 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Denoising Diffusion Post-Processing for Low-Light Image Enhancement
Mar 16, 2023

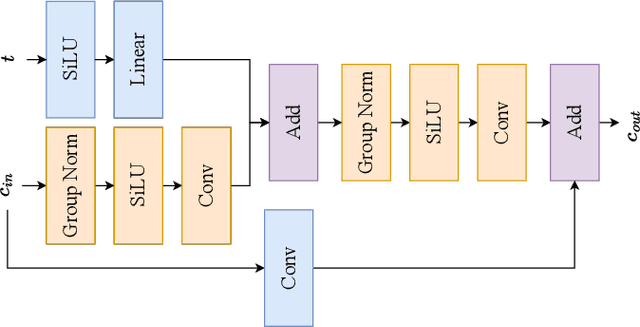

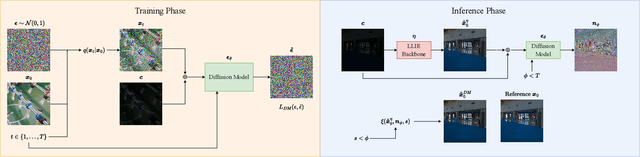
Low-light image enhancement (LLIE) techniques attempt to increase the visibility of images captured in low-light scenarios. However, as a result of enhancement, a variety of image degradations such as noise and color bias are revealed. Furthermore, each particular LLIE approach may introduce a different form of flaw within its enhanced results. To combat these image degradations, post-processing denoisers have widely been used, which often yield oversmoothed results lacking detail. We propose using a diffusion model as a post-processing approach, and we introduce Low-light Post-processing Diffusion Model (LPDM) in order to model the conditional distribution between under-exposed and normally-exposed images. We apply LPDM in a manner which avoids the computationally expensive generative reverse process of typical diffusion models, and post-process images in one pass through LPDM. Extensive experiments demonstrate that our approach outperforms competing post-processing denoisers by increasing the perceptual quality of enhanced low-light images on a variety of challenging low-light datasets. Source code is available at https://github.com/savvaki/LPDM.
Coherent Concept-based Explanations in Medical Image and Its Application to Skin Lesion Diagnosis
Apr 10, 2023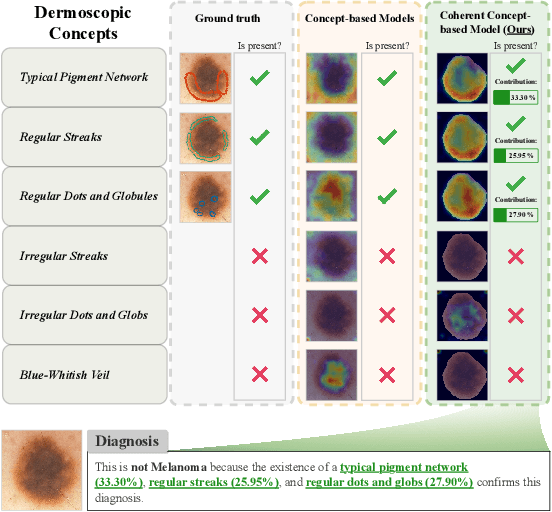
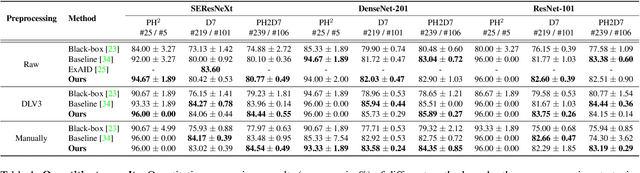
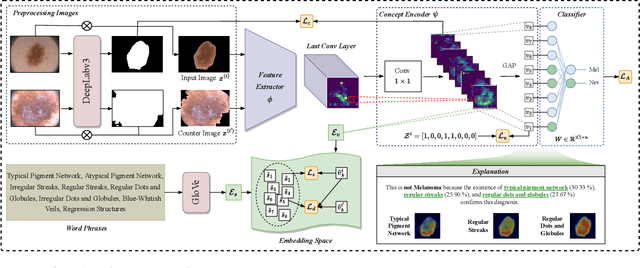
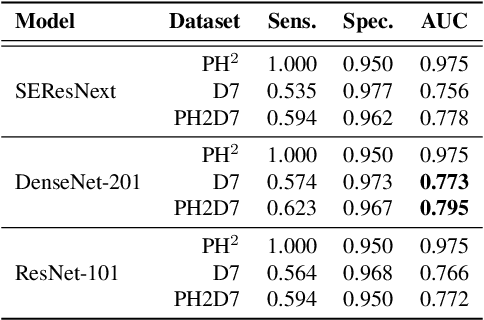
Early detection of melanoma is crucial for preventing severe complications and increasing the chances of successful treatment. Existing deep learning approaches for melanoma skin lesion diagnosis are deemed black-box models, as they omit the rationale behind the model prediction, compromising the trustworthiness