 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A direct time-of-flight image sensor with in-pixel surface detection and dynamic vision
Sep 23, 2022
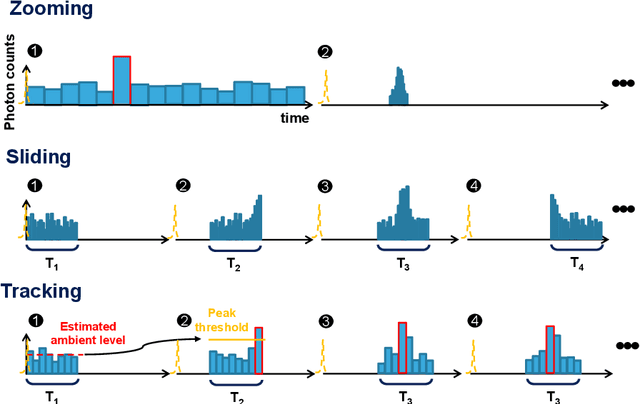
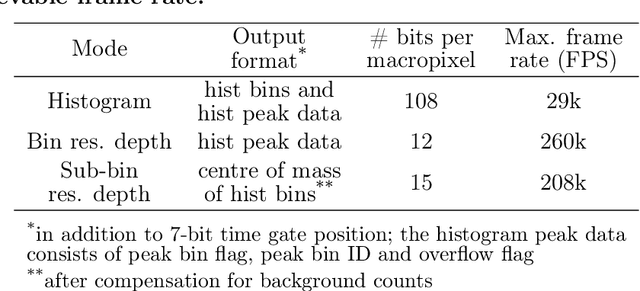
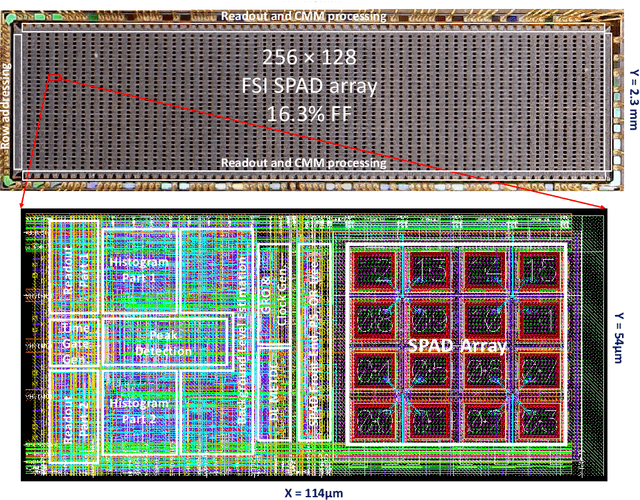
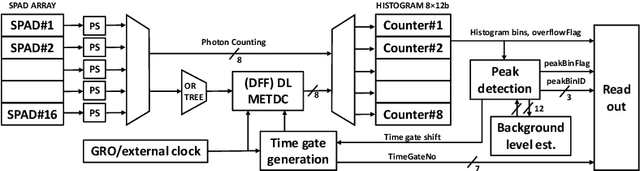
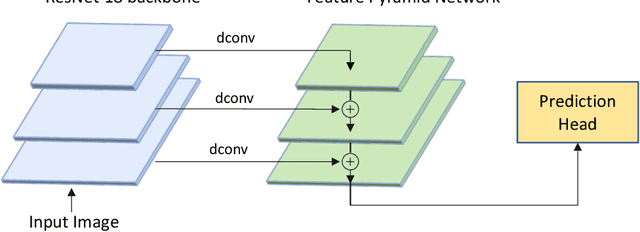
3D flash LIDAR is an alternative to the traditional scanning LIDAR systems, promising precise depth imaging in a compact form factor, and free of moving parts, for applications such as self-driving cars, robotics and augmented reality (AR). Typically implemented using single-photon, direct time-of-flight (dToF) receivers in image sensor format, the operation of the devices can be hindered by the large number of photon events needing to be processed and compressed in outdoor scenarios, limiting frame rates and scalability to larger arrays. We here present a 64x32 pixel (256x128 SPAD) dToF imager that overcomes these limitations by using pixels with embedded histogramming, which lock onto and track the return signal. This reduces the size of output data frames considerably, enabling maximum frame rates in the 10 kFPS range or 100 kFPS for direct depth readings. The sensor offers selective readout of pixels detecting surfaces, or those sensing motion, leading to reduced power consumption and off-chip processing requirements. We demonstrate the application of the sensor in mid-range LIDAR.
