 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Interplay of Convolutional Padding and Adversarial Robustness
Aug 12, 2023
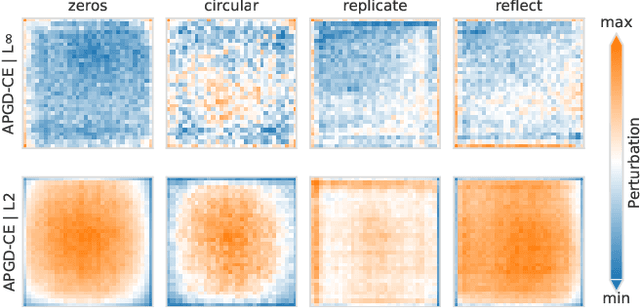
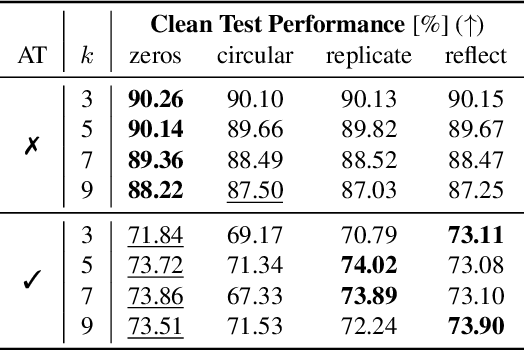

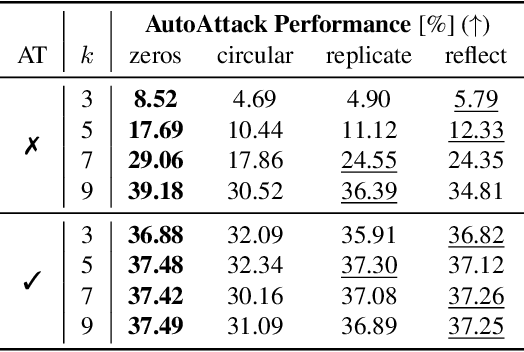
It is common practice to apply padding prior to convolution operations to preserve the resolution of feature-maps in Convolutional Neural Networks (CNN). While many alternatives exist, this is often achieved by adding a border of zeros around the inputs. In this work, we show that adversarial attacks often result in perturbation anomalies at the image boundaries, which are the areas where padding is used. Consequently, we aim to provide an analysis of the interplay between padding and adversarial attacks and seek an answer to the question of how different padding modes (or their absence) affect adversarial robustness in various scenarios.
Bridging the Gap: Exploring the Capabilities of Bridge-Architectures for Complex Visual Reasoning Tasks
Jul 31, 2023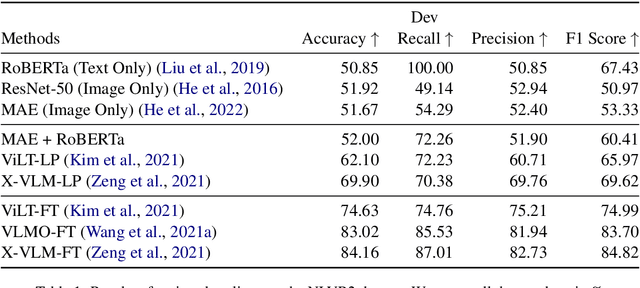
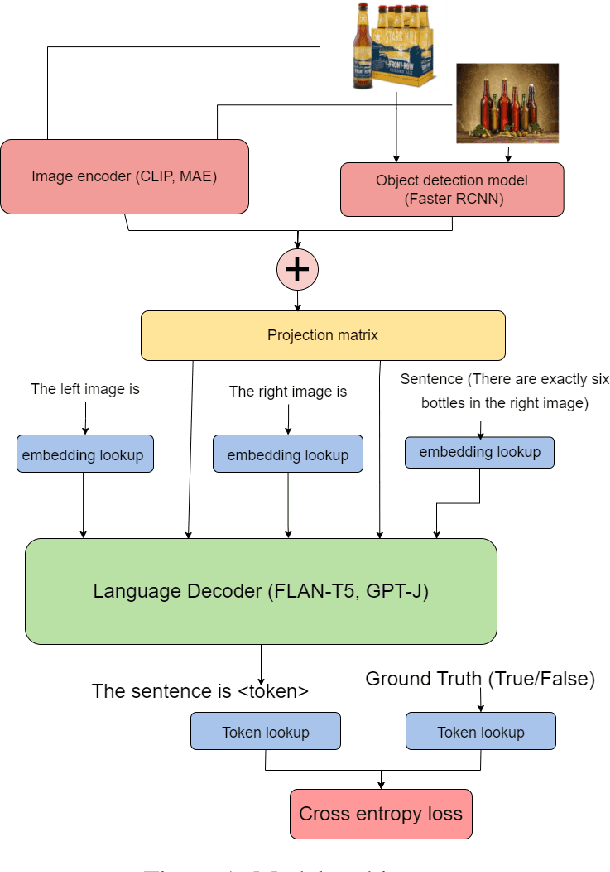
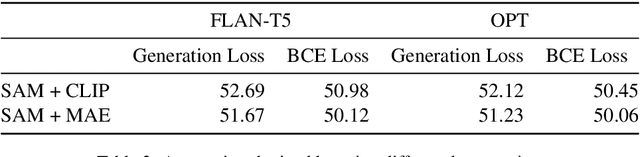
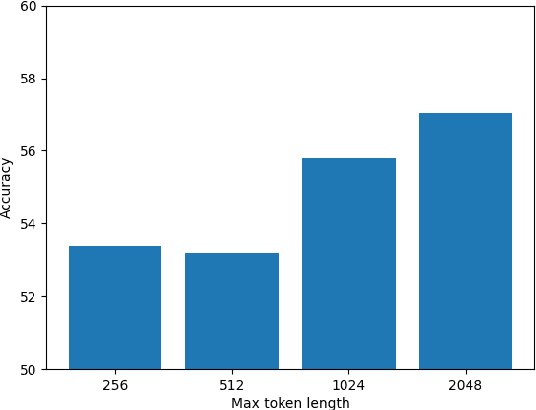
In recent times there has been a surge of multi-modal architectures based on Large Language Models, which leverage the zero shot generation capabilities of LLMs and project image embeddings into the text space and then use the auto-regressive capacity to solve tasks such as VQA, captioning, and image retrieval. We name these architectures as "bridge-architectures" as they project from the image space to the text space. These models deviate from the traditional recipe of training transformer based multi-modal models, which involve using large-scale pre-training and complex multi-modal