 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALON: Token-Aligned Lightweight Adapters for 6-DoF Spacecraft Pose Estimation
May 29, 2026Monocular 6-DoF spacecraft pose estimation methods predominantly process individual frames, discarding the temporal information present in an image sequence acquired during spacecraft manoeuvres. Few temporal approaches require full backbone fine-tuning or auxiliary optical flow networks, risking catastrophic forgetting or increasing computational cost, respectively. We propose TALON (Token-Aligned Lightweight adapters for Orbital Navigation): spatiotemporal 3D adapters injected before the self-attention layers of a frozen ViT vision transformer, combined with a patch-token alignment loss that geometrically grounds the adapted features to keypoint structure through a prototype-conditioned KL-divergence objective. Pre-attention placement allows the frozen attention to reason over temporally enriched tokens, achieving stronger performance with a single adapter per block than post-attention alternatives. The alignment loss shapes the intermediate representations so that each keypoint induces a spatially precise activation in the token field, while the framework adds less than 5% parameters to the frozen backbone. On SPADES dataset, TALON reduces the pose error by 50% over the prior state-of-the-art, and on SwissCube dataset it surpasses the prior best by 21.8% in ADD-0.1d accuracy. Zero-shot cross-domain evaluation from sim-to-real on SPARK real data reduces pose error by 4.7x, and ablations characterise the role of adapter depth across in-domain and cross-domain settings.
ASTER: Latent Pseudo-Anomaly Generation for Unsupervised Time-Series Anomaly Detection
Apr 15, 2026Time-series anomaly detection (TSAD) is critical in domains such as industrial monitoring, healthcare, and cybersecurity, but it remains challenging due to rare and heterogeneous anomalies and the scarcity of labelled data. This scarcity makes unsupervised approaches predominant, yet existing methods often rely on reconstruction or forecasting, which struggle with complex data, or on embedding-based approaches that require domain-specific anomaly synthesis and fixed distance metrics. We propose ASTER, a framework that generates pseudo-anomalies directly in the latent space, avoiding handcrafted anomaly injections and the need for domain expertise. A latent-space decoder produces tailored pseudo-anomalies to train a Transformer-based anomaly classifier, while a pre-trained LLM enriches the temporal and contextual representations of this space. Experiments on three benchmark datasets show that ASTER achieves state-of-the-art performance and sets a new standard for LLM-based TSAD.
Efficient Onboard Spacecraft Pose Estimation with Event Cameras and Neuromorphic Hardware
Apr 05, 2026Reliable relative pose estimation is a key enabler for autonomous rendezvous and proximity operations, yet space imagery is notoriously challenging due to extreme illumination, high contrast, and fast target motion. Event cameras provide asynchronous, change-driven measurements that can remain informative when frame-based imagery saturates or blurs, while neuromorphic processors can exploit sparse activations for low-latency, energy-efficient inferences. This paper presents a spacecraft 6-DoF pose-estimation pipeline that couples event-based vision with the BrainChip Akida neuromorphic processor. Using the SPADES dataset, we train compact MobileNet-style keypoint regression networks on lightweight event-frame representations, apply quantization-aware training (8/4-bit), and convert the models to Akida-compatible spiking neural networks. We benchmark three event representations and demonstrate real-time, low-power inference on Akida V1 hardware. We additionally design a heatmap-based model targeting Akida V2 and evaluate it on Akida Cloud, yielding improved pose accuracy. To our knowledge, this is the first end-to-end demonstration of spacecraft pose estimation running on Akida hardware, highlighting a practical route to low-latency, low-power perception for future autonomous space missions.
LAA-X: Unified Localized Artifact Attention for Quality-Agnostic and Generalizable Face Forgery Detection
Apr 05, 2026In this paper, we propose Localized Artifact Attention X (LAA-X), a novel deepfake detection framework that is both robust to high-quality forgeries and capable of generalizing to unseen manipulations. Existing approaches typically rely on binary classifiers coupled with implicit attention mechanisms, which often fail to generalize beyond known manipulations. In contrast, LAA-X introduces an explicit attention strategy based on a multi-task learning framework combined with blending-based data synthesis. Auxiliary tasks are designed to guide the model toward localized, artifact-prone (i.e., vulnerable) regions. The proposed framework is compatible with both CNN and transformer backbones, resulting in two different versions, namely, LAA-Net and LAA-Former, respectively. Despite being trained only on real and pseudo-fake samples, LAA-X competes with state-of-the-art methods across multiple benchmarks. Code and pre-trained weights for LAA-Net\footnote{https://github.com/10Ring/LAA-Net} and LAA-Former\footnote{https://github.com/10Ring/LAA-Former} are publicly available.
