 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Foundations of Continual Learning via Drift-Plus-Penalty
Jun 07, 2026In many real-world settings, data streams are nonstationary and arrive sequentially, requiring learning systems to adapt continuously without retraining from scratch. Continual learning (CL) addresses this challenge by incorporating new tasks while mitigating catastrophic forgetting, where learning new information degrades performance on previously acquired knowledge. We introduce a control-theoretic perspective on CL that explicitly regulates the evolution of forgetting, framing adaptation as a controlled process subject to long-term stability constraints. We focus on replay-based CL, where a finite memory buffer stores representative samples from prior tasks. We propose COntinual Learning with Drift-Plus-Penalty (COLD), a continual learning framework based on the Drift-Plus-Penalty (DPP) principle from stochastic optimization. To facilitate analysis, we also consider an oracle variant, COLD-ORACLE, as a reference benchmark. At each task, both methods minimize the current task loss while maintaining a virtual queue that tracks deviations from long-term stability on previously learned tasks, capturing the stability-plasticity trade-off as a regulated dynamical process. We establish stability and convergence guarantees that characterize this trade-off through a tunable control parameter. Experiments on standard benchmarks demonstrate that COLD consistently outperforms a broad range of state-of-the-art CL methods while providing competitive and controllable forgetting behavior through explicit regulation of stability and plasticity.
Informative Perturbation Selection for Uncertainty-Aware Post-hoc Explanations
Mar 17, 2026Trust and ethical concerns due to the widespread deployment of opaque machine learning (ML) models motivating the need for reliable model explanations. Post-hoc model-agnostic explanation methods addresses this challenge by learning a surrogate model that approximates the behavior of the deployed black-box ML model in the locality of a sample of interest. In post-hoc scenarios, neither the underlying model parameters nor the training are available, and hence, this local neighborhood must be constructed by generating perturbed inputs in the neighborhood of the sample of interest, and its corresponding model predictions. We propose \emph{Expected Active Gain for Local Explanations} (\texttt{EAGLE}), a post-hoc model-agnostic explanation framework that formulates perturbation selection as an information-theoretic active learning problem. By adaptively sampling perturbations that maximize the expected information gain, \texttt{EAGLE} efficiently learns a linear surrogate explainable model while producing feature importance scores along with the uncertainty/confidence estimates. Theoretically, we establish that cumulative information gain scales as $\mathcal{O}(d \log t)$, where $d$ is the feature dimension and $t$ represents the number of samples, and that the sample complexity grows linearly with $d$ and logarithmically with the confidence parameter $1/δ$. Empirical results on tabular and image datasets corroborate our theoretical findings and demonstrate that \texttt{EAGLE} improves explanation reproducibility across runs, achieves higher neighborhood stability, and improves perturbation sample quality as compared to state-of-the-art baselines such as Tilia, US-LIME, GLIME and BayesLIME.
Nishpaksh: TEC Standard-Compliant Framework for Fairness Auditing and Certification of AI Models
Jan 23, 2026The growing reliance on Artificial Intelligence (AI) models in high-stakes decision-making systems, particularly within emerging telecom and 6G applications, underscores the urgent need for transparent and standardized fairness assessment frameworks. While global toolkits such as IBM AI Fairness 360 and Microsoft Fairlearn have advanced bias detection, they often lack alignment with region-specific regulatory requirements and national priorities. To address this gap, we propose Nishpaksh, an indigenous fairness evaluation tool that operationalizes the Telecommunication Engineering Centre (TEC) Standard for the Evaluation and Rating of Artificial Intelligence Systems. Nishpaksh integrates survey-based risk quantification, contextual threshold determination, and quantitative fairness evaluation into a unified, web-based dashboard. The tool employs vectorized computation, reactive state management, and certification-ready reporting to enable reproducible, audit-grade assessments, thereby addressing a critical post-standardization implementation need. Experimental validation on the COMPAS dataset demonstrates Nishpaksh's effectiveness in identifying attribute-specific bias and generating standardized fairness scores compliant with the TEC framework. The system bridges the gap between research-oriented fairness methodologies and regulatory AI governance in India, marking a significant step toward responsible and auditable AI deployment within critical infrastructure like telecommunications.
