 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meme Sentiment Analysis Enhanced with Multimodal Spatial Encoding and Facial Embedding
Mar 03, 2023
Internet memes are characterised by the interspersing of text amongst visual elements. State-of-the-art multimodal meme classifiers do not account for the relative positions of these elements across the two modalities, despite the latent meaning associated with where text and visual elements are placed. Against two meme sentiment classification datasets, we systematically show performance gains from incorporating the spatial position of visual objects, faces, and text clusters extracted from memes. In addition, we also present facial embedding as an impactful enhancement to image representation in a multimodal meme classifier. Finally, we show that incorporating this spatial information allows our fully automated approaches to outperform their corresponding baselines that rely on additional human validation of OCR-extracted text.
* Published as chapter in ISBN:978-3-031-26438-2
Mask-Guided Image Person Removal with Data Synthesis
Sep 29, 2022
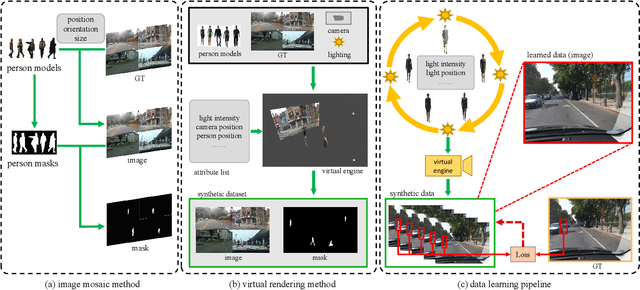
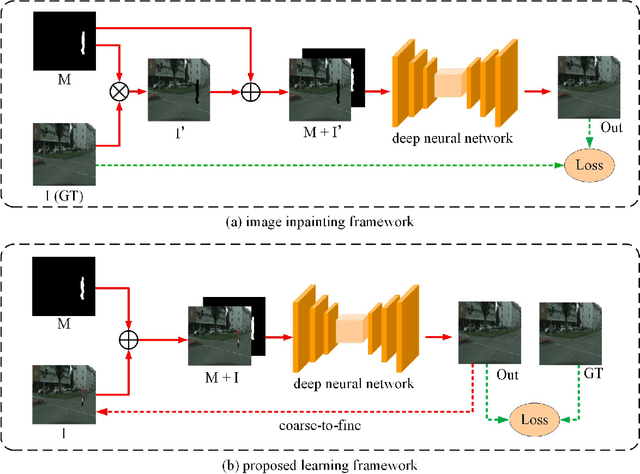

As a special case of common object removal, image person removal is playing an increasingly important role in social media and criminal investigation domains. Due to the integrity of person area and the complexity of human posture, person removal has its own dilemmas. In this paper, we propose a novel idea to tackle these problems from the perspective of data synthesis. Concerning the lack of dedicated dataset for image person removal, two dataset production methods are proposed to automatically generate images, masks and ground truths respectively. Then, a learning framework similar to local image degradation is proposed so that the masks can be used to guide the feature extraction process and more texture information can be gathered for final prediction. A coarse-to-fine training strategy is further applied to refine the details. The data synthesis and learning framework combine well with each other. Experimental results verify the effectiveness of our method quantitatively and qualitatively, and the trained network proves to have good generalization ability either on real or synthetic images.
Learning advisor networks for noisy image classification
Nov 08, 2022In this paper, we introduced the novel concept of advisor network to address the problem of noisy labels in image classification. Deep neural networks (DNN) are prone to performance reduction and overfitting problems on training data with noisy annotations. Weighting loss methods aim to mitigate the influence of noisy labels during the training, completely removing their contribution. This discarding process prevents DNNs from learning wrong associations between images and their correct labels but reduces the amount of data used, especially when most of the samples have noisy labels. Differently, our method weighs the feature extracted directly from the classifier without altering the loss value of each data. The advisor helps to focus only on some part of the information present in mislabeled examples, allowing the classifier to leverage that data as well. We trained it with a meta-learning strategy so that it can adapt throughout the training of the main model. We tested our method on CIFAR10 and CIFAR100 with synthetic noise, and on Clothing1M which contains real-world noise, reporting state-of-the-art results.
