 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bringing Inputs to Shared Domains for 3D Interacting Hands Recovery in the Wild
Mar 23, 2023
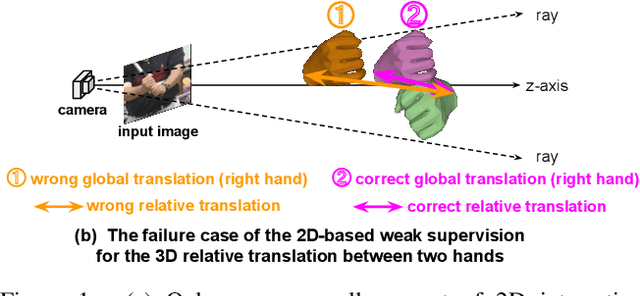

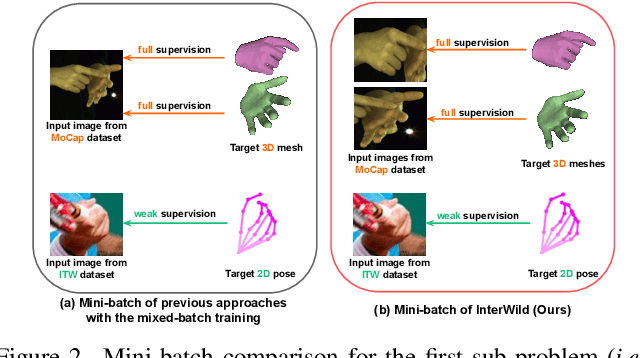
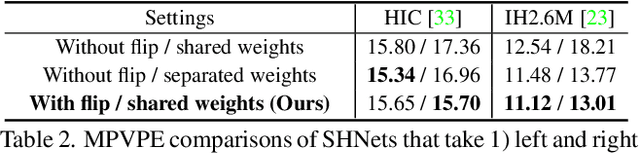
Despite recent achievements, existing 3D interacting hands recovery methods have shown results mainly on motion capture (MoCap) environments, not on in-the-wild (ITW) ones. This is because collecting 3D interacting hands data in the wild is extremely challenging, even for the 2D data. We present InterWild, which brings MoCap and ITW samples to shared domains for robust 3D interacting hands recovery in the wild with a limited amount of ITW 2D/3D interacting hands data. 3D interacting hands recovery consists of two sub-problems: 1) 3D recovery of each hand and 2) 3D relative translation recovery between two hands. For the first sub-problem, we bring MoCap and ITW samples to a shared 2D scale space. Although ITW datasets provide a limited amount of 2D/3D interacting hands, they contain large-scale 2D single hand data. Motivated by this, we use a single hand image as an input for the first sub-problem regardless of whether two hands are interacting. Hence, interacting hands of MoCap datasets are brought to the 2D scale space of single hands of ITW datasets. For the second sub-problem, we bring MoCap and ITW samples to a shared appearance-invariant space. Unlike the first sub-problem, 2D labels of ITW datasets are not helpful for the second sub-problem due to the 3D translation's ambiguity. Hence, instead of relying on ITW samples, we amplify the generalizability of MoCap samples by taking only a geometric feature without an image as an input for the second sub-problem. As the geometric feature is invariant to appearances, MoCap and ITW samples do not suffer from a huge appearance gap between the two datasets. The code is publicly available at https://github.com/facebookresearch/InterWild.
