 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Constant Parameters: Hyper Prediction Models and HyperMPC
Aug 08, 2025Model Predictive Control (MPC) is among the most widely adopted and reliable methods for robot control, relying critically on an accurate dynamics model. However, existing dynamics models used in the gradient-based MPC are limited by computational complexity and state representation. To address this limitation, we propose the Hyper Prediction Model (HyperPM) - a novel approach in which we project the unmodeled dynamics onto a time-dependent dynamics model. This time-dependency is captured through time-varying model parameters, whose evolution over the MPC prediction horizon is learned using a neural network. Such formulation preserves the computational efficiency and robustness of the base model while equipping it with the capacity to anticipate previously unmodeled phenomena. We evaluated the proposed approach on several challenging systems, including real-world F1TENTH autonomous racing, and demonstrated that it significantly reduces long-horizon prediction errors. Moreover, when integrated within the MPC framework (HyperMPC), our method consistently outperforms existing state-of-the-art techniques.
Robust Localization, Mapping, and Navigation for Quadruped Robots
May 04, 2025Quadruped robots are currently a widespread platform for robotics research, thanks to powerful Reinforcement Learning controllers and the availability of cheap and robust commercial platforms. However, to broaden the adoption of the technology in the real world, we require robust navigation stacks relying only on low-cost sensors such as depth cameras. This paper presents a first step towards a robust localization, mapping, and navigation system for low-cost quadruped robots. In pursuit of this objective we combine contact-aided kinematic, visual-inertial odometry, and depth-stabilized vision, enhancing stability and accuracy of the system. Our results in simulation and two different real-world quadruped platforms show that our system can generate an accurate 2D map of the environment, robustly localize itself, and navigate autonomously. Furthermore, we present in-depth ablation studies of the important components of the system and their impact on localization accuracy. Videos, code, and additional experiments can be found on the project website: https://sites.google.com/view/low-cost-quadruped-slam
On learning racing policies with reinforcement learning
Apr 03, 2025



Fully autonomous vehicles promise enhanced safety and efficiency. However, ensuring reliable operation in challenging corner cases requires control algorithms capable of performing at the vehicle limits. We address this requirement by considering the task of autonomous racing and propose solving it by learning a racing policy using Reinforcement Learning (RL). Our approach leverages domain randomization, actuator dynamics modeling, and policy architecture design to enable reliable and safe zero-shot deployment on a real platform. Evaluated on the F1TENTH race car, our RL policy not only surpasses a state-of-the-art Model Predictive Control (MPC), but, to the best of our knowledge, also represents the first instance of an RL policy outperforming expert human drivers in RC racing. This work identifies the key factors driving this performance improvement, providing critical insights for the design of robust RL-based control strategies for autonomous vehicles.
One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
Sep 10, 2024



Deep Reinforcement Learning techniques are achieving state-of-the-art results in robust legged locomotion. While there exists a wide variety of legged platforms such as quadruped, humanoids, and hexapods, the field is still missing a single learning framework that can control all these different embodiments easily and effectively and possibly transfer, zero or few-shot, to unseen robot embodiments. We introduce URMA, the Unified Robot Morphology Architecture, to close this gap. Our framework brings the end-to-end Multi-Task Reinforcement Learning approach to the realm of legged robots, enabling the learned policy to control any type of robot morphology. The key idea of our method is to allow the network to learn an abstract locomotion controller that can be seamlessly shared between embodiments thanks to our morphology-agnostic encoders and decoders. This flexible architecture can be seen as a potential first step in building a foundation model for legged robot locomotion. Our experiments show that URMA can learn a locomotion policy on multiple embodiments that can be easily transferred to unseen robot platforms in simulation and the real world.
Learning dynamics models for velocity estimation in autonomous racing
Aug 28, 2024



Velocity estimation is of great importance in autonomous racing. Still, existing solutions are characterized by limited accuracy, especially in the case of aggressive driving or poor generalization to unseen road conditions. To address these issues, we propose to utilize Unscented Kalman Filter (UKF) with a learned dynamics model that is optimized directly for the state estimation task. Moreover, we propose to aid this model with the online-estimated friction coefficient, which increases the estimation accuracy and enables zero-shot adaptation to the new road conditions. To evaluate the UKF-based velocity estimator with the proposed dynamics model, we introduced a publicly available dataset of aggressive manoeuvres performed by an F1TENTH car, with sideslip angles reaching 40{\deg}. Using this dataset, we show that learning the dynamics model through UKF leads to improved estimation performance and that the proposed solution outperforms state-of-the-art learning-based state estimators by 17% in the nominal scenario. Moreover, we present unseen zero-shot adaptation abilities of the proposed method to the new road surface thanks to the use of the proposed learning-based tire dynamics model with online friction estimation.
Bridging the gap between Learning-to-plan, Motion Primitives and Safe Reinforcement Learning
Aug 26, 2024