Cov2Pose: Leveraging Spatial Covariance for Direct Manifold-aware 6-DoF Object Pose Estimation
Mar 20, 2026In this paper, we address the problem of 6-DoF object pose estimation from a single RGB image. Indirect methods that typically predict intermediate 2D keypoints, followed by a Perspective-n-Point solver, have shown great performance. Direct approaches, which regress the pose in an end-to-end manner, are usually computationally more efficient but less accurate. However, direct heads rely on globally pooled features, ignoring spatial second-order statistics despite their informativeness in pose prediction. They also predict, in most cases, discontinuous pose representations that lack robustness. Herein, we therefore propose a covariance-pooled representation that encodes convolutional feature distributions as a symmetric positive definite (SPD) matrix. Moreover, we propose a novel pose encoding in the form of an SPD matrix via its Cholesky decomposition. Pose is then regressed in an end-to-end manner with a manifold-aware network head, taking into account the Riemannian geometry of SPD matrices. Experiments and ablations consistently demonstrate the relevance of second-order pooling and continuous representations for direct pose regression, including under partial occlusion.
Annotation Free Spacecraft Detection and Segmentation using Vision Language Models
Feb 04, 2026Vision Language Models (VLMs) have demonstrated remarkable performance in open-world zero-shot visual recognition. However, their potential in space-related applications remains largely unexplored. In the space domain, accurate manual annotation is particularly challenging due to factors such as low visibility, illumination variations, and object blending with planetary backgrounds. Developing methods that can detect and segment spacecraft and orbital targets without requiring extensive manual labeling is therefore of critical importance. In this work, we propose an annotation-free detection and segmentation pipeline for space targets using VLMs. Our approach begins by automatically generating pseudo-labels for a small subset of unlabeled real data with a pre-trained VLM. These pseudo-labels are then leveraged in a teacher-student label distillation framework to train lightweight models. Despite the inherent noise in the pseudo-labels, the distillation process leads to substantial performance gains over direct zero-shot VLM inference. Experimental evaluations on the SPARK-2024, SPEED+, and TANGO datasets on segmentation tasks demonstrate consistent improvements in average precision (AP) by up to 10 points. Code and models are available at https://github.com/giddyyupp/annotation-free-spacecraft-segmentation.
Training Free Zero-Shot Visual Anomaly Localization via Diffusion Inversion
Jan 12, 2026Zero-Shot image Anomaly Detection (ZSAD) aims to detect and localise anomalies without access to any normal training samples of the target data. While recent ZSAD approaches leverage additional modalities such as language to generate fine-grained prompts for localisation, vision-only methods remain limited to image-level classification, lacking spatial precision. In this work, we introduce a simple yet effective training-free vision-only ZSAD framework that circumvents the need for fine-grained prompts by leveraging the inversion of a pretrained Denoising Diffusion Implicit Model (DDIM). Specifically, given an input image and a generic text description (e.g., "an image of an [object class]"), we invert the image to obtain latent representations and initiate the denoising process from a fixed intermediate timestep to reconstruct the image. Since the underlying diffusion model is trained solely on normal data, this process yields a normal-looking reconstruction. The discrepancy between the input image and the reconstructed one highlights potential anomalies. Our method achieves state-of-the-art performance on VISA dataset, demonstrating strong localisation capabilities without auxiliary modalities and facilitating a shift away from prompt dependence for zero-shot anomaly detection research. Code is available at https://github.com/giddyyupp/DIVAD.