Zero-Shot Object Segmentation through Concept Distillation from Generative Image Foundation Models
Dec 29, 2022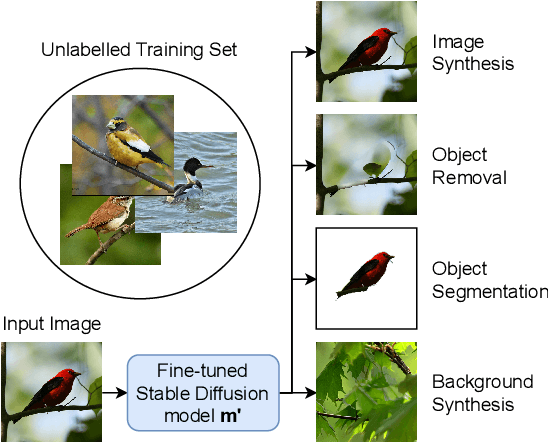
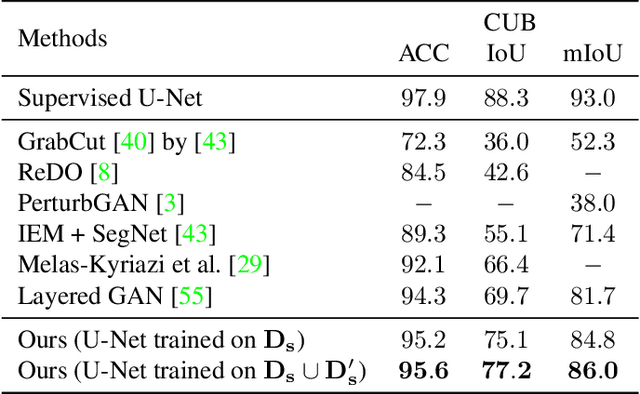
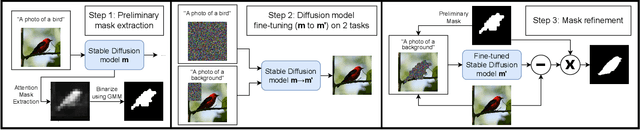

Curating datasets for object segmentation is a difficult task. With the advent of large-scale pre-trained generative models, conditional image generation has been given a significant boost in result quality and ease of use. In this paper, we present a novel method that enables the generation of general foreground-background segmentation models from simple textual descriptions, without requiring segmentation labels. We leverage and explore pre-trained latent diffusion models, to automatically generate weak segmentation masks for concepts and objects. The masks are then used to fine-tune the diffusion model on an inpainting task, which enables fine-grained removal of the object, while at the same time providing a synthetic foreground and background dataset. We demonstrate that using this method beats previous methods in both discriminative and generative performance and closes the gap with fully supervised training while requiring no pixel-wise object labels. We show results on the task of segmenting four different objects (humans, dogs, cars, birds).
Downscaled Representation Matters: Improving Image Rescaling with Collaborative Downscaled Images
Nov 19, 2022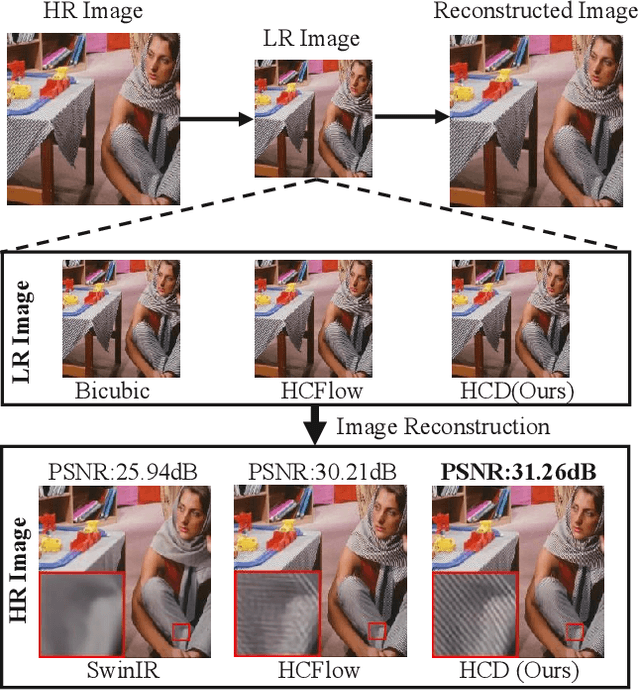
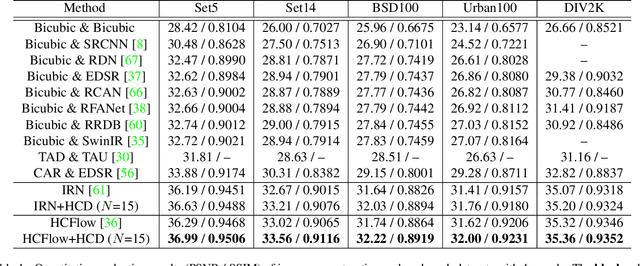
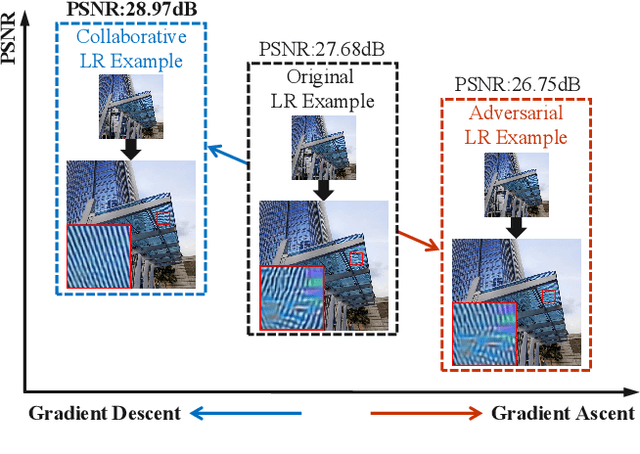

Deep networks have achieved great success in image rescaling (IR) task that seeks to learn the optimal downscaled representations, i.e., low-resolution (LR) images, to reconstruct the original high-resolution (HR) images. Compared with super-resolution methods that consider a fixed downscaling scheme, e.g., bicubic, IR often achieves significantly better reconstruction performance thanks to the learned downscaled representations. This highlights the importance of a good downscaled representation in image reconstruction tasks. Existing IR methods mainly learn the downscaled representation by jointly optimizing the downscaling and upscaling models. Unlike them, we seek to improve the downscaled representation through a different and more direct way: optimizing the downscaled image itself instead of the down-/upscaling models. Specifically, we propose a collaborative downscaling scheme that directly