* Paper published as Poster at ICIAP21
Euler Characteristic Transform Based Topological Loss for Reconstructing 3D Images from Single 2D Slices
Mar 08, 2023

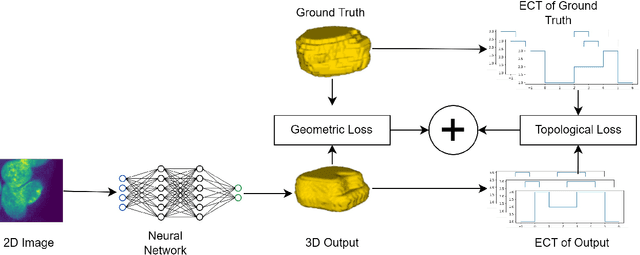
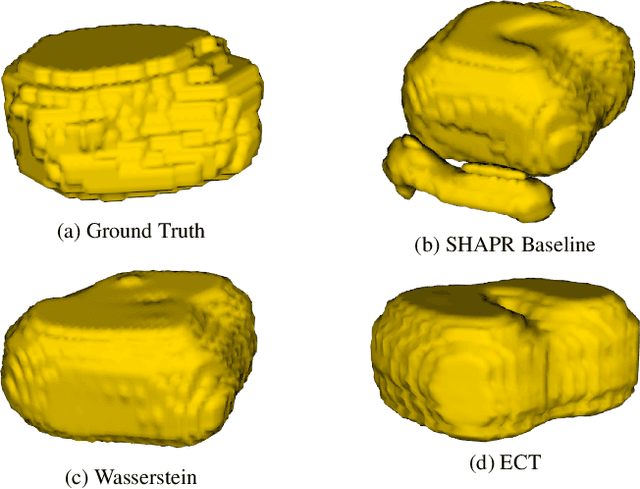
The computer vision task of reconstructing 3D images, i.e., shapes, from their single 2D image slices is extremely challenging, more so in the regime of limited data. Deep learning models typically optimize geometric loss functions, which may lead to poor reconstructions as they ignore the structural properties of the shape. To tackle this, we propose a novel topological loss function based on the Euler Characteristic Transform. This loss can be used as an inductive bias to aid the optimization of any neural network toward better reconstructions in the regime of limited data. We show the effectiveness of the proposed loss function by incorporating it into SHAPR, a state-of-the-art shape reconstruction model, and test it on two benchmark datasets, viz., Red Blood Cells and Nuclei datasets. We also show a favourable property, namely injectivity and discuss the stability of the topological loss function based on the Euler Characteristic Transform.
HyT-NAS: Hybrid Transformers Neural Architecture Search for Edge Devices
Mar 08, 2023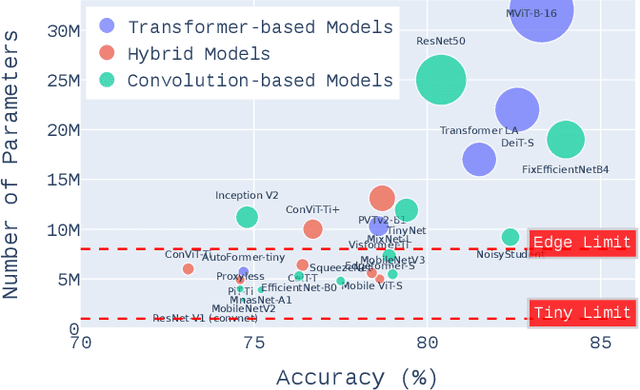

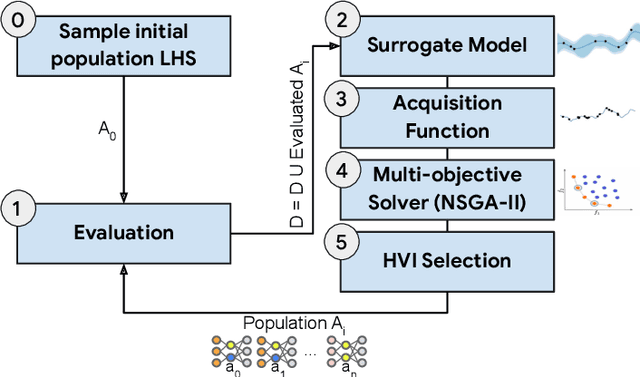
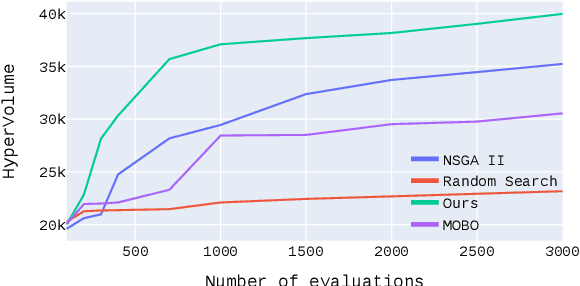
Vision Transformers have enabled recent attention-based Deep Learning (DL) architectures to achieve remarkable results in Computer Vision (CV) tasks. However, due to the extensive computational resources required, these architectures are rarely implemented on resource-constrained platforms. Current research investigates hybrid handcrafted convolution-based and attention-based models for CV tasks such as image classification and object detection. In this paper, we propose HyT-NAS, an efficient Hardware-aware Neural Architecture Search (HW-NAS) including hybrid architectures targeting vision tasks on tiny devices. HyT-NAS improves state-of-the-art HW-NAS by enriching the search space and enhancing the search strategy as well as the performance predictors. Our experiments show that HyT-NAS achieves a similar hypervolume with less than ~5x training evaluations. Our resulting architecture outperforms MLPerf MobileNetV1 by 6.3% accuracy improvement with 3.5x less number of parameters on Visual Wake Words.