and acceptability of these diagnostic methods. Attempts to provide concept-based explanations are based on post-hoc approaches, which depend on an additional model to derive interpretations. In this paper, we propose an inherently interpretable framework to improve the interpretability of concept-based models by incorporating a hard attention mechanism and a coherence loss term to assure the visual coherence of concept activations by the concept encoder, without requiring the supervision of additional annotations. The proposed framework explains its decision in terms of human-interpretable concepts and their respective contribution to the final prediction, as well as a visual interpretation of the locations where the concept is present in the image. Experiments on skin image datasets demonstrate that our method outperforms existing black-box and concept-based models for skin lesion classification.
Ultra Sharp : Study of Single Image Super Resolution using Residual Dense Network
Apr 24, 2023
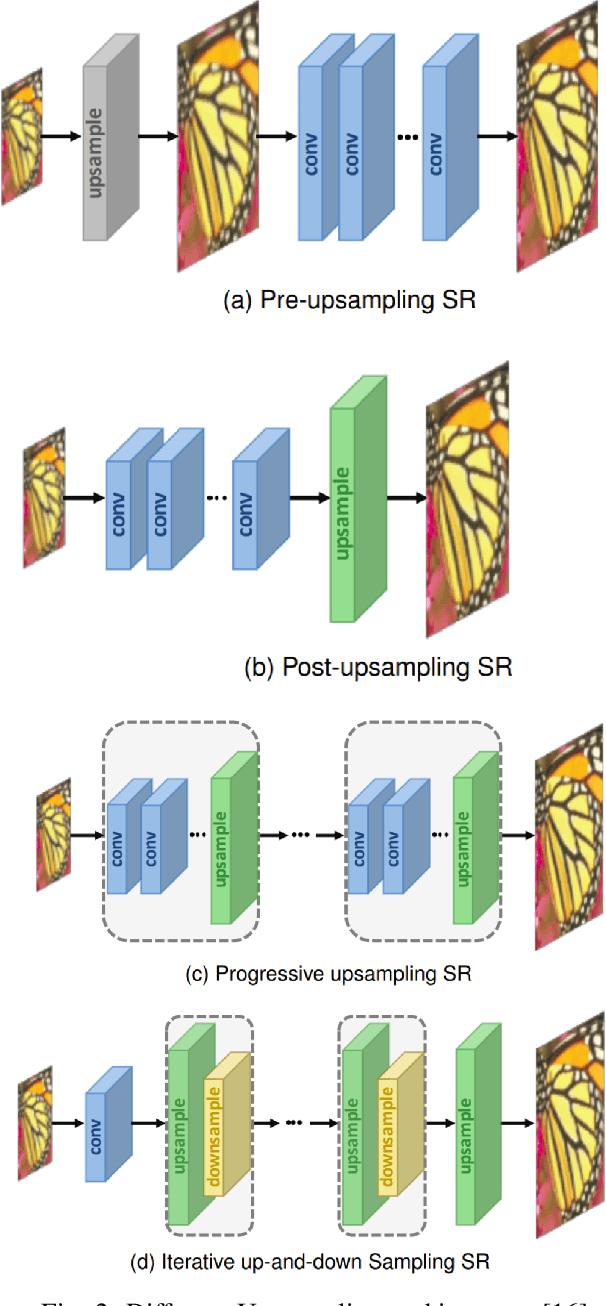
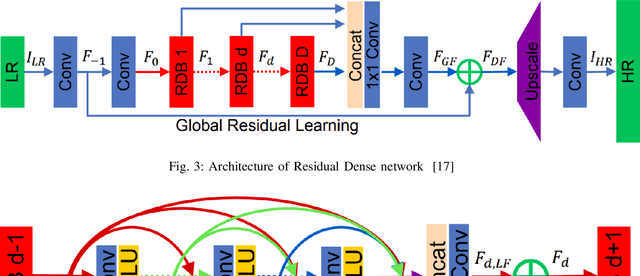
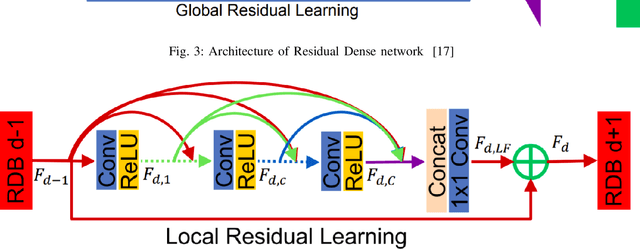
For years, Single Image Super Resolution (SISR) has been an interesting and ill-posed problem in computer vision. The traditional super-resolution (SR) imaging approaches involve interpolation, reconstruction, and learning-based methods. Interpolation methods are fast and uncomplicated to compute, but they are not so accurate and reliable. Reconstruction-based methods are better compared with interpolation methods, but they are time-consuming and the quality degrades as the scaling increases. Even though learning-based methods like Markov random chains are far better than all the previous ones, they are unable to match the performance of deep learning models for SISR. This study examines the Residual Dense Networks architecture proposed by Yhang et al. [17] and analyzes the importance of its components. By leveraging hierarchical