generates the collaborative LR examples by descending the gradient w.r.t. the reconstruction loss on them to benefit the IR process. Furthermore, since LR images are downscaled from the corresponding HR images, one can also improve the downscaled representation if we have a better representation in the HR domain. Inspired by this, we propose a Hierarchical Collaborative Downscaling (HCD) method that performs gradient descent in both HR and LR domains to improve the downscaled representations. Extensive experiments show that our HCD significantly improves the reconstruction performance both quantitatively and qualitatively. Moreover, we also highlight the flexibility of our HCD since it can generalize well across diverse IR models.
HumanDiffusion: a Coarse-to-Fine Alignment Diffusion Framework for Controllable Text-Driven Person Image Generation
Nov 11, 2022
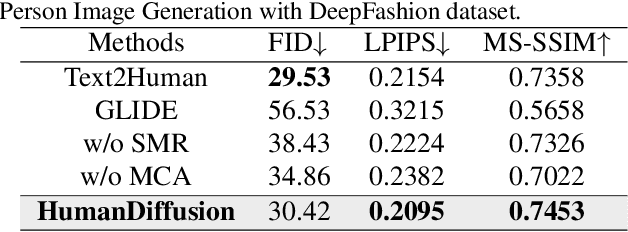
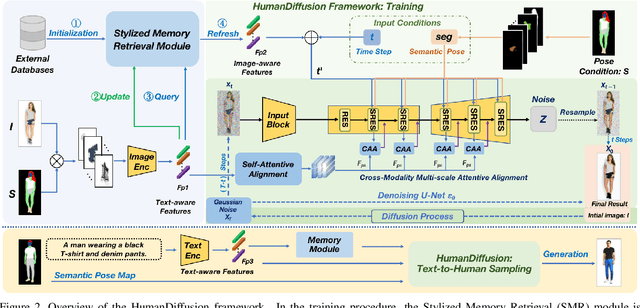
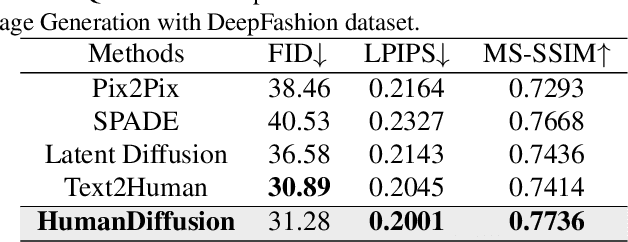
Text-driven person image generation is an emerging and challenging task in cross-modality image generation. Controllable person image generation promotes a wide range of applications such as digital human interaction and virtual try-on. However, previous methods mostly employ single-modality information as the prior condition (e.g. pose-guided person image generation), or utilize the preset words for text-driven human synthesis. Introducing a sentence composed of free words with an editable semantic pose map to describe person appearance is a more user-friendly way. In this paper, we propose HumanDiffusion, a coarse-to-fine alignment diffusion framework, for text-driven person image generation. Specifically, two collaborative modules are proposed, the Stylized Memory Retrieval (SMR) module for fine-grained feature distillation in data processing and the Multi-scale Cross-modality Alignment (MCA) module for coarse-to-fine feature alignment in diffusion. These two modules guarantee the alignment quality of the text and image, from image-level to feature-level, from low-resolution to high-resolution. As a result, HumanDiffusion realizes open-vocabulary person image generation with desired semantic poses. Extensive experiments conducted on DeepFashion demonstrate the superiority of our method compared with previous approaches. Moreover, better results could be obtained for complicated person images with various details and uncommon poses.