DALLE-URBAN: Capturing the urban design expertise of large text to image transformers
Aug 03, 2022
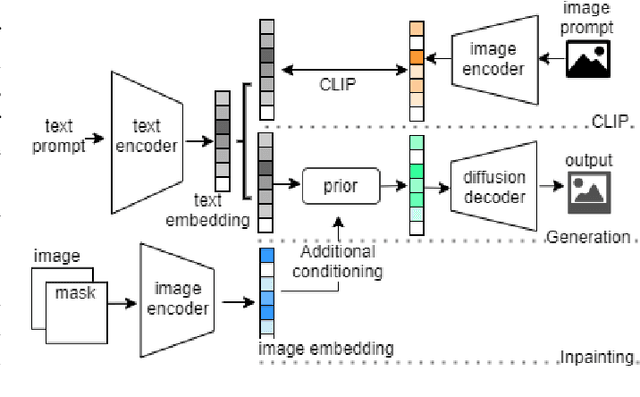

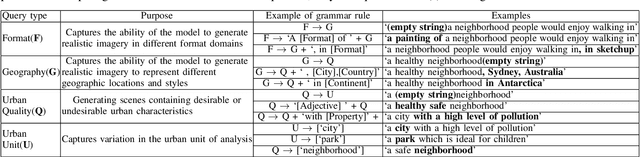
Automatically converting text descriptions into images using transformer architectures has recently received considerable attention. Such advances have implications for many applied design disciplines across fashion, art, architecture, urban planning, landscape design and the future tools available to such disciplines. However, a detailed analysis capturing the capabilities of such models, specifically with a focus on the built environment, has not been performed to date. In this work, we investigate the capabilities and biases of such text-to-image methods as it applies to the built environment in detail. We use a systematic grammar to generate queries related to the built environment and evaluate resulting generated images. We generate 1020 different images and find that text to image transformers are robust at generating realistic images across different domains for this use-case. Generated imagery can be found at the github: https://github.com/sachith500/DALLEURBAN
Image-based Early Detection System for Wildfires
Nov 03, 2022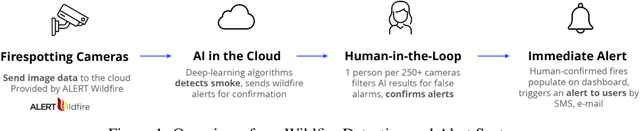
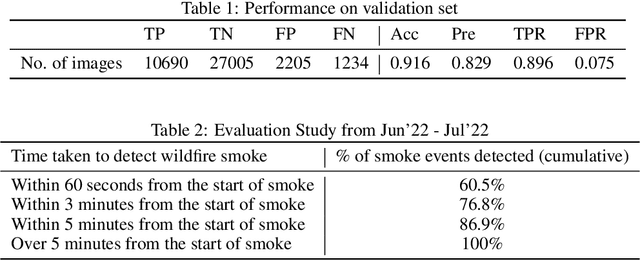

Wildfires are a disastrous phenomenon which cause damage to land, loss of property, air pollution, and even loss of human life. Due to the warmer and drier conditions created by climate change, more severe and uncontrollable wildfires are expected to occur in the coming years. This could lead to a global wildfire crisis and have dire consequences on our planet. Hence, it has become imperative to use technology to help prevent the spread of wildfires. One way to prevent the spread of wildfires before they become too large is to perform early detection i.e, detecting the smoke before the actual fire starts. In this paper, we present our Wildfire Detection and Alert System which use machine learning to detect wildfire smoke with a high degree of accuracy and can send immediate alerts to users. Our technology is currently being used in the USA to monitor data coming in from hundreds of cameras daily. We show that our system has a high true detection rate and a low false detection rate. Our performance evaluation study also shows that on an average our system detects wildfire smoke faster than an actual person.
