 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpretable by Design Visual Question Answering
May 24, 2023
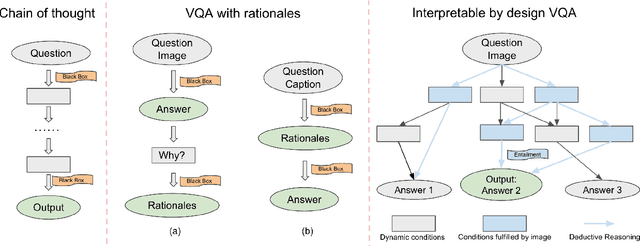
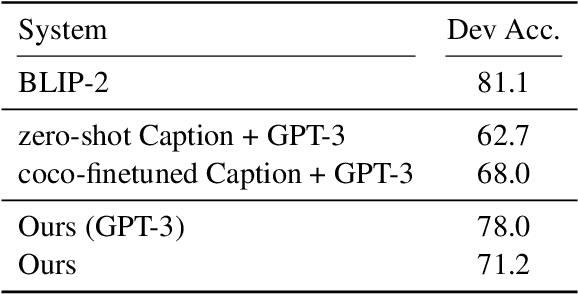
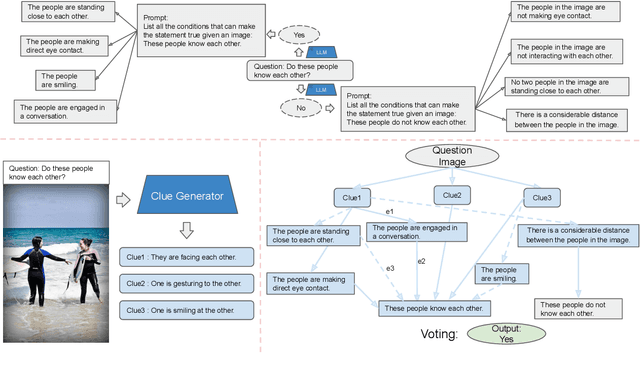
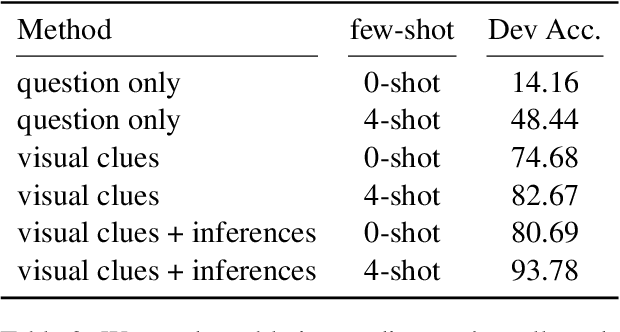
Model interpretability has long been a hard problem for the AI community especially in the multimodal setting, where vision and language need to be aligned and reasoned at the same time. In this paper, we specifically focus on the problem of Visual Question Answering (VQA). While previous researches try to probe into the network structures of black-box multimodal models, we propose to tackle the problem from a different angle -- to treat interpretability as an explicit additional goal. Given an image and question, we argue that an interpretable VQA model should be able to tell what conclusions it can get from which part of the image, and show how each statement help to arrive at an answer. We introduce InterVQA: Interpretable-by-design VQA, where we design an explicit intermediate dynamic reasoning structure for VQA problems and enforce symbolic reasoning that only use the structure for final answer prediction to take place. InterVQA produces high-quality explicit intermediate reasoning steps, while maintaining similar to the state-of-the-art (sota) end-task performance.
