 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recyclable Semi-supervised Method Based on Multi-model Ensemble for Video Scene Parsing
Jun 05, 2023
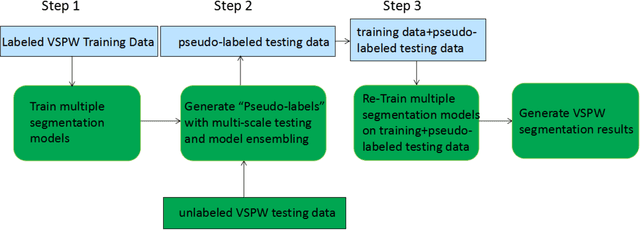

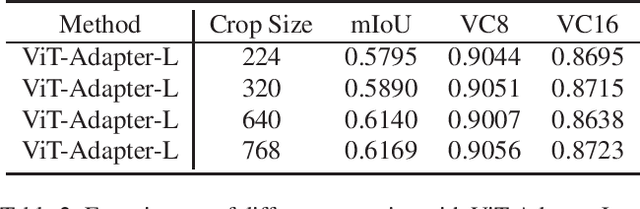

Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Since the real-world is actually video-based rather than a static state, learning to perform video semantic segmentation is more reasonable and practical for realistic applications. In this paper, we adopt Mask2Former as architecture and ViT-Adapter as backbone. Then, we propose a recyclable semi-supervised training method based on multi-model ensemble. Our method achieves the mIoU scores of 62.97% and 65.83% on Development test and final test respectively. Finally, we obtain the 2nd place in the Video Scene Parsing in the Wild Challenge at CVPR 2023.
LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark
Jun 11, 2023
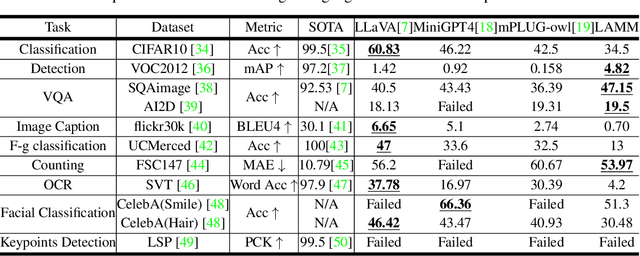
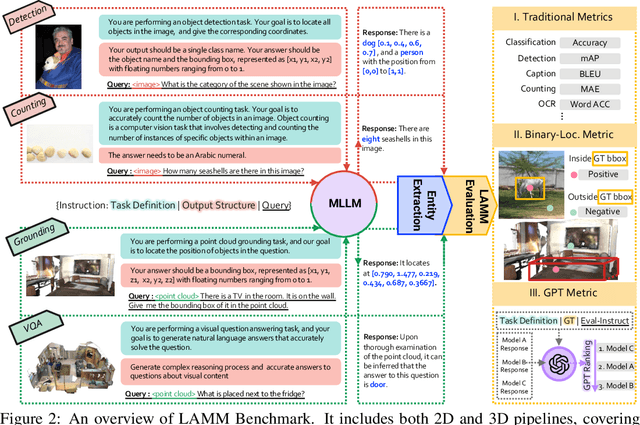
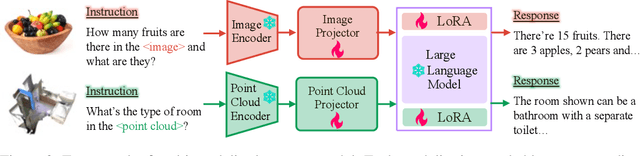
Large language models have become a potential pathway toward achieving artificial general intelligence. Recent works on multi-modal large language models have demonstrated their effectiveness in handling visual modalities. In this work, we extend the research of MLLMs to point clouds and present the LAMM-Dataset and LAMM-Benchmark for 2D image and 3D point cloud understanding. We also establish an extensible framework to facilitate the extension of MLLMs to additional modalities. Our main contribution is three-fold: 1) We present the LAMM-Dataset and LAMM-Benchmark, which cover almost all high-level vision tasks for 2D and 3D vision. Extensive experiments validate the effectiveness of our dataset and benchmark. 2) We demonstrate the detailed methods of constructing instruction-tuning datasets and benchmarks for MLLMs, which will enable future research on MLLMs to scale up and extend to other domains, tasks, and modalities faster. 3) We provide a primary but potential MLLM training framework optimized for modalities' extension. We also provide baseline models, comprehensive experimental observations, and analysis to accelerate future research.
