 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Neural Scaling Laws
Jan 27, 2026Neural scaling laws predict how language model performance improves with increased compute. While aggregate metrics like validation loss can follow smooth power-law curves, individual downstream tasks exhibit diverse scaling behaviors: some improve monotonically, others plateau, and some even degrade with scale. We argue that predicting downstream performance from validation perplexity suffers from two limitations: averaging token-level losses obscures signal, and no simple parametric family can capture the full spectrum of scaling behaviors. To address this, we propose Neural Neural Scaling Laws (NeuNeu), a neural network that frames scaling law prediction as time-series extrapolation. NeuNeu combines temporal context from observed accuracy trajectories with token-level validation losses, learning to predict future performance without assuming any bottleneck or functional form. Trained entirely on open-source model checkpoints from HuggingFace, NeuNeu achieves 2.04% mean absolute error in predicting model accuracy on 66 downstream tasks -- a 38% reduction compared to logistic scaling laws (3.29% MAE). Furthermore, NeuNeu generalizes zero-shot to unseen model families, parameter counts, and downstream tasks. Our work suggests that predicting downstream scaling laws directly from data outperforms parametric alternatives.
Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check
Jul 01, 2025Downstream scaling laws aim to predict task performance at larger scales from pretraining losses at smaller scales. Whether this prediction should be possible is unclear: some works demonstrate that task performance follows clear linear scaling trends under transformation, whereas others point out fundamental challenges to downstream scaling laws, such as emergence and inverse scaling. In this work, we conduct a meta-analysis of existing data on downstream scaling laws, finding that close fit to linear scaling laws only occurs in a minority of cases: 39% of the time. Furthermore, seemingly benign changes to the experimental setting can completely change the scaling trend. Our analysis underscores the need to understand the conditions under which scaling laws succeed. To fully model the relationship between pretraining loss and downstream task performance, we must embrace the cases in which scaling behavior deviates from linear trends.
RELIC: Evaluating Compositional Instruction Following via Language Recognition
Jun 05, 2025Large language models (LLMs) are increasingly expected to perform tasks based only on a specification of the task provided in context, without examples of inputs and outputs; this ability is referred to as instruction following. We introduce the Recognition of Languages In-Context (RELIC) framework to evaluate instruction following using language recognition: the task of determining if a string is generated by formal grammar. Unlike many standard evaluations of LLMs' ability to use their context, this task requires composing together a large number of instructions (grammar productions) retrieved from the context. Because the languages are synthetic, the task can be increased in complexity as LLMs' skills improve, and new instances can be automatically generated, mitigating data contamination. We evaluate state-of-the-art LLMs on RELIC and find that their accuracy can be reliably predicted from the complexity of the grammar and the individual example strings, and that even the most advanced LLMs currently available show near-chance performance on more complex grammars and samples, in line with theoretical expectations. We also use RELIC to diagnose how LLMs attempt to solve increasingly difficult reasoning tasks, finding that as the complexity of the language recognition task increases, models switch to relying on shallow heuristics instead of following complex instructions.
Between Circuits and Chomsky: Pre-pretraining on Formal Languages Imparts Linguistic Biases
Feb 26, 2025



Pretraining language models on formal languages can improve their acquisition of natural language, but it is unclear which features of the formal language impart an inductive bias that leads to effective transfer. Drawing on insights from linguistics and complexity theory, we hypothesize that effective transfer occurs when the formal language both captures dependency structures in natural language and remains within the computational limitations of the model architecture. Focusing on transformers, we find that formal languages with both these properties enable language models to achieve lower loss on natural language and better linguistic generalization compared to other languages. In fact, pre-pretraining, or training on formal-then-natural language, reduces loss more efficiently than the same amount of natural language. For a 1B-parameter language model trained on roughly 1.6B tokens of natural language, pre-pretraining achieves the same loss and better linguistic generalization with a 33% smaller token budget. We also give mechanistic evidence of cross-task transfer from formal to natural language: attention heads acquired during formal language pretraining remain crucial for the model's performance on syntactic evaluations.
