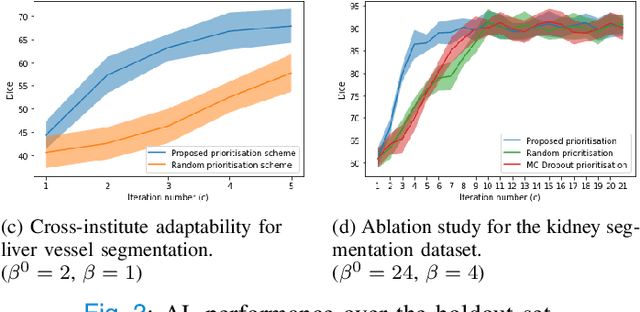
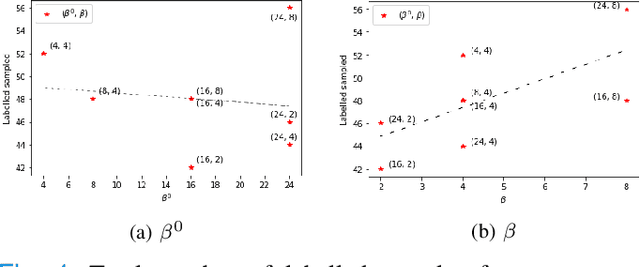
Supervised machine learning-based medical image computing applications necessitate expert label curation, while unlabelled image data might be relatively abundant. Active learning methods aim to prioritise a subset of available image data for expert annotation, for label-efficient model training. We develop a controller neural network that measures priority of images in a sequence of batches, as in batch-mode active learning, for multi-class segmentation tasks. The controller is optimised by rewarding positive task-specific performance gain, within a Markov decision process (MDP) environment that also optimises the task predictor. In this work, the task predictor is a segmentation network. A meta-reinforcement learning algorithm is proposed with multiple MDPs, such that the pre-trained controller can be adapted to a new MDP that contains data from different institutes and/or requires segmentation of different organs or structures within the abdomen. We present experimental results using multiple CT datasets from more than one thousand patients, with segmentation tasks of nine different abdominal organs, to demonstrate the efficacy of the learnt prioritisation controller function and its cross-institute and cross-organ adaptability. We show that the proposed adaptable prioritisation metric yields converging segmentation accuracy for the novel class of kidney, unseen in training, using between approximately 40\% to 60\% of labels otherwise required with other heuristic or random prioritisation metrics. For clinical datasets of limited size, the proposed adaptable prioritisation offers a performance improvement of 22.6\% and 10.2\% in Dice score, for tasks of kidney and liver vessel segmentation, respectively, compared to random prioritisation and alternative active sampling strategies.
SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction
Dec 04, 2022


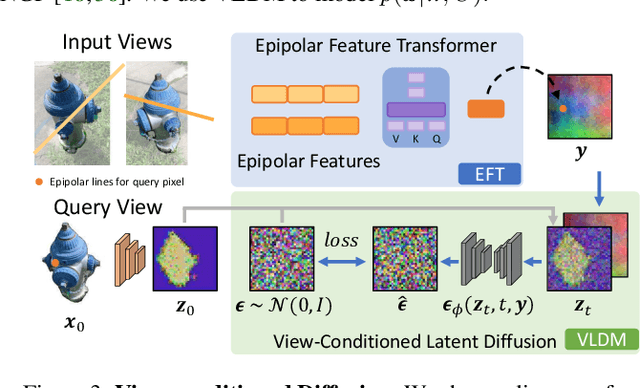
We propose SparseFusion, a sparse view 3D reconstruction approach that unifies recent advances in neural rendering and probabilistic image generation. Existing approaches typically build on neural rendering with re-projected features but fail to generate unseen regions or handle uncertainty under large viewpoint changes. Alternate methods treat this as a (probabilistic) 2D synthesis task, and while they can generate plausible 2D images, they do not infer a consistent underlying 3D. However, we find that this trade-off between 3D consistency and probabilistic image generation does not need to exist. In fact, we show that geometric consistency and generative inference can be complementary in a mode-seeking behavior. By distilling a 3D consistent scene representation from a view-conditioned latent diffusion model, we are able to recover a plausible 3D representation whose renderings are both accurate and realistic. We evaluate our approach across 51 categories in the CO3D dataset and show that it outperforms existing methods, in both distortion and perception metrics, for sparse-view novel view synthesis.