3rd Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation
Jun 11, 2023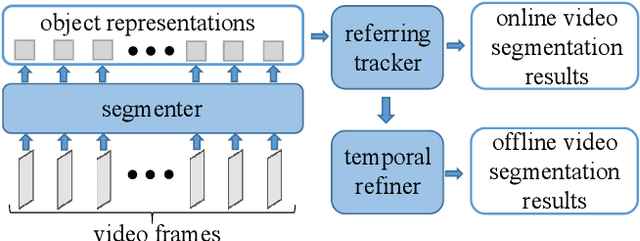
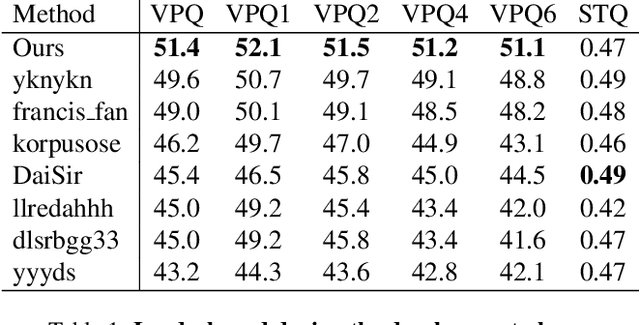
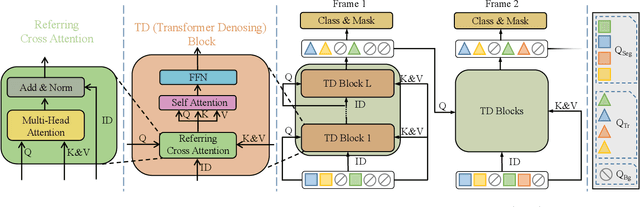
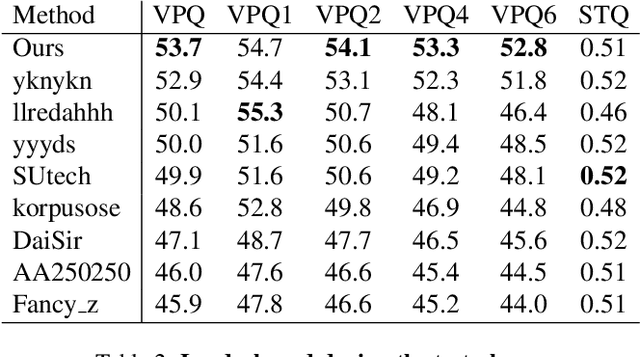
In order to deal with the task of video panoptic segmentation in the wild, we propose a robust integrated video panoptic segmentation solution. In our solution, we regard the video panoptic segmentation task as a segmentation target querying task, represent both semantic and instance targets as a set of queries, and then combine these queries with video features extracted by neural networks to predict segmentation masks. In order to improve the learning accuracy and convergence speed of the solution, we add additional tasks of video semantic segmentation and video instance segmentation for joint training. In addition, we also add an additional image semantic segmentation model to further improve the performance of semantic classes. In addition, we also add some additional operations to improve the robustness of the model. Extensive experiments on the VIPSeg dataset show that the proposed solution achieves state-of-the-art performance with 50.04\% VPQ on the VIPSeg test set, which is 3rd place on the video panoptic segmentation track of the PVUW Challenge 2023.
On the Efficacy of 3D Point Cloud Reinforcement Learning
Jun 11, 2023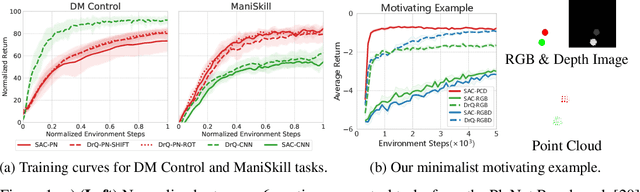
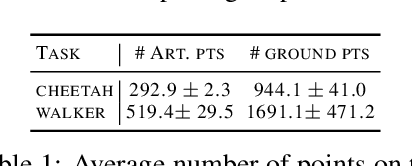


Recent studies on visual reinforcement learning (visual RL) have explored the use of 3D visual representations. However, none of these work has systematically compared the efficacy of 3D representations with 2D representations across different tasks, nor have they analyzed 3D representations from the perspective of agent-object / object-object relationship reasoning. In this work, we seek answers to the question of when and how do 3D neural networks that learn features in the 3D-native space provide a beneficial inductive bias for visual RL. We specifically focus on 3D point clouds, one of the most common forms of 3D representations. We systematically investigate design choices for 3D point cloud RL, leading to the development of a robust algorithm for various robotic manipulation and control tasks. Furthermore, through comparisons between 2D image vs 3D point cloud RL methods on both minimalist synthetic tasks and complex robotic manipulation tasks, we find that 3D point cloud RL can significantly outperform the 2D counterpart when agent-object / object-object relationship encoding is a key factor.
