 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Driver Drowsiness Detection System: An Approach By Machine Learning Application
Mar 11, 2023
The majority of human deaths and injuries are caused by traffic accidents. A million people worldwide die each year due to traffic accident injuries, consistent with the World Health Organization. Drivers who do not receive enough sleep, rest, or who feel weary may fall asleep behind the wheel, endangering both themselves and other road users. The research on road accidents specified that major road accidents occur due to drowsiness while driving. These days, it is observed that tired driving is the main reason to occur drowsiness. Now, drowsiness becomes the main principle for to increase in the number of road accidents. This becomes a major issue in a world which is very important to resolve as soon as possible. The predominant goal of all devices is to improve the performance to detect drowsiness in real time. Many devices were developed to detect drowsiness, which depend on different artificial intelligence algorithms. So, our research is also related to driver drowsiness detection which can identify the drowsiness of a driver by identifying the face and then followed by eye tracking. The extracted eye image is matched with the dataset by the system. With the help of the dataset, the system detected that if eyes were close for a certain range, it could ring an alarm to alert the driver and if the eyes were open after the alert, then it could continue tracking. If the eyes were open then the score that we set decreased and if the eyes were closed then the score increased. This paper focus to resolve the problem of drowsiness detection with an accuracy of 80% and helps to reduce road accidents.
Controlling for Stereotypes in Multimodal Language Model Evaluation
Feb 03, 2023


We propose a methodology and design two benchmark sets for measuring to what extent language-and-vision language models use the visual signal in the presence or absence of stereotypes. The first benchmark is designed to test for stereotypical colors of common objects, while the second benchmark considers gender stereotypes. The key idea is to compare predictions when the image conforms to the stereotype to predictions when it does not. Our results show that there is significant variation among multimodal models: the recent Transformer-based FLAVA seems to be more sensitive to the choice of image and less affected by stereotypes than older CNN-based models such as VisualBERT and LXMERT. This effect is more discernible in this type of controlled setting than in traditional evaluations where we do not know whether the model relied on the stereotype or the visual signal.
GH-Feat: Learning Versatile Generative Hierarchical Features from GANs
Jan 12, 2023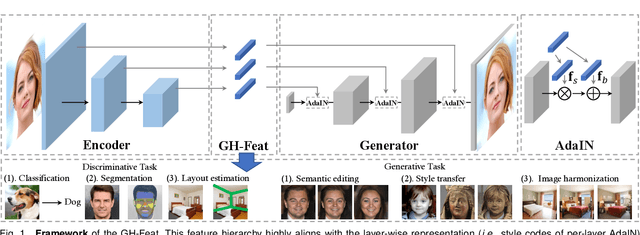
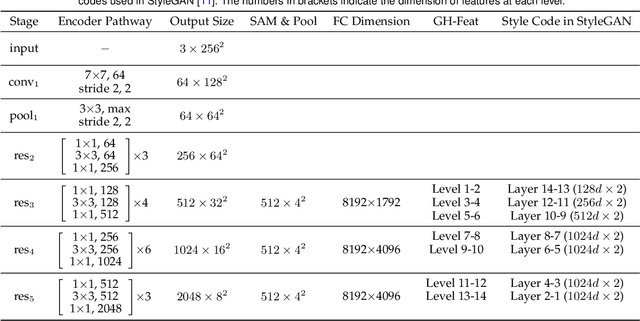
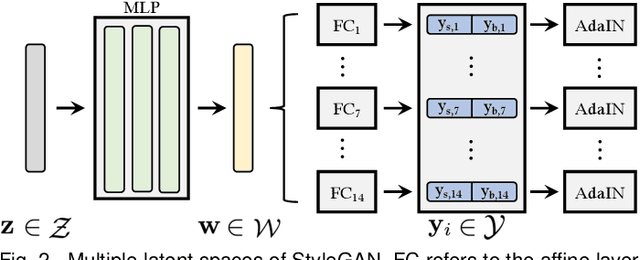

Recent years witness the tremendous success of generative adversarial networks (GANs) in synthesizing photo-realistic images. GAN generator learns to compose realistic images and reproduce the real data distribution. Through that, a hierarchical visual feature with multi-level semantics spontaneously emerges. In this work we investigate that such a generative feature learned from image synthesis exhibits great potentials in solving a wide range of computer vision tasks, including both generative ones and more importantly discriminative ones. We first train an encoder by considering the pretrained StyleGAN generator as a learned loss function. The visual features produced by our encoder, termed as Generative Hierarchical Features (GH-Feat), highly align with the layer-wise GAN representations, and hence describe the input image adequately from the reconstruction perspective. Extensive experiments support the versatile transferability of GH-Feat across a range of applications, such as image editing, image processing, image harmonization, face verification, landmark detection, layout prediction, image retrieval, etc. We further show that, through a proper spatial expansion, our developed GH-Feat can also facilitate fine-grained semantic segmentation using only a few annotations. Both qualitative and quantitative results demonstrate the appealing performance of GH-Feat.