Rethinking Disparity: A Depth Range Free Multi-View Stereo Based on Disparity
Dec 04, 2022
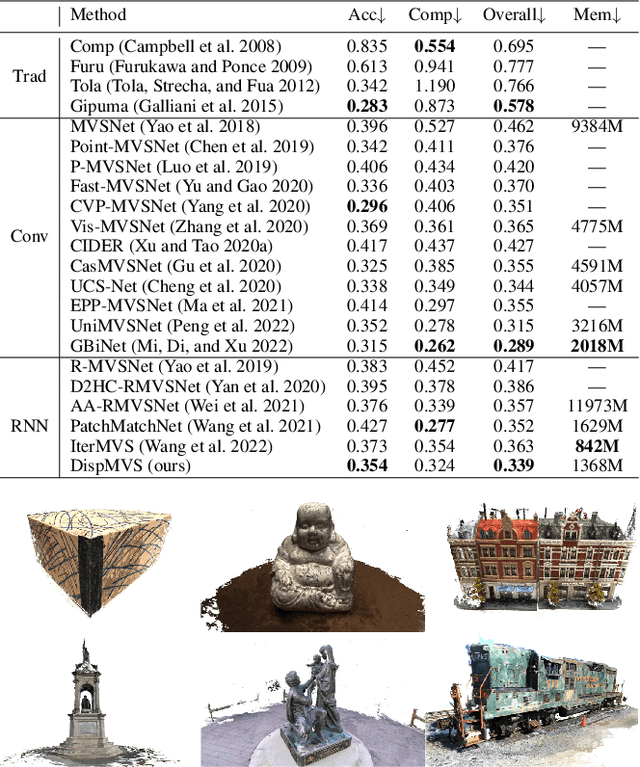
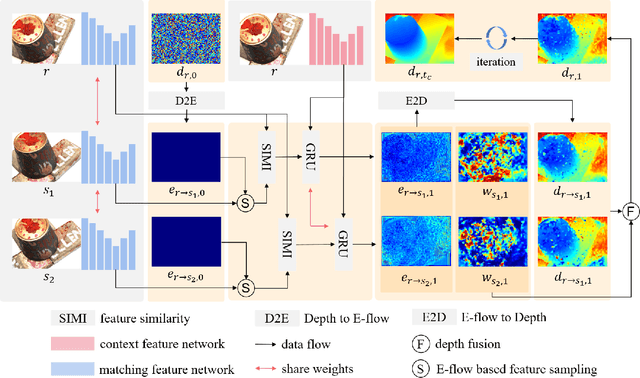
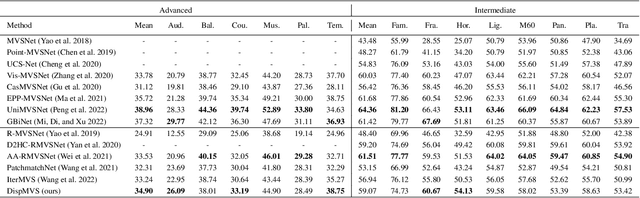
Existing learning-based multi-view stereo (MVS) methods rely on the depth range to build the 3D cost volume and may fail when the range is too large or unreliable. To address this problem, we propose a disparity-based MVS method based on the epipolar disparity flow (E-flow), called DispMVS, which infers the depth information from the pixel movement between two views. The core of DispMVS is to construct a 2D cost volume on the image plane along the epipolar line between each pair (between the reference image and several source images) for pixel matching and fuse uncountable depths triangulated from each pair by multi-view geometry to ensure multi-view consistency. To be robust, DispMVS starts from a randomly initialized depth map and iteratively refines the depth map with the help of the coarse-to-fine strategy. Experiments on DTUMVS and Tanks\&Temple datasets show that DispMVS is not sensitive to the depth range and achieves state-of-the-art results with lower GPU memory.
