 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Optical Flow from Geometric Matching Consistent Perspective
Mar 15, 2023

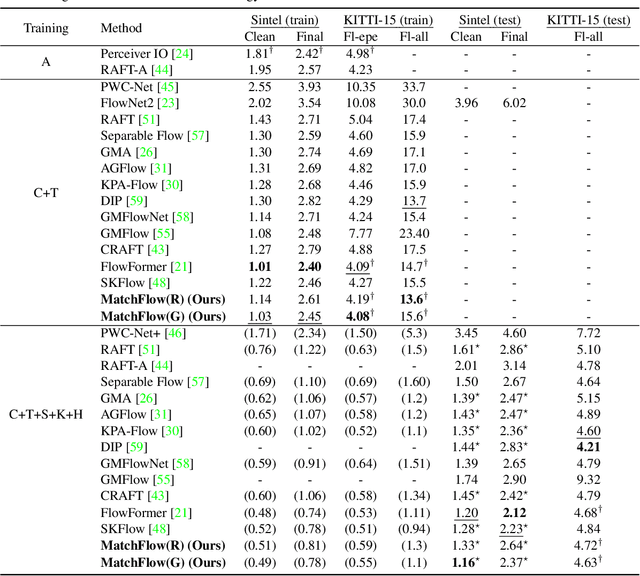
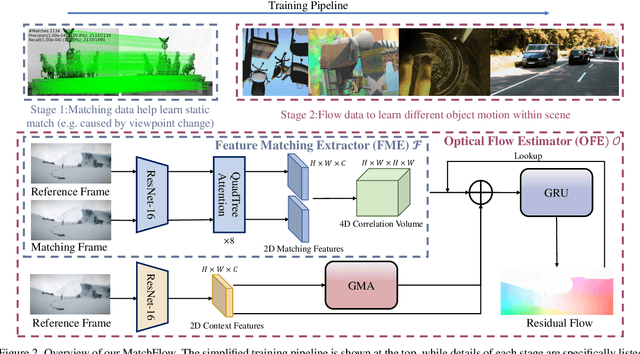
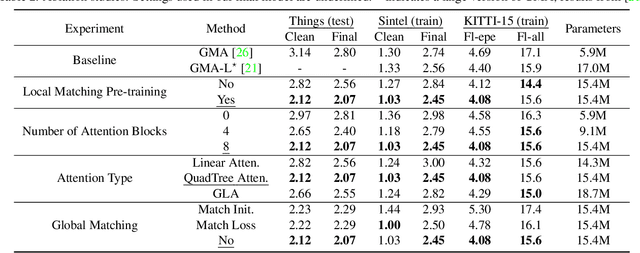
Optical flow estimation is a challenging problem remaining unsolved. Recent deep learning based optical flow models have achieved considerable success. However, these models often train networks from the scratch on standard optical flow data, which restricts their ability to robustly and geometrically match image features. In this paper, we propose a rethinking to previous optical flow estimation. We particularly leverage Geometric Image Matching (GIM) as a pre-training task for the optical flow estimation (MatchFlow) with better feature representations, as GIM shares some common challenges as optical flow estimation, and with massive labeled real-world data. Thus, matching static scenes helps to learn more fundamental feature correlations of objects and scenes with consistent displacements. Specifically, the proposed MatchFlow model employs a QuadTree attention-based network pre-trained on MegaDepth to extract coarse features for further flow regression. Extensive experiments show that our model has great cross-dataset generalization. Our method achieves 11.5% and 10.1% error reduction from GMA on Sintel clean pass and KITTI test set. At the time of anonymous submission, our MatchFlow(G) enjoys state-of-the-art performance on Sintel clean and final pass compared to published approaches with comparable computation and memory footprint. Codes and models will be released in https://github.com/DQiaole/MatchFlow.