features from original low-resolution (LR) images, this architecture achieves superior performance, with a network structure comprising four main blocks, including the residual dense block (RDB) as the core. Through investigations of each block and analyses using various loss metrics, the study evaluates the effectiveness of the architecture and compares it to other state-of-the-art models that differ in both architecture and components.
MedGen3D: A Deep Generative Framework for Paired 3D Image and Mask Generation
Apr 08, 2023
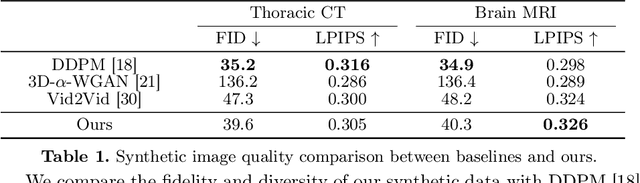
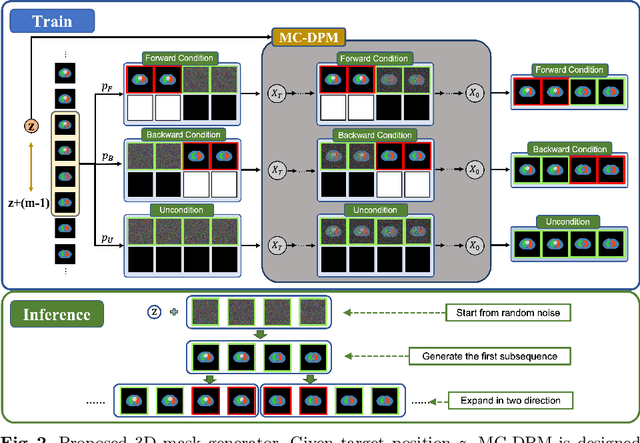
Acquiring and annotating sufficient labeled data is crucial in developing accurate and robust learning-based models, but obtaining such data can be challenging in many medical image segmentation tasks. One promising solution is to synthesize realistic data with ground-truth mask annotations. However, no prior studies have explored generating complete 3D volumetric images with masks. In this paper, we present MedGen3D, a deep generative framework that can generate paired 3D medical images and masks. First, we represent the 3D medical data as 2D sequences and propose the Multi-Condition Diffusion Probabilistic Model (MC-DPM) to generate multi-label mask sequences adhering to anatomical geometry. Then, we use an image sequence generator and semantic diffusion refiner conditioned on the generated mask sequences to produce realistic 3D medical images that align with the generated masks. Our proposed framework guarantees accurate alignment between synthetic images and segmentation maps. Experiments on 3D thoracic CT and brain MRI datasets show that our synthetic data is both diverse and faithful to the original data, and demonstrate the benefits for downstream segmentation tasks. We anticipate that MedGen3D's ability to synthesize paired 3D medical images and masks will prove valuable in training deep learning models for medical imaging tasks.