RUPNet: Residual upsampling network for real-time polyp segmentation
Jan 06, 2023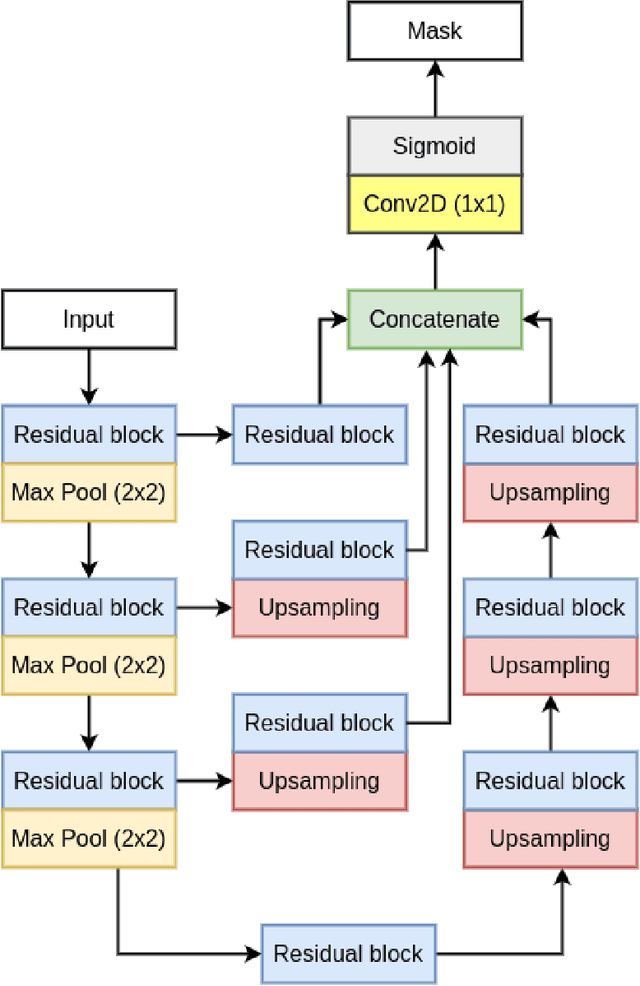
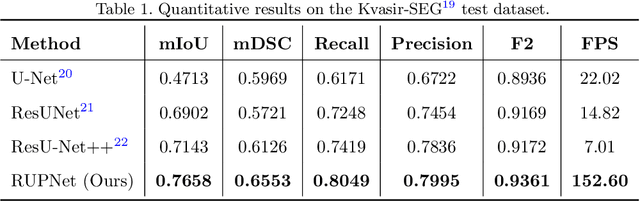
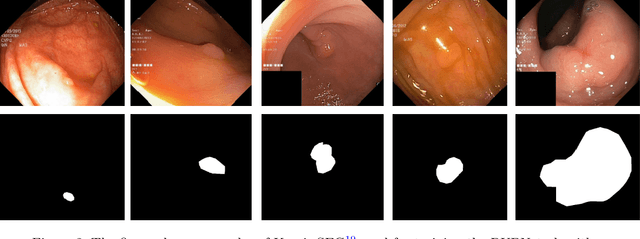
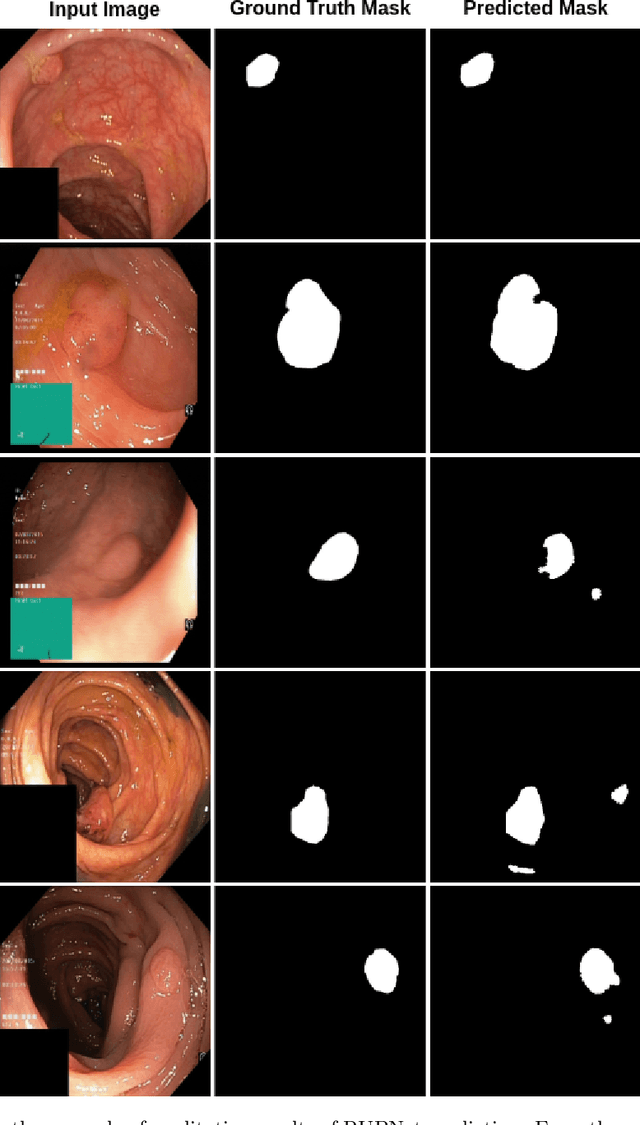
Colorectal cancer is among the most prevalent cause of cancer-related mortality worldwide. Detection and removal of polyps at an early stage can help reduce mortality and even help in spreading over adjacent organs. Early polyp detection could save the lives of millions of patients over the world as well as reduce the clinical burden. However, the detection polyp rate varies significantly among endoscopists. There is numerous deep learning-based method proposed, however, most of the studies improve accuracy. Here, we propose a novel architecture, Residual Upsampling Network (RUPNet) for colon polyp segmentation that can process in real-time and show high recall and precision. The proposed architecture, RUPNet, is an encoder-decoder network that consists of three encoders, three decoder blocks, and some additional upsampling blocks at the end of the network. With an image size of $512 \times 512$, the proposed method achieves an excellent real-time operation speed of 152.60 frames per second with an average dice coefficient of 0.7658, mean intersection of union of 0.6553, sensitivity of 0.8049, precision of 0.7995, and F2-score of 0.9361. The results suggest that RUPNet can give real-time feedback while retaining high accuracy indicating a good benchmark for early polyp detection.