Designing an Encoder for Fast Personalization of Text-to-Image Models
Feb 26, 2023
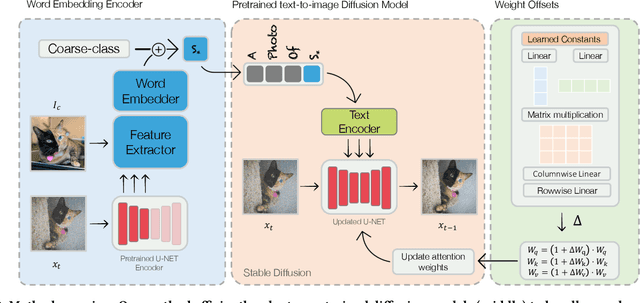

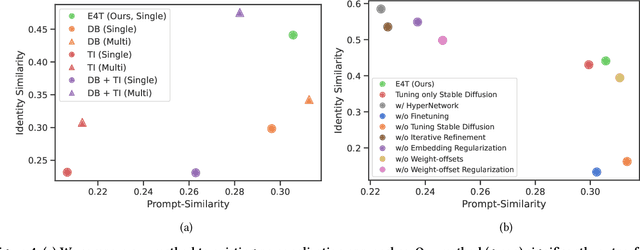
Text-to-image personalization aims to teach a pre-trained diffusion model to reason about novel, user provided concepts, embedding them into new scenes guided by natural language prompts. However, current personalization approaches struggle with lengthy training times, high storage requirements or loss of identity. To overcome these limitations, we propose an encoder-based domain-tuning approach. Our key insight is that by underfitting on a large set of concepts from a given domain, we can improve generalization and create a model that is more amenable to quickly adding novel concepts from the same domain. Specifically, we employ two components: First, an encoder that takes as an input a single image of a target concept from a given domain, e.g. a specific face, and learns to map it into a word-embedding representing the concept. Second, a set of regularized weight-offsets for the text-to-image model that learn how to effectively ingest additional concepts. Together, these components are used to guide the learning of unseen concepts, allowing us to personalize a model using only a single image and as few as 5 training steps - accelerating personalization from dozens of minutes to seconds, while preserving quality.
Align, Perturb and Decouple: Toward Better Leverage of Difference Information for RSI Change Detection
May 30, 2023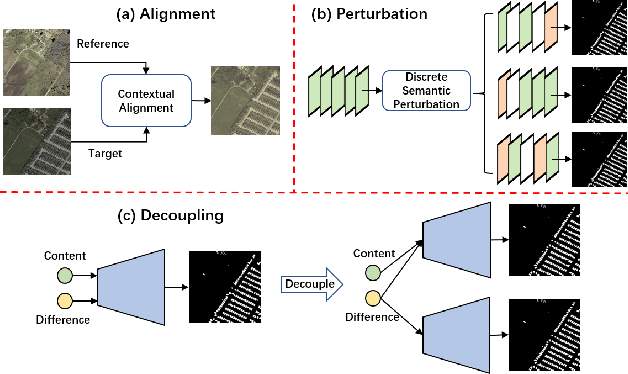
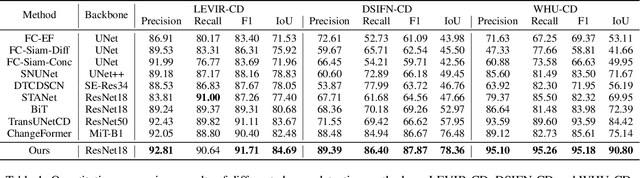
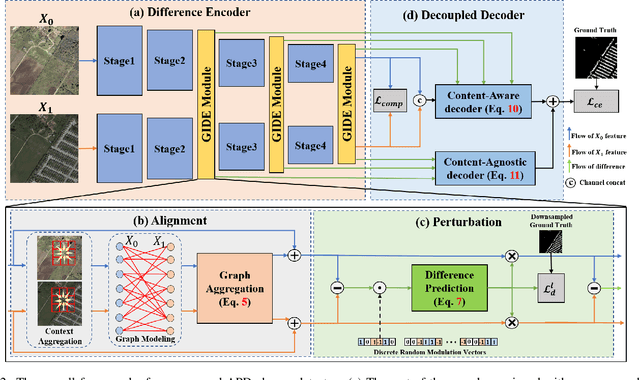
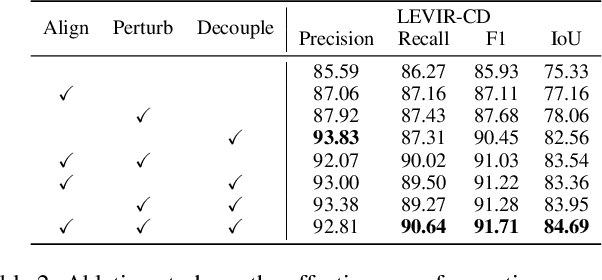
Change detection is a widely adopted technique in remote sense imagery (RSI) analysis in the discovery of long-term geomorphic evolution. To highlight the areas of semantic changes, previous effort mostly pays attention to learning representative feature descriptors of a single image, while the