Findings of the Second BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Dec 06, 2024The BabyLM Challenge is a community effort to close the data-efficiency gap between human and computational language learners. Participants compete to optimize language model training on a fixed language data budget of 100 million words or less. This year, we released improved text corpora, as well as a vision-and-language corpus to facilitate research into cognitively plausible vision language models. Submissions were compared on evaluation tasks targeting grammatical ability, (visual) question answering, pragmatic abilities, and grounding, among other abilities. Participants could submit to a 10M-word text-only track, a 100M-word text-only track, and/or a 100M-word and image multimodal track. From 31 submissions employing diverse methods, a hybrid causal-masked language model architecture outperformed other approaches. No submissions outperformed the baselines in the multimodal track. In follow-up analyses, we found a strong relationship between training FLOPs and average performance across tasks, and that the best-performing submissions proposed changes to the training data, training objective, and model architecture. This year's BabyLM Challenge shows that there is still significant room for innovation in this setting, in particular for image-text modeling, but community-driven research can yield actionable insights about effective strategies for small-scale language modeling.
Aioli: A Unified Optimization Framework for Language Model Data Mixing
Nov 08, 2024



Language model performance depends on identifying the optimal mixture of data groups to train on (e.g., law, code, math). Prior work has proposed a diverse set of methods to efficiently learn mixture proportions, ranging from fitting regression models over training runs to dynamically updating proportions throughout training. Surprisingly, we find that no existing method consistently outperforms a simple stratified sampling baseline in terms of average test perplexity per group. In this paper, we study the cause of this inconsistency by unifying existing methods into a standard optimization framework. We show that all methods set proportions to minimize total loss, subject to a method-specific mixing law -- an assumption on how loss is a function of mixture proportions. We find that existing parameterizations of mixing laws can express the true loss-proportion relationship empirically, but the methods themselves often set the mixing law parameters inaccurately, resulting in poor and inconsistent performance. Finally, we leverage the insights from our framework to derive a new online method named Aioli, which directly estimates the mixing law parameters throughout training and uses them to dynamically adjust proportions. Empirically, Aioli outperforms stratified sampling on 6 out of 6 datasets by an average of 0.28 test perplexity points, whereas existing methods fail to consistently beat stratified sampling, doing up to 6.9 points worse. Moreover, in a practical setting where proportions are learned on shorter runs due to computational constraints, Aioli can dynamically adjust these proportions over the full training run, consistently improving performance over existing methods by up to 12.01 test perplexity points.
[Call for Papers] The 2nd BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
Apr 09, 2024![Figure 1 for [Call for Papers] The 2nd BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F6c552d900eadfcedce23c16cbd70fdf6d3024125%2F3-Table1-1.png&w=640&q=75)
After last year's successful BabyLM Challenge, the competition will be hosted again in 2024/2025. The overarching goals of the challenge remain the same; however, some of the competition rules will be different. The big changes for this year's competition are as follows: First, we replace the loose track with a paper track, which allows (for example) non-model-based submissions, novel cognitively-inspired benchmarks, or analysis techniques. Second, we are relaxing the rules around pretraining data, and will now allow participants to construct their own datasets provided they stay within the 100M-word or 10M-word budget. Third, we introduce a multimodal vision-and-language track, and will release a corpus of 50% text-only and 50% image-text multimodal data as a starting point for LM model training. The purpose of this CfP is to provide rules for this year's challenge, explain these rule changes and their rationale in greater detail, give a timeline of this year's competition, and provide answers to frequently asked questions from last year's challenge.
Comparing Abstraction in Humans and Large Language Models Using Multimodal Serial Reproduction
Feb 06, 2024



Humans extract useful abstractions of the world from noisy sensory data. Serial reproduction allows us to study how people construe the world through a paradigm similar to the game of telephone, where one person observes a stimulus and reproduces it for the next to form a chain of reproductions. Past serial reproduction experiments typically employ a single sensory modality, but humans often communicate abstractions of the world to each other through language. To investigate the effect language on the formation of abstractions, we implement a novel multimodal serial reproduction framework by asking people who receive a visual stimulus to reproduce it in a linguistic format, and vice versa. We ran unimodal and multimodal chains with both humans and GPT-4 and find that adding language as a modality has a larger effect on human reproductions than GPT-4's. This suggests human visual and linguistic representations are more dissociable than those of GPT-4.