CLIMAX: An exploration of Classifier-Based Contrastive Explanations
Jul 02, 2023
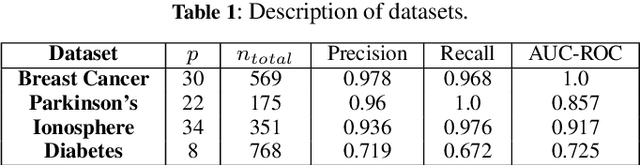
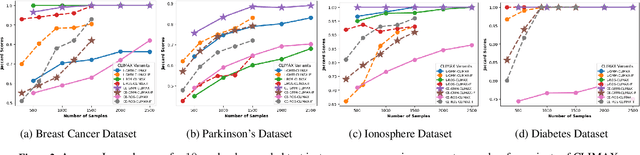
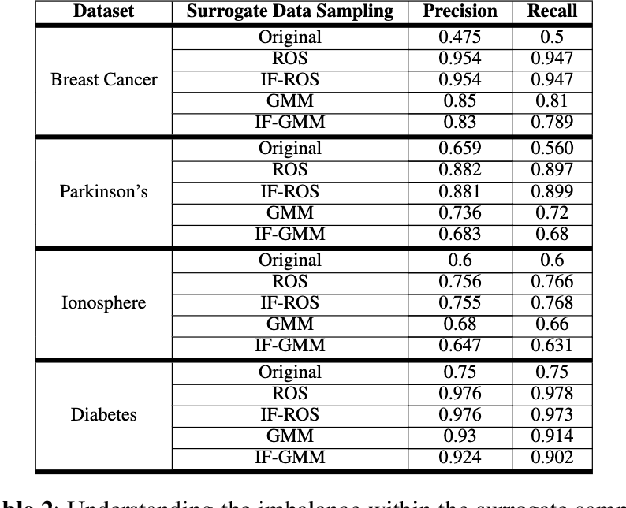
Explainable AI is an evolving area that deals with understanding the decision making of machine learning models so that these models are more transparent, accountable, and understandable for humans. In particular, post-hoc model-agnostic interpretable AI techniques explain the decisions of a black-box ML model for a single instance locally, without the knowledge of the intrinsic nature of the ML model. Despite their simplicity and capability in providing valuable insights, existing approaches fail to deliver consistent and reliable explanations. Moreover, in the context of black-box classifiers, existing approaches justify the predicted class, but these methods do not ensure that the explanation scores strongly differ as compared to those of another class. In this work we propose a novel post-hoc model agnostic XAI technique that provides contrastive explanations justifying the classification of a black box classifier along with a reasoning as to why another class was not predicted. Our method, which we refer to as CLIMAX which is short for Contrastive Label-aware Influence-based Model Agnostic XAI, is based on local classifiers . In order to ensure model fidelity of the explainer, we require the perturbations to be such that it leads to a class-balanced surrogate dataset. Towards this, we employ a label-aware surrogate data generation method based on random oversampling and Gaussian Mixture Model sampling. Further, we propose influence subsampling in order to retaining effective samples and hence ensure sample complexity. We show that we achieve better consistency as compared to baselines such as LIME, BayLIME, and SLIME. We also depict results on textual and image based datasets, where we generate contrastive explanations for any black-box classification model where one is able to only query the class probabilities for an instance of interest.
