 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical study of LoRA-based fine-tuning of large language models for automated test case generation
Apr 08, 2026Automated test case generation from natural language requirements remains a challenging problem in software engineering due to the ambiguity of requirements and the need to produce structured, executable test artifacts. Recent advances in LLMs have shown promise in addressing this task; however, their effectiveness depends on task-specific adaptation and efficient fine-tuning strategies. In this paper, we present a comprehensive empirical study on the use of parameter-efficient fine-tuning, specifically LoRA, for requirement-based test case generation. We evaluate multiple LLM families, including open-source and proprietary models, under a unified experimental pipeline. The study systematically explores the impact of key LoRA hyperparameters, including rank, scaling factor, and dropout, on downstream performance. We propose an automated evaluation framework based on GPT-4o, which assesses generated test cases across nine quality dimensions. Experimental results demonstrate that LoRA-based fine-tuning significantly improves the performance of all open-source models, with Ministral-8B achieving the best results among them. Furthermore, we show that a fine-tuned 8B open-source model can achieve performance comparable to pre-fine-tuned GPT-4.1 models, highlighting the effectiveness of parameter-efficient adaptation. While GPT-4.1 models achieve the highest overall performance, the performance gap between proprietary and open-source models is substantially reduced after fine-tuning. These findings provide important insights into model selection, fine-tuning strategies, and evaluation methods for automated test generation. In particular, they demonstrate that cost-efficient, locally deployable open-source models can serve as viable alternatives to proprietary systems when combined with well-designed fine-tuning approaches.
Multi-modal user interface control detection using cross-attention
Apr 08, 2026Detecting user interface (UI) controls from software screenshots is a critical task for automated testing, accessibility, and software analytics, yet it remains challenging due to visual ambiguities, design variability, and the lack of contextual cues in pixel-only approaches. In this paper, we introduce a novel multi-modal extension of YOLOv5 that integrates GPT-generated textual descriptions of UI images into the detection pipeline through cross-attention modules. By aligning visual features with semantic information derived from text embeddings, our model enables more robust and context-aware UI control detection. We evaluate the proposed framework on a large dataset of over 16,000 annotated UI screenshots spanning 23 control classes. Extensive experiments compare three fusion strategies, i.e. element-wise addition, weighted sum, and convolutional fusion, demonstrating consistent improvements over the baseline YOLOv5 model. Among these, convolutional fusion achieved the strongest performance, with significant gains in detecting semantically complex or visually ambiguous classes. These results establish that combining visual and textual modalities can substantially enhance UI element detection, particularly in edge cases where visual information alone is insufficient. Our findings open promising opportunities for more reliable and intelligent tools in software testing, accessibility support, and UI analytics, setting the stage for future research on efficient, robust, and generalizable multi-modal detection systems.
Artificial intelligence for context-aware visual change detection in software test automation
May 01, 2024Automated software testing is integral to the software development process, streamlining workflows and ensuring product reliability. Visual testing within this context, especially concerning user interface (UI) and user experience (UX) validation, stands as one of crucial determinants of overall software quality. Nevertheless, conventional methods like pixel-wise comparison and region-based visual change detection fall short in capturing contextual similarities, nuanced alterations, and understanding the spatial relationships between UI elements. In this paper, we introduce a novel graph-based method for visual change detection in software test automation. Leveraging a machine learning model, our method accurately identifies UI controls from software screenshots and constructs a graph representing contextual and spatial relationships between the controls. This information is then used to find correspondence between UI controls within screenshots of different versions of a software. The resulting graph encapsulates the intricate layout of the UI and underlying contextual relations, providing a holistic and context-aware model. This model is finally used to detect and highlight visual regressions in the UI. Comprehensive experiments on different datasets showed that our change detector can accurately detect visual software changes in various simple and complex test scenarios. Moreover, it outperformed pixel-wise comparison and region-based baselines by a large margin in more complex testing scenarios. This work not only contributes to the advancement of visual change detection but also holds practical implications, offering a robust solution for real-world software test automation challenges, enhancing reliability, and ensuring the seamless evolution of software interfaces.