difference information is either modeled with simple difference operations or implicitly embedded via feature interactions. Nevertheless, such difference modeling can be noisy since it suffers from non-semantic changes and lacks explicit guidance from image content or context. In this paper, we revisit the importance of feature difference for change detection in RSI, and propose a series of operations to fully exploit the difference information: Alignment, Perturbation and Decoupling (APD). Firstly, alignment leverages contextual similarity to compensate for the non-semantic difference in feature space. Next, a difference module trained with semantic-wise perturbation is adopted to learn more generalized change estimators, which reversely bootstraps feature extraction and prediction. Finally, a decoupled dual-decoder structure is designed to predict semantic changes in both content-aware and content-agnostic manners. Extensive experiments are conducted on benchmarks of LEVIR-CD, WHU-CD and DSIFN-CD, demonstrating our proposed operations bring significant improvement and achieve competitive results under similar comparative conditions. Code is available at https://github.com/wangsp1999/CD-Research/tree/main/openAPD
Fine-Grained is Too Coarse: A Novel Data-Centric Approach for Efficient Scene Graph Generation
May 30, 2023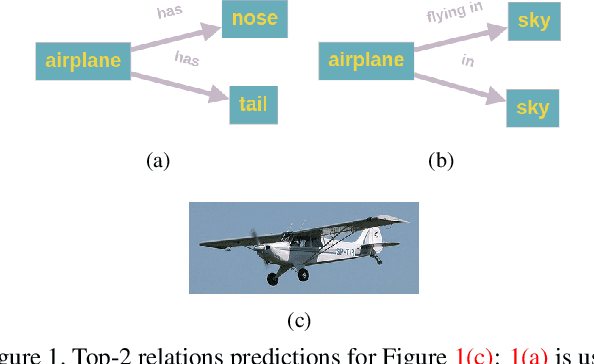
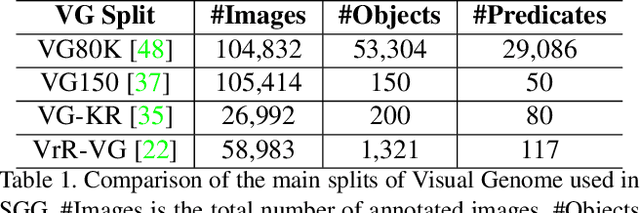
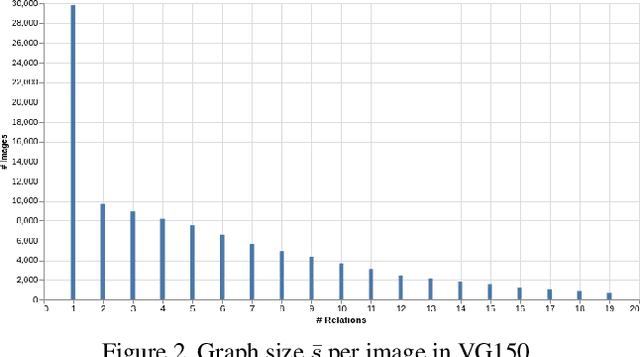
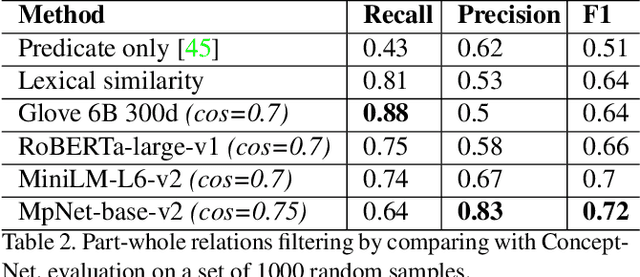
Learning to compose visual relationships from raw images in the form of scene graphs is a highly challenging task due to contextual dependencies, but it is essential in computer vision applications that depend on scene understanding. However, no current approaches in Scene Graph Generation (SGG) aim at providing useful graphs for downstream tasks. Instead, the main focus has primarily been on the task of unbiasing the data distribution for predicting more fine-grained