3D-Aware Object Localization using Gaussian Implicit Occupancy Function
Mar 03, 2023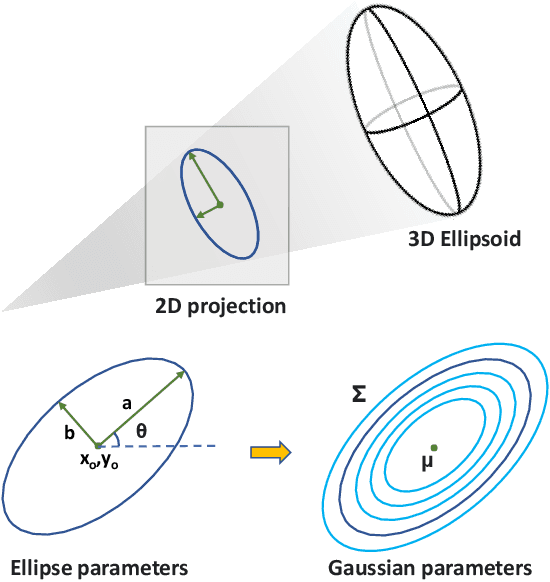

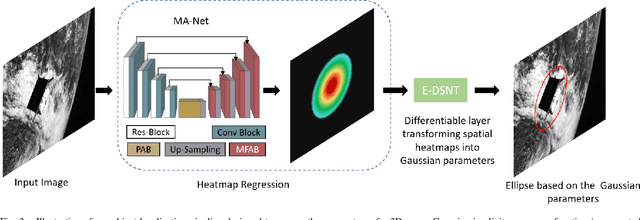

To automatically localize a target object in an image is crucial for many computer vision applications. Recently ellipse representations have been identified as an alternative to axis-aligned bounding boxes for object localization. This paper considers 3D-aware ellipse labels, i.e., which are projections of a 3D ellipsoidal approximation of the object in the images for 2D target localization. Such generic ellipsoidal models allow for handling coarsely known targets, and 3D-aware ellipse detections carry more geometric information about the object than traditional 3D-agnostic bounding box labels. We propose to have a new look at ellipse regression and replace the geometric ellipse parameters with the parameters of an implicit Gaussian distribution encoding object occupancy in the image. The models are trained to regress the values of this bivariate Gaussian distribution over the image pixels using a continuous statistical loss function. We introduce a novel non-trainable differentiable layer, E-DSNT, to extract the distribution parameters. Also, we describe how to readily generate consistent 3D-aware Gaussian occupancy parameters using only coarse dimensions of the target and relative pose labels. We extend three existing spacecraft pose estimation datasets with 3D-aware Gaussian occupancy labels to validate our hypothesis.