Adaptively Clustering Neighbor Elements for Image Captioning
Jan 05, 2023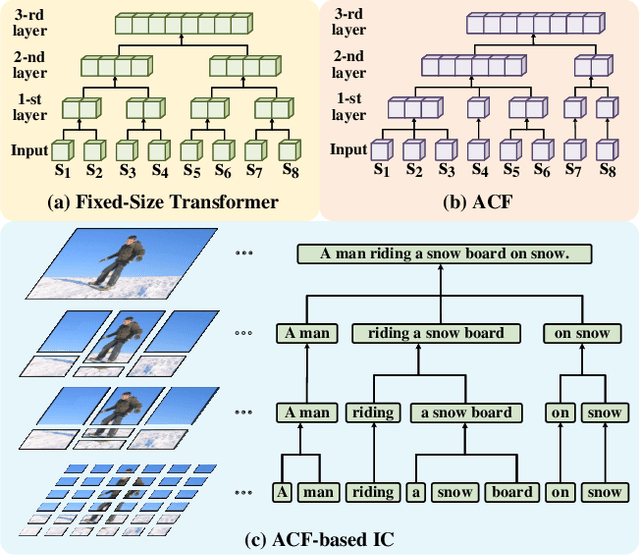
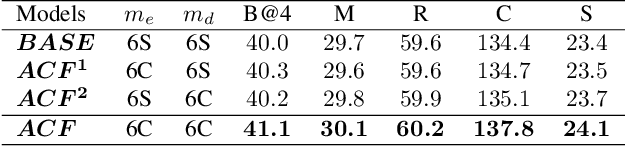
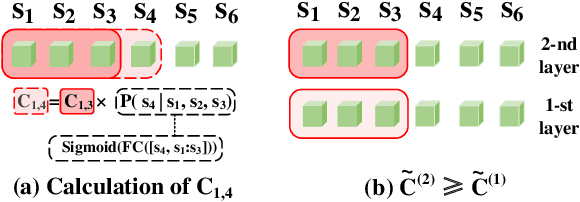
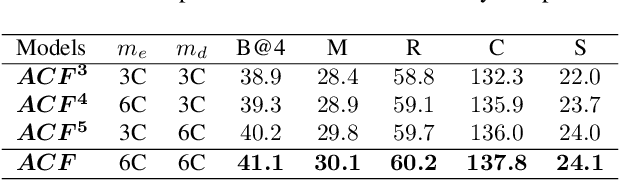
We design a novel global-local Transformer named \textbf{Ada-ClustFormer} (\textbf{ACF}) to generate captions. We use this name since each layer of ACF can adaptively cluster input elements to carry self-attention (Self-ATT) for learning local context. Compared with other global-local Transformers which carry Self-ATT in fixed-size windows, ACF can capture varying graininess, \eg, an object may cover different numbers of grids or a phrase may contain diverse numbers of words. To build ACF, we insert a probabilistic matrix C into the Self-ATT layer. For an input sequence {{s}_1,...,{s}_N , C_{i,j} softly determines whether the sub-sequence {s_i,...,s_j} should be clustered for carrying Self-ATT. For implementation, {C}_{i,j} is calculated from the contexts of {{s}_i,...,{s}_j}, thus ACF can exploit the input itself to decide which local contexts should be learned. By using ACF to build the vision encoder and language decoder, the captioning model can automatically discover the hidden structures in both vision and language, which encourages the model to learn a unified structural space for transferring more structural commonalities. The experiment results demonstrate the effectiveness of ACF that we achieve CIDEr of 137.8, which outperforms most SOTA captioning models and achieve comparable scores compared with some BERT-based models. The code will be available in the supplementary material.