Object as Query: Equipping Any 2D Object Detector with 3D Detection Ability
Jan 06, 2023
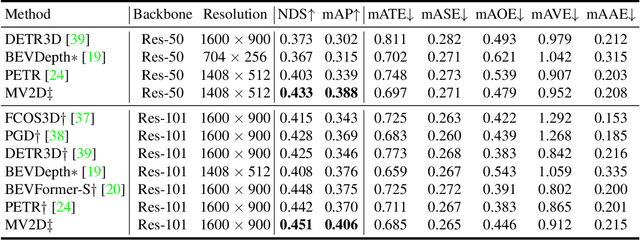
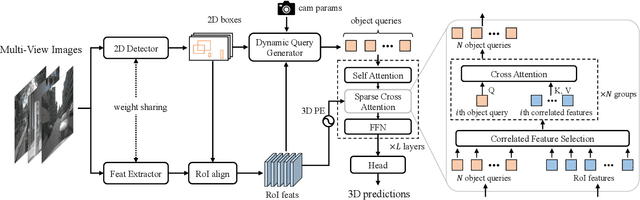
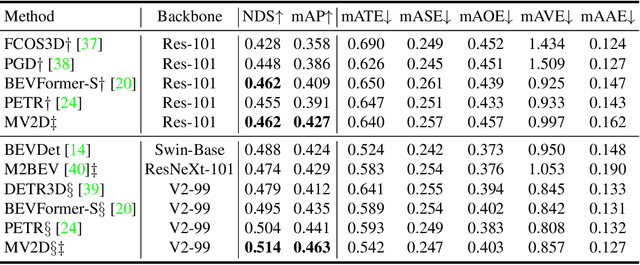
3D object detection from multi-view images has drawn much attention over the past few years. Existing methods mainly establish 3D representations from multi-view images and adopt a dense detection head for object detection, or employ object queries distributed in 3D space to localize objects. In this paper, we design Multi-View 2D Objects guided 3D Object Detector (MV2D), which can be equipped with any 2D object detector to promote multi-view 3D object detection. Since 2D detections can provide valuable priors for object existence, MV2D exploits 2D detector to generate object queries conditioned on the rich image semantics. These dynamically generated queries enable MV2D to detect objects in larger 3D space without increased computational costs and shows a strong capability of localizing 3D objects. For the generated queries, we design a sparse cross attention module to force them to focus on the features of specific objects, which reduces the computational cost and suppresses interference from noises. The evaluation results on the nuScenes dataset demonstrate that dynamic object queries and sparse feature aggregation do not harm 3D detection capability. MV2D also exhibits a state-of-the-art performance among existing methods. We hope MV2D can serve as a new baseline for future research.