Co-training with High-Confidence Pseudo Labels for Semi-supervised Medical Image Segmentation
Jan 11, 2023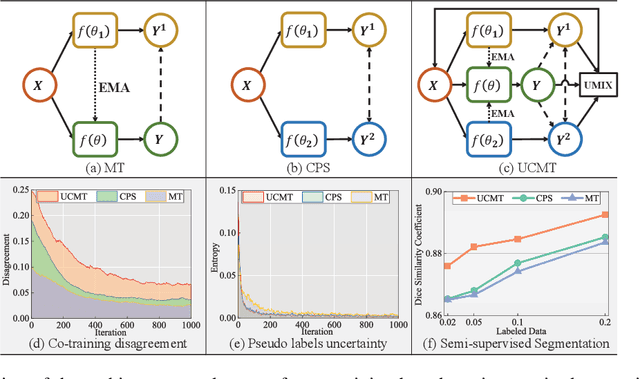
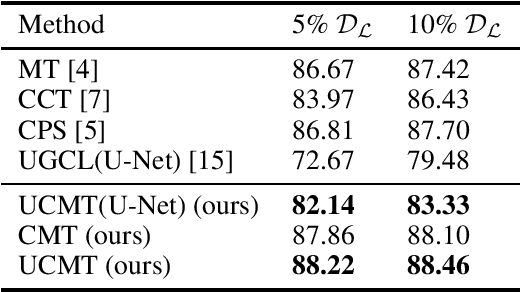
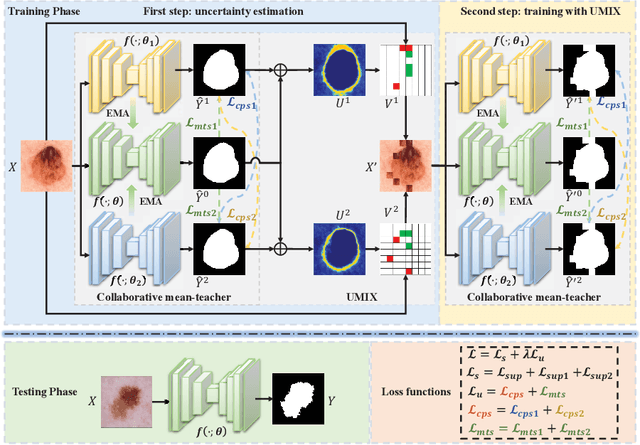
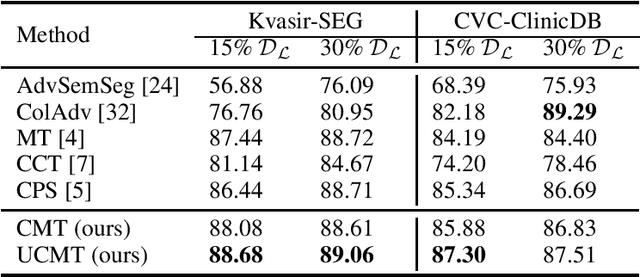
High-quality pseudo labels are essential for semi-supervised semantic segmentation. Consistency regularization and pseudo labeling-based semi-supervised methods perform co-training using the pseudo labels from multi-view inputs. However, such co-training models tend to converge early to a consensus during training, so that the models degenerate to the self-training ones. Besides, the multi-view inputs are generated by perturbing or augmenting the original images, which inevitably introduces noise into the input leading to low-confidence pseudo labels. To address these issues, we propose an \textbf{U}ncertainty-guided Collaborative Mean-Teacher (UCMT) for semi-supervised semantic segmentation with the high-confidence pseudo labels. Concretely, UCMT consists of two main components: 1) collaborative mean-teacher (CMT) for encouraging model disagreement and performing co-training between the sub-networks, and 2) uncertainty-guided region mix (UMIX) for manipulating the input images according to the uncertainty maps of CMT and facilitating CMT to produce high-confidence pseudo labels. Combining the strengths of UMIX with CMT, UCMT can retain model disagreement and enhance the quality of pseudo labels for the co-training segmentation. Extensive experiments on four public medical image datasets including 2D and 3D modalities demonstrate the superiority of UCMT over the state-of-the-art. Code is available at: https://github.com/Senyh/UCMT.
