 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFish Audio S2 Technical Report
Mar 11, 2026We introduce Fish Audio S2, an open-sourced text-to-speech system featuring multi-speaker, multi-turn generation, and, most importantly, instruction-following control via natural-language descriptions. To scale training, we develop a multi-stage training recipe together with a staged data pipeline covering video captioning and speech captioning, voice-quality assessment, and reward modeling. To push the frontier of open-source TTS, we release our model weights, fine-tuning code, and an SGLang-based inference engine. The inference engine is production-ready for streaming, achieving an RTF of 0.195 and a time-to-first-audio below 100 ms.Our code and weights are available on GitHub (https://github.com/fishaudio/fish-speech) and Hugging Face (https://huggingface.co/fishaudio/s2-pro). We highly encourage readers to visit https://fish.audio to try custom voices.
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Apr 04, 2024



We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction
Dec 04, 2022



We propose SparseFusion, a sparse view 3D reconstruction approach that unifies recent advances in neural rendering and probabilistic image generation. Existing approaches typically build on neural rendering with re-projected features but fail to generate unseen regions or handle uncertainty under large viewpoint changes. Alternate methods treat this as a (probabilistic) 2D synthesis task, and while they can generate plausible 2D images, they do not infer a consistent underlying 3D. However, we find that this trade-off between 3D consistency and probabilistic image generation does not need to exist. In fact, we show that geometric consistency and generative inference can be complementary in a mode-seeking behavior. By distilling a 3D consistent scene representation from a view-conditioned latent diffusion model, we are able to recover a plausible 3D representation whose renderings are both accurate and realistic. We evaluate our approach across 51 categories in the CO3D dataset and show that it outperforms existing methods, in both distortion and perception metrics, for sparse-view novel view synthesis.
Audrey: A Personalized Open-Domain Conversational Bot
Nov 11, 2020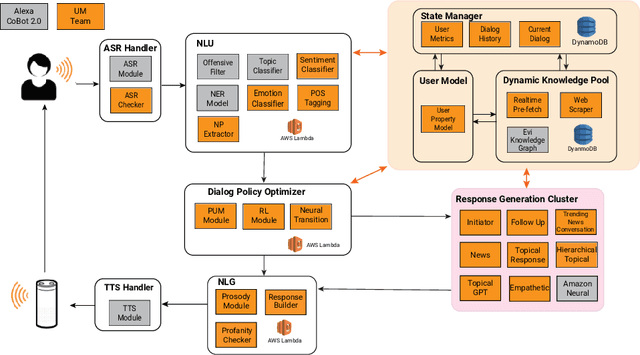


Conversational Intelligence requires that a person engage on informational, personal and relational levels. Advances in Natural Language Understanding have helped recent chatbots succeed at dialog on the informational level. However, current techniques still lag for conversing with humans on a personal level and fully relating to them. The University of Michigan's submission to the Alexa Prize Grand Challenge 3, Audrey, is an open-domain conversational chat-bot that aims to engage customers on these levels through interest driven conversations guided by customers' personalities and emotions. Audrey is built from socially-aware models such as Emotion Detection and a Personal Understanding Module to grasp a deeper understanding of users' interests and desires. Our architecture interacts with customers using a hybrid approach balanced between knowledge-driven response generators and context-driven neural response generators to cater to all three levels of conversations. During the semi-finals period, we achieved an average cumulative rating of 3.25 on a 1-5 Likert scale.