EurNet: Efficient Multi-Range Relational Modeling of Spatial Multi-Relational Data
Nov 23, 2022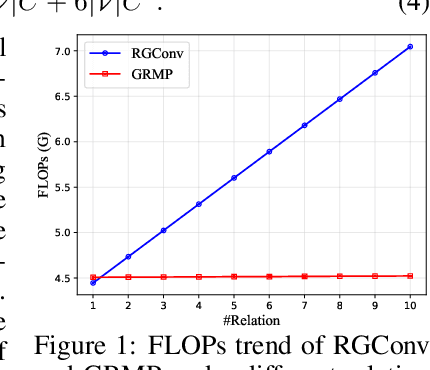
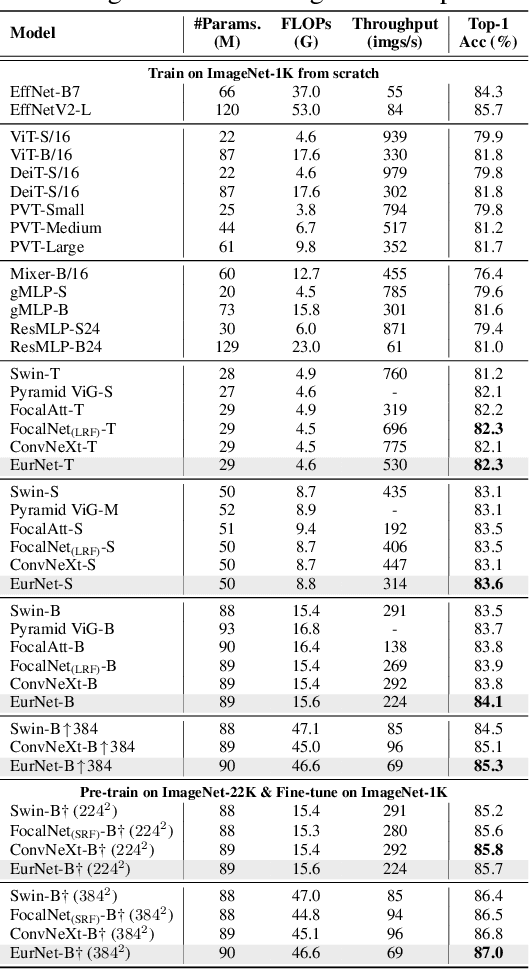
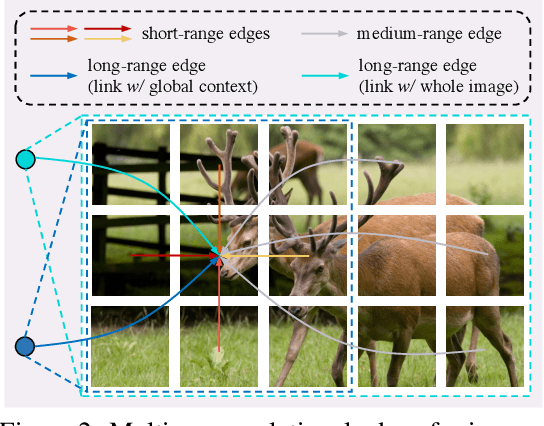
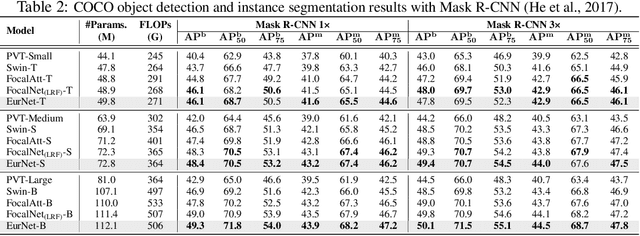
Modeling spatial relationship in the data remains critical across many different tasks, such as image classification, semantic segmentation and protein structure understanding. Previous works often use a unified solution like relative positional encoding. However, there exists different kinds of spatial relations, including short-range, medium-range and long-range relations, and modeling them separately can better capture the focus of different tasks on the multi-range relations (e.g., short-range relations can be important in instance segmentation, while long-range relations should be upweighted for semantic segmentation). In this work, we introduce the EurNet for Efficient multi-range relational modeling. EurNet constructs the multi-relational graph, where each type of edge corresponds to short-, medium- or long-range spatial interactions. In the constructed graph, EurNet adopts a novel modeling layer, called gated relational message passing (GRMP), to propagate multi-relational information across the data. GRMP captures multiple relations within the data with little extra computational cost. We study EurNets in two important domains for image and protein structure modeling. Extensive experiments on ImageNet classification, COCO object detection and ADE20K semantic segmentation verify the gains of EurNet over the previous SoTA FocalNet. On the EC and GO protein function prediction benchmarks, EurNet consistently surpasses the previous SoTA GearNet. Our results demonstrate the strength of EurNets on modeling spatial multi-relational data from various domains. The implementations of EurNet for image modeling are available at https://github.com/hirl-team/EurNet-Image . The implementations for other applied domains/tasks will be released soon.