Mimic before Reconstruct: Enhancing Masked Autoencoders with Feature Mimicking
Mar 09, 2023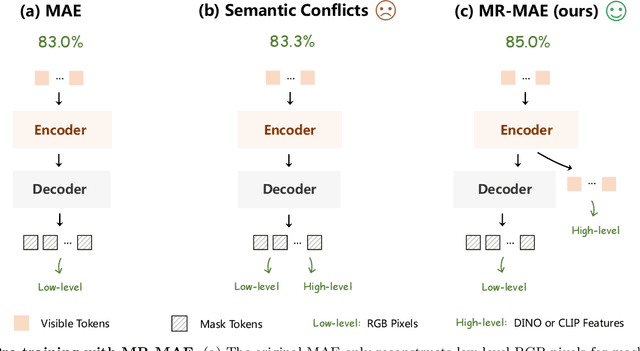
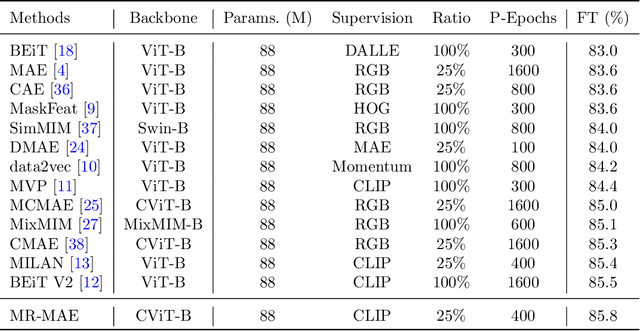
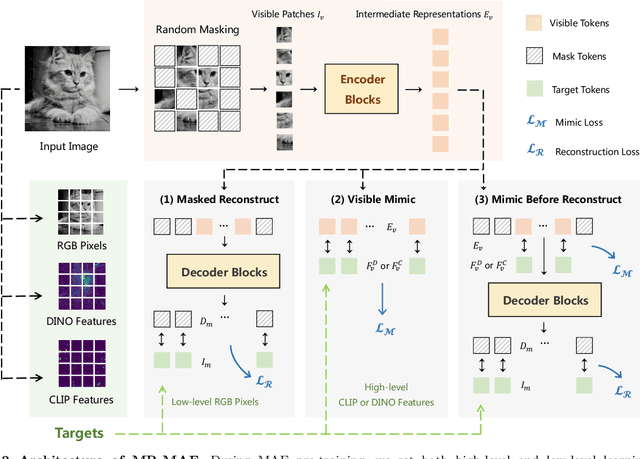
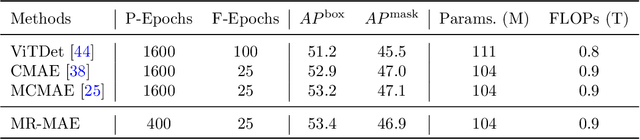
Masked Autoencoders (MAE) have been popular paradigms for large-scale vision representation pre-training. However, MAE solely reconstructs the low-level RGB signals after the decoder and lacks supervision upon high-level semantics for the encoder, thus suffering from sub-optimal learned representations and long pre-training epochs. To alleviate this, previous methods simply replace the pixel reconstruction targets of 75% masked tokens by encoded features from pre-trained image-image (DINO) or image-language (CLIP) contrastive learning. Different from those efforts, we propose to Mimic before Reconstruct for Masked Autoencoders, named as MR-MAE, which jointly learns high-level and low-level representations without interference during pre-training. For high-level semantics, MR-MAE employs a mimic loss over 25% visible tokens from the encoder to capture the pre-trained patterns encoded in CLIP and DINO. For low-level structures, we inherit the reconstruction loss in MAE to predict RGB pixel values for 75% masked tokens after the decoder. As MR-MAE applies high-level and low-level targets respectively at different partitions, the learning conflicts between them can be naturally overcome and contribute to superior visual representations for various downstream tasks. On ImageNet-1K, the MR-MAE base pre-trained for only 400 epochs achieves 85.8% top-1 accuracy after fine-tuning, surpassing the 1600-epoch MAE base by +2.2% and the previous state-of-the-art BEiT V2 base by +0.3%. Code and pre-trained models will be released at https://github.com/Alpha-VL/ConvMAE.
Memotion 3: Dataset on Sentiment and Emotion Analysis of Codemixed Hindi-English Memes
Mar 23, 2023
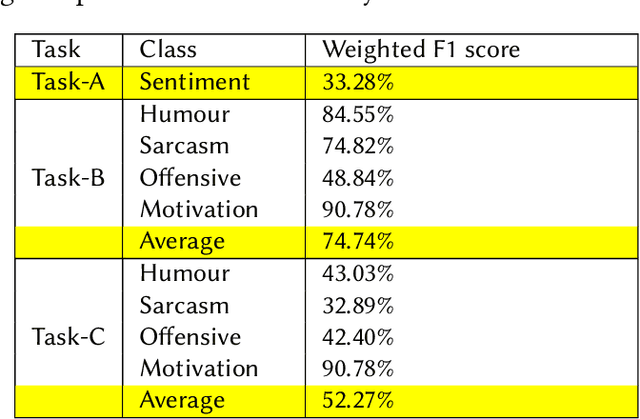