BOSS: Bones, Organs and Skin Shape Model
Mar 08, 2023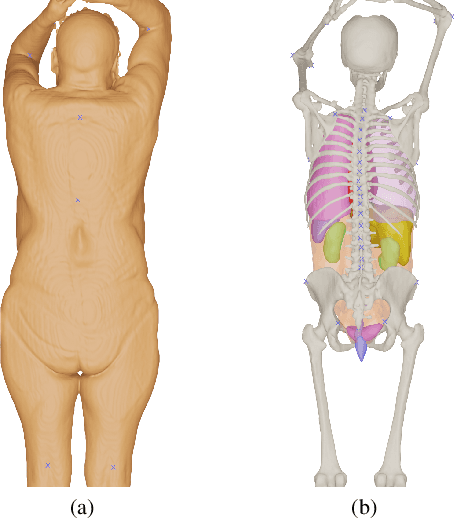
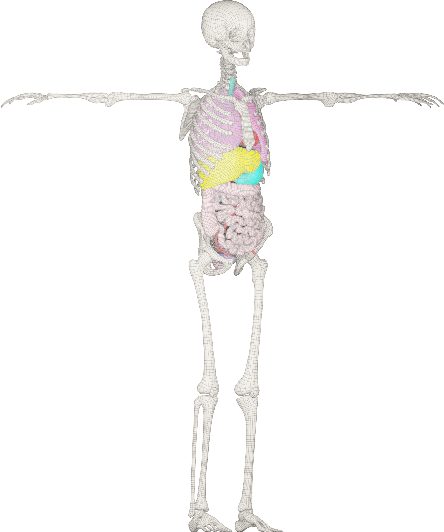
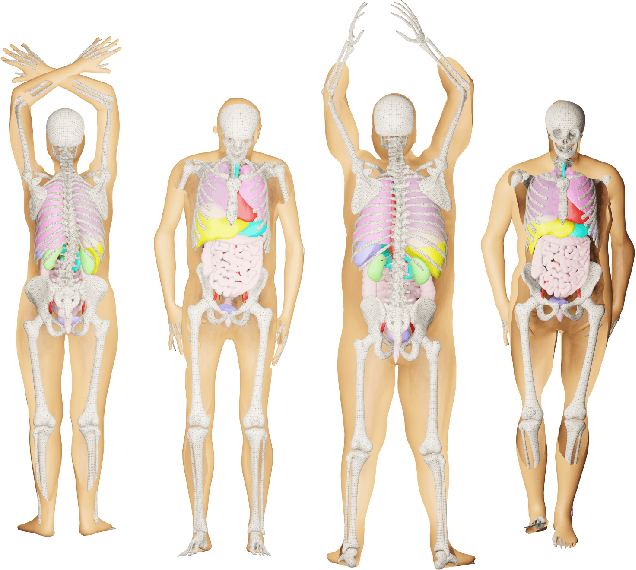
Objective: A digital twin of a patient can be a valuable tool for enhancing clinical tasks such as workflow automation, patient-specific X-ray dose optimization, markerless tracking, positioning, and navigation assistance in image-guided interventions. However, it is crucial that the patient's surface and internal organs are of high quality for any pose and shape estimates. At present, the majority of statistical shape models (SSMs) are restricted to a small number of organs or bones or do not adequately represent the general population. Method: To address this, we propose a deformable human shape and pose model that combines skin, internal organs, and bones, learned from CT images. By modeling the statistical variations in a pose-normalized space using probabilistic PCA while also preserving joint kinematics, our approach offers a holistic representation of the body that can benefit various medical applications. Results: We assessed our model's performance on a registered dataset, utilizing the unified shape space, and noted an average error of 3.6 mm for bones and 8.8 mm for organs. To further verify our findings, we conducted additional tests on publicly available datasets with multi-part segmentations, which confirmed the effectiveness of our model. Conclusion: This works shows that anatomically parameterized statistical shape models can be created accurately and in a computationally efficient manner. Significance: The proposed approach enables the construction of shape models that can be directly applied to various medical applications, including biomechanics and reconstruction.