A Call to Reflect on Evaluation Practices for Failure Detection in Image Classification
Nov 28, 2022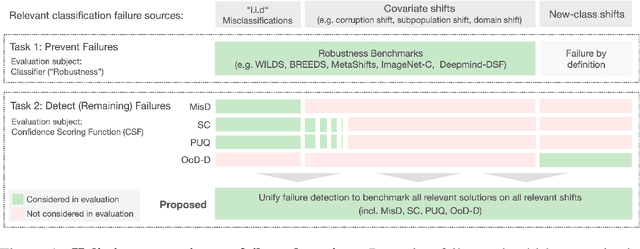
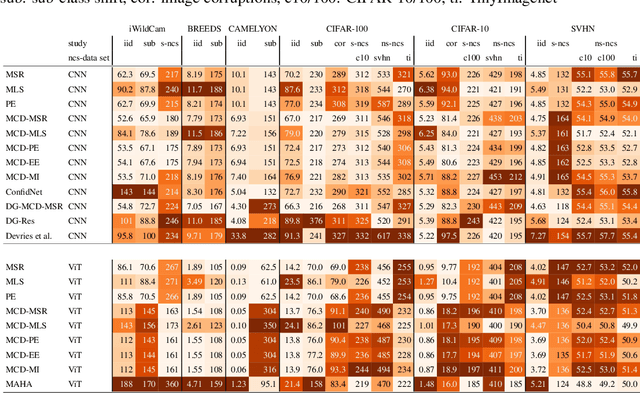
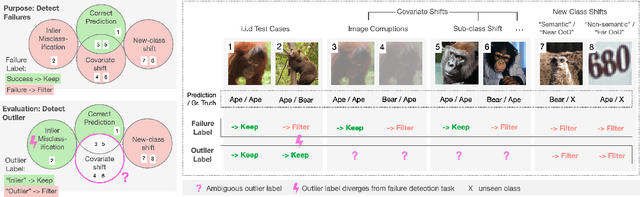
Reliable application of machine learning-based decision systems in the wild is one of the major challenges currently investigated by the field. A large portion of established approaches aims to detect erroneous predictions by means of assigning confidence scores. This confidence may be obtained by either quantifying the model's predictive uncertainty, learning explicit scoring functions, or assessing whether the input is in line with the training distribution. Curiously, while these approaches all state to address the same eventual goal of detecting failures of a classifier upon real-life application, they currently constitute largely separated research fields with individual evaluation protocols, which either exclude a substantial part of relevant methods or ignore large parts of relevant failure sources. In this work, we systematically reveal current pitfalls caused by these inconsistencies and derive requirements for a holistic and realistic evaluation of failure detection. To demonstrate the relevance of this unified perspective, we present a large-scale empirical study for the first time enabling benchmarking confidence scoring functions w.r.t all relevant methods and failure sources. The revelation of a simple softmax response baseline as the overall best performing method underlines the drastic shortcomings of current evaluation in the abundance of publicized research on confidence scoring. Code and trained models are at https://github.com/IML-DKFZ/fd-shifts.