Memes are the new-age conveyance mechanism for humor on social media sites. Memes often include an image and some text. Memes can be used to promote disinformation or hatred, thus it is crucial to investigate in details. We introduce Memotion 3, a new dataset with 10,000 annotated memes. Unlike other prevalent datasets in the domain, including prior iterations of Memotion, Memotion 3 introduces Hindi-English Codemixed memes while prior works in the area were limited to only the English memes. We describe the Memotion task, the data collection and the dataset creation methodologies. We also provide a baseline for the task. The baseline code and dataset will be made available at https://github.com/Shreyashm16/Memotion-3.0
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing
Mar 17, 2023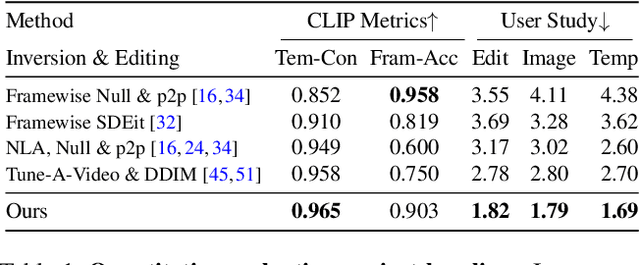
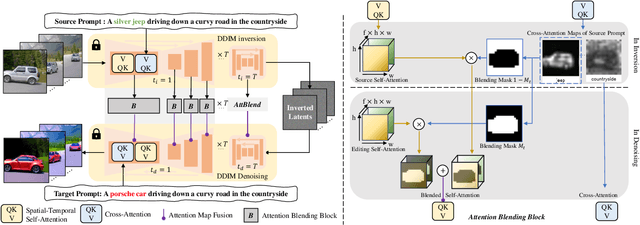
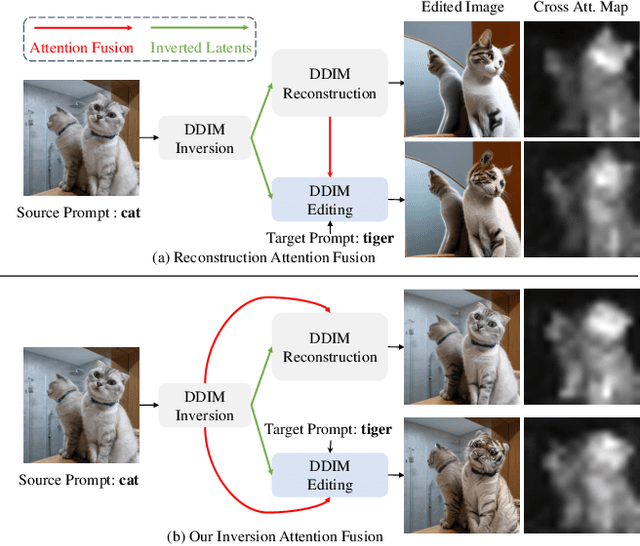

The diffusion-based generative models have achieved remarkable success in text-based image generation. However, since it contains enormous randomness in generation progress, it is still challenging to apply such models for real-world visual content editing, especially in videos. In this paper, we propose FateZero, a zero-shot text-based editing method on real-world videos without per-prompt training or use-specific mask. To edit videos consistently, we propose several techniques based on the pre-trained models. Firstly, in contrast to the straightforward DDIM inversion technique, our approach captures intermediate attention maps during inversion, which effectively retain both structural and motion information. These maps are directly fused in the editing process rather than generated during denoising. To further minimize semantic leakage of the source video, we then fuse self-attentions with a blending mask obtained by cross-attention features from the source prompt. Furthermore, we have implemented a reform of the self-attention mechanism in denoising UNet by introducing spatial-temporal attention to ensure frame consistency. Yet succinct, our method is the first one to show the ability of zero-shot text-driven video style and local attribute editing from the trained text-to-image model. We also have a better zero-shot shape-aware editing ability based on the text-to-video model. Extensive experiments demonstrate our superior temporal consistency and editing capability than previous works.