Representation Learning Preserving Ignorability and Covariate Matching for Treatment Effects
Apr 29, 2025Estimating treatment effects from observational data is challenging due to two main reasons: (a) hidden confounding, and (b) covariate mismatch (control and treatment groups not having identical distributions). Long lines of works exist that address only either of these issues. To address the former, conventional techniques that require detailed knowledge in the form of causal graphs have been proposed. For the latter, covariate matching and importance weighting methods have been used. Recently, there has been progress in combining testable independencies with partial side information for tackling hidden confounding. A common framework to address both hidden confounding and selection bias is missing. We propose neural architectures that aim to learn a representation of pre-treatment covariates that is a valid adjustment and also satisfies covariate matching constraints. We combine two different neural architectures: one based on gradient matching across domains created by subsampling a suitable anchor variable that assumes causal side information, followed by the other, a covariate matching transformation. We prove that approximately invariant representations yield approximate valid adjustment sets which would enable an interval around the true causal effect. In contrast to usual sensitivity analysis, where an unknown nuisance parameter is varied, we have a testable approximation yielding a bound on the effect estimate. We also outperform various baselines with respect to ATE and PEHE errors on causal benchmarks that include IHDP, Jobs, Cattaneo, and an image-based Crowd Management dataset.
Noise Resilient Over-The-Air Federated Learning In Heterogeneous Wireless Networks
Mar 25, 2025



In 6G wireless networks, Artificial Intelligence (AI)-driven applications demand the adoption of Federated Learning (FL) to enable efficient and privacy-preserving model training across distributed devices. Over-The-Air Federated Learning (OTA-FL) exploits the superposition property of multiple access channels, allowing edge users in 6G networks to efficiently share spectral resources and perform low-latency global model aggregation. However, these advantages come with challenges, as traditional OTA-FL techniques suffer due to the joint effects of Additive White Gaussian Noise (AWGN) at the server, fading, and both data and system heterogeneity at the participating edge devices. In this work, we propose the novel Noise Resilient Over-the-Air Federated Learning (NoROTA-FL) framework to jointly tackle these challenges in federated wireless networks. In NoROTA-FL, the local optimization problems find controlled inexact solutions, which manifests as an additional proximal constraint at the clients. This approach provides robustness against straggler-induced partial work, heterogeneity, noise, and fading. From a theoretical perspective, we leverage the zeroth- and first-order inexactness and establish convergence guarantees for non-convex optimization problems in the presence of heterogeneous data and varying system capabilities. Experimentally, we validate NoROTA-FL on real-world datasets, including FEMNIST, CIFAR10, and CIFAR100, demonstrating its robustness in noisy and heterogeneous environments. Compared to state-of-the-art baselines such as COTAF and FedProx, NoROTA-FL achieves significantly more stable convergence and higher accuracy, particularly in the presence of stragglers.
On the Convergence of Continual Federated Learning Using Incrementally Aggregated Gradients
Nov 12, 2024



The holy grail of machine learning is to enable Continual Federated Learning (CFL) to enhance the efficiency, privacy, and scalability of AI systems while learning from streaming data. The primary challenge of a CFL system is to overcome global catastrophic forgetting, wherein the accuracy of the global model trained on new tasks declines on the old tasks. In this work, we propose Continual Federated Learning with Aggregated Gradients (C-FLAG), a novel replay-memory based federated strategy consisting of edge-based gradient updates on memory and aggregated gradients on the current data. We provide convergence analysis of the C-FLAG approach which addresses forgetting and bias while converging at a rate of $O(1/\sqrt{T})$ over $T$ communication rounds. We formulate an optimization sub-problem that minimizes catastrophic forgetting, translating CFL into an iterative algorithm with adaptive learning rates that ensure seamless learning across tasks. We empirically show that C-FLAG outperforms several state-of-the-art baselines on both task and class-incremental settings with respect to metrics such as accuracy and forgetting.
On Homomorphic Encryption Based Strategies for Class Imbalance in Federated Learning
Oct 28, 2024Class imbalance in training datasets can lead to bias and poor generalization in machine learning models. While pre-processing of training datasets can efficiently address both these issues in centralized learning environments, it is challenging to detect and address these issues in a distributed learning environment such as federated learning. In this paper, we propose FLICKER, a privacy preserving framework to address issues related to global class imbalance in federated learning. At the heart of our contribution lies the popular CKKS homomorphic encryption scheme, which is used by the clients to privately share their data attributes, and subsequently balance their datasets before implementing the FL scheme. Extensive experimental results show that our proposed method significantly improves the FL accuracy numbers when used along with popular datasets and relevant baselines.
