 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
POLCOVID: a multicenter multiclass chest X-ray database
Dec 15, 2022The outbreak of the SARS-CoV-2 pandemic has put healthcare systems worldwide to their limits, resulting in increased waiting time for diagnosis and required medical assistance. With chest radiographs (CXR) being one of the most common COVID-19 diagnosis methods, many artificial intelligence tools for image-based COVID-19 detection have been developed, often trained on a small number of images from COVID-19-positive patients. Thus, the need for high-quality and well-annotated CXR image databases increased. This paper introduces POLCOVID dataset, containing chest X-ray (CXR) images of patients with COVID-19 or other-type pneumonia, and healthy individuals gathered from 15 Polish hospitals. The original radiographs are accompanied by the preprocessed images limited to the lung area and the corresponding lung masks obtained with the segmentation model. Moreover, the manually created lung masks are provided for a part of POLCOVID dataset and the other four publicly available CXR image collections. POLCOVID dataset can help in pneumonia or COVID-19 diagnosis, while the set of matched images and lung masks may serve for the development of lung segmentation solutions.
CIRCA: comprehensible online system in support of chest X-rays-based COVID-19 diagnosis
Oct 11, 2022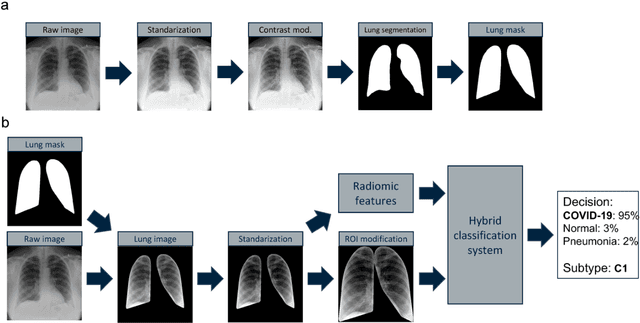
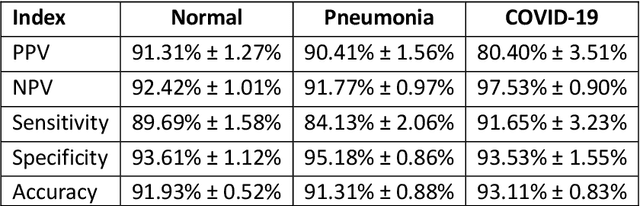
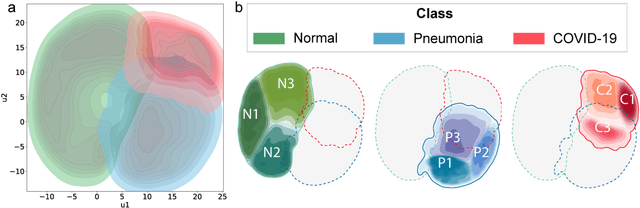
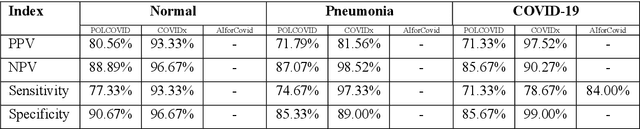
Due to the large accumulation of patients requiring hospitalization, the COVID-19 pandemic disease caused a high overload of health systems, even in developed countries. Deep learning techniques based on medical imaging data can help in the faster detection of COVID-19 cases and monitoring of disease progression. Regardless of the numerous proposed solutions for lung X-rays, none of them is a product that can be used in the clinic. Five different datasets (POLCOVID, AIforCOVID, COVIDx, NIH, and artificially generated data) were used to construct a representative dataset of 23 799 CXRs for model training; 1 050 images were used as a hold-out test set, and 44 247 as independent test set (BIMCV database). A U-Net-based model was developed to identify a clinically relevant region of the CXR. Each image class (normal, pneumonia, and COVID-19) was divided into 3 subtypes using a 2D Gaussian mixture model. A decision tree was used to aggregate predictions from the InceptionV3 network based on processed CXRs and a dense neural network on radiomic features. The lung segmentation model gave the Sorensen-Dice coefficient of 94.86% in the validation dataset, and 93.36% in the testing dataset. In 5-fold cross-validation, the accuracy for all classes ranged from 91% to 93%, keeping slightly higher specificity than sensitivity and NPV than PPV. In the hold-out test set, the balanced accuracy ranged between 68% and 100%. The highest performance was obtained for the subtypes N1, P1, and C1. A similar performance was obtained on the independent dataset for normal and COVID-19 class subtypes. Seventy-six percent of COVID-19 patients wrongly classified as normal cases were annotated by radiologists as with no signs of disease. Finally, we developed the online service (https://circa.aei.polsl.pl) to provide access to fast diagnosis support tools.