FAQ: Feature Aggregated Queries for Transformer-based Video Object Detectors
Mar 15, 2023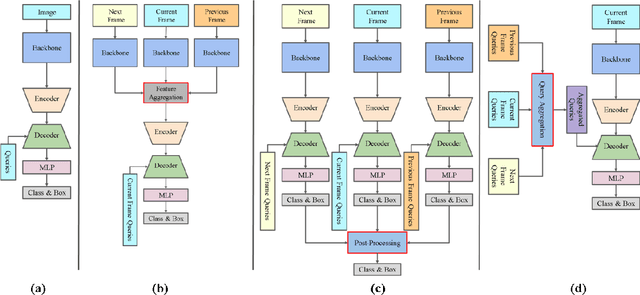
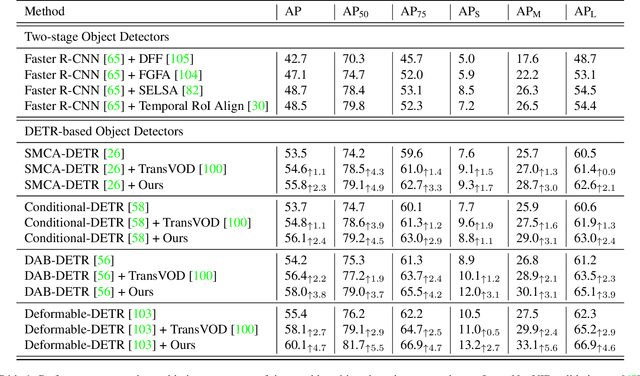
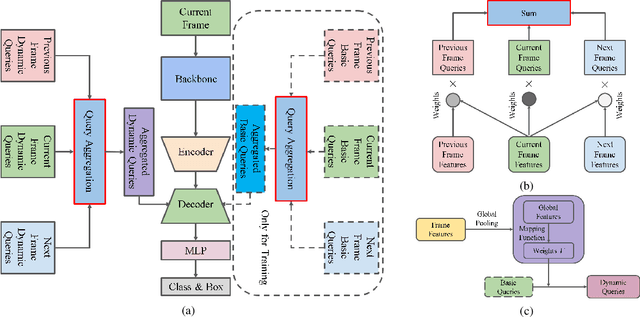
Video object detection needs to solve feature degradation situations that rarely happen in the image domain. One solution is to use the temporal information and fuse the features from the neighboring frames. With Transformerbased object detectors getting a better performance on the image domain tasks, recent works began to extend those methods to video object detection. However, those existing Transformer-based video object detectors still follow the same pipeline as those used for classical object detectors, like enhancing the object feature representations by aggregation. In this work, we take a different perspective on video object detection. In detail, we improve the qualities of queries for the Transformer-based models by aggregation. To achieve this goal, we first propose a vanilla query aggregation module that weighted averages the queries according to the features of the neighboring frames. Then, we extend the vanilla module to a more practical version, which generates and aggregates queries according to the features of the input frames. Extensive experimental results validate the effectiveness of our proposed methods: On the challenging ImageNet VID benchmark, when integrated with our proposed modules, the current state-of-the-art Transformer-based object detectors can be improved by more than 2.4% on mAP and 4.2% on AP50.
Significantly improving zero-shot X-ray pathology classification via fine-tuning pre-trained image-text encoders
Dec 14, 2022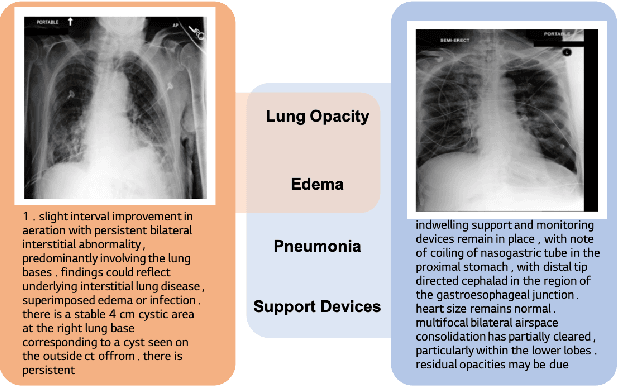
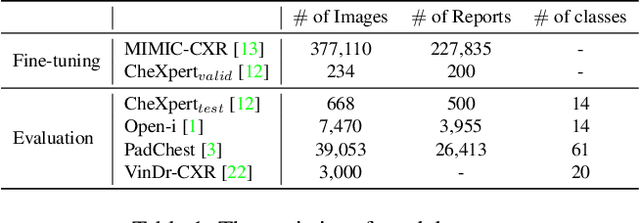
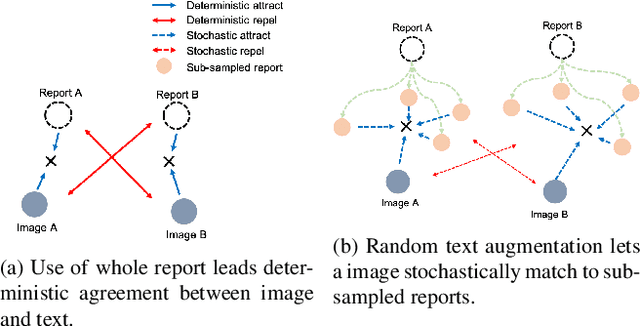
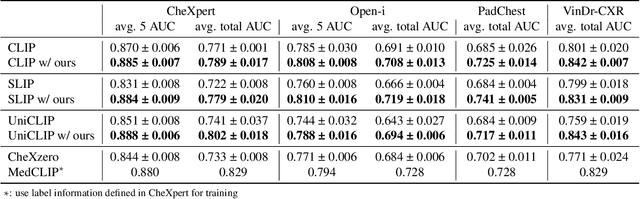
Deep neural networks have been successfully adopted to diverse domains including pathology classification based on medical images. However, large-scale and high-quality data to train powerful neural networks are rare in the medical domain as the labeling must be done by qualified experts. Researchers recently tackled this problem with some success by taking advantage of models pre-trained on large-scale general domain data. Specifically, researchers took contrastive