O2RNet: Occluder-Occludee Relational Network for Robust Apple Detection in Clustered Orchard Environments
Mar 08, 2023


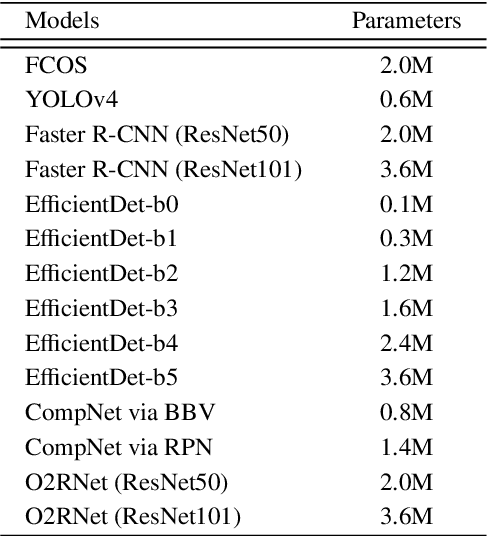
Automated apple harvesting has attracted significant research interest in recent years due to its potential to revolutionize the apple industry, addressing the issues of shortage and high costs in labor. One key technology to fully enable efficient automated harvesting is accurate and robust apple detection, which is challenging due to complex orchard environments that involve varying lighting conditions and foliage/branch occlusions. Furthermore, clustered apples are common in the orchard, which brings additional challenges as the clustered apples may be identified as one apple. This will cause issues in localization for subsequent robotic operations. In this paper, we present the development of a novel deep learning-based apple detection framework, Occluder-Occludee Relational Network (O2RNet), for robust detection of apples in such clustered environments. This network exploits the occuluder-occludee relationship modeling head by introducing a feature expansion structure to enable the combination of layered traditional detectors to split clustered apples and foliage occlusions. More specifically, we collect a comprehensive apple orchard image dataset under different lighting conditions (overcast, front lighting, and back lighting) with frequent apple occlusions. We then develop a novel occlusion-aware network for apple detection, in which a feature expansion structure is incorporated into the convolutional neural networks to extract additional features generated by the original network for occluded apples. Comprehensive evaluations are performed, which show that the developed O2RNet outperforms state-of-the-art models with a higher accuracy of 94\% and a higher F1-score of 0.88 on apple detection.