Model-agnostic explainable artificial intelligence for object detection in image data
Apr 12, 2023



Object detection is a fundamental task in computer vision, which has been greatly progressed through developing large and intricate deep learning models. However, the lack of transparency is a big challenge that may not allow the widespread adoption of these models. Explainable artificial intelligence is a field of research where methods are developed to help users understand the behavior, decision logics, and vulnerabilities of AI-based systems. Black-box explanation refers to explaining decisions of an AI system without having access to its internals. In this paper, we design and implement a black-box explanation method named Black-box Object Detection Explanation by Masking (BODEM) through adopting a new masking approach for AI-based object detection systems. We propose local and distant masking to generate multiple versions of an input image. Local masks are used to disturb pixels within a target object to figure out how the object detector reacts to these changes, while distant masks are used to assess how the detection model's decisions are affected by disturbing pixels outside the object. A saliency map is then created by estimating the importance of pixels through measuring the difference between the detection output before and after masking. Finally, a heatmap is created that visualizes how important pixels within the input image are to the detected objects. The experimentations on various object detection datasets and models showed that BODEM can be effectively used to explain the behavior of object detectors and reveal their vulnerabilities. This makes BODEM suitable for explaining and validating AI based object detection systems in black-box software testing scenarios. Furthermore, we conducted data augmentation experiments that showed local masks produced by BODEM can be used for further training the object detectors and improve their detection accuracy and robustness.
U-Net with spatial pyramid pooling for drusen segmentation in optical coherence tomography
Dec 11, 2019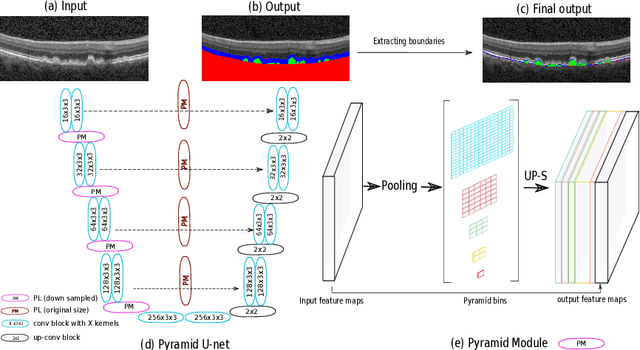

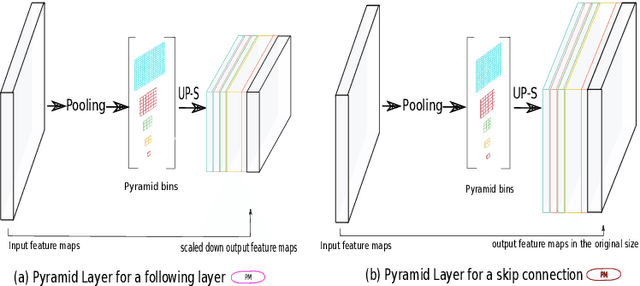
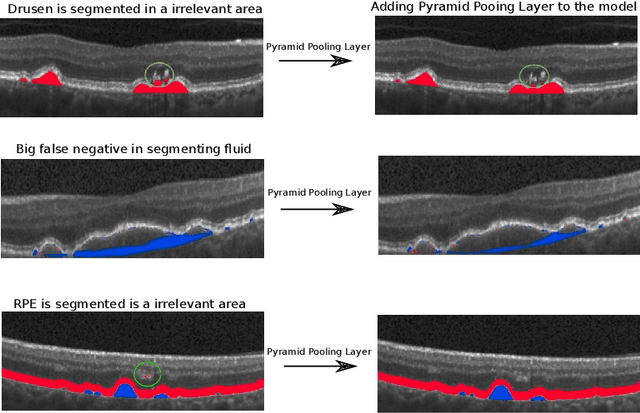
The presence of drusen is the main hallmark of early/intermediate age-related macular degeneration (AMD). Therefore, automated drusen segmentation is an important step in image-guided management of AMD. There are two common approaches to drusen segmentation. In the first, the drusen are segmented directly as a binary classification task. In the second approach, the surrounding retinal layers (outer boundary retinal pigment epithelium (OBRPE) and Bruch's membrane (BM)) are segmented and the remaining space between these two layers is extracted as drusen. In this work, we extend the standard U-Net architecture with spatial pyramid pooling components to introduce global feature context. We apply the model to the task of segmenting drusen together with BM and OBRPE. The proposed network was trained and evaluated on a longitudinal OCT dataset of 425 scans from 38 patients with early/intermediate AMD. This preliminary study showed that the proposed network consistently outperformed the standard U-net model.