Model-agnostic explainable artificial intelligence for object detection in image data
Apr 12, 2023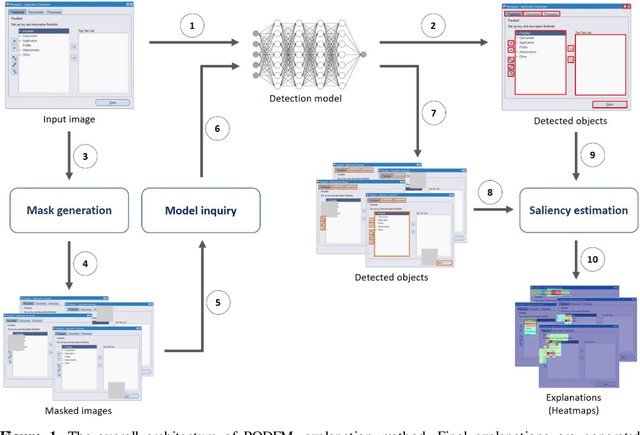
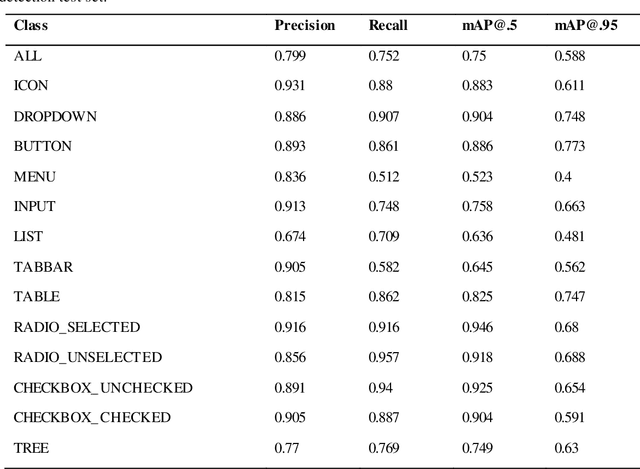
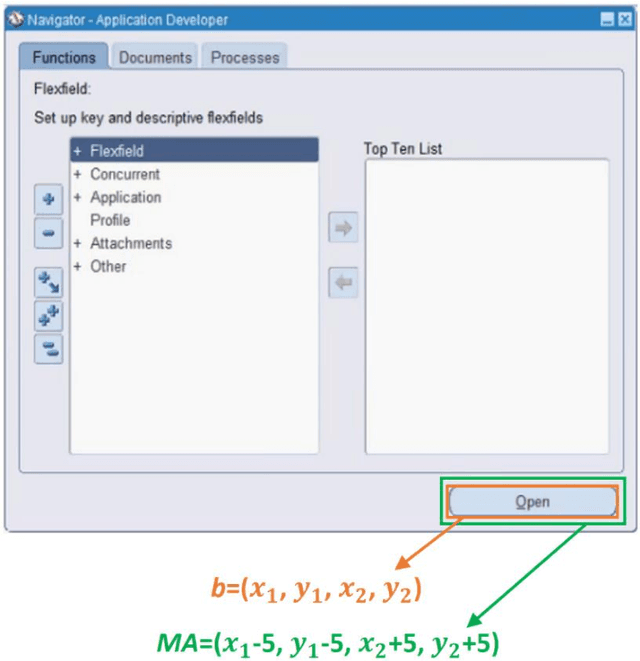
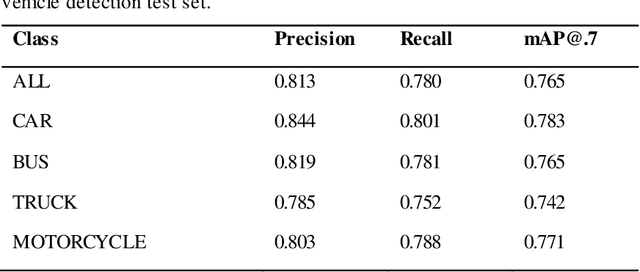
Object detection is a fundamental task in computer vision, which has been greatly progressed through developing large and intricate deep learning models. However, the lack of transparency is a big challenge that may not allow the widespread adoption of these models. Explainable artificial intelligence is a field of research where methods are developed to help users understand the behavior, decision logics, and vulnerabilities of AI-based systems. Black-box explanation refers to explaining decisions of an AI system without having access to its internals. In this paper, we design and implement a black-box explanation method named Black-box Object Detection Explanation by Masking (BODEM) through adopting a new masking approach for AI-based object detection systems. We propose local and distant masking to generate multiple versions of an input image. Local masks are used to disturb pixels within a target object to figure out how the object detector reacts to these changes, while distant masks are used to assess how the detection model's decisions are affected by disturbing pixels outside the object. A saliency map is then created by estimating the importance of pixels through measuring the difference between the detection output before and after masking. Finally, a heatmap is created that visualizes how important pixels within the input image are to the detected objects. The experimentations on various object detection datasets and models showed that BODEM can be effectively used to explain the behavior of object detectors and reveal their vulnerabilities. This makes BODEM suitable for explaining and validating AI based object detection systems in black-box software testing scenarios. Furthermore, we conducted data augmentation experiments that showed local masks produced by BODEM can be used for further training the object detectors and improve their detection accuracy and robustness.