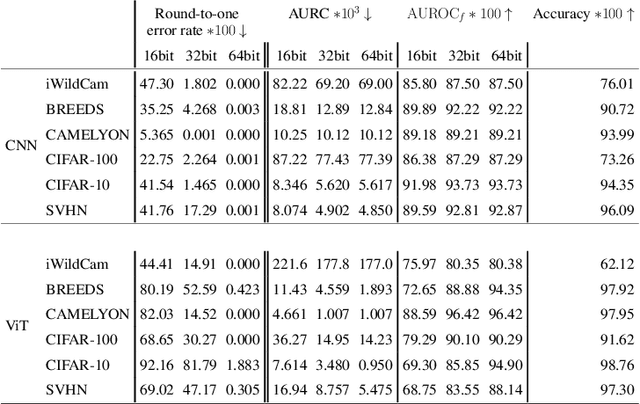
RankDNN: Learning to Rank for Few-shot Learning
Nov 29, 2022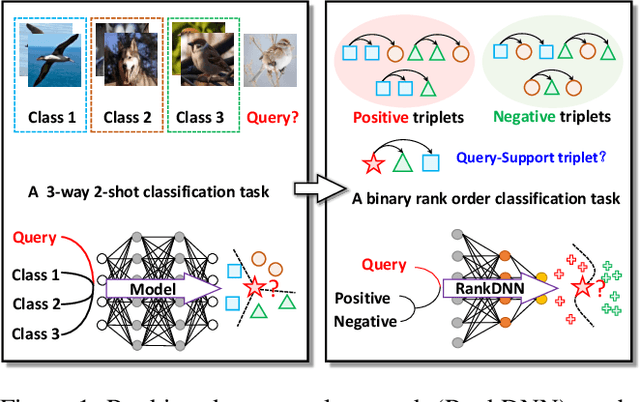
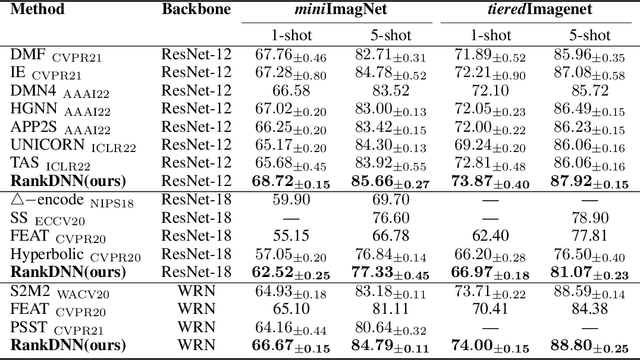
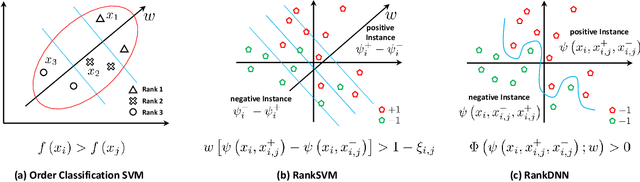
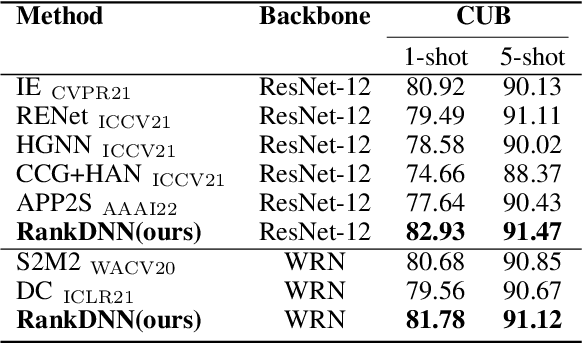
This paper introduces a new few-shot learning pipeline that casts relevance ranking for image retrieval as binary ranking relation classification. In comparison to image classification, ranking relation classification is sample efficient and domain agnostic. Besides, it provides a new perspective on few-shot learning and is complementary to state-of-the-art methods. The core component of our deep neural network is a simple MLP, which takes as input an image triplet encoded as the difference between two vector-Kronecker products, and outputs a binary relevance ranking order. The proposed RankMLP can be built on top of any state-of-the-art feature extractors, and our entire deep neural network is called the ranking deep neural network, or RankDNN. Meanwhile, RankDNN can be flexibly fused with other post-processing methods. During the meta test, RankDNN ranks support images according to their similarity with the query samples, and each query sample is assigned the class label of its nearest neighbor. Experiments demonstrate that RankDNN can effectively improve the performance of its baselines based on a variety of backbones and it outperforms previous state-of-the-art algorithms on multiple few-shot learning benchmarks, including miniImageNet, tieredImageNet, Caltech-UCSD Birds, and CIFAR-FS. Furthermore, experiments on the cross-domain challenge demonstrate the superior transferability of RankDNN.The code is available at: https://github.com/guoqianyu-alberta/RankDNN.