POLCOVID: a multicenter multiclass chest X-ray database (Poland, 2020-2021)
Nov 29, 2022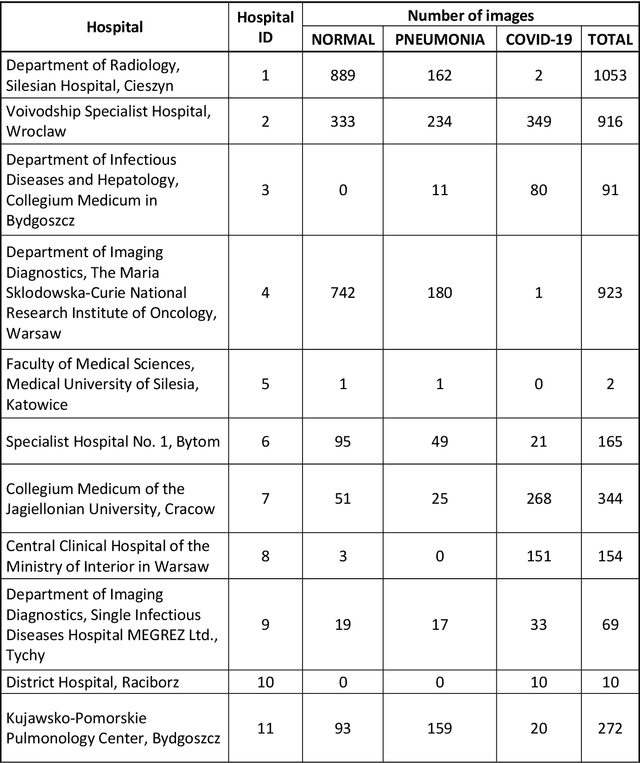
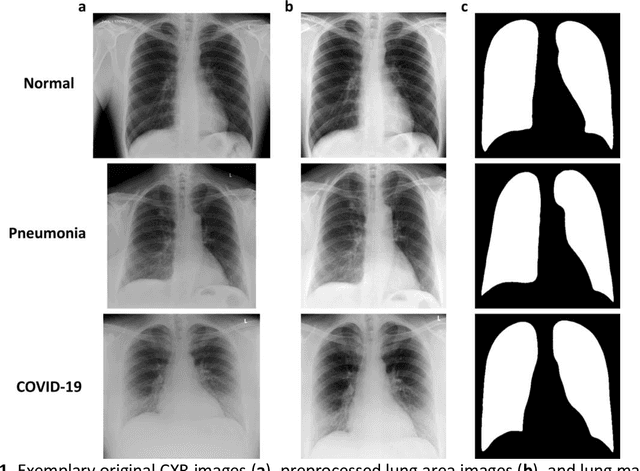
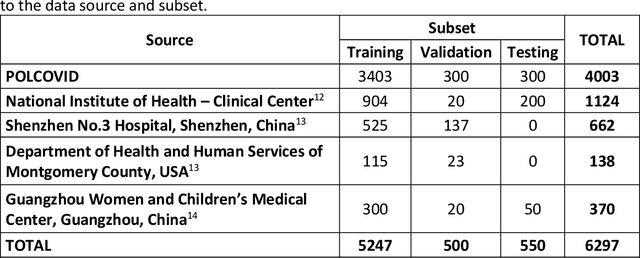
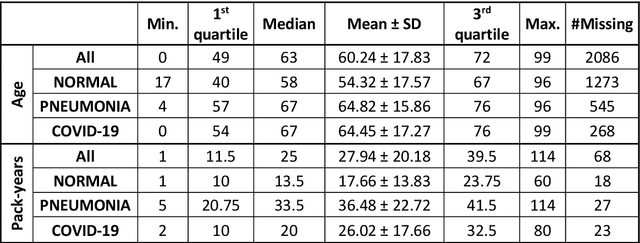
The outbreak of the SARS-CoV-2 pandemic has put healthcare systems worldwide to their limits, resulting in increased waiting time for diagnosis and required medical assistance. With chest radiographs (CXR) being one of the most common COVID-19 diagnosis methods, many artificial intelligence tools for image-based COVID-19 detection have been developed, often trained on a small number of images from COVID-19-positive patients. Thus, the need for high-quality and well-annotated CXR image databases increased. This paper introduces POLCOVID dataset, containing chest X-ray (CXR) images of patients with COVID-19 or other-type pneumonia, and healthy individuals gathered from 15 Polish hospitals. The original radiographs are accompanied by the preprocessed images limited to the lung area and the corresponding lung masks obtained with the segmentation model. Moreover, the manually created lung masks are provided for a part of POLCOVID dataset and the other four publicly available CXR image collections. POLCOVID dataset can help in pneumonia or COVID-19 diagnosis, while the set of matched images and lung masks may serve for the development of lung segmentation solutions.