image-text encoders (e.g., CLIP) and fine-tuned it with chest X-ray images and paired reports to perform zero-shot pathology classification, thus completely removing the need for pathology-annotated images to train a classification model. Existing studies, however, fine-tuned the pre-trained model with the same contrastive learning objective, and failed to exploit the multi-labeled nature of medical image-report pairs. In this paper, we propose a new fine-tuning strategy based on sentence sampling and positive-pair loss relaxation for improving the downstream zero-shot pathology classification performance, which can be applied to any pre-trained contrastive image-text encoders. Our method consistently showed dramatically improved zero-shot pathology classification performance on four different chest X-ray datasets and 3 different pre-trained models (5.77% average AUROC increase). In particular, fine-tuning CLIP with our method showed much comparable or marginally outperformed to board-certified radiologists (0.619 vs 0.625 in F1 score and 0.530 vs 0.544 in MCC) in zero-shot classification of five prominent diseases from the CheXpert dataset.
DLOFTBs -- Fast Tracking of Deformable Linear Objects with B-splines
Feb 27, 2023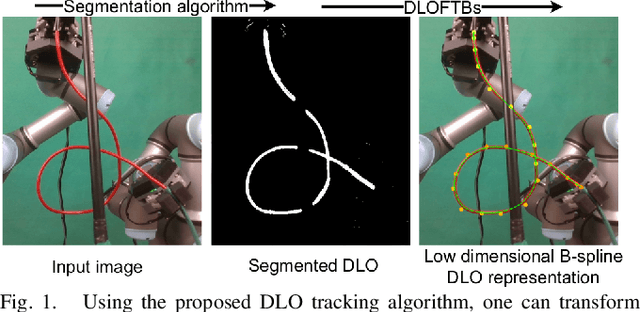



While the manipulation of rigid objects is an extensively explored research topic, deformable linear object (DLO) manipulation seems significantly underdeveloped. A potential reason for this is the inherent difficulty in describing and observing the state of the DLO as its geometry changes during manipulation. This paper proposes an algorithm for fast-tracking the shape of a DLO based on the masked image. Having no prior knowledge about the tracked object, the proposed method finds a reliable representation of the shape of the tracked object within tens of milliseconds. This algorithm's main idea is to first skeletonize the DLO mask image, walk through the parts of the DLO skeleton, arrange the segments into an ordered path, and finally fit a B-spline into it. Experiments show that our solution outperforms the State-of-the-Art approaches in DLO's shape reconstruction accuracy and algorithm running time and can handle challenging scenarios such as severe occlusions, self-intersections, and multiple DLOs in a single image.