CapDet: Unifying Dense Captioning and Open-World Detection Pretraining
Mar 15, 2023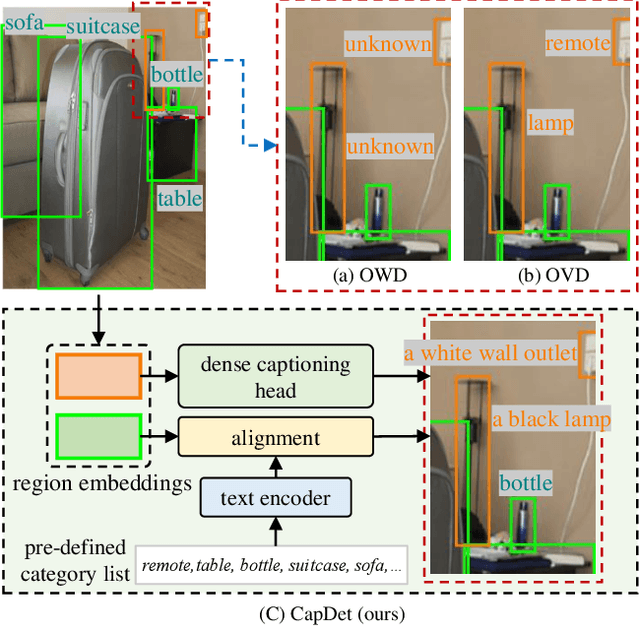
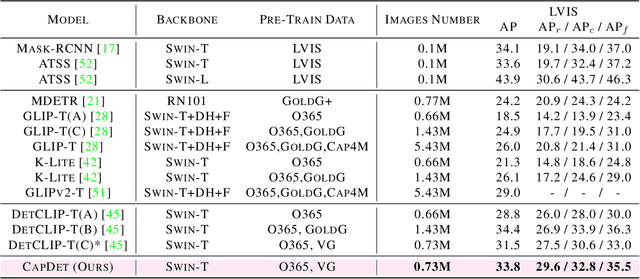
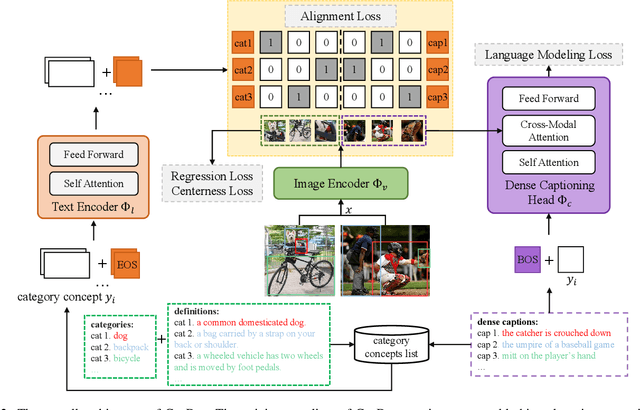
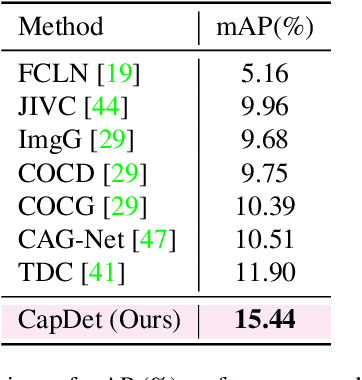
Benefiting from large-scale vision-language pre-training on image-text pairs, open-world detection methods have shown superior generalization ability under the zero-shot or few-shot detection settings. However, a pre-defined category space is still required during the inference stage of existing methods and only the objects belonging to that space will be predicted. To introduce a "real" open-world detector, in this paper, we propose a novel method named CapDet to either predict under a given category list or directly generate the category of predicted bounding boxes. Specifically, we unify the open-world detection and dense caption tasks into a single yet effective framework by introducing an additional dense captioning head to generate the region-grounded captions. Besides, adding the captioning task will in turn benefit the generalization of detection performance since the captioning dataset covers more concepts. Experiment results show that by unifying the dense caption task, our CapDet has obtained significant performance improvements (e.g., +2.1% mAP on LVIS rare classes) over the baseline method on LVIS (1203 classes). Besides, our CapDet also achieves state-of-the-art performance on dense captioning tasks, e.g., 15.44% mAP on VG V1.2 and 13.98% on the VG-COCO dataset.
Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations
Mar 15, 2023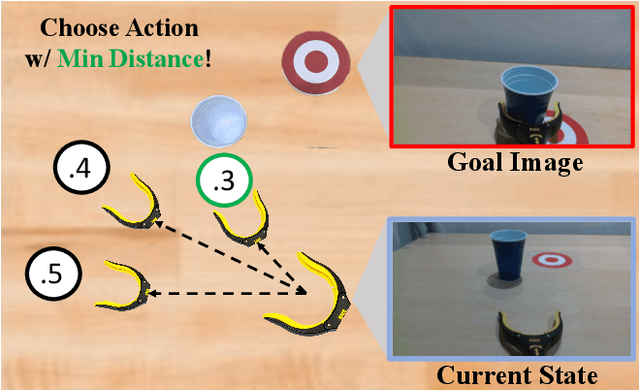
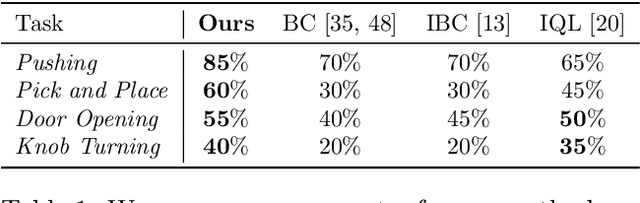
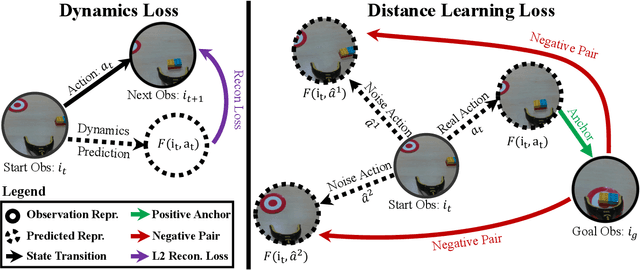
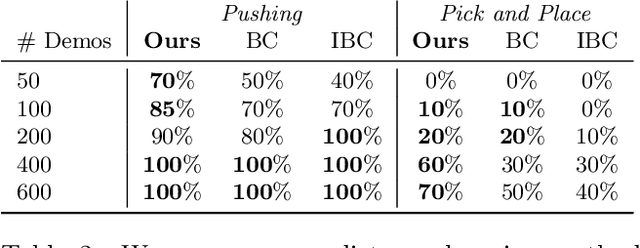
The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as distances (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time. For visualizations of the learned policies please check: https://agi-labs.github.io/manipulate-by-seeing/
Practicality of generalization guarantees for unsupervised domain adaptation with neural networks
Mar 15, 2023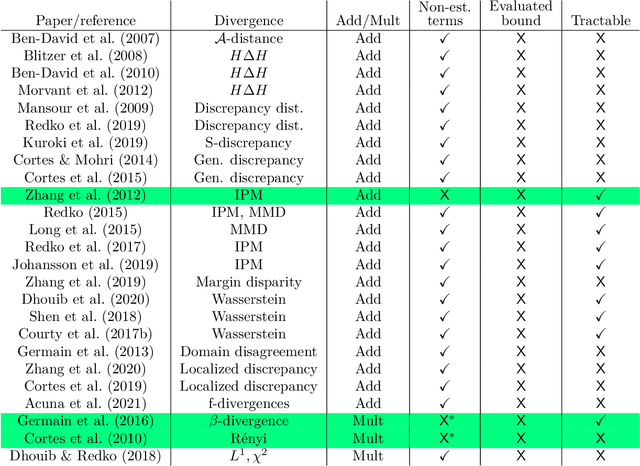
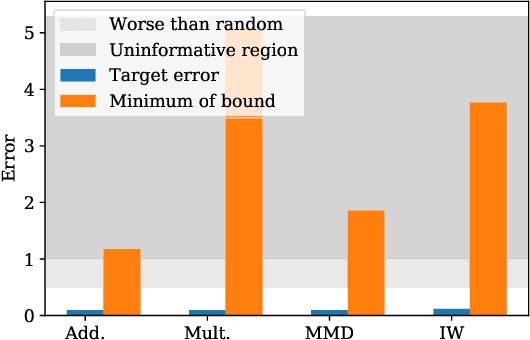
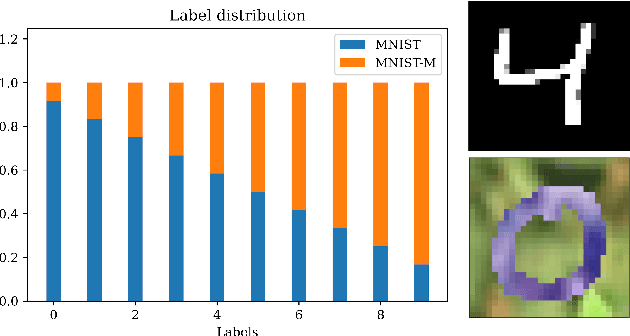
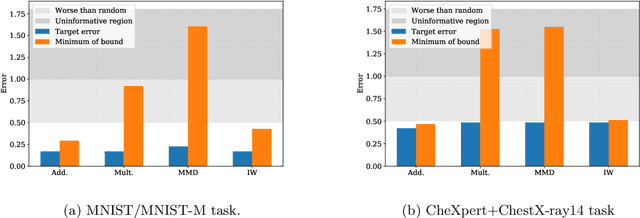
Understanding generalization is crucial to confidently engineer and deploy machine learning models, especially when deployment implies a shift in the data domain. For such domain adaptation problems, we seek generalization bounds which are tractably computable and tight. If these desiderata can be reached, the bounds can serve as guarantees for adequate performance in deployment. However, in applications where deep neural networks are the models of choice, deriving results which fulfill these remains an unresolved challenge; most existing bounds are either vacuous or has non-estimable terms, even in favorable conditions. In this work, we evaluate existing bounds from the literature with potential to satisfy our desiderata on domain adaptation image classification tasks, where deep neural networks are preferred. We find that all bounds are vacuous and that sample generalization terms account for much of the observed looseness, especially when these terms interact with measures of domain shift. To overcome this and arrive at the tightest possible results, we combine each bound with recent data-dependent PAC-Bayes analysis, greatly improving the guarantees. We find that, when domain overlap can be assumed, a simple importance weighting extension of previous work provides the tightest estimable bound. Finally, we study which terms dominate the bounds and identify possible directions for further improvement.