VisorGPT: Learning Visual Prior via Generative Pre-Training
May 24, 2023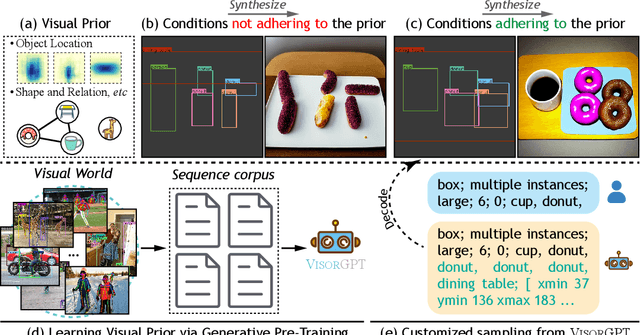
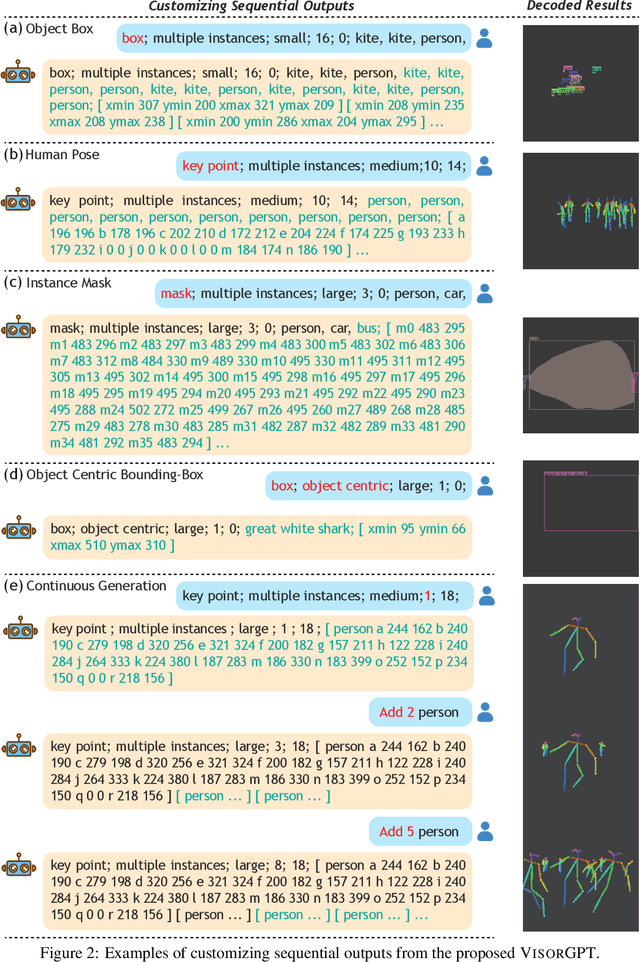

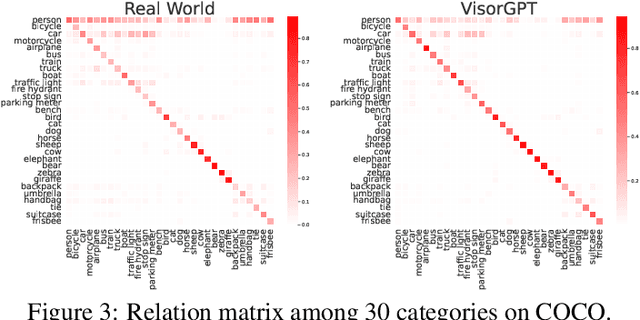
Various stuff and things in visual data possess specific traits, which can be learned by deep neural networks and are implicitly represented as the visual prior, \emph{e.g.,} object location and shape, in the model. Such prior potentially impacts many vision tasks. For example, in conditional image synthesis, spatial conditions failing to adhere to the prior can result in visually inaccurate synthetic results. This work aims to explicitly learn the visual prior and enable the customization of sampling. Inspired by advances in language modeling, we propose to learn Visual prior via Generative Pre-Training, dubbed VisorGPT. By discretizing visual locations of objects, \emph{e.g.,} bounding boxes, human pose, and instance masks, into sequences, \our~can model visual prior through likelihood maximization. Besides, prompt engineering is investigated to unify various visual locations and enable customized sampling of sequential outputs from the learned prior. Experimental results demonstrate that \our~can effectively model the visual prior, which can be employed for many vision tasks, such as customizing accurate human pose for conditional image synthesis models like ControlNet. Code will be released at https://github.com/Sierkinhane/VisorGPT.