Learning to Perceive in Deep Model-Free Reinforcement Learning
Jan 10, 2023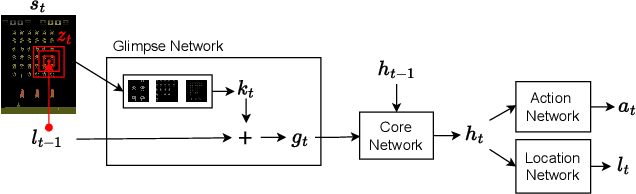

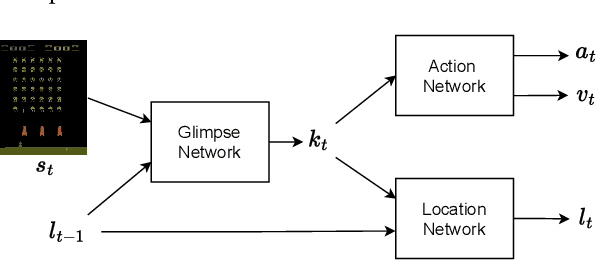
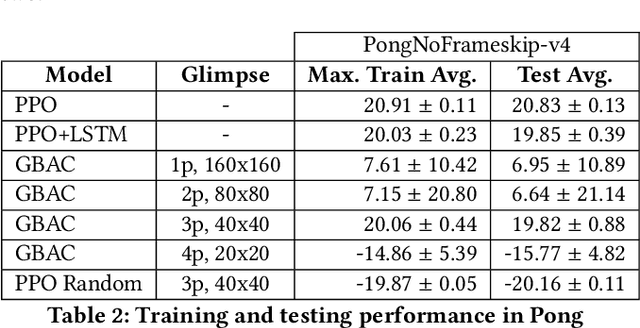
This work proposes a novel model-free Reinforcement Learning (RL) agent that is able to learn how to complete an unknown task having access to only a part of the input observation. We take inspiration from the concepts of visual attention and active perception that are characteristic of humans and tried to apply them to our agent, creating a hard attention mechanism. In this mechanism, the model decides first which region of the input image it should look at, and only after that it has access to the pixels of that region. Current RL agents do not follow this principle and we have not seen these mechanisms applied to the same purpose as this work. In our architecture, we adapt an existing model called recurrent attention model (RAM) and combine it with the proximal policy optimization (PPO) algorithm. We investigate whether a model with these characteristics is capable of achieving similar performance to state-of-the-art model-free RL agents that access the full input observation. This analysis is made in two Atari games, Pong and SpaceInvaders, which have a discrete action space, and in CarRacing, which has a continuous action space. Besides assessing its performance, we also analyze the movement of the attention of our model and compare it with what would be an example of the human behavior. Even with such visual limitation, we show that our model matches the performance of PPO+LSTM in two of the three games tested.