interactions through co or cross attention. However, the capabilities of bridge architectures have not been tested on complex visual reasoning tasks which require fine grained analysis about the image. In this project, we investigate the performance of these bridge-architectures on the NLVR2 dataset, and compare it to state-of-the-art transformer based architectures. We first extend the traditional bridge architectures for the NLVR2 dataset, by adding object level features to faciliate fine-grained object reasoning. Our analysis shows that adding object level features to bridge architectures does not help, and that pre-training on multi-modal data is key for good performance on complex reasoning tasks such as NLVR2. We also demonstrate some initial results on a recently bridge-architecture, LLaVA, in the zero shot setting and analyze its performance.
FastSurfer-HypVINN: Automated sub-segmentation of the hypothalamus and adjacent structures on high-resolutional brain MRI
Aug 24, 2023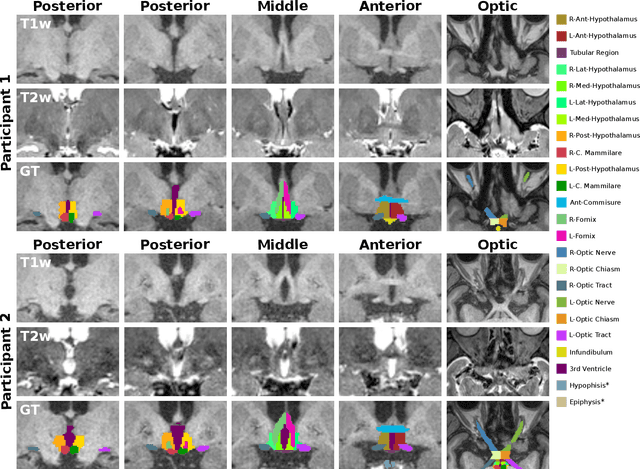
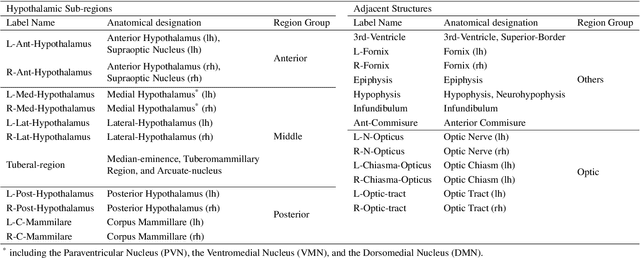
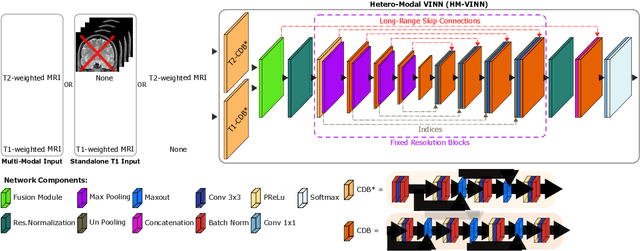
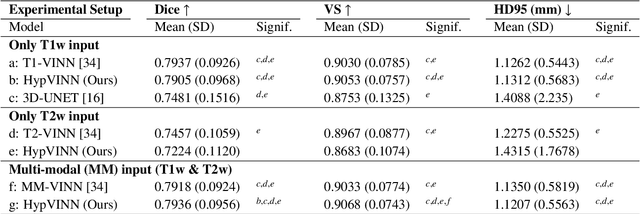
The hypothalamus plays a crucial role in the regulation of a broad range of physiological, behavioural, and cognitive functions. However, despite its importance, only a few small-scale neuroimaging studies have investigated its substructures, likely due to the lack of fully automated segmentation tools to address scalability and reproducibility issues of manual segmentation. While the only previous attempt to automatically sub-segment the hypothalamus with a neural network showed promise for 1.0 mm isotropic T1-weighted (T1w) MRI, there is a need for an automated tool to sub-segment also high-resolutional (HiRes) MR scans, as they are becoming widely available, and include structural detail also from multi-modal MRI. We, therefore, introduce a novel, fast, and fully automated deep learning method named HypVINN for sub-segmentation of the hypothalamus and adjacent structures on 0.8 mm isotropic T1w and T2w brain MR images that is robust to missing modalities. We extensively validate our model with respect to segmentation accuracy, generalizability, in-session test-retest reliability, and sensitivity to replicate hypothalamic volume effects (e.g. sex-differences). The proposed method exhibits high segmentation performance both for standalone T1w images as well as for T1w/T2w image pairs. Even with the additional capability to accept flexible inputs, our model matches or exceeds the performance of state-of-the-art methods with fixed inputs. We, further, demonstrate the generalizability of our method in experiments with 1.0 mm MR scans from both the Rhineland Study and the UK Biobank. Finally, HypVINN can perform the segmentation in less than a minute (GPU) and will be available in the open source FastSurfer neuroimaging software suite, offering a validated, efficient, and scalable solution for evaluating imaging-derived phenotypes of the hypothalamus.
HSR-Diff:Hyperspectral Image Super-Resolution via Conditional Diffusion Models
Jun 21, 2023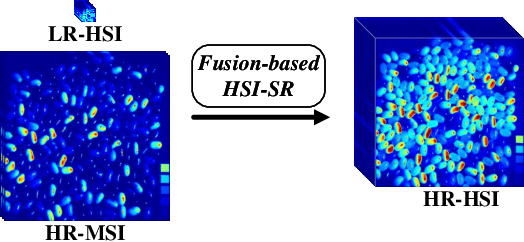
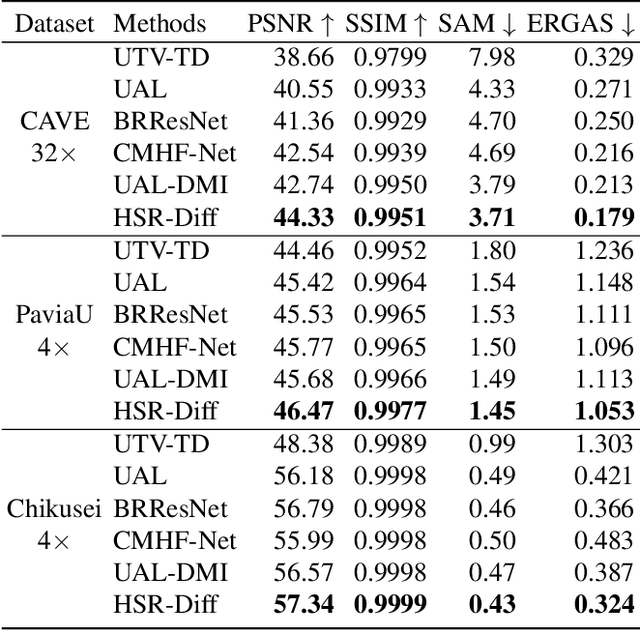
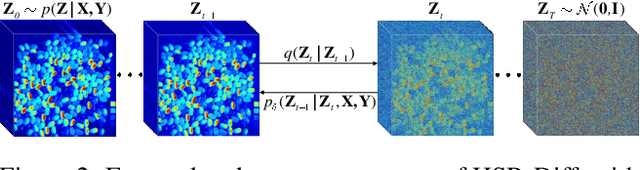
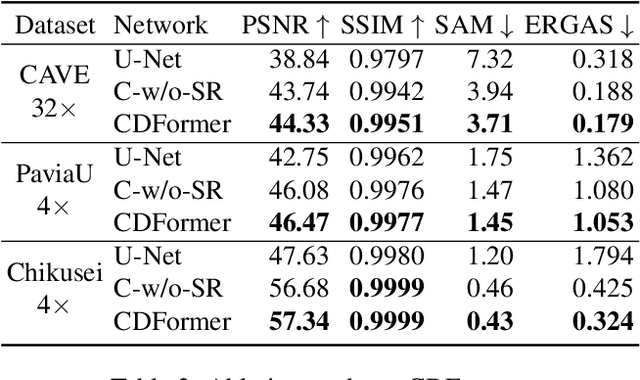