Online Lane Graph Extraction from Onboard Video
Apr 03, 2023
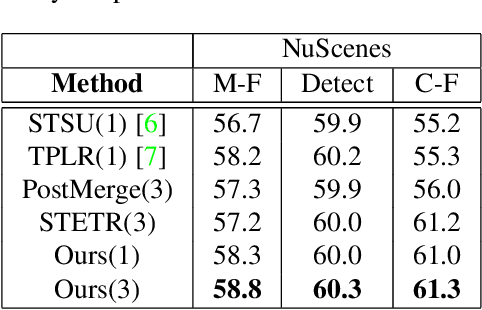

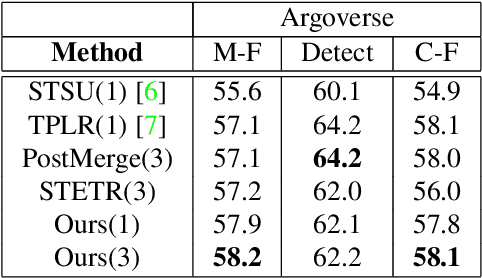
Autonomous driving requires a structured understanding of the surrounding road network to navigate. One of the most common and useful representation of such an understanding is done in the form of BEV lane graphs. In this work, we use the video stream from an onboard camera for online extraction of the surrounding's lane graph. Using video, instead of a single image, as input poses both benefits and challenges in terms of combining the information from different timesteps. We study the emerged challenges using three different approaches. The first approach is a post-processing step that is capable of merging single frame lane graph estimates into a unified lane graph. The second approach uses the spatialtemporal embeddings in the transformer to enable the network to discover the best temporal aggregation strategy. Finally, the third, and the proposed method, is an early temporal aggregation through explicit BEV projection and alignment of framewise features. A single model of this proposed simple, yet effective, method can process any number of images, including one, to produce accurate lane graphs. The experiments on the Nuscenes and Argoverse datasets show the validity of all the approaches while highlighting the superiority of the proposed method. The code will be made public.
Vision-Language Models for Vision Tasks: A Survey
Apr 03, 2023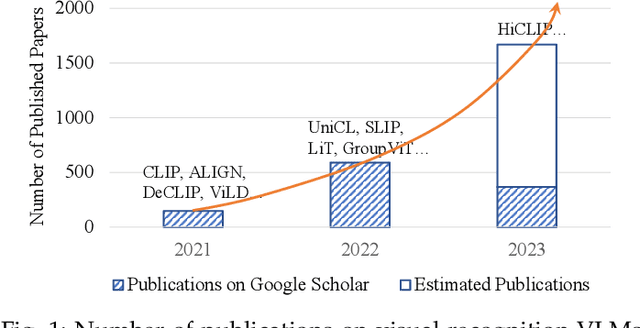
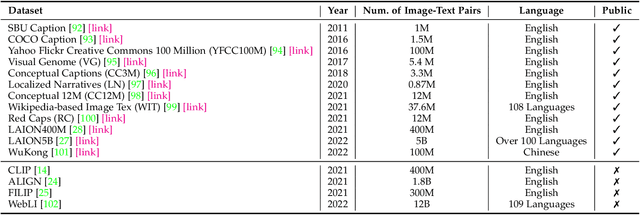
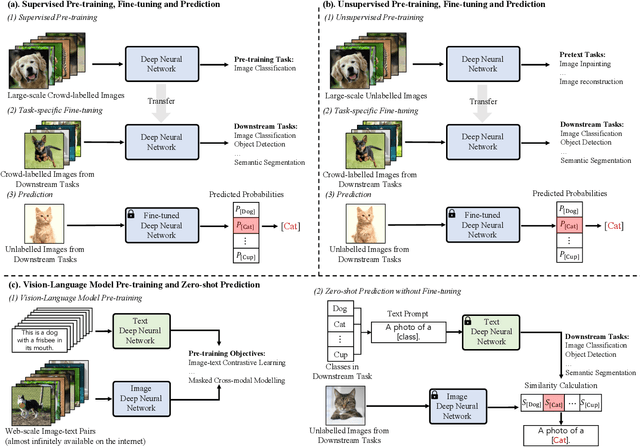
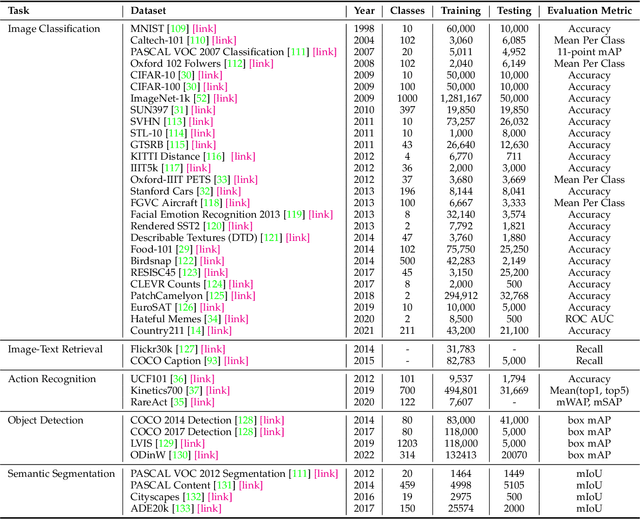
Most visual recognition studies rely heavily on crowd-labelled data in deep neural networks (DNNs) training, and they usually train a DNN for each single visual recognition task, leading to a laborious and time-consuming visual recognition paradigm. To address the two challenges, Vision-Language Models (VLMs) have been intensively investigated recently, which learns rich vision-language correlation from web-scale image-text pairs that are almost