YoloCurvSeg: You Only Label One Noisy Skeleton for Vessel-style Curvilinear Structure Segmentation
Dec 11, 2022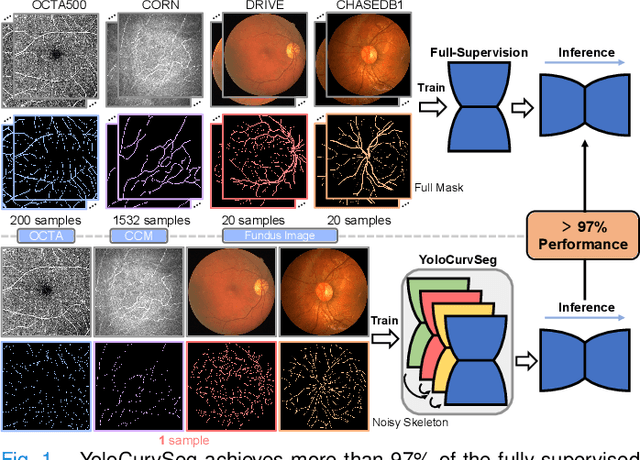
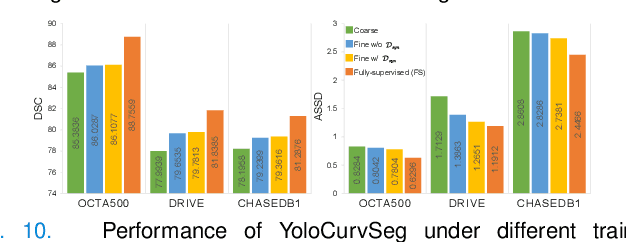
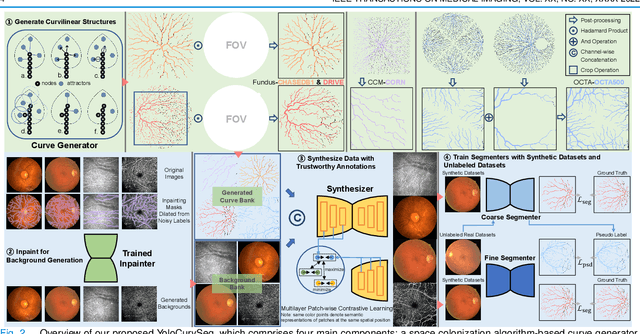
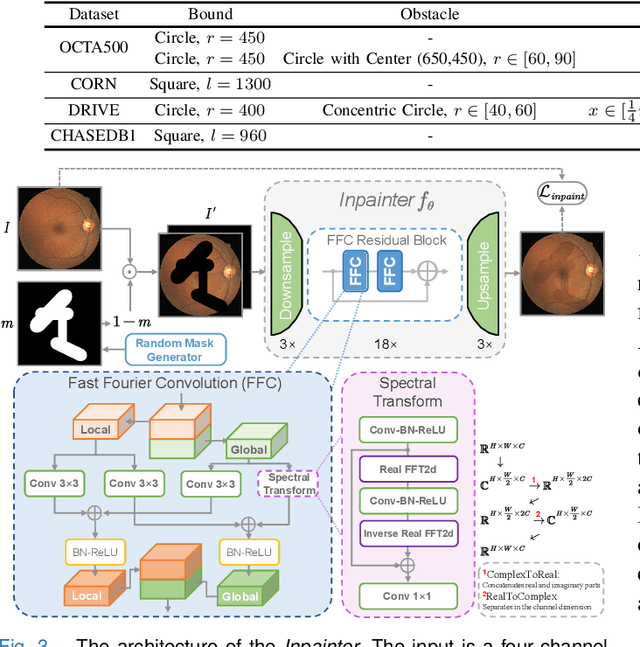
Weakly-supervised learning (WSL) has been proposed to alleviate the conflict between data annotation cost and model performance through employing sparsely-grained (i.e., point-, box-, scribble-wise) supervision and has shown promising performance, particularly in the image segmentation field. However, it is still a very challenging problem due to the limited supervision, especially when only a small number of labeled samples are available. Additionally, almost all existing WSL segmentation methods are designed for star-convex structures which are very different from curvilinear structures such as vessels and nerves. In this paper, we propose a novel sparsely annotated segmentation framework for curvilinear structures, named YoloCurvSeg, based on image synthesis. A background generator delivers image backgrounds that closely match real distributions through inpainting dilated skeletons. The extracted backgrounds are then combined with randomly emulated curves generated by a Space Colonization Algorithm-based foreground generator and through a multilayer patch-wise contrastive learning synthesizer. In this way, a synthetic dataset with both images and curve segmentation labels is obtained, at the cost of only one or a few noisy skeleton annotations. Finally, a segmenter is trained with the generated dataset and possibly an unlabeled dataset. The proposed YoloCurvSeg is evaluated on four publicly available datasets (OCTA500, CORN, DRIVE and CHASEDB1) and the results show that YoloCurvSeg outperforms state-of-the-art WSL segmentation methods by large margins. With only one noisy skeleton annotation (respectively 0.14%, 0.02%, 1.4%, and 0.65% of the full annotation), YoloCurvSeg achieves more than 97% of the fully-supervised performance on each dataset. Code and datasets will be released at https://github.com/llmir/YoloCurvSeg.
Digital Image Processing Applied To Object Segmentation By Intensity And Motion