HDR image watermarking using saliency detection and quantization index modulation
Feb 23, 2023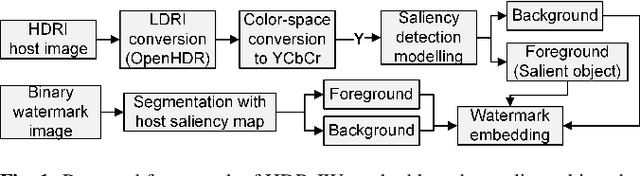
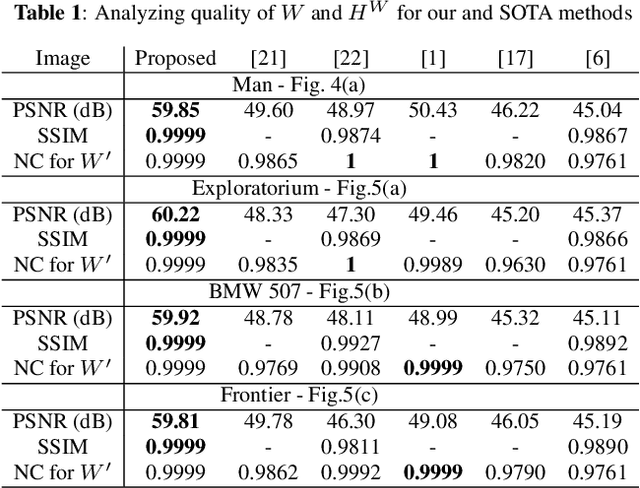
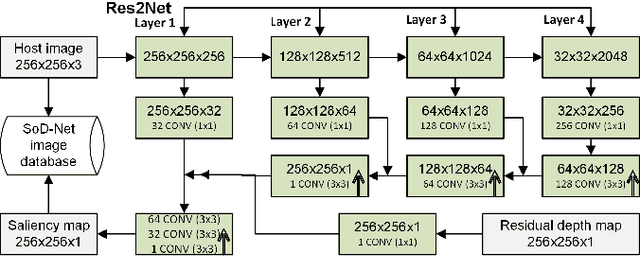

High-dynamic range (HDR) images are circulated rapidly over the internet with risks of being exploited for unauthorized usage. To protect these images, some HDR image based watermarking (HDR-IW) methods were put forward. However, they inherited the same problem faced by conventional IW methods for standard dynamic range (SDR) images, where only trade-offs among conflicting requirements are managed instead of simultaneous improvement. In this paper, a novel saliency (eye-catching object) detection based trade-off independent HDR-IW is proposed, to simultaneously improve robustness, imperceptibility and payload. First, the host image goes through our proposed salient object detection model to produce a saliency map, which is, in turn, exploited to segment the foreground and background of the host image. Next, the binary watermark is partitioned into the foregrounds and backgrounds using the same mask and scrambled using a random permutation algorithm. Finally, the watermark segments are embedded into selected bit-plane of the corresponding host segments using quantized indexed modulation. Experimental results suggest that the proposed work outperforms state-of-the-art methods in terms of improving the conflicting requirements.
Temporal Consistent Automatic Video Colorization via Semantic Correspondence
May 13, 2023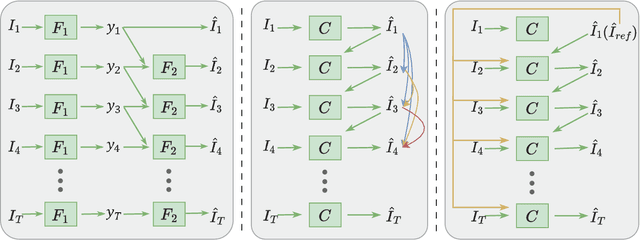
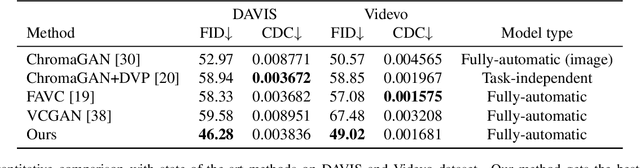
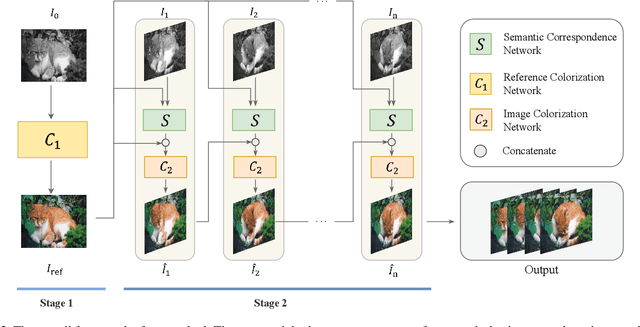
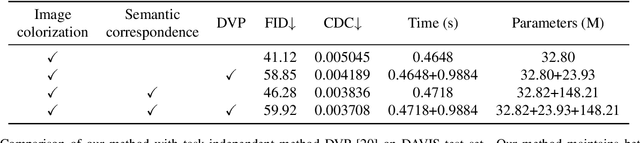
Video colorization task has recently attracted wide attention. Recent methods mainly work on the temporal consistency in adjacent frames or frames with small interval. However, it still faces severe challenge of the inconsistency between frames with large interval.To address this issue, we propose a novel video colorization framework, which combines semantic correspondence into automatic video colorization to keep long-range consistency. Firstly, a reference colorization network is designed to automatically colorize the first frame of each video, obtaining a reference image to supervise the following whole colorization process. Such automatically colorized reference image can not only avoid labor-intensive and time-consuming manual selection, but also enhance the similarity between reference and grayscale images. Afterwards, a semantic correspondence network and an image colorization network are introduced to colorize a series of the remaining frames with the help of the reference. Each frame is supervised by both the reference image and the immediately colorized preceding frame to improve both short-range and long-range temporal consistency. Extensive experiments demonstrate that our method outperforms other methods in maintaining temporal consistency both qualitatively and quantitatively. In the NTIRE 2023 Video Colorization Challenge, our method ranks at the 3rd place in Color Distribution Consistency (CDC) Optimization track.