infinitely available on the Internet and enables zero-shot predictions on various visual recognition tasks with a single VLM. This paper provides a systematic review of visual language models for various visual recognition tasks, including: (1) the background that introduces the development of visual recognition paradigms; (2) the foundations of VLM that summarize the widely-adopted network architectures, pre-training objectives, and downstream tasks; (3) the widely-adopted datasets in VLM pre-training and evaluations; (4) the review and categorization of existing VLM pre-training methods, VLM transfer learning methods, and VLM knowledge distillation methods; (5) the benchmarking, analysis and discussion of the reviewed methods; (6) several research challenges and potential research directions that could be pursued in the future VLM studies for visual recognition. A project associated with this survey has been created at https://github.com/jingyi0000/VLM_survey.
VTAE: Variational Transformer Autoencoder with Manifolds Learning
Apr 03, 2023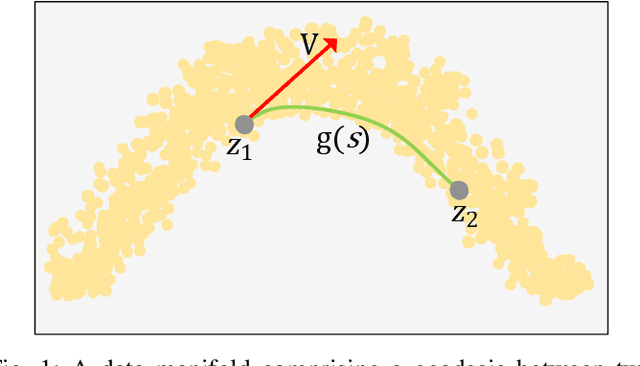
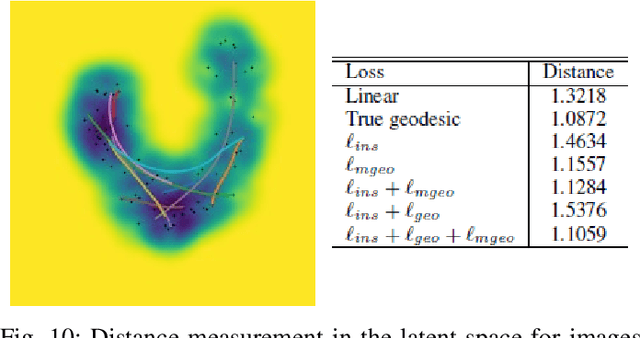
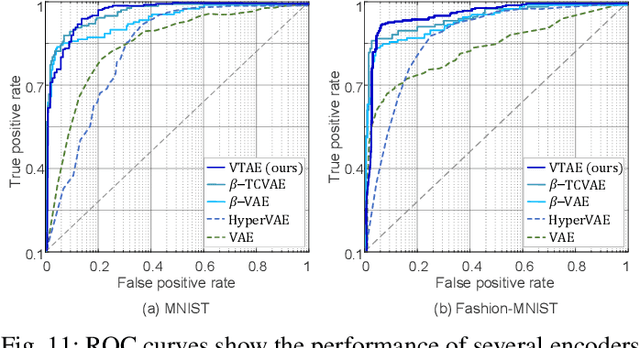
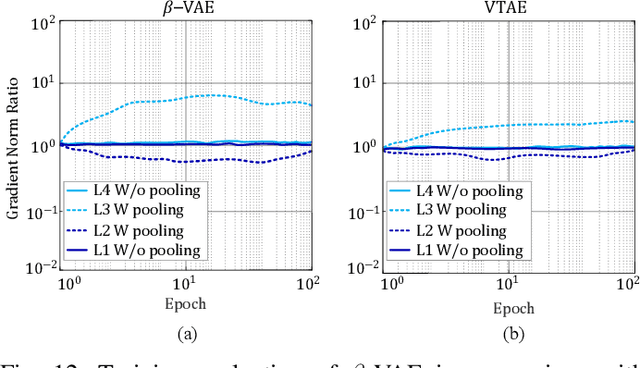
Deep generative models have demonstrated successful applications in learning non-linear data distributions through a number of latent variables and these models use a nonlinear function (generator) to map latent samples into the data space. On the other hand, the nonlinearity of the generator implies that the latent space shows an unsatisfactory projection of the data space, which results in poor representation learning. This weak projection, however, can be addressed by a Riemannian metric, and we show that geodesics computation and accurate interpolations between data samples on the Riemannian manifold can substantially improve the performance of deep generative models. In this paper, a Variational spatial-Transformer AutoEncoder (VTAE) is proposed to minimize geodesics on a Riemannian manifold and improve representation learning. In particular, we carefully design the variational