VLMDiff: Leveraging Vision-Language Models for Multi-Class Anomaly Detection with Diffusion
Nov 11, 2025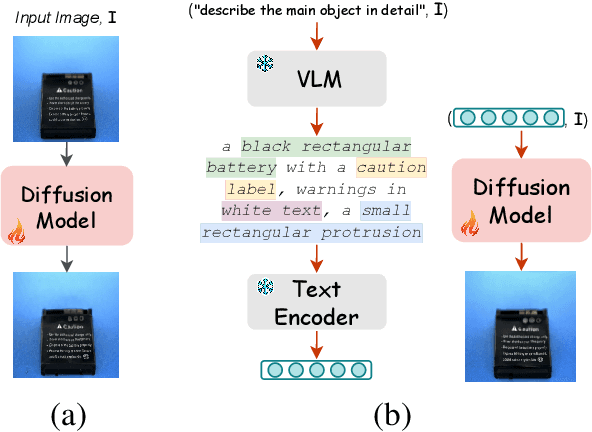



Detecting visual anomalies in diverse, multi-class real-world images is a significant challenge. We introduce \ours, a novel unsupervised multi-class visual anomaly detection framework. It integrates a Latent Diffusion Model (LDM) with a Vision-Language Model (VLM) for enhanced anomaly localization and detection. Specifically, a pre-trained VLM with a simple prompt extracts detailed image descriptions, serving as additional conditioning for LDM training. Current diffusion-based methods rely on synthetic noise generation, limiting their generalization and requiring per-class model training, which hinders scalability. \ours, however, leverages VLMs to obtain normal captions without manual annotations or additional training. These descriptions condition the diffusion model, learning a robust normal image feature representation for multi-class anomaly detection. Our method achieves competitive performance, improving the pixel-level Per-Region-Overlap (PRO) metric by up to 25 points on the Real-IAD dataset and 8 points on the COCO-AD dataset, outperforming state-of-the-art diffusion-based approaches. Code is available at https://github.com/giddyyupp/VLMDiff.
Zero-Shot Anomaly Detection in Battery Thermal Images Using Visual Question Answering with Prior Knowledge
May 22, 2025



Batteries are essential for various applications, including electric vehicles and renewable energy storage, making safety and efficiency critical concerns. Anomaly detection in battery thermal images helps identify failures early, but traditional deep learning methods require extensive labeled data, which is difficult to obtain, especially for anomalies due to safety risks and high data collection costs. To overcome this, we explore zero-shot anomaly detection using Visual Question Answering (VQA) models, which leverage pretrained knowledge and textbased prompts to generalize across vision tasks. By incorporating prior knowledge of normal battery thermal behavior, we design prompts to detect anomalies without battery-specific training data. We evaluate three VQA models (ChatGPT-4o, LLaVa-13b, and BLIP-2) analyzing their robustness to prompt variations, repeated trials, and qualitative outputs. Despite the lack of finetuning on battery data, our approach demonstrates competitive performance compared to state-of-the-art models that are trained with the battery data. Our findings highlight the potential of VQA-based zero-shot learning for battery anomaly detection and suggest future directions for improving its effectiveness.
Domain Adaptation for Multi-label Image Classification: a Discriminator-free Approach
May 20, 2025This paper introduces a discriminator-free adversarial-based approach termed DDA-MLIC for Unsupervised Domain Adaptation (UDA) in the context of Multi-Label Image Classification (MLIC). While recent efforts have explored adversarial-based UDA methods for MLIC, they typically include an additional discriminator subnet. Nevertheless, decoupling the classification and the discrimination tasks may harm their task-specific discriminative power. Herein, we address this challenge by presenting a novel adversarial critic directly derived from the task-specific classifier. Specifically, we employ a two-component Gaussian Mixture Model (GMM) to model both source and target predictions, distinguishing between two distinct clusters. Instead of using the traditional Expectation Maximization (EM) algorithm, our approach utilizes a Deep Neural Network (DNN) to estimate the parameters of each GMM component. Subsequently, the source and target GMM parameters are leveraged to formulate an adversarial loss using the Fr\'echet distance. The proposed framework is therefore not only fully differentiable but is also cost-effective as it avoids the expensive iterative process usually induced by the standard EM method. The proposed method is evaluated on several multi-label image datasets covering three different types of domain shift. The obtained results demonstrate that DDA-MLIC outperforms existing state-of-the-art methods in terms of precision while requiring a lower number of parameters. The code is made publicly available at github.com/cvi2snt/DDA-MLIC.