Homogenizing Non-IID datasets via In-Distribution Knowledge Distillation for Decentralized Learning
Apr 09, 2023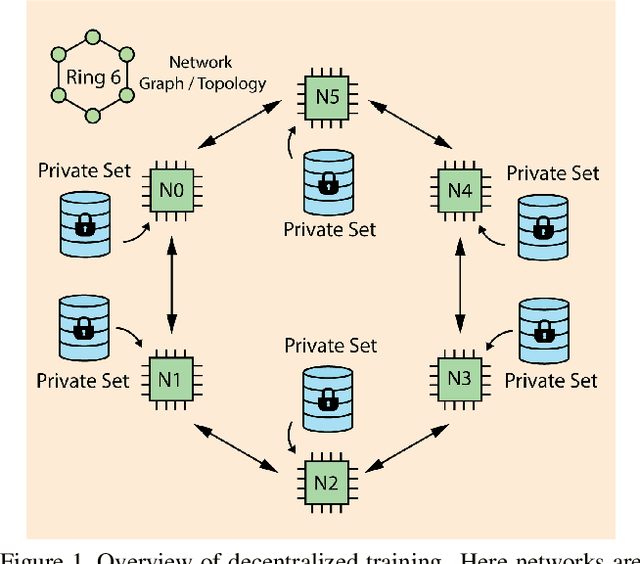
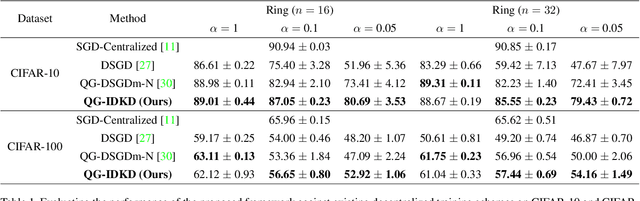
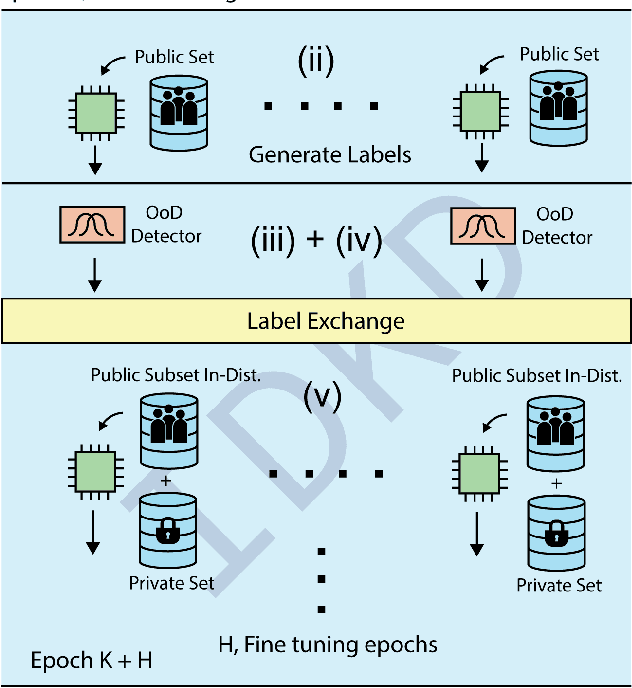
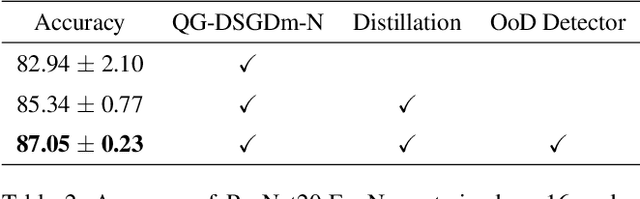
Decentralized learning enables serverless training of deep neural networks (DNNs) in a distributed manner on multiple nodes. This allows for the use of large datasets, as well as the ability to train with a wide variety of data sources. However, one of the key challenges with decentralized learning is heterogeneity in the data distribution across the nodes. In this paper, we propose In-Distribution Knowledge Distillation (IDKD) to address the challenge of heterogeneous data distribution. The goal of IDKD is to homogenize the data distribution across the nodes. While such data homogenization can be achieved by exchanging data among the nodes sacrificing privacy, IDKD achieves the same objective using a common public dataset across nodes without breaking the privacy constraint. This public dataset is different from the training dataset and is used to distill the knowledge from each node and communicate it to its neighbors through the generated labels. With traditional knowledge distillation, the generalization of the distilled model is reduced because all the public dataset samples are used irrespective of their similarity to the local dataset. Thus, we introduce an Out-of-Distribution (OoD) detector at each node to label a subset of the public dataset that maps close to the local training data distribution. Finally, only labels corresponding to these subsets are exchanged among the nodes and with appropriate label averaging each node is finetuned on these data subsets along with its local data. Our experiments on multiple image classification datasets and graph topologies show that the proposed IDKD scheme is more effective than traditional knowledge distillation and achieves state-of-the-art generalization performance on heterogeneously distributed data with minimal communication overhead.