Despite the proven significance of hyperspectral images (HSIs) in performing various computer vision tasks, its potential is adversely affected by the low-resolution (LR) property in the spatial domain, resulting from multiple physical factors. Inspired by recent advancements in deep generative models, we propose an HSI Super-resolution (SR) approach with Conditional Diffusion Models (HSR-Diff) that merges a high-resolution (HR) multispectral image (MSI) with the corresponding LR-HSI. HSR-Diff generates an HR-HSI via repeated refinement, in which the HR-HSI is initialized with pure Gaussian noise and iteratively refined. At each iteration, the noise is removed with a Conditional Denoising Transformer (CDF ormer) that is trained on denoising at different noise levels, conditioned on the hierarchical feature maps of HR-MSI and LR-HSI. In addition, a progressive learning strategy is employed to exploit the global information of full-resolution images. Systematic experiments have been conducted on four public datasets, demonstrating that HSR-Diff outperforms state-of-the-art methods.
NeRFs: The Search for the Best 3D Representation
Aug 18, 2023
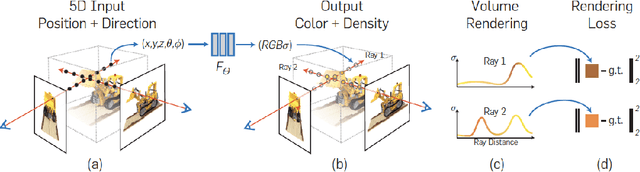

Neural Radiance Fields or NeRFs have become the representation of choice for problems in view synthesis or image-based rendering, as well as in many other applications across computer graphics and vision, and beyond. At their core, NeRFs describe a new representation of 3D scenes or 3D geometry. Instead of meshes, disparity maps, multiplane images or even voxel grids, they represent the scene as a continuous volume, with volumetric parameters like view-dependent radiance and volume density obtained by querying a neural network. The NeRF representation has now been widely used, with thousands of papers extending or building on it every year, multiple authors and websites providing overviews and surveys, and numerous industrial applications and startup companies. In this article, we briefly review the NeRF