autoencoder with an encoded spatial-Transformer to explicitly expand the latent variable model to data on a Riemannian manifold, and obtain global context modelling. Moreover, to have smooth and plausible interpolations while traversing between two different objects' latent representations, we propose a geodesic interpolation network different from the existing models that use linear interpolation with inferior performance. Experiments on benchmarks show that our proposed model can improve predictive accuracy and versatility over a range of computer vision tasks, including image interpolations, and reconstructions.
D-Score: A White-Box Diagnosis Score for CNNs Based on Mutation Operators
Apr 03, 2023
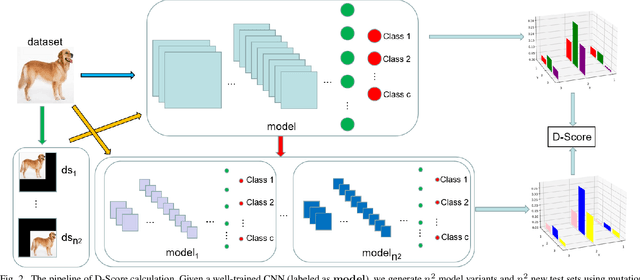
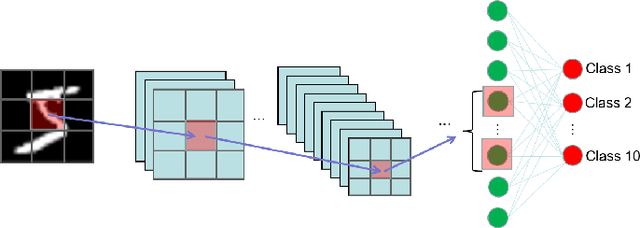

Convolutional neural networks (CNNs) have been widely applied in many safety-critical domains, such as autonomous driving and medical diagnosis. However, concerns have been raised with respect to the trustworthiness of these models: The standard testing method evaluates the performance of a model on a test set, while low-quality and insufficient test sets can lead to unreliable evaluation results, which can have unforeseeable consequences. Therefore, how to comprehensively evaluate CNNs and, based on the evaluation results, how to enhance their trustworthiness are the key problems to be urgently addressed. Prior work has used mutation tests to evaluate the test sets of CNNs. However, the evaluation scores are black boxes and not explicit enough for what is being tested. In this paper, we propose a white-box diagnostic approach that uses mutation operators and image transformation to calculate the feature and attention distribution of the model and further present a diagnosis score, namely D-Score, to reflect the model's robustness and fitness to a dataset. We also propose a D-Score based data augmentation method to enhance the CNN's performance to translations and rescalings. Comprehensive experiments on two widely used datasets and three commonly adopted CNNs demonstrate the effectiveness of our approach.