Progressive Knowledge Distillation: Building Ensembles for Efficient Inference
Feb 20, 2023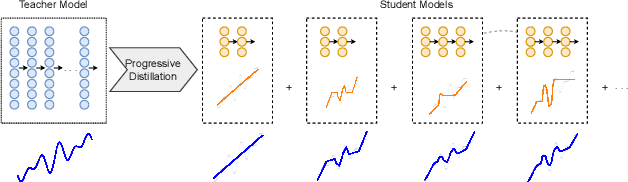
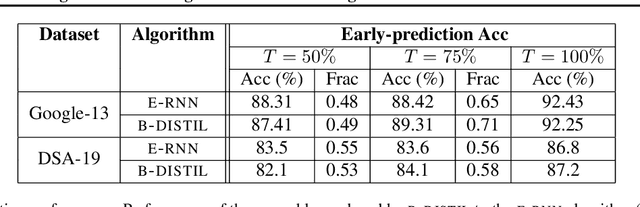
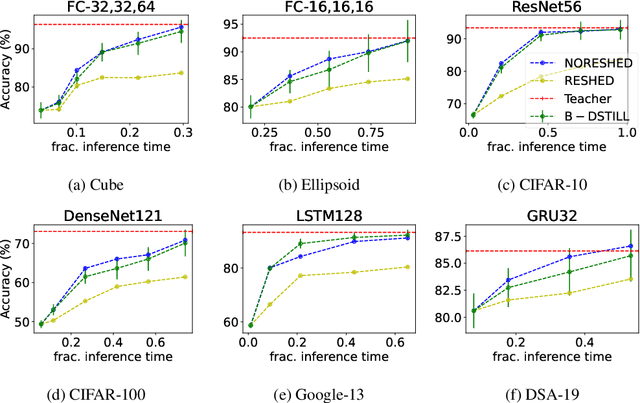
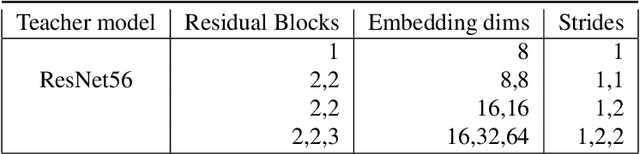
We study the problem of progressive distillation: Given a large, pre-trained teacher model $g$, we seek to decompose the model into an ensemble of smaller, low-inference cost student models $f_i$. The resulting ensemble allows for flexibly tuning accuracy vs. inference cost, which is useful for a number of applications in on-device inference. The method we propose, B-DISTIL, relies on an algorithmic procedure that uses function composition over intermediate activations to construct expressive ensembles with similar performance as $g$, but with much smaller student models. We demonstrate the effectiveness of \algA by decomposing pretrained models across standard image, speech, and sensor datasets. We also provide theoretical guarantees for our method in terms of convergence and generalization.
Cross-domain Unsupervised Reconstruction with Equivariance for Photoacoustic Computed Tomography
Jan 17, 2023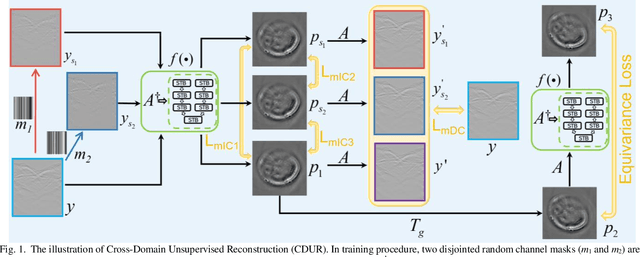

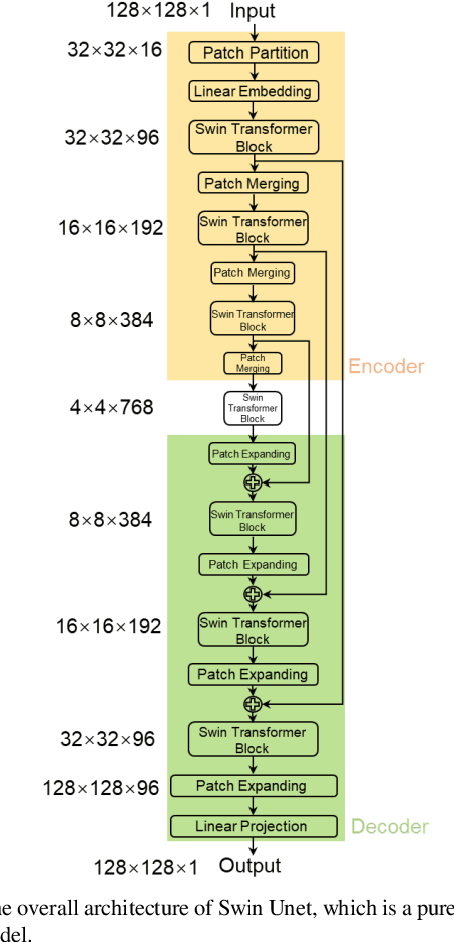
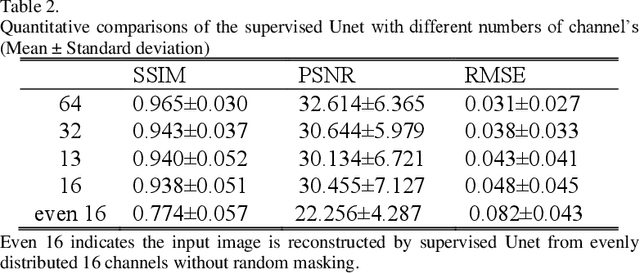
Accurate image reconstruction is crucial for photoacoustic (PA) computed tomography (PACT). Recently, deep learning has been used to reconstruct the PA image with a supervised scheme, which requires high-quality images as ground truth labels. In practice, there are inevitable trade-offs between cost and performance since the use of more channels is an expensive strategy to access more measurements. Here, we propose a cross-domain unsupervised reconstruction (CDUR) strategy with a pure transformer model, which overcomes the lack of ground truth labels from limited PA measurements. The proposed approach exploits the equivariance of PACT to achieve high performance with a smaller number of channels. We implement a self-supervised reconstruction in a model-based form. Meanwhile, we also leverage