Contrastive Learning for Predicting Cancer Prognosis Using Gene Expression Values
Jun 09, 2023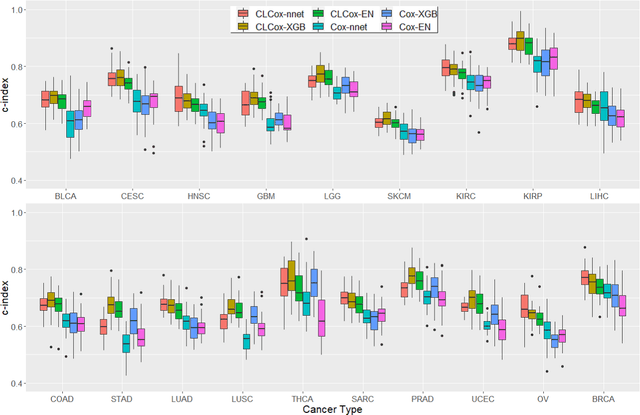
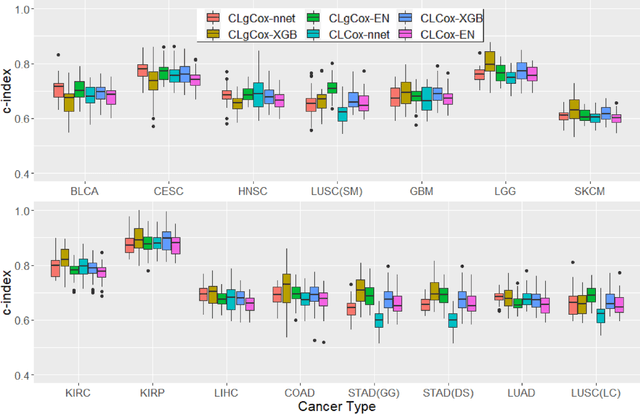
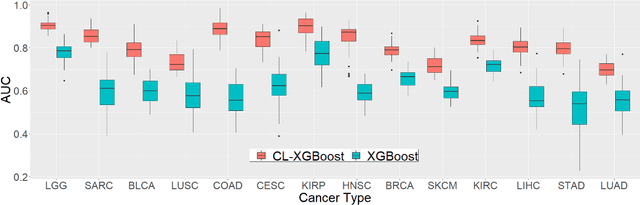
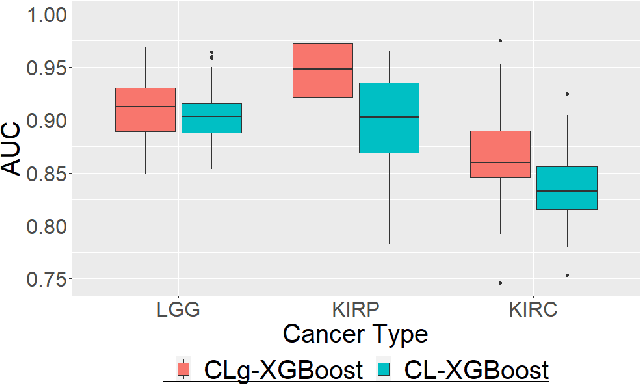
Several artificial neural networks (ANNs) have recently been developed as the Cox proportional hazard model for predicting cancer prognosis based on tumor transcriptome. However, they have not demonstrated significantly better performance than the traditional Cox regression with regularization. Training an ANN with high prediction power is challenging in the presence of a limited number of data samples and a high-dimensional feature space. Recent advancements in image classification have shown that contrastive learning can facilitate further learning tasks by learning good feature representation from a limited number of data samples. In this paper, we applied supervised contrastive learning to tumor gene expression and clinical data to learn feature representations in a low-dimensional space. We then used these learned features to train the Cox model for predicting cancer prognosis. Using data from The Cancer Genome Atlas (TCGA), we demonstrated that our contrastive learning-based Cox model (CLCox) significantly outperformed existing methods in predicting the prognosis of 18 types of cancer under consideration. We also developed contrastive learning-based classifiers to classify tumors into different risk groups and showed that contrastive learning can significantly improve classification accuracy.