3D Data Augmentation for Driving Scenes on Camera
Mar 18, 2023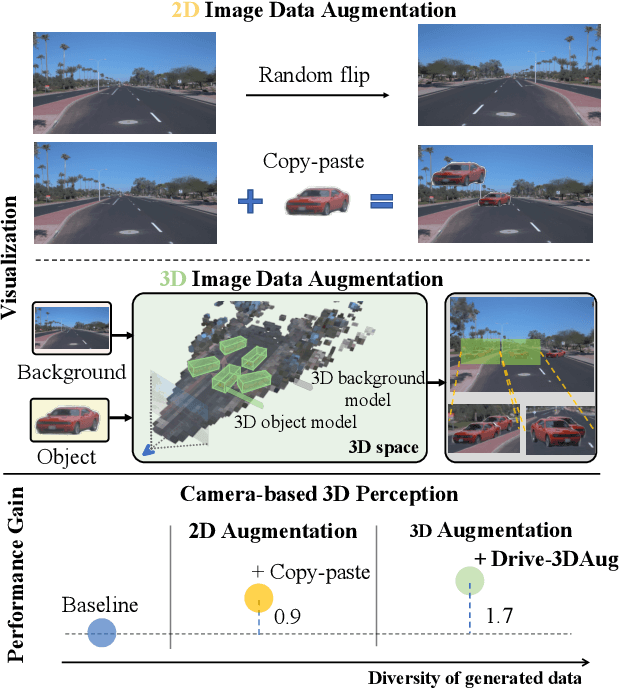
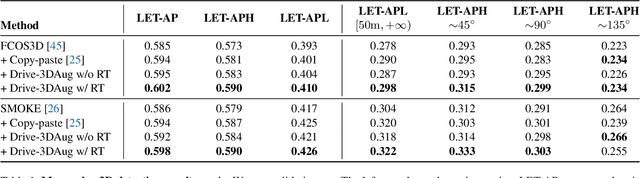
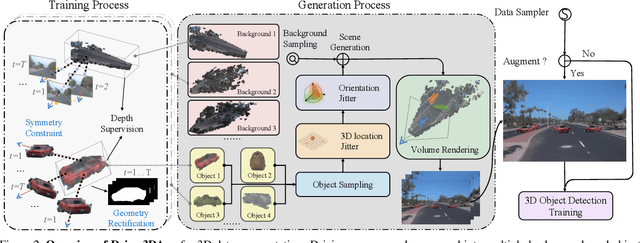
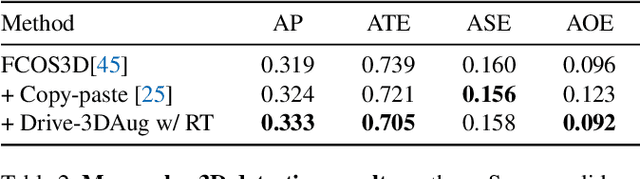
Driving scenes are extremely diverse and complicated that it is impossible to collect all cases with human effort alone. While data augmentation is an effective technique to enrich the training data, existing methods for camera data in autonomous driving applications are confined to the 2D image plane, which may not optimally increase data diversity in 3D real-world scenarios. To this end, we propose a 3D data augmentation approach termed Drive-3DAug, aiming at augmenting the driving scenes on camera in the 3D space. We first utilize Neural Radiance Field (NeRF) to reconstruct the 3D models of background and foreground objects. Then, augmented driving scenes can be obtained by placing the 3D objects with adapted location and orientation at the pre-defined valid region of backgrounds. As such, the training database could be effectively scaled up. However, the 3D object modeling is constrained to the image quality and the limited viewpoints. To overcome these problems, we modify the original NeRF by introducing a geometric rectified loss and a symmetric-aware training strategy. We evaluate our method for the camera-only monocular 3D detection task on the Waymo and nuScences datasets. The proposed data augmentation approach contributes to a gain of 1.7% and 1.4% in terms of detection accuracy, on Waymo and nuScences respectively. Furthermore, the constructed 3D models serve as digital driving assets and could be recycled for different detectors or other 3D perception tasks.