the self-supervision to enforce the measurement and image consistency on three partitions of measured PA data, by randomly masking different channels. We find that dynamically masking a high proportion of the channels, e.g., 80%, yields nontrivial self-supervisors in both image and signal domains, which decrease the multiplicity of the pseudo solution to efficiently reconstruct the image from fewer PA measurements with minimum error of the image. Experimental results on in-vivo PACT dataset of mice demonstrate the potential of our unsupervised framework. In addition, our method shows a high performance (0.83 structural similarity index (SSIM) in the extreme sparse case with 13 channels), which is close to that of supervised scheme (0.77 SSIM with 16 channels). On top of all the advantages, our method may be deployed on different trainable models in an end-to-end manner.
TransAdapt: A Transformative Framework for Online Test Time Adaptive Semantic Segmentation
Feb 24, 2023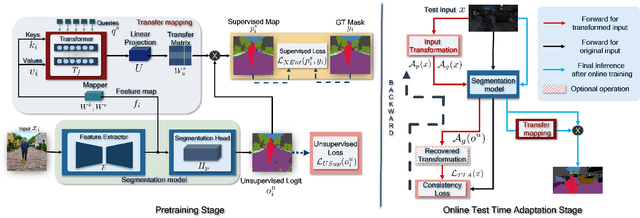
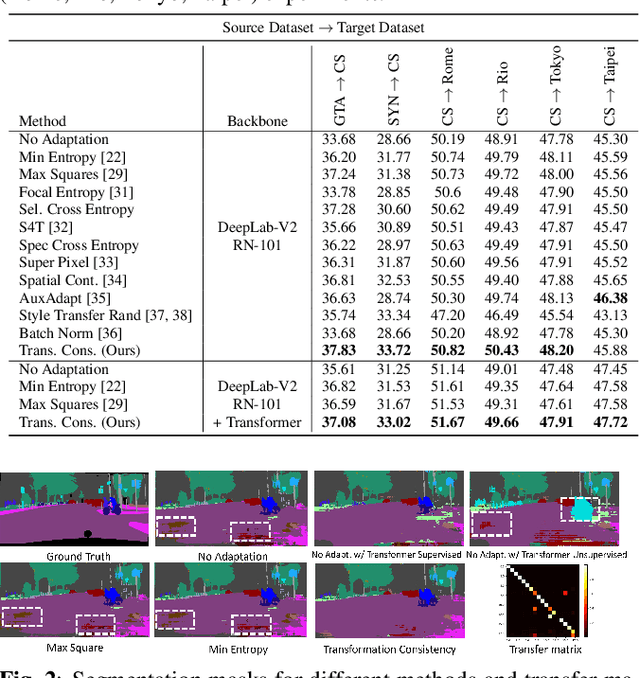

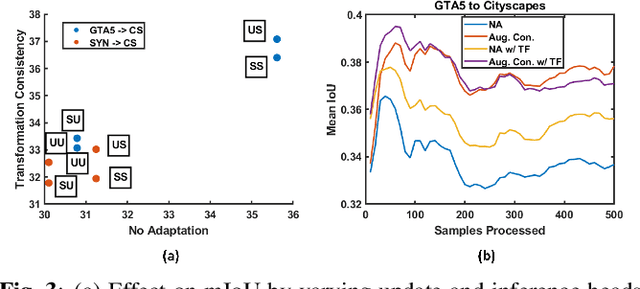
Test-time adaptive (TTA) semantic segmentation adapts a source pre-trained image semantic segmentation model to unlabeled batches of target domain test images, different from real-world, where samples arrive one-by-one in an online fashion. To tackle online settings, we propose TransAdapt, a framework that uses transformer and input transformations to improve segmentation performance. Specifically, we pre-train a transformer-based module on a segmentation network that transforms unsupervised segmentation output to a more reliable supervised output, without requiring test-time online training. To also facilitate test-time adaptation, we propose an unsupervised loss based on the transformed input that enforces the model to be invariant and equivariant to photometric and geometric perturbations, respectively. Overall, our framework produces higher quality segmentation masks with up to 17.6% and 2.8% mIOU improvement over no-adaptation and competitive baselines, respectively.