COMCAT: Towards Efficient Compression and Customization of Attention-Based Vision Models
Jun 09, 2023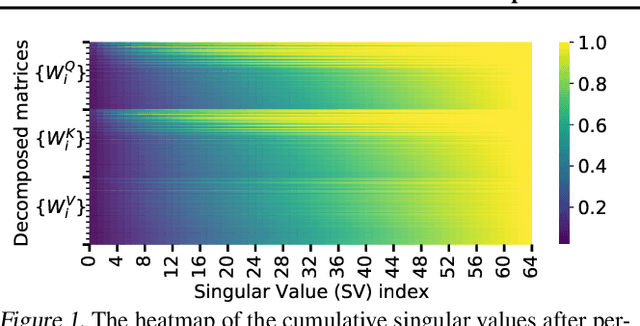
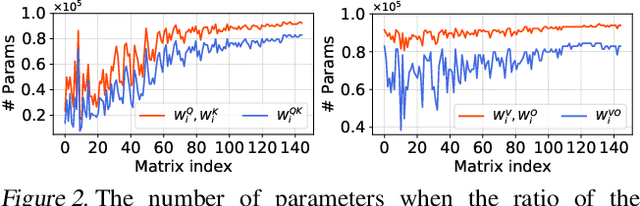
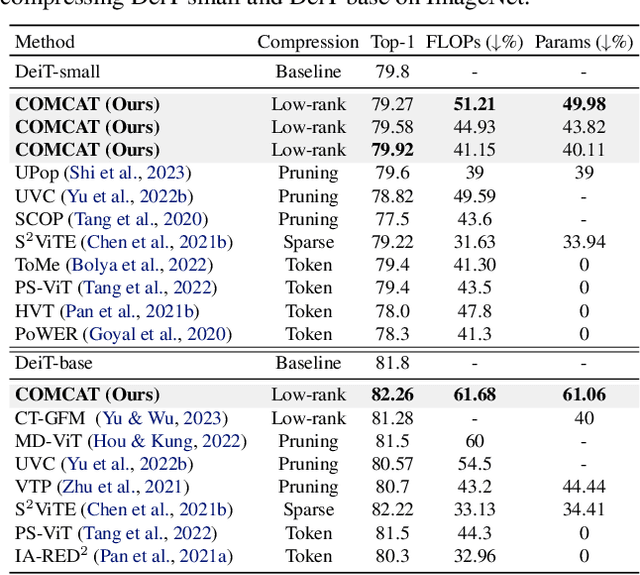
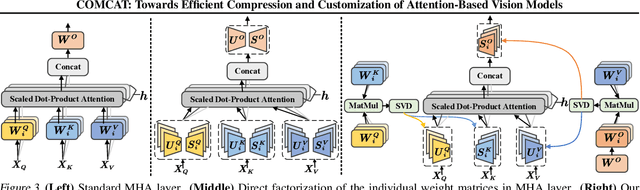
Attention-based vision models, such as Vision Transformer (ViT) and its variants, have shown promising performance in various computer vision tasks. However, these emerging architectures suffer from large model sizes and high computational costs, calling for efficient model compression solutions. To date, pruning ViTs has been well studied, while other compression strategies that have been widely applied in CNN compression, e.g., model factorization, is little explored in the context of ViT compression. This paper explores an efficient method for compressing vision transformers to enrich the toolset for obtaining compact attention-based vision models. Based on the new insight on the multi-head attention layer, we develop a highly efficient ViT compression solution, which outperforms the state-of-the-art pruning methods. For compressing DeiT-small and DeiT-base models on ImageNet, our proposed approach can achieve 0.45% and 0.76% higher top-1 accuracy even with fewer parameters. Our finding can also be applied to improve the customization efficiency of text-to-image diffusion models, with much faster training (up to $2.6\times$ speedup) and lower extra storage cost (up to $1927.5\times$ reduction) than the existing works.