CLIMAX: An exploration of Classifier-Based Contrastive Explanations
Jul 02, 2023Explainable AI is an evolving area that deals with understanding the decision making of machine learning models so that these models are more transparent, accountable, and understandable for humans. In particular, post-hoc model-agnostic interpretable AI techniques explain the decisions of a black-box ML model for a single instance locally, without the knowledge of the intrinsic nature of the ML model. Despite their simplicity and capability in providing valuable insights, existing approaches fail to deliver consistent and reliable explanations. Moreover, in the context of black-box classifiers, existing approaches justify the predicted class, but these methods do not ensure that the explanation scores strongly differ as compared to those of another class. In this work we propose a novel post-hoc model agnostic XAI technique that provides contrastive explanations justifying the classification of a black box classifier along with a reasoning as to why another class was not predicted. Our method, which we refer to as CLIMAX which is short for Contrastive Label-aware Influence-based Model Agnostic XAI, is based on local classifiers . In order to ensure model fidelity of the explainer, we require the perturbations to be such that it leads to a class-balanced surrogate dataset. Towards this, we employ a label-aware surrogate data generation method based on random oversampling and Gaussian Mixture Model sampling. Further, we propose influence subsampling in order to retaining effective samples and hence ensure sample complexity. We show that we achieve better consistency as compared to baselines such as LIME, BayLIME, and SLIME. We also depict results on textual and image based datasets, where we generate contrastive explanations for any black-box classification model where one is able to only query the class probabilities for an instance of interest.
Over-The-Air Clustered Wireless Federated Learning
Nov 08, 2022Privacy, security, and bandwidth constraints have led to federated learning (FL) in wireless systems, where training a machine learning (ML) model is accomplished collaboratively without sharing raw data. Often, such collaborative FL strategies necessitate model aggregation at a server. On the other hand, decentralized FL necessitates that participating clients reach a consensus ML model by exchanging parameter updates. In this work, we propose the over-the-air clustered wireless FL (CWFL) strategy, which eliminates the need for a strong central server and yet achieves an accuracy similar to the server-based strategy while using fewer channel uses as compared to decentralized FL. We theoretically show that the convergence rate of CWFL per cluster is O(1/T) while mitigating the impact of noise. Using the MNIST and CIFAR datasets, we demonstrate the accuracy performance of CWFL for the different number of clusters across communication rounds.
DAGSurv: Directed Acyclic Graph Based Survival Analysis Using Deep Neural Networks
Nov 02, 2021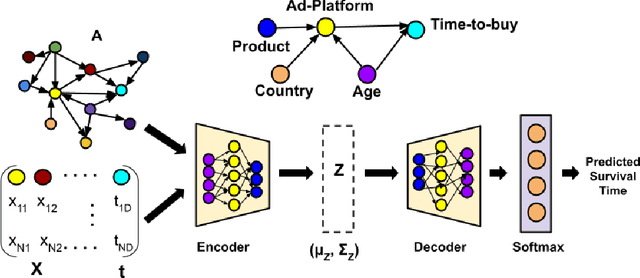
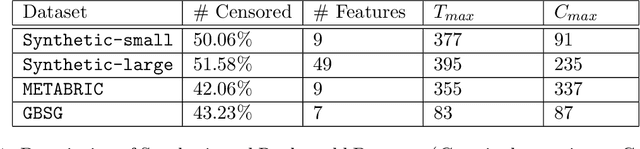
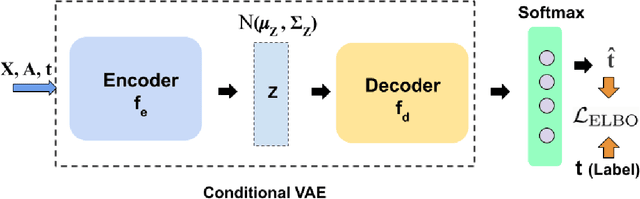

Causal structures for observational survival data provide crucial information regarding the relationships between covariates and time-to-event. We derive motivation from the information theoretic source coding argument, and show that incorporating the knowledge of the directed acyclic graph (DAG) can be beneficial if suitable source encoders are employed. As a possible source encoder in this context, we derive a variational inference based conditional variational autoencoder for causal structured survival prediction, which we refer to as DAGSurv. We illustrate the performance of DAGSurv on low and high-dimensional synthetic datasets, and real-world datasets such as METABRIC and GBSG. We demonstrate that the proposed method outperforms other survival analysis baselines such as Cox Proportional Hazards, DeepSurv and Deephit, which are oblivious to the underlying causal relationship between data entities.