Multiclass segmentation as multitask learning for drusen segmentation in retinal optical coherence tomography
Jul 24, 2019
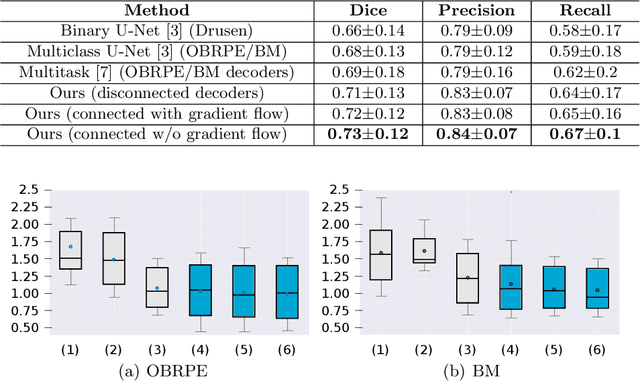
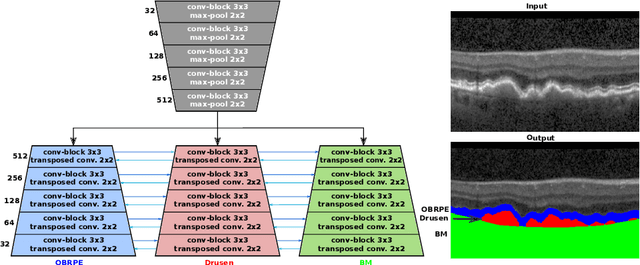
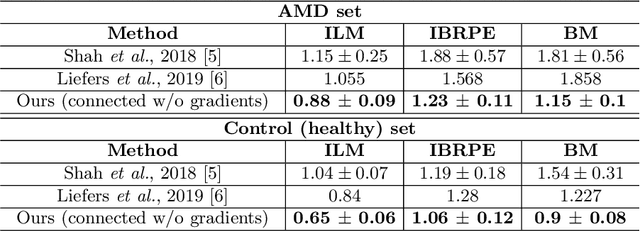
Automated drusen segmentation in retinal optical coherence tomography (OCT) scans is relevant for understanding age-related macular degeneration (AMD) risk and progression. This task is usually performed by segmenting the top/bottom anatomical interfaces that define drusen, the outer boundary of the retinal pigment epithelium (OBRPE) and the Bruch's membrane (BM), respectively. In this paper we propose a novel multi-decoder architecture that tackles drusen segmentation as a multitask problem. Instead of training a multiclass model for OBRPE/BM segmentation, we use one decoder per target class and an extra one aiming for the area between the layers. We also introduce connections between each class-specific branch and the additional decoder to increase the regularization effect of this surrogate task. We validated our approach on private/public data sets with 166 early/intermediate AMD Spectralis, and 200 AMD and control Bioptigen OCT volumes, respectively. Our method consistently outperformed several baselines in both layer and drusen segmentation evaluations.