ProSFDA: Prompt Learning based Source-free Domain Adaptation for Medical Image Segmentation
Nov 21, 2022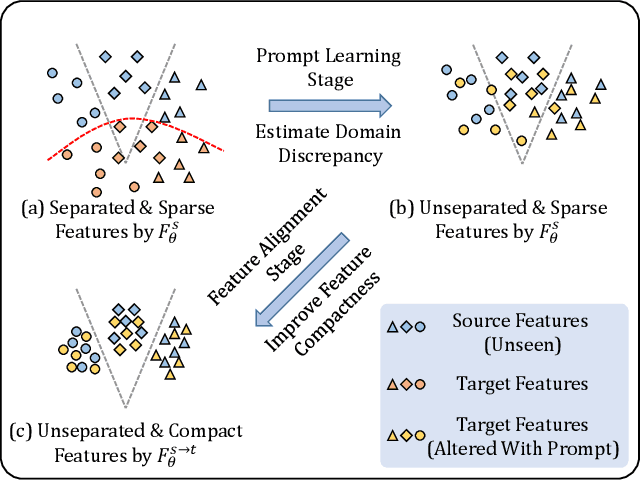
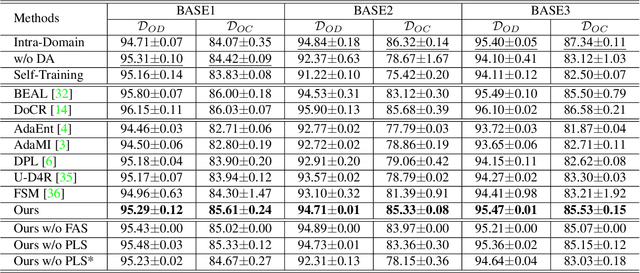
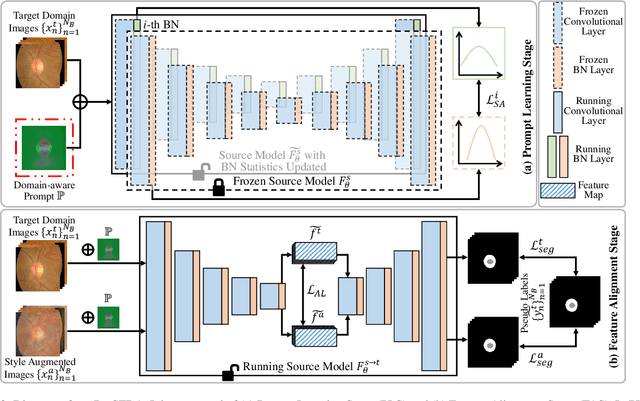
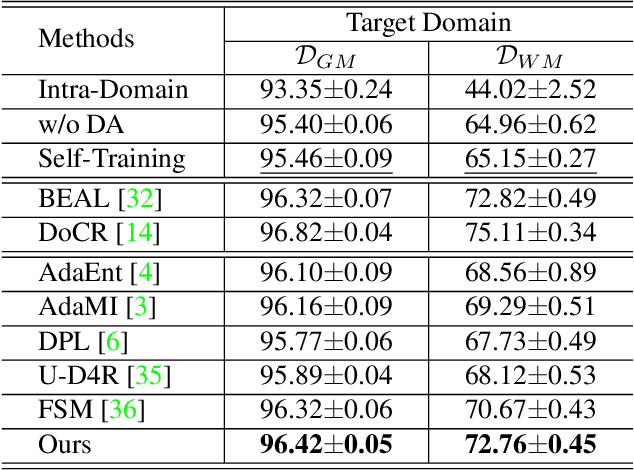
The domain discrepancy existed between medical images acquired in different situations renders a major hurdle in deploying pre-trained medical image segmentation models for clinical use. Since it is less possible to distribute training data with the pre-trained model due to the huge data size and privacy concern, source-free unsupervised domain adaptation (SFDA) has recently been increasingly studied based on either pseudo labels or prior knowledge. However, the image features and probability maps used by pseudo label-based SFDA and the consistent prior assumption and the prior prediction network used by prior-guided SFDA may become less reliable when the domain discrepancy is large. In this paper, we propose a \textbf{Pro}mpt learning based \textbf{SFDA} (\textbf{ProSFDA}) method for medical image segmentation, which aims to improve the quality of domain adaption by minimizing explicitly the domain discrepancy. Specifically, in the prompt learning stage, we estimate source-domain images via adding a domain-aware prompt to target-domain images, then optimize the prompt via minimizing the statistic alignment loss, and thereby prompt the source model to generate reliable predictions on (altered) target-domain images. In the feature alignment stage, we also align the features of target-domain images and their styles-augmented counterparts to optimize the source model, and hence push the model to extract compact features. We evaluate our ProSFDA on two multi-domain medical image segmentation benchmarks. Our results indicate that the proposed ProSFDA outperforms substantially other SFDA methods and is even comparable to UDA methods. Code will be available at \url{https://github.com/ShishuaiHu/ProSFDA}.