Deformable Cross-Attention Transformer for Medical Image Registration
Mar 10, 2023
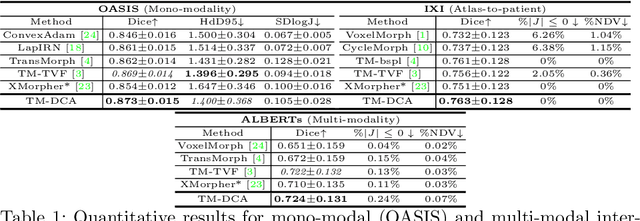
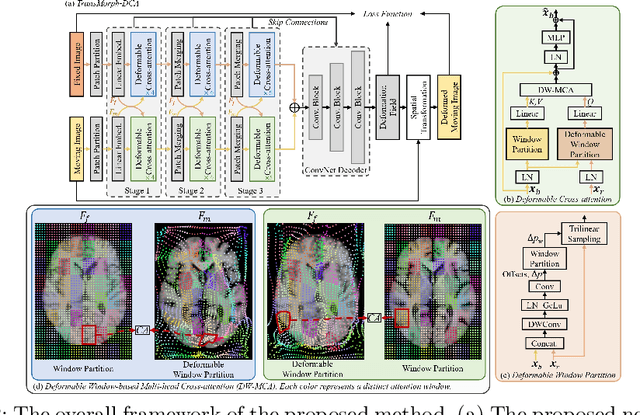
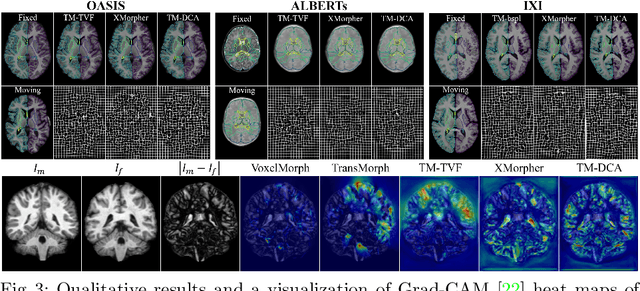
Transformers have recently shown promise for medical image applications, leading to an increasing interest in developing such models for medical image registration. Recent advancements in designing registration Transformers have focused on using cross-attention (CA) to enable a more precise understanding of spatial correspondences between moving and fixed images. Here, we propose a novel CA mechanism that computes windowed attention using deformable windows. In contrast to existing CA mechanisms that require intensive computational complexity by either computing CA globally or locally with a fixed and expanded search window, the proposed deformable CA can selectively sample a diverse set of features over a large search window while maintaining low computational complexity. The proposed model was extensively evaluated on multi-modal, mono-modal, and atlas-to-patient registration tasks, demonstrating promising performance against state-of-the-art methods and indicating its effectiveness for medical image registration. The source code for this work will be available after publication.
DreamEditor: Text-Driven 3D Scene Editing with Neural Fields
Jun 23, 2023
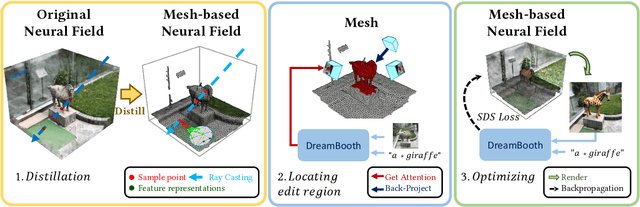

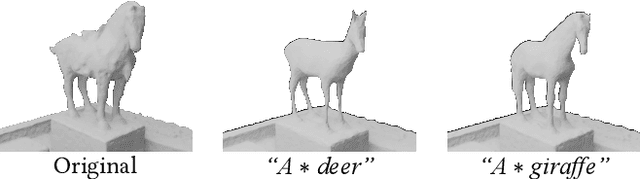
Neural fields have achieved impressive advancements in view synthesis and scene reconstruction. However, editing these neural fields remains challenging due to the implicit encoding of geometry and texture information. In this paper, we propose DreamEditor, a novel framework that enables users to perform controlled editing of neural fields using text prompts. By representing scenes as mesh-based neural fields, DreamEditor allows localized editing within specific regions. DreamEditor utilizes the text encoder of a pretrained text-to-Image diffusion model to automatically identify the regions to be edited based on the semantics of the text prompts. Subsequently, DreamEditor optimizes the editing region and aligns its geometry and texture with the text prompts through score distillation sampling [29]. Extensive experiments have demonstrated that DreamEditor can accurately edit neural fields of real-world scenes according to the given text prompts while ensuring consistency in irrelevant areas. DreamEditor generates highly realistic textures and geometry, significantly surpassing previous works in both quantitative and qualitative evaluations.