GEO-Bench: Toward Foundation Models for Earth Monitoring
Jun 06, 2023
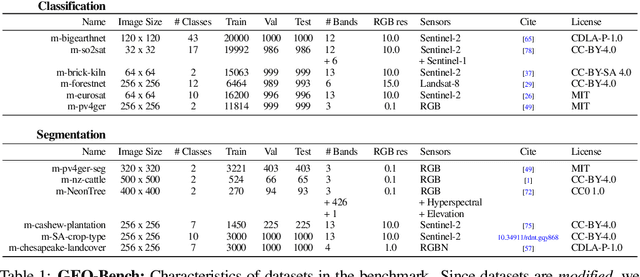

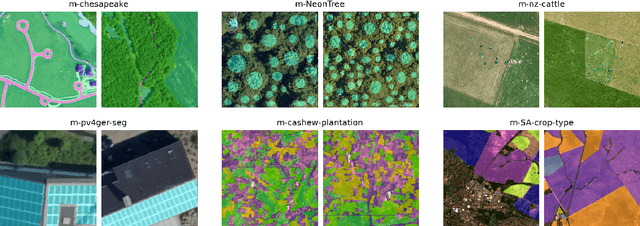
Recent progress in self-supervision has shown that pre-training large neural networks on vast amounts of unsupervised data can lead to substantial increases in generalization to downstream tasks. Such models, recently coined foundation models, have been transformational to the field of natural language processing. Variants have also been proposed for image data, but their applicability to remote sensing tasks is limited. To stimulate the development of foundation models for Earth monitoring, we propose a benchmark comprised of six classification and six segmentation tasks, which were carefully curated and adapted to be both relevant to the field and well-suited for model evaluation. We accompany this benchmark with a robust methodology for evaluating models and reporting aggregated results to enable a reliable assessment of progress. Finally, we report results for 20 baselines to gain information about the performance of existing models. We believe that this benchmark will be a driver of progress across a variety of Earth monitoring tasks.
An Approach to Solving the Abstraction and Reasoning Corpus (ARC) Challenge
Jun 06, 2023

We utilise the power of Large Language Models (LLMs), in particular GPT4, to be prompt engineered into performing an arbitrary task. Here, we give the model some human priors via text, along with some typical procedures for solving the ARC tasks, and ask it to generate the i) broad description of the input-output relation, ii) detailed steps of the input-output mapping, iii) use the detailed steps to perform manipulation on the test input and derive the test output. The current GPT3.5/GPT4 prompt solves 2 out of 4 tested small ARC challenges (those with small grids of 8x8 and below). With tweaks to the prompt to make it more specific for the use case, it can solve more. We posit that when scaled to a multi-agent system with usage of past memory and equipped with an image interpretation tool via Visual Question Answering, we may actually be able to solve the majority of the ARC challenge
Learning Human Mesh Recovery in 3D Scenes
Jun 06, 2023
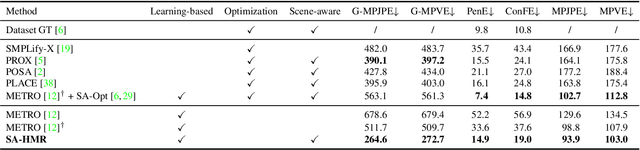
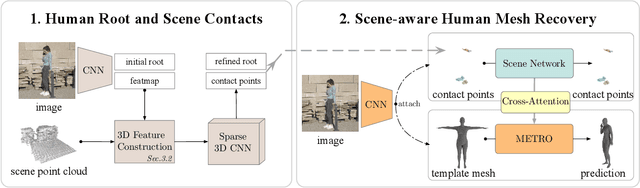
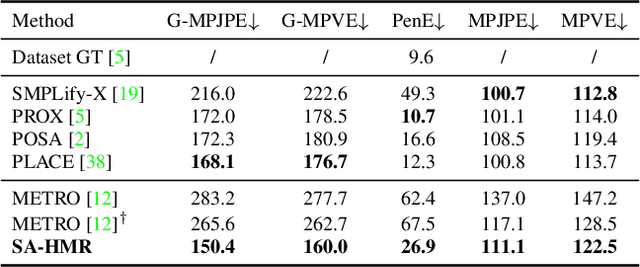
We present a novel method for recovering the absolute pose and shape of a human in a pre-scanned scene given a single image. Unlike previous methods that perform sceneaware mesh optimization, we propose to first estimate absolute position and dense scene contacts with a sparse 3D CNN, and later enhance a pretrained human mesh recovery network by cross-attention with the derived 3D scene cues. Joint learning on images and scene geometry enables our method to reduce the ambiguity caused by depth and occlusion, resulting in more reasonable global postures and contacts. Encoding scene-aware cues in the network also allows the proposed method to be optimization-free, and opens up the opportunity for real-time applications. The experiments show that the proposed network is capable of recovering accurate and physically-plausible meshes by a single forward pass and outperforms state-of-the-art methods in terms of both accuracy and speed.