relations. That being said, all fine-grained relations are not equally relevant and at least a part of them are of no use for real-world applications. In this work, we introduce the task of Efficient SGG that prioritizes the generation of relevant relations, facilitating the use of Scene Graphs in downstream tasks such as Image Generation. To support further approaches in this task, we present a new dataset, VG150-curated, based on the annotations of the popular Visual Genome dataset. We show through a set of experiments that this dataset contains more high-quality and diverse annotations than the one usually adopted by approaches in SGG. Finally, we show the efficiency of this dataset in the task of Image Generation from Scene Graphs. Our approach can be easily replicated to improve the quality of other Scene Graph Generation datasets.
Masked Collaborative Contrast for Weakly Supervised Semantic Segmentation
May 15, 2023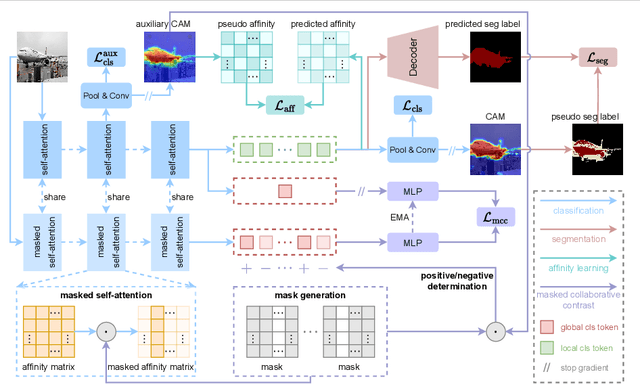
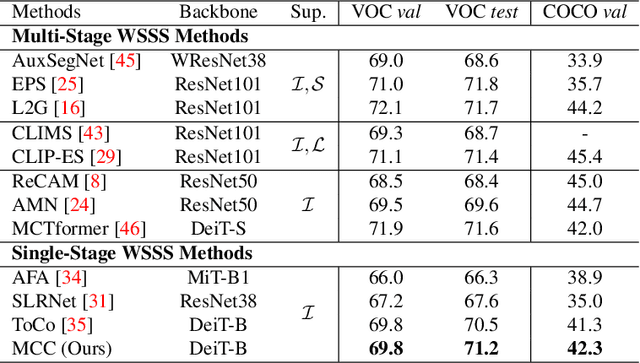
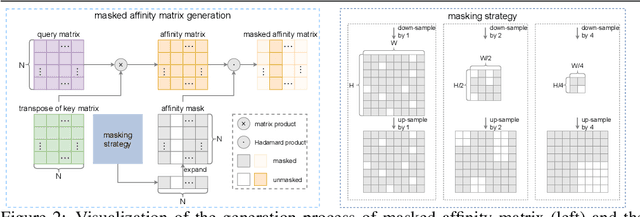

This study introduces an efficacious approach, Masked Collaborative Contrast (MCC), to emphasize semantic regions in weakly supervised semantic segmentation. MCC adroitly incorporates concepts from masked image modeling and contrastive learning to devise Transformer blocks that induce keys to contract towards semantically pertinent regions. Unlike prevalent techniques that directly eradicate patch regions in the input image when generating masks, we scrutinize the neighborhood relations of patch tokens by exploring masks considering keys on the affinity matrix. Moreover, we generate positive and negative samples in contrastive learning by utilizing the masked local output and contrasting it with the global output. Elaborate experiments on commonly employed datasets evidences that the proposed MCC mechanism effectively aligns global and local perspectives within the image, attaining impressive performance.