Image Quality Assessment with Gradient Siamese Network
Aug 08, 2022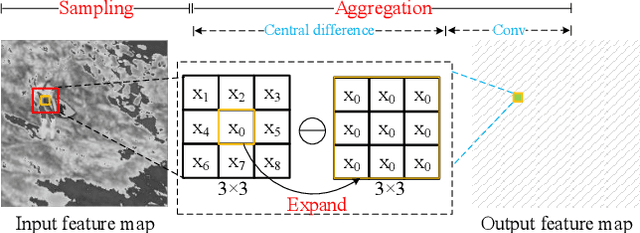
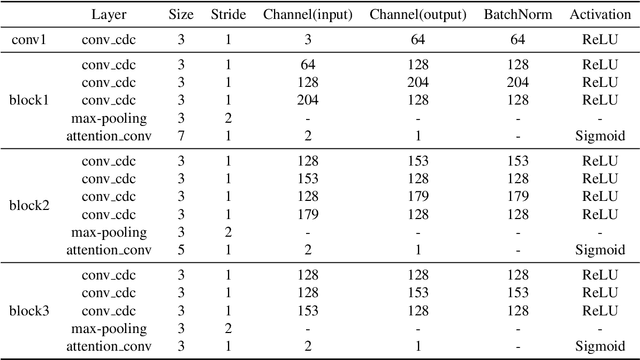
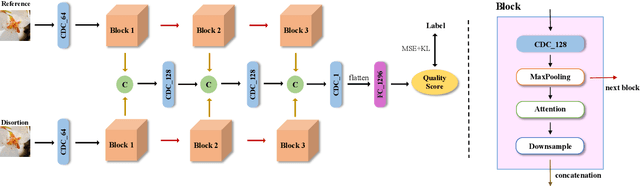
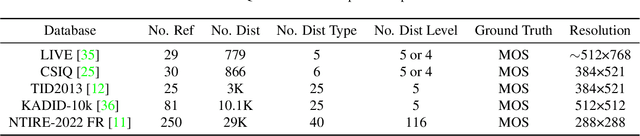
In this work, we introduce Gradient Siamese Network (GSN) for image quality assessment. The proposed method is skilled in capturing the gradient features between distorted images and reference images in full-reference image quality assessment(IQA) task. We utilize Central Differential Convolution to obtain both semantic features and detail difference hidden in image pair. Furthermore, spatial attention guides the network to concentrate on regions related to image detail. For the low-level, mid-level and high-level features extracted by the network, we innovatively design a multi-level fusion method to improve the efficiency of feature utilization. In addition to the common mean square error supervision, we further consider the relative distance among batch samples and successfully apply KL divergence loss to the image quality assessment task. We experimented the proposed algorithm GSN on several publicly available datasets and proved its superior performance. Our network won the second place in NTIRE 2022 Perceptual Image Quality Assessment Challenge track 1 Full-Reference.
* 10 pages, 5 figures, Computer Vision and Pattern Recognition (CVPR) Workshops