representation, and describe the three decades-long quest to find the best 3D representation for view synthesis and related problems, culminating in the NeRF papers. We then describe new developments in terms of NeRF representations and make some observations and insights regarding the future of 3D representations.
MATLABER: Material-Aware Text-to-3D via LAtent BRDF auto-EncodeR
Aug 18, 2023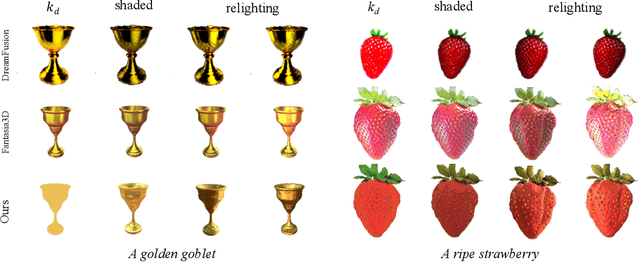
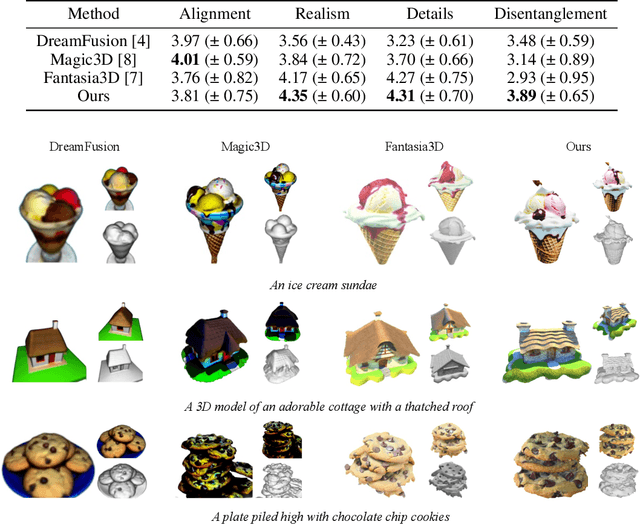
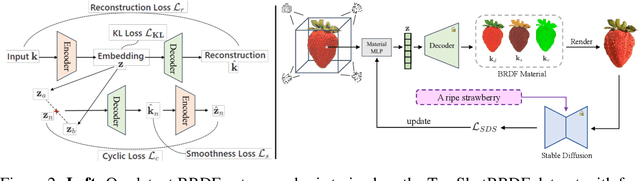
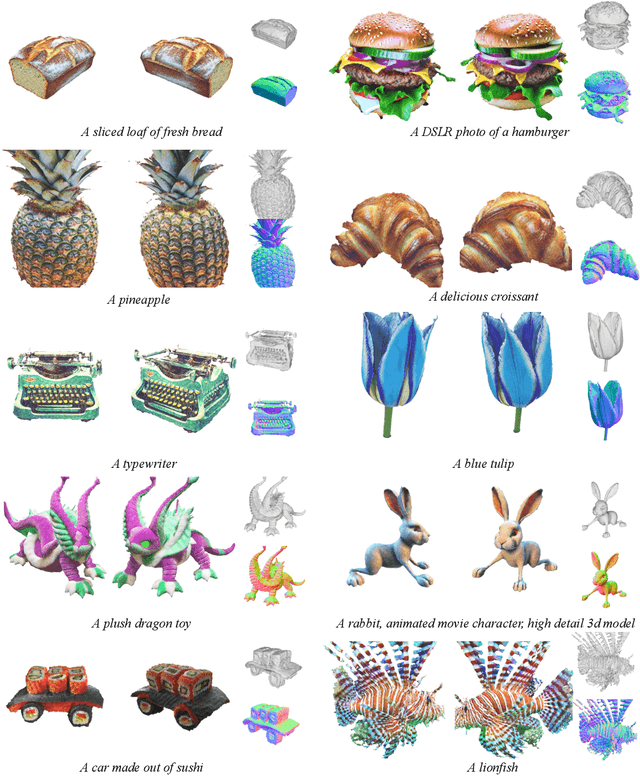
Based on powerful text-to-image diffusion models, text-to-3D generation has made significant progress in generating compelling geometry and appearance. However, existing methods still struggle to recover high-fidelity object materials, either only considering Lambertian reflectance, or failing to disentangle BRDF materials from the environment lights. In this work, we propose Material-Aware Text-to-3D via LAtent BRDF auto-EncodeR (\textbf{MATLABER}) that leverages a novel latent BRDF auto-encoder for material generation. We train this auto-encoder with large-scale real-world BRDF collections and ensure the smoothness of its latent space, which implicitly acts as a natural distribution of materials. During appearance modeling in text-to-3D generation, the latent BRDF embeddings, rather than BRDF parameters, are predicted via a material network. Through exhaustive experiments, our approach demonstrates the superiority over existing ones in generating realistic and coherent object materials. Moreover, high-quality materials naturally enable multiple downstream tasks such as relighting and material editing. Code and model will be publicly available at \url{https://sheldontsui.github.io/projects/Matlaber}.