MobileBrick: Building LEGO for 3D Reconstruction on Mobile Devices
Mar 09, 2023
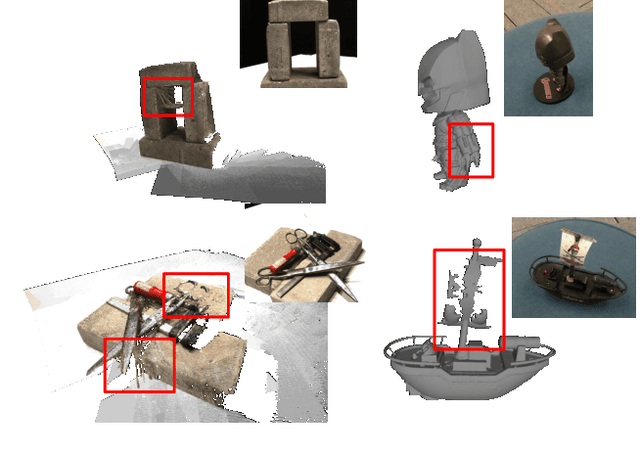
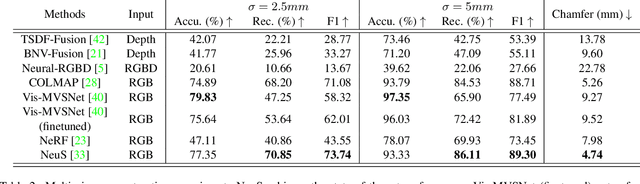
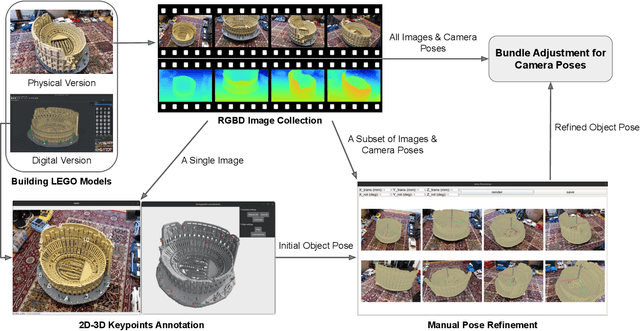
High-quality 3D ground-truth shapes are critical for 3D object reconstruction evaluation. However, it is difficult to create a replica of an object in reality, and even 3D reconstructions generated by 3D scanners have artefacts that cause biases in evaluation. To address this issue, we introduce a novel multi-view RGBD dataset captured using a mobile device, which includes highly precise 3D ground-truth annotations for 153 object models featuring a diverse set of 3D structures. We obtain precise 3D ground-truth shape without relying on high-end 3D scanners by utilising LEGO models with known geometry as the 3D structures for image capture. The distinct data modality offered by high-resolution RGB images and low-resolution depth maps captured on a mobile device, when combined with precise 3D geometry annotations, presents a unique opportunity for future research on high-fidelity 3D reconstruction. Furthermore, we evaluate a range of 3D reconstruction algorithms on the proposed dataset. Project page: http://code.active.vision/MobileBrick/
Replacement as a Self-supervision for Fine-grained Vision-language Pre-training
Mar 09, 2023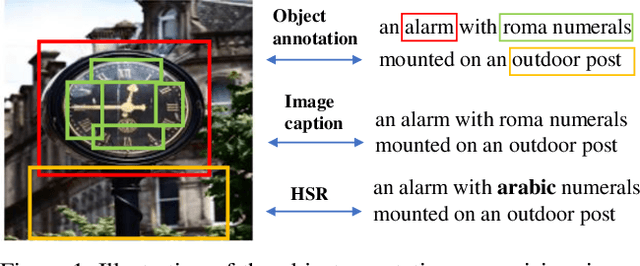
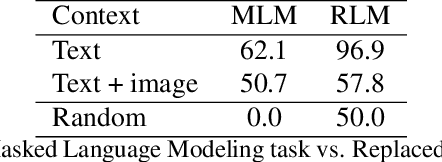
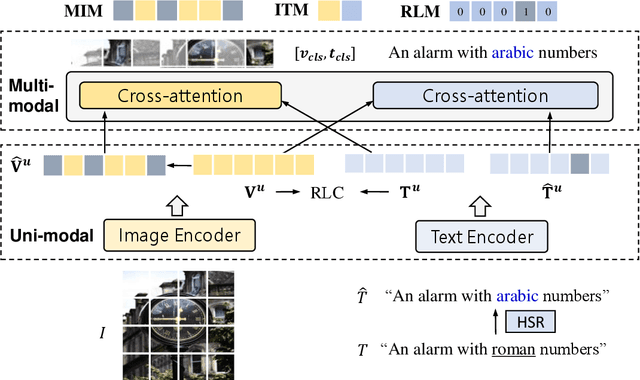

Fine-grained supervision based on object annotations has been widely used for vision and language pre-training (VLP). However, in real-world application scenarios, aligned multi-modal data is usually in the image-caption format, which only provides coarse-grained supervision. It is cost-expensive to collect object annotations and build object annotation pre-extractor for different scenarios. In this paper, we propose a fine-grained self-supervision signal without object annotations from a replacement perspective. First, we propose a homonym sentence rewriting (HSR) algorithm to provide token-level supervision. The algorithm replaces a verb/noun/adjective/quantifier word of the caption with its homonyms from WordNet. Correspondingly, we propose a replacement vision-language modeling (RVLM) framework to exploit the token-level supervision. Two replaced modeling tasks, i.e., replaced language contrastive (RLC) and replaced language modeling (RLM), are proposed to learn the fine-grained alignment. Extensive experiments on several downstream tasks demonstrate the superior performance of the proposed method.