 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRAVEL: Training-Free Retrieval and Alignment for Vision-and-Language Navigation
Feb 11, 2025



In this work, we propose a modular approach for the Vision-Language Navigation (VLN) task by decomposing the problem into four sub-modules that use state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs) in a zero-shot setting. Given navigation instruction in natural language, we first prompt LLM to extract the landmarks and the order in which they are visited. Assuming the known model of the environment, we retrieve the top-k locations of the last landmark and generate $k$ path hypotheses from the starting location to the last landmark using the shortest path algorithm on the topological map of the environment. Each path hypothesis is represented by a sequence of panoramas. We then use dynamic programming to compute the alignment score between the sequence of panoramas and the sequence of landmark names, which match scores obtained from VLM. Finally, we compute the nDTW metric between the hypothesis that yields the highest alignment score to evaluate the path fidelity. We demonstrate superior performance compared to other approaches that use joint semantic maps like VLMaps \cite{vlmaps} on the complex R2R-Habitat \cite{r2r} instruction dataset and quantify in detail the effect of visual grounding on navigation performance.
GSR-BENCH: A Benchmark for Grounded Spatial Reasoning Evaluation via Multimodal LLMs
Jun 19, 2024



The ability to understand and reason about spatial relationships between objects in images is an important component of visual reasoning. This skill rests on the ability to recognize and localize objects of interest and determine their spatial relation. Early vision and language models (VLMs) have been shown to struggle to recognize spatial relations. We extend the previously released What'sUp dataset and propose a novel comprehensive evaluation for spatial relationship understanding that highlights the strengths and weaknesses of 27 different models. In addition to the VLMs evaluated in What'sUp, our extensive evaluation encompasses 3 classes of Multimodal LLMs (MLLMs) that vary in their parameter sizes (ranging from 7B to 110B), training/instruction-tuning methods, and visual resolution to benchmark their performances and scrutinize the scaling laws in this task.
Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
Apr 29, 2024



Vision and Language Models (VLMs) continue to demonstrate remarkable zero-shot (ZS) performance across various tasks. However, many probing studies have revealed that even the best-performing VLMs struggle to capture aspects of compositional scene understanding, lacking the ability to properly ground and localize linguistic phrases in images. Recent VLM advancements include scaling up both model and dataset sizes, additional training objectives and levels of supervision, and variations in the model architectures. To characterize the grounding ability of VLMs, such as phrase grounding, referring expressions comprehension, and relationship understanding, Pointing Game has been used as an evaluation metric for datasets with bounding box annotations. In this paper, we introduce a novel suite of quantitative metrics that utilize GradCAM activations to rigorously evaluate the grounding capabilities of pre-trained VLMs like CLIP, BLIP, and ALBEF. These metrics offer an explainable and quantifiable approach for a more detailed comparison of the zero-shot capabilities of VLMs and enable measuring models' grounding uncertainty. This characterization reveals interesting tradeoffs between the size of the model, the dataset size, and their performance.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
Towards Grounded Visual Spatial Reasoning in Multi-Modal Vision Language Models
Aug 18, 2023



With the advances in large scale vision-and-language models (VLMs) it is of interest to assess their performance on various visual reasoning tasks such as counting, referring expressions and general visual question answering. The focus of this work is to study the ability of these models to understanding spatial relations. Previously, this has been tackled using image-text matching (Liu, Emerson, and Collier 2022) or visual question answering task, both showing poor performance and a large gap compared to human performance. To better understand the gap, we present fine-grained compositional grounding of spatial relationships and propose a bottom up approach for ranking spatial clauses and evaluating the performance of spatial relationship reasoning task. We propose to combine the evidence from grounding noun phrases corresponding to objects and their locations to compute the final rank of the spatial clause. We demonstrate the approach on representative vision-language models (Tan and Bansal 2019; Gupta et al. 2022; Kamath et al. 2021) and compare and highlight their abilities to reason about spatial relationships.
Towards More Equitable Question Answering Systems: How Much More Data Do You Need?
May 28, 2021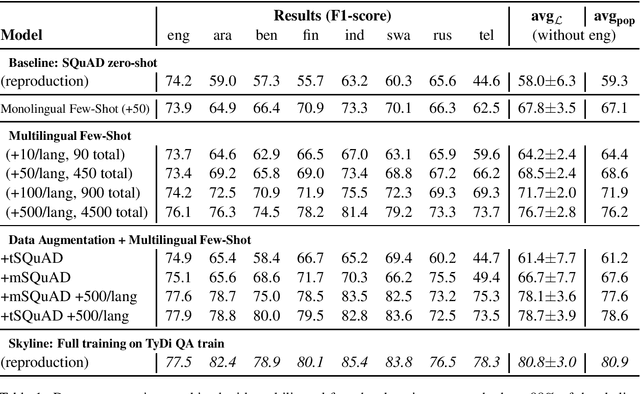
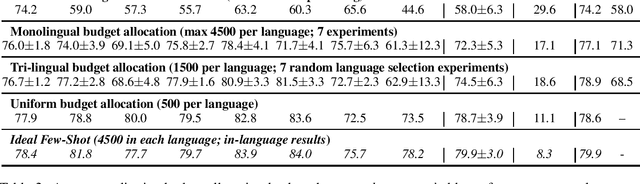

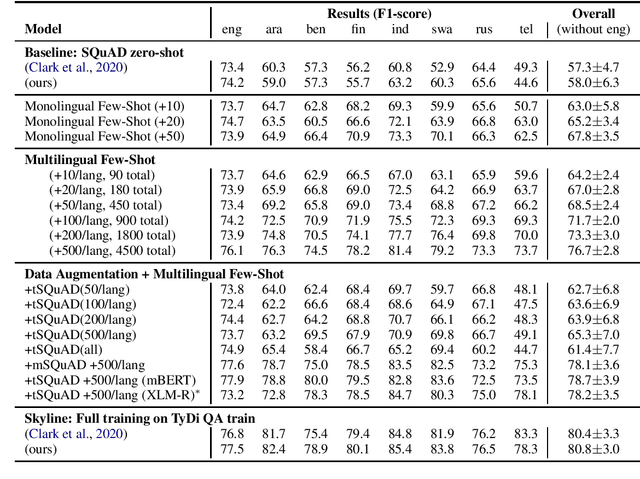
Question answering (QA) in English has been widely explored, but multilingual datasets are relatively new, with several methods attempting to bridge the gap between high- and low-resourced languages using data augmentation through translation and cross-lingual transfer. In this project, we take a step back and study which approaches allow us to take the most advantage of existing resources in order to produce QA systems in many languages. Specifically, we perform extensive analysis to measure the efficacy of few-shot approaches augmented with automatic translations and permutations of context-question-answer pairs. In addition, we make suggestions for future dataset development efforts that make better use of a fixed annotation budget, with a goal of increasing the language coverage of QA datasets and systems. Code and data for reproducing our experiments are available here: https://github.com/NavidRajabi/EMQA.