Aug 26, 2022The current technological development allows us to carry out tasks that some time ago were unthinkable if not impossible, digital image processing has been one of the major constants of development today, taking into account that its implementation dates from a short time ago, OpenCV [1] is a tool focused on machine vision, In this case implemented in an object-oriented programming platform based on Java language offered by the NetBeans development software, based on the above, a physical platform was proposed and implemented as a closed environment which through the development of an algorithm allowed detection and segmentation of objects by means of the RGB color model; In future works this algorithm will provide the information base for the autonomous robotic platform; this advance opens a wide spectrum for the development of applications and tools in the field of artificial vision.
REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory
Dec 10, 2022
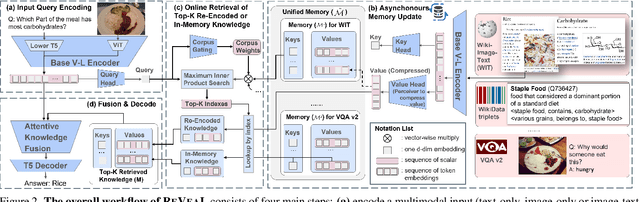
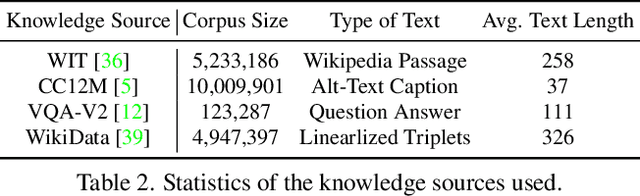
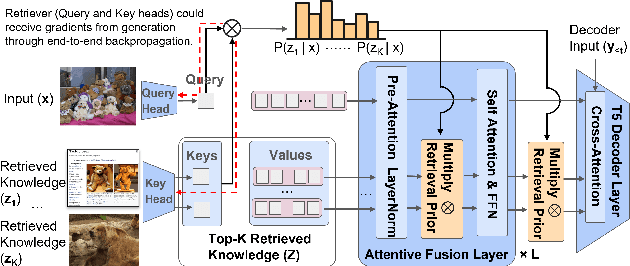
In this paper, we propose an end-to-end Retrieval-Augmented Visual Language Model (REVEAL) that learns to encode world knowledge into a large-scale memory, and to retrieve from it to answer knowledge-intensive queries. REVEAL consists of four key components: the memory, the encoder, the retriever and the generator. The large-scale memory encodes various sources of multimodal world knowledge (e.g. image-text pairs, question answering pairs, knowledge graph triplets, etc) via a unified encoder. The retriever finds the most relevant knowledge entries in the memory, and the generator fuses the retrieved knowledge with the input query to produce the output. A key novelty in our approach is that the memory, encoder, retriever and generator are all pre-trained end-to-end on a massive amount of data. Furthermore, our approach can use a diverse set of multimodal knowledge sources, which is shown to result in significant gains. We show that REVEAL achieves state-of-the-art results on visual question answering and image captioning.