Pentagon-Match (PMatch): Identification of View-Invariant Planar Feature for Local Feature Matching-Based Homography Estimation
May 27, 2023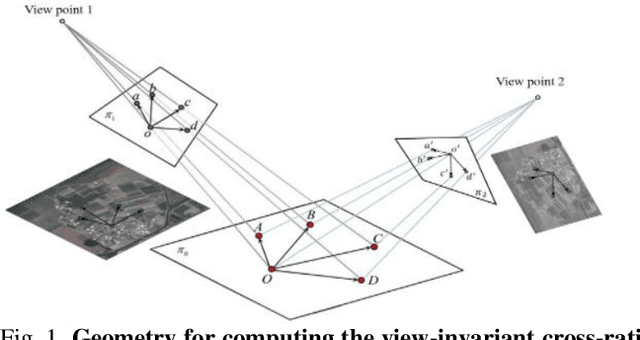
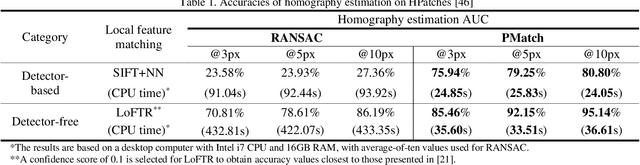
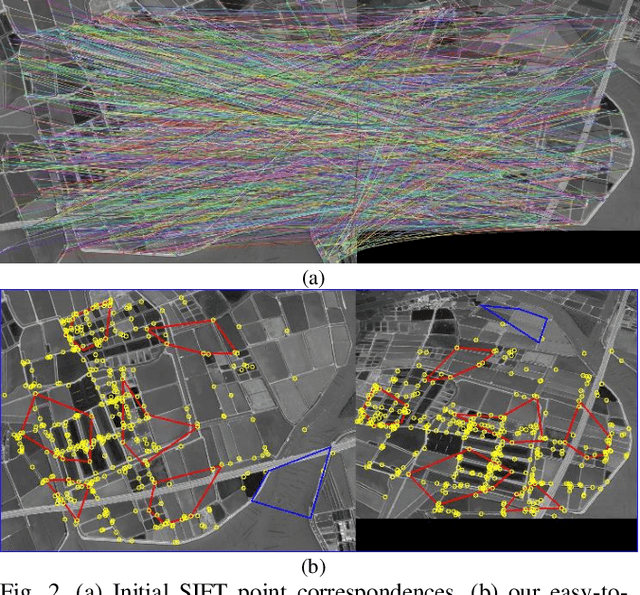
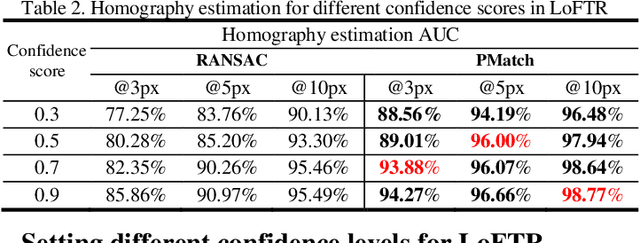
In computer vision, finding correct point correspondence among images plays an important role in many applications, such as image stitching, image retrieval, visual localization, etc. Most of the research works focus on the matching of local feature before a sampling method is employed, such as RANSAC, to verify initial matching results via repeated fitting of certain global transformation among the images. However, incorrect matches may still exist. Thus, a novel sampling scheme, Pentagon-Match (PMatch), is proposed in this work to verify the correctness of initially matched keypoints using pentagons randomly sampled from them. By ensuring shape and location of these pentagons are view-invariant with various evaluations of cross-ratio (CR), incorrect matches of keypoint can be identified easily with homography estimated from correctly matched pentagons. Experimental results show that highly accurate estimation of homography can be obtained efficiently for planar scenes of the HPatches dataset, based on keypoint matching results provided by LoFTR. Besides, accurate outlier identification for the above matching results and possible extension of the approach for multi-plane situation are also demonstrated.