Prediction under Latent Subgroup Shifts with High-Dimensional Observations
Jun 23, 2023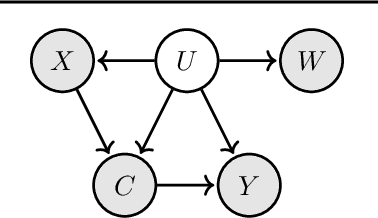
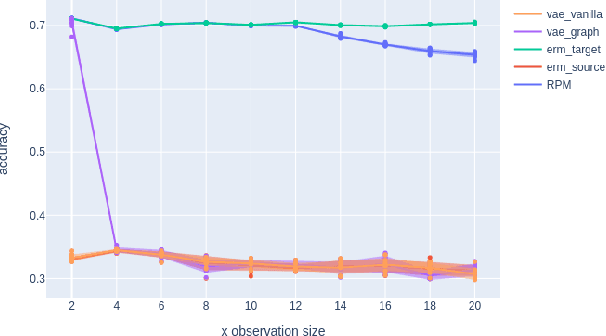
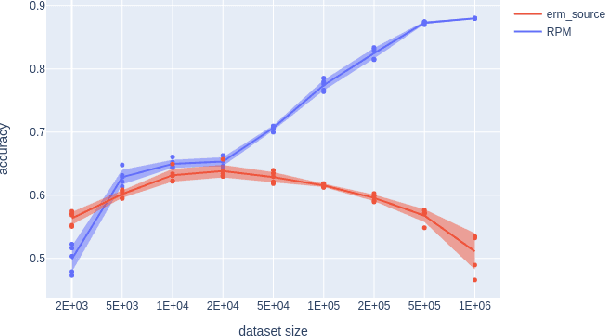
We introduce a new approach to prediction in graphical models with latent-shift adaptation, i.e., where source and target environments differ in the distribution of an unobserved confounding latent variable. Previous work has shown that as long as "concept" and "proxy" variables with appropriate dependence are observed in the source environment, the latent-associated distributional changes can be identified, and target predictions adapted accurately. However, practical estimation methods do not scale well when the observations are complex and high-dimensional, even if the confounding latent is categorical. Here we build upon a recently proposed probabilistic unsupervised learning framework, the recognition-parametrised model (RPM), to recover low-dimensional, discrete latents from image observations. Applied to the problem of latent shifts, our novel form of RPM identifies causal latent structure in the source environment, and adapts properly to predict in the target. We demonstrate results in settings where predictor and proxy are high-dimensional images, a context to which previous methods fail to scale.
What makes a good data augmentation for few-shot unsupervised image anomaly detection?