Self-Supervised Clustering on Image-Subtracted Data with Deep-Embedded Self-Organizing Map
Sep 14, 2022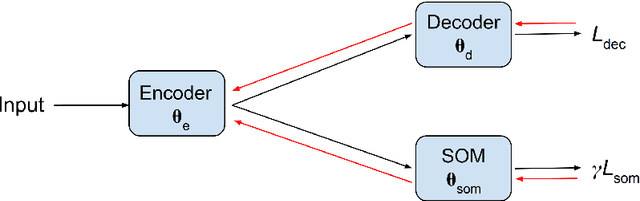

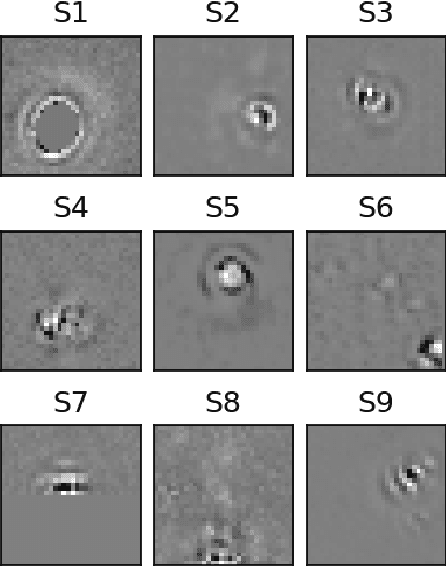

Developing an effective automatic classifier to separate genuine sources from artifacts is essential for transient follow-ups in wide-field optical surveys. The identification of transient detections from the subtraction artifacts after the image differencing process is a key step in such classifiers, known as real-bogus classification problem. We apply a self-supervised machine learning model, the deep-embedded self-organizing map (DESOM) to this "real-bogus" classification problem. DESOM combines an autoencoder and a self-organizing map to perform clustering in order to distinguish between real and bogus detections, based on their dimensionality-reduced representations. We use 32x32 normalized detection thumbnails as the input of DESOM. We demonstrate different model training approaches, and find that our best DESOM classifier shows a missed detection rate of 6.6% with a false positive rate of 1.5%. DESOM offers a more nuanced way to fine-tune the decision boundary identifying likely real detections when used in combination with other types of classifiers, for example built on neural networks or decision trees. We also discuss other potential usages of DESOM and its limitations.
Intensity-Sensitive Similarity Indexes for Image Quality Assessment
Jun 22, 2022
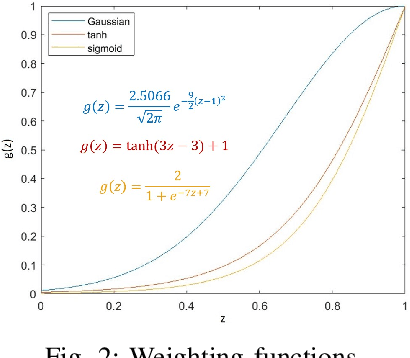
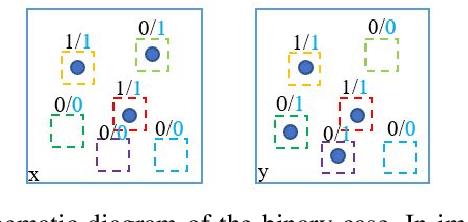
The importance of Image quality assessment (IQA) is ever increasing due to the fast paced advances in imaging technology and computer vision. Among the numerous IQA methods, Structural SIMilarity (SSIM) index and its variants are better matched to the perceived quality of the human visual system. However, SSIM methods are insufficiently sensitive, when images contain low information, where the important information only occupies a low proportion of the image while most of the image is noise-like, which is common in scientific data. Therefore, we propose two new IQA methods, InTensity Weighted SSIM index and Low-Information Similarity Index, for such low information images. In addition, auxiliary indexes are proposed to assist with the assessment. The application of these new IQA methods to natural images and field-specific images, such as radio astronomical images, medical images, and remote sensing images, are also demonstrated. The results show that our IQA methods perform better than state-of-the-art SSIM methods for differences in high-intensity parts of the input images and have similar performance to that of the original and gradient-based SSIM for differences in low-intensity parts. Different similarity indexes are suitable for different applications, which we demonstrate in our results.
ZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation
Dec 07, 2022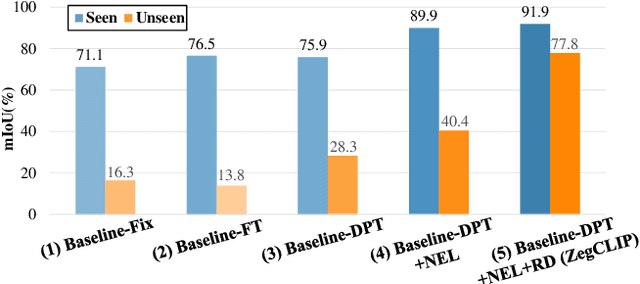
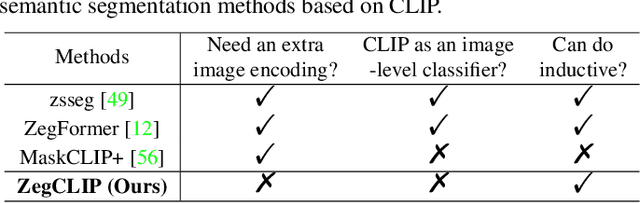
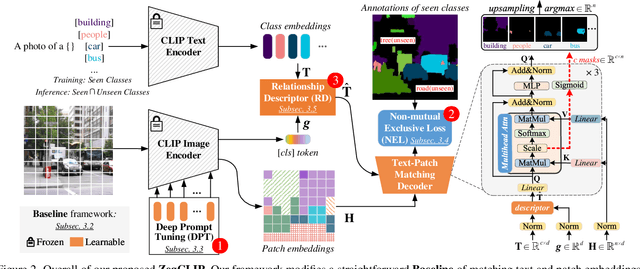
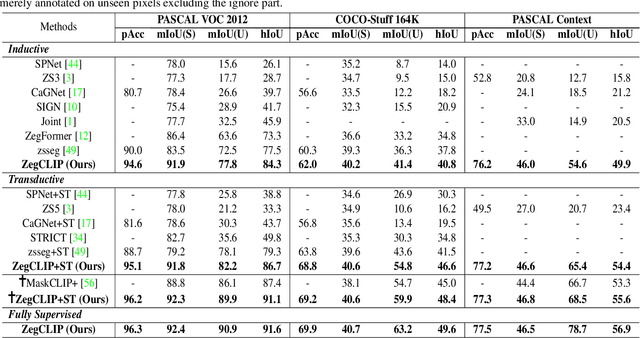
Recently, CLIP has been applied to pixel-level zero-shot learning tasks via a two-stage scheme. The general idea is to first generate class-agnostic region proposals and then feed the cropped proposal regions to CLIP to utilize its image-level zero-shot classification capability. While effective, such a scheme requires two image encoders, one for proposal generation and one for CLIP, leading to a complicated pipeline and high computational cost. In this work, we pursue a simpler-and-efficient one-stage solution that directly extends CLIP's zero-shot prediction capability from image to pixel level. Our investigation starts with a straightforward extension as our baseline that generates semantic masks by comparing the similarity between text and patch embeddings extracted from CLIP. However, such a paradigm could heavily overfit the seen classes and fail to generalize to unseen classes. To handle this issue, we propose three simple-but-effective designs and figure out that they can significantly retain the inherent zero-shot capacity of CLIP and improve pixel-level generalization ability. Incorporating those modifications leads to an efficient zero-shot semantic segmentation system called ZegCLIP. Through extensive experiments on three public benchmarks, ZegCLIP demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both "inductive" and "transductive" zero-shot settings. In addition, compared with the two-stage method, our one-stage ZegCLIP achieves a speedup of about 5 times faster during inference. We release the code at https://github.com/ZiqinZhou66/ZegCLIP.git.