Bytes Are All You Need: Transformers Operating Directly On File Bytes
May 31, 2023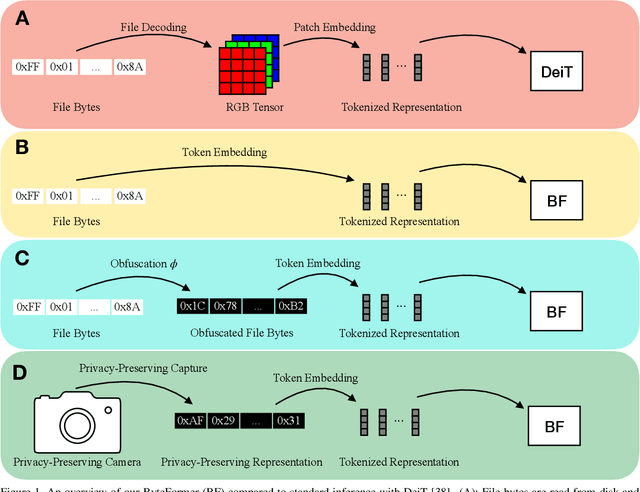

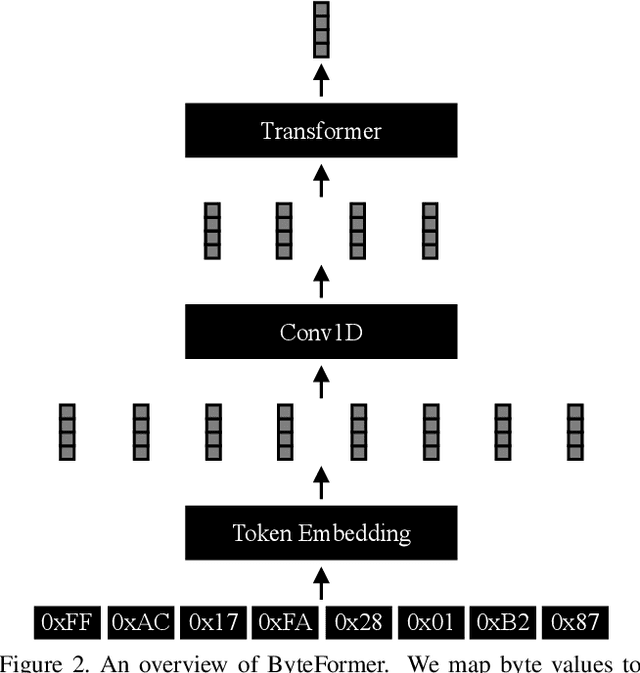
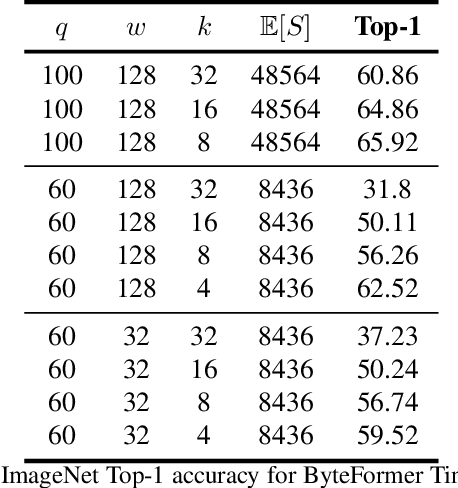
Modern deep learning approaches usually transform inputs into a modality-specific form. For example, the most common deep learning approach to image classification involves decoding image file bytes into an RGB tensor which is passed into a neural network. Instead, we investigate performing classification directly on file bytes, without the need for decoding files at inference time. Using file bytes as model inputs enables the development of models which can operate on multiple input modalities. Our model, \emph{ByteFormer}, achieves an ImageNet Top-1 classification accuracy of $77.33\%$ when training and testing directly on TIFF file bytes using a transformer backbone with configuration similar to DeiT-Ti ($72.2\%$ accuracy when operating on RGB images). Without modifications or hyperparameter tuning, ByteFormer achieves $95.42\%$ classification accuracy when operating on WAV files from the Speech Commands v2 dataset (compared to state-of-the-art accuracy of $98.7\%$). Additionally, we demonstrate that ByteFormer has applications in privacy-preserving inference. ByteFormer is capable of performing inference on particular obfuscated input representations with no loss of accuracy. We also demonstrate ByteFormer's ability to perform inference with a hypothetical privacy-preserving camera which avoids forming full images by consistently masking $90\%$ of pixel channels, while still achieving $71.35\%$ accuracy on ImageNet. Our code will be made available at https://github.com/apple/ml-cvnets/tree/main/examples/byteformer.