Apr 21, 2023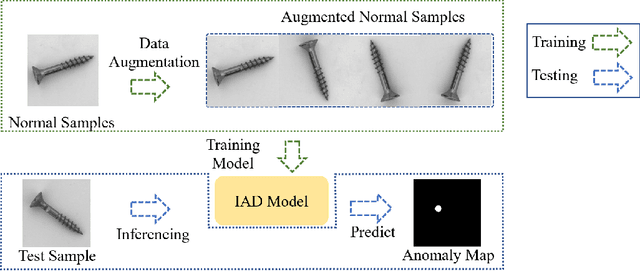

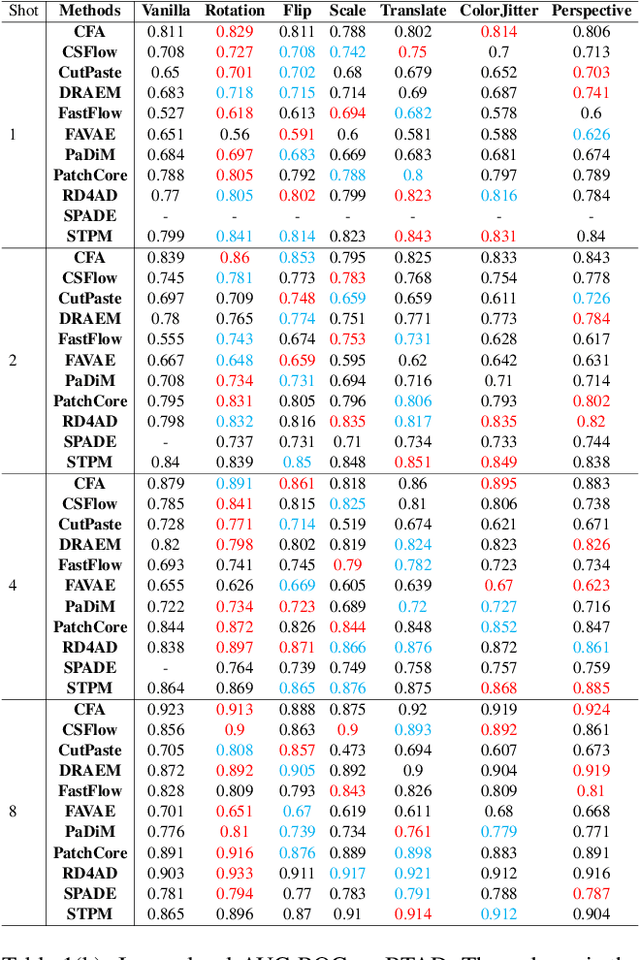
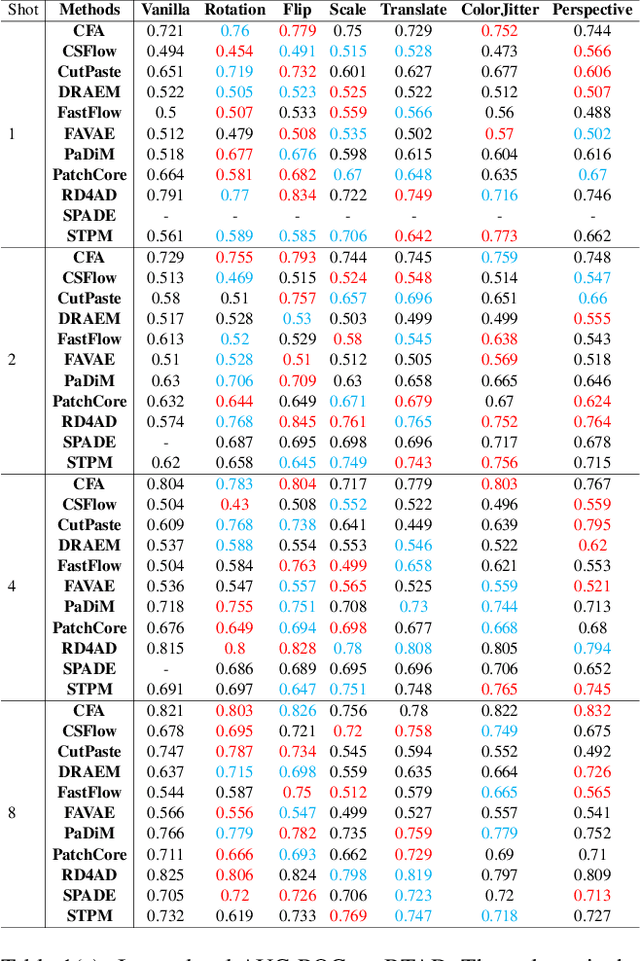
Data augmentation is a promising technique for unsupervised anomaly detection in industrial applications, where the availability of positive samples is often limited due to factors such as commercial competition and sample collection difficulties. In this paper, how to effectively select and apply data augmentation methods for unsupervised anomaly detection is studied. The impact of various data augmentation methods on different anomaly detection algorithms is systematically investigated through experiments. The experimental results show that the performance of different industrial image anomaly detection (termed as IAD) algorithms is not significantly affected by the specific data augmentation method employed and that combining multiple data augmentation methods does not necessarily yield further improvements in the accuracy of anomaly detection, although it can achieve excellent results on specific methods. These findings provide useful guidance on selecting appropriate data augmentation methods for different requirements in IAD.