Manipulating Visually-aware Federated Recommender Systems and Its Countermeasures
May 16, 2023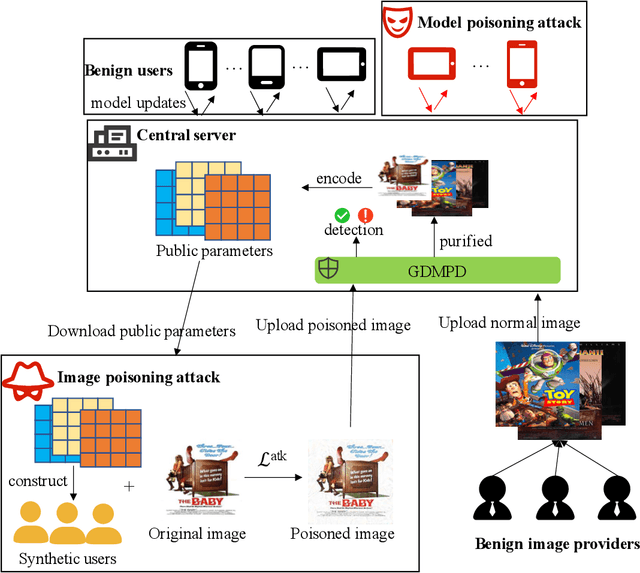

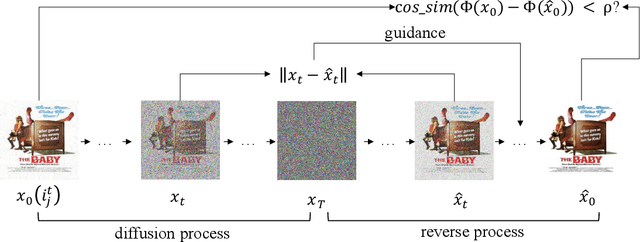

Federated recommender systems (FedRecs) have been widely explored recently due to their ability to protect user data privacy. In FedRecs, a central server collaboratively learns recommendation models by sharing model public parameters with clients, thereby offering a privacy-preserving solution. Unfortunately, the exposure of model parameters leaves a backdoor for adversaries to manipulate FedRecs. Existing works about FedRec security already reveal that items can easily be promoted by malicious users via model poisoning attacks, but all of them mainly focus on FedRecs with only collaborative information (i.e., user-item interactions). We argue that these attacks are effective because of the data sparsity of collaborative signals. In practice, auxiliary information, such as products' visual descriptions, is used to alleviate collaborative filtering data's sparsity. Therefore, when incorporating visual information in FedRecs, all existing model poisoning attacks' effectiveness becomes questionable. In this paper, we conduct extensive experiments to verify that incorporating visual information can beat existing state-of-the-art attacks in reasonable settings. However, since visual information is usually provided by external sources, simply including it will create new security problems. Specifically, we propose a new kind of poisoning attack for visually-aware FedRecs, namely image poisoning attacks, where adversaries can gradually modify the uploaded image to manipulate item ranks during FedRecs' training process. Furthermore, we reveal that the potential collaboration between image poisoning attacks and model poisoning attacks will make visually-aware FedRecs more vulnerable to being manipulated. To safely use visual information, we employ a diffusion model in visually-aware FedRecs to purify each uploaded image and detect the adversarial images.