MonoNeRD: NeRF-like Representations for Monocular 3D Object Detection
Aug 18, 2023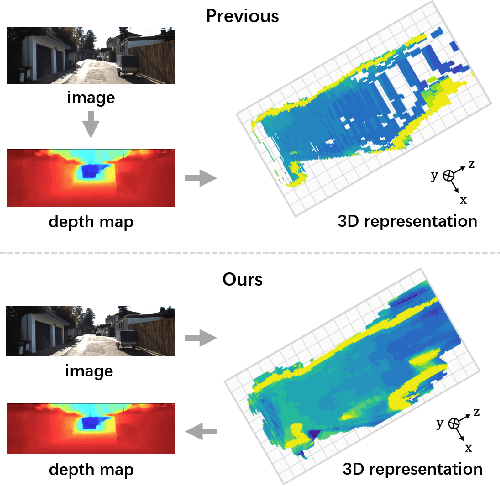

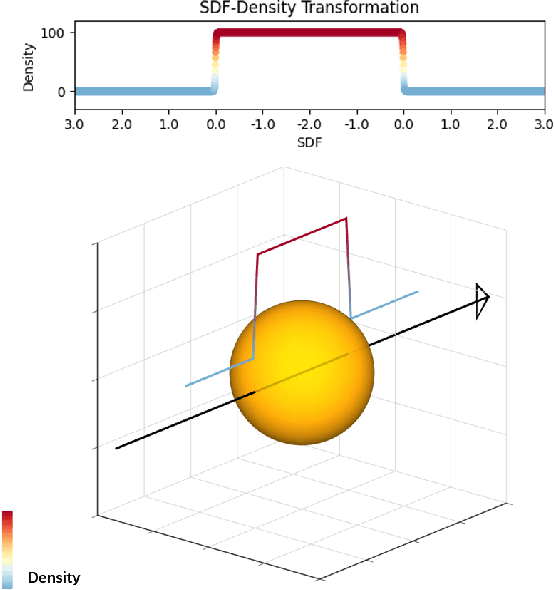
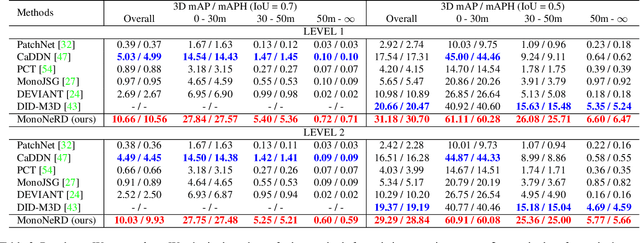
In the field of monocular 3D detection, it is common practice to utilize scene geometric clues to enhance the detector's performance. However, many existing works adopt these clues explicitly such as estimating a depth map and back-projecting it into 3D space. This explicit methodology induces sparsity in 3D representations due to the increased dimensionality from 2D to 3D, and leads to substantial information loss, especially for distant and occluded objects. To alleviate this issue, we propose MonoNeRD, a novel detection framework that can infer dense 3D geometry and occupancy. Specifically, we model scenes with Signed Distance Functions (SDF), facilitating the production of dense 3D representations. We treat these representations as Neural Radiance Fields (NeRF) and then employ volume rendering to recover RGB images and depth maps. To the best of our knowledge, this work is the first to introduce volume rendering for M3D, and demonstrates the potential of implicit reconstruction for image-based 3D perception. Extensive experiments conducted on the KITTI-3D benchmark and Waymo Open Dataset demonstrate the effectiveness of MonoNeRD. Codes are available at https://github.com/cskkxjk/MonoNeRD.
Latent State Models of Training Dynamics
Aug 18, 2023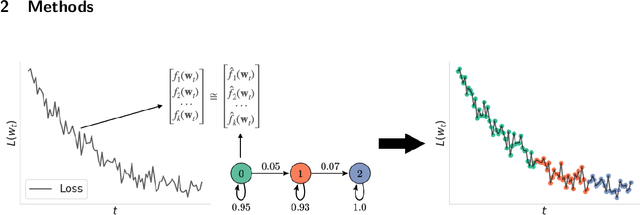
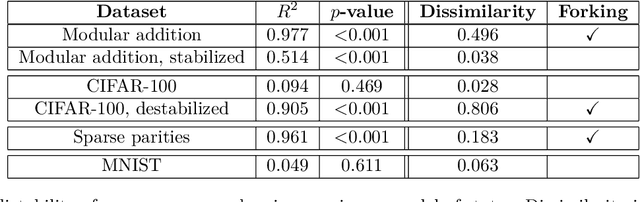
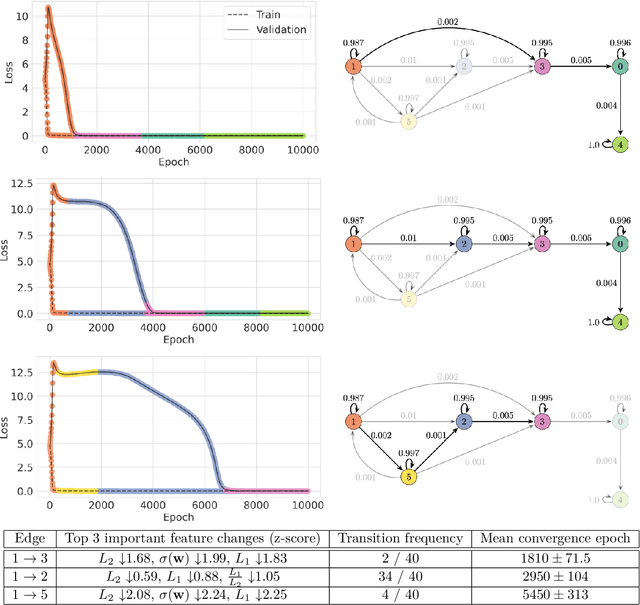
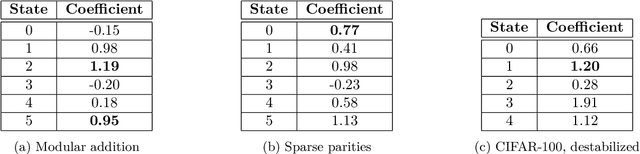
The impact of randomness on model training is poorly understood. How do differences in data order and initialization actually manifest in the model, such that some training runs outperform others or converge faster? Furthermore, how can we interpret the resulting training dynamics and the phase transitions that characterize different trajectories? To understand the effect of randomness on the dynamics and outcomes of neural network training, we train models multiple times with different random seeds and compute a variety of metrics throughout training, such as the $L_2$ norm, mean, and variance of the neural network's weights. We then fit a hidden Markov model (HMM) over the resulting sequences of metrics. The HMM represents training as a stochastic process of transitions between latent states, providing an intuitive overview of significant changes during training. Using our method, we produce a low-dimensional, discrete representation of training dynamics on grokking tasks, image classification, and masked language modeling. We use the HMM representation to study phase transitions and identify latent "detour" states that slow down convergence.