Trajectory planning under kinodynamic constraints is fundamental for advanced robotics applications that require dexterous, reactive, and rapid skills in complex environments. These constraints, which may represent task, safety, or actuator limitations, are essential for ensuring the proper functioning of robotic platforms and preventing unexpected behaviors. Recent advances in kinodynamic planning demonstrate that learning-to-plan techniques can generate complex and reactive motions under intricate constraints. However, these techniques necessitate the analytical modeling of both the robot and the entire task, a limiting assumption when systems are extremely complex or when constructing accurate task models is prohibitive. This paper addresses this limitation by combining learning-to-plan methods with reinforcement learning, resulting in a novel integration of black-box learning of motion primitives and optimization. We evaluate our approach against state-of-the-art safe reinforcement learning methods, showing that our technique, particularly when exploiting task structure, outperforms baseline methods in challenging scenarios such as planning to hit in robot air hockey. This work demonstrates the potential of our integrated approach to enhance the performance and safety of robots operating under complex kinodynamic constraints.
Learning Quasi-Static 3D Models of Markerless Deformable Linear Objects for Bimanual Robotic Manipulation
Sep 14, 2023



The robotic manipulation of Deformable Linear Objects (DLOs) is a vital and challenging task that is important in many practical applications. Classical model-based approaches to this problem require an accurate model to capture how robot motions affect the deformation of the DLO. Nowadays, data-driven models offer the best tradeoff between quality and computation time. This paper analyzes several learning-based 3D models of the DLO and proposes a new one based on the Transformer architecture that achieves superior accuracy, even on the DLOs of different lengths, thanks to the proposed scaling method. Moreover, we introduce a data augmentation technique, which improves the prediction performance of almost all considered DLO data-driven models. Thanks to this technique, even a simple Multilayer Perceptron (MLP) achieves close to state-of-the-art performance while being significantly faster to evaluate. In the experiments, we compare the performance of the learning-based 3D models of the DLO on several challenging datasets quantitatively and demonstrate their applicability in the task of shaping a DLO.
DLOFTBs -- Fast Tracking of Deformable Linear Objects with B-splines
Feb 27, 2023



While the manipulation of rigid objects is an extensively explored research topic, deformable linear object (DLO) manipulation seems significantly underdeveloped. A potential reason for this is the inherent difficulty in describing and observing the state of the DLO as its geometry changes during manipulation. This paper proposes an algorithm for fast-tracking the shape of a DLO based on the masked image. Having no prior knowledge about the tracked object, the proposed method finds a reliable representation of the shape of the tracked object within tens of milliseconds. This algorithm's main idea is to first skeletonize the DLO mask image, walk through the parts of the DLO skeleton, arrange the segments into an ordered path, and finally fit a B-spline into it. Experiments show that our solution outperforms the State-of-the-Art approaches in DLO's shape reconstruction accuracy and algorithm running time and can handle challenging scenarios such as severe occlusions, self-intersections, and multiple DLOs in a single image.
Fast Kinodynamic Planning on the Constraint Manifold with Deep Neural Networks
Jan 12, 2023