Towards Grounded Visual Spatial Reasoning in Multi-Modal Vision Language Models
Aug 18, 2023
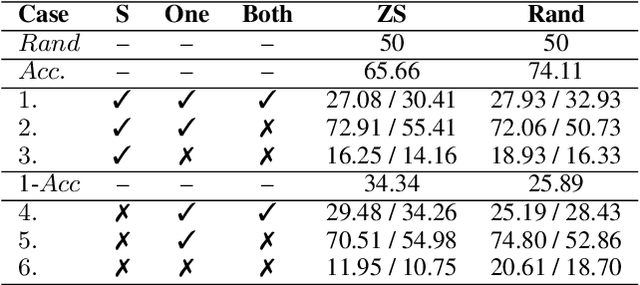

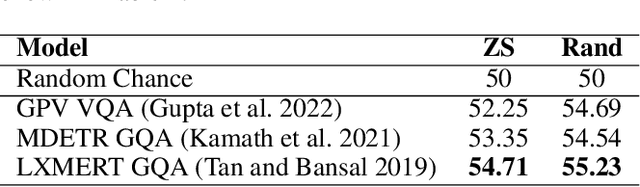
With the advances in large scale vision-and-language models (VLMs) it is of interest to assess their performance on various visual reasoning tasks such as counting, referring expressions and general visual question answering. The focus of this work is to study the ability of these models to understanding spatial relations. Previously, this has been tackled using image-text matching (Liu, Emerson, and Collier 2022) or visual question answering task, both showing poor performance and a large gap compared to human performance. To better understand the gap, we present fine-grained compositional grounding of spatial relationships and propose a bottom up approach for ranking spatial clauses and evaluating the performance of spatial relationship reasoning task. We propose to combine the evidence from grounding noun phrases corresponding to objects and their locations to compute the final rank of the spatial clause. We demonstrate the approach on representative vision-language models (Tan and Bansal 2019; Gupta et al. 2022; Kamath et al. 2021) and compare and highlight their abilities to reason about spatial relationships.
Automated mapping of virtual environments with visual predictive coding
Aug 20, 2023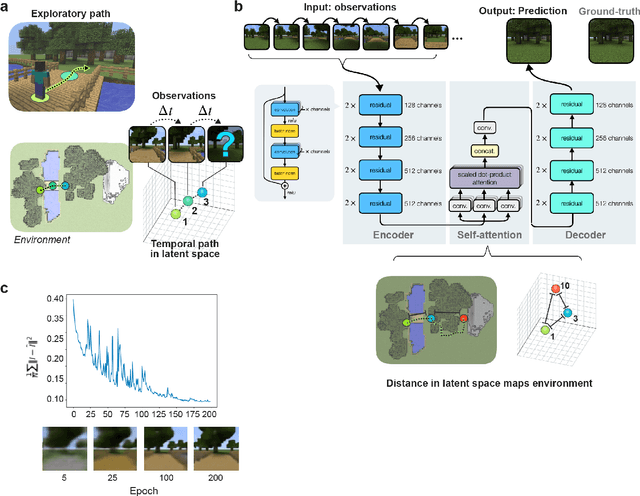
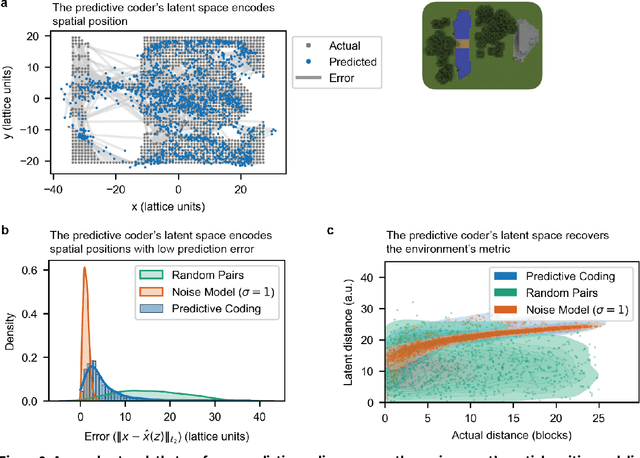
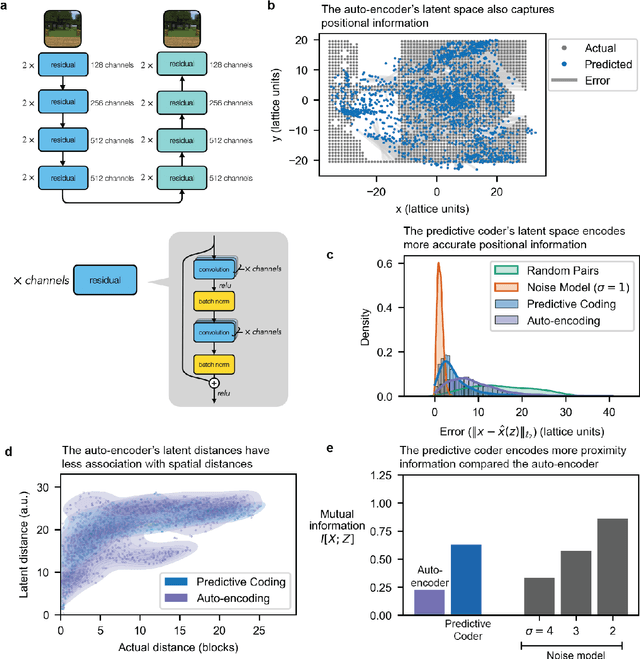
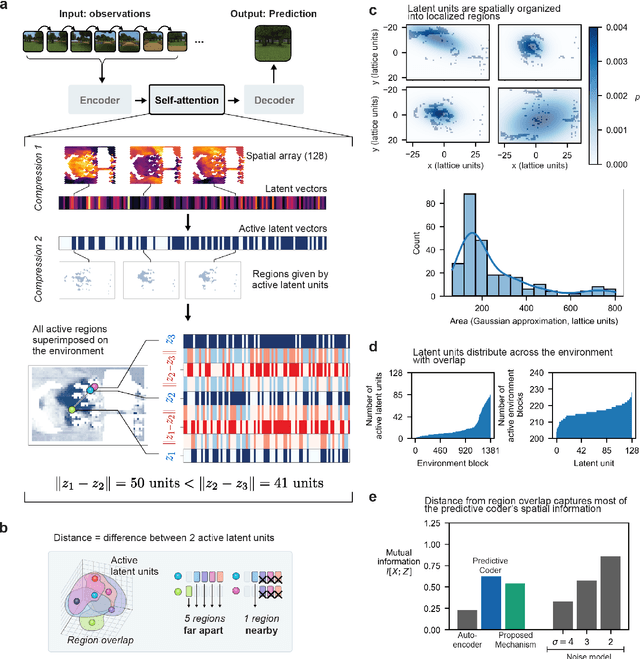
Humans construct internal cognitive maps of their environment directly from sensory inputs without access to a system of explicit coordinates or distance measurements. While machine learning algorithms like SLAM utilize specialized visual inference procedures to identify visual features and construct spatial maps from visual and odometry data, the general nature of cognitive maps in the brain suggests a unified mapping algorithmic strategy that can generalize to auditory, tactile, and linguistic inputs. Here, we demonstrate that predictive coding provides a natural and versatile neural network algorithm for constructing spatial maps using sensory data. We introduce a framework in which an agent navigates a virtual environment while engaging in visual predictive coding using a self-attention-equipped convolutional neural network. While learning a next image prediction task, the agent automatically constructs an internal representation of the environment that quantitatively reflects distances. The internal map enables the agent to pinpoint its location relative to landmarks using only visual information.The predictive coding network generates a vectorized encoding of the environment that supports vector navigation where individual latent space units delineate localized, overlapping neighborhoods in the environment. Broadly, our work introduces predictive coding as a unified algorithmic framework for constructing cognitive maps that can naturally extend to the mapping of auditory, sensorimotor, and linguistic inputs.