Motion planning is a mature area of research in robotics with many well-established methods based on optimization or sampling the state space, suitable for solving kinematic motion planning. However, when dynamic motions under constraints are needed and computation time is limited, fast kinodynamic planning on the constraint manifold is indispensable. In recent years, learning-based solutions have become alternatives to classical approaches, but they still lack comprehensive handling of complex constraints, such as planning on a lower-dimensional manifold of the task space while considering the robot's dynamics. This paper introduces a novel learning-to-plan framework that exploits the concept of constraint manifold, including dynamics, and neural planning methods. Our approach generates plans satisfying an arbitrary set of constraints and computes them in a short constant time, namely the inference time of a neural network. This allows the robot to plan and replan reactively, making our approach suitable for dynamic environments. We validate our approach on two simulated tasks and in a demanding real-world scenario, where we use a Kuka LBR Iiwa 14 robotic arm to perform the hitting movement in robotic Air Hockey.
Teaching Autonomous Systems Hands-On: Leveraging Modular Small-Scale Hardware in the Robotics Classroom
Sep 21, 2022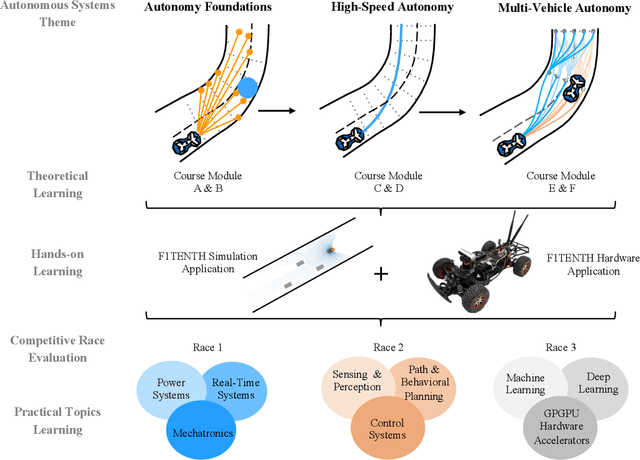
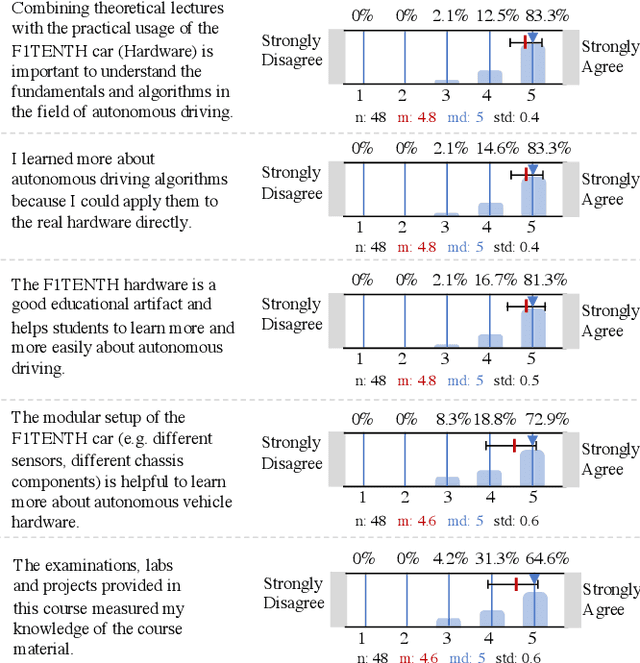
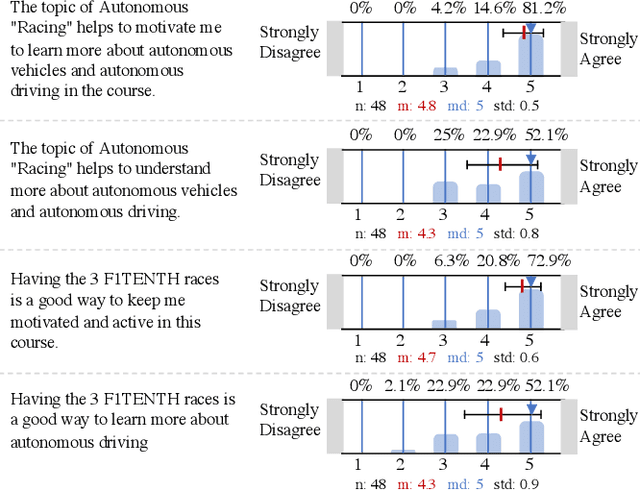
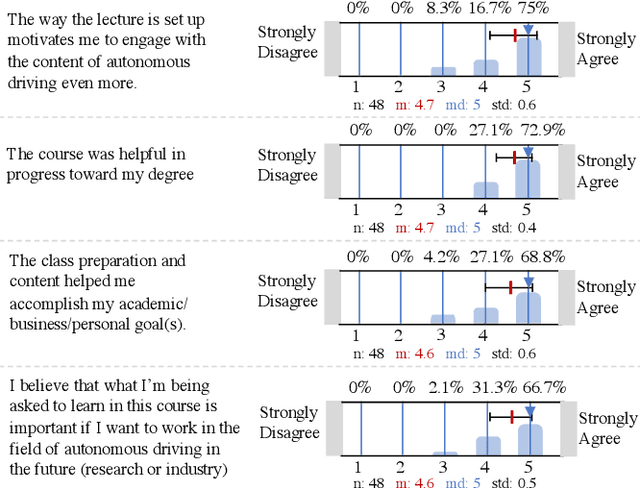
Although robotics courses are well established in higher education, the courses often focus on theory and sometimes lack the systematic coverage of the techniques involved in developing, deploying, and applying software to real hardware. Additionally, most hardware platforms for robotics teaching are low-level toys aimed at younger students at middle-school levels. To address this gap, an autonomous vehicle hardware platform, called F1TENTH, is developed for teaching autonomous systems hands-on. This article describes the teaching modules and software stack for teaching at various educational levels with the theme of "racing" and competitions that replace exams. The F1TENTH vehicles offer a modular hardware platform and its related software for teaching the fundamentals of autonomous driving algorithms. From basic reactive methods to advanced planning algorithms, the teaching modules enhance students' computational thinking through autonomous driving with the F1TENTH vehicle. The F1TENTH car fills the gap between research platforms and low-end toy cars and offers hands-on experience in learning the topics in autonomous systems. Four universities have adopted the teaching modules for their semester-long undergraduate and graduate courses for multiple years. Student feedback is used to analyze the effectiveness of the F1TENTH platform. More than 80% of the students strongly agree that the hardware platform and modules greatly motivate their learning, and more than 70% of the students strongly agree that the hardware-enhanced their understanding of the subjects. The survey results show that more than 80% of the students strongly agree that the competitions motivate them for the course.