Latent State Models of Training Dynamics
Aug 18, 2023



The impact of randomness on model training is poorly understood. How do differences in data order and initialization actually manifest in the model, such that some training runs outperform others or converge faster? Furthermore, how can we interpret the resulting training dynamics and the phase transitions that characterize different trajectories? To understand the effect of randomness on the dynamics and outcomes of neural network training, we train models multiple times with different random seeds and compute a variety of metrics throughout training, such as the $L_2$ norm, mean, and variance of the neural network's weights. We then fit a hidden Markov model (HMM) over the resulting sequences of metrics. The HMM represents training as a stochastic process of transitions between latent states, providing an intuitive overview of significant changes during training. Using our method, we produce a low-dimensional, discrete representation of training dynamics on grokking tasks, image classification, and masked language modeling. We use the HMM representation to study phase transitions and identify latent "detour" states that slow down convergence.
Using Natural Language and Program Abstractions to Instill Human Inductive Biases in Machines
May 23, 2022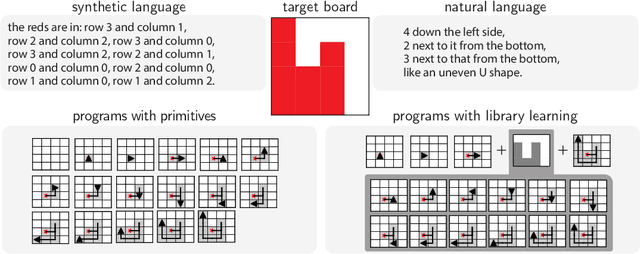
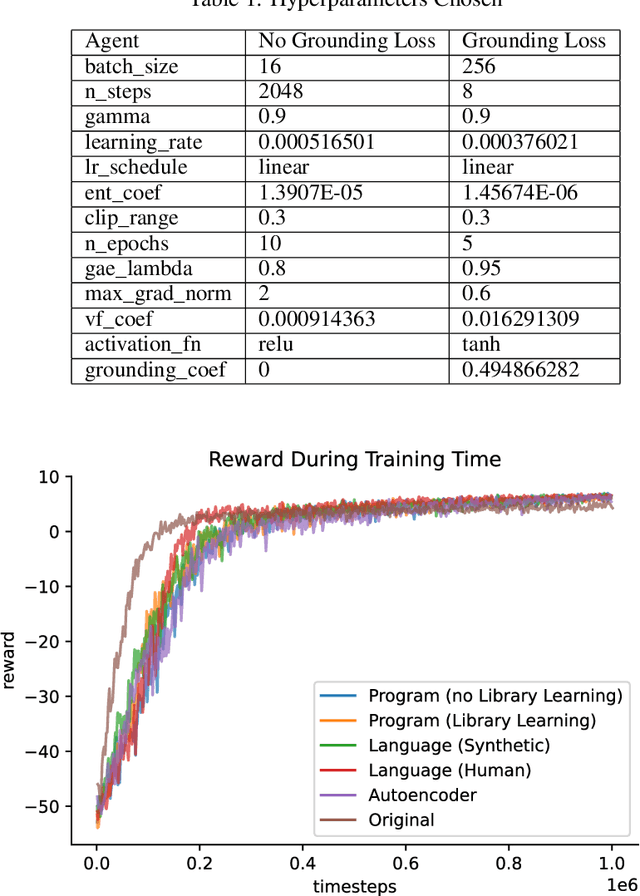
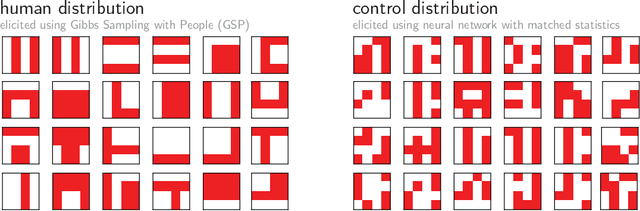
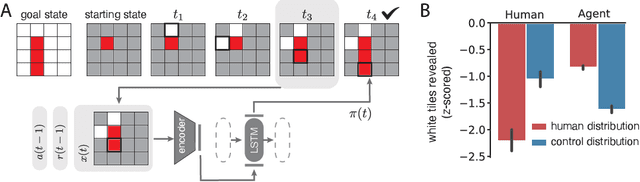
Strong inductive biases are a key component of human intelligence, allowing people to quickly learn a variety of tasks. Although meta-learning has emerged as an approach for endowing neural networks with useful inductive biases, agents trained by meta-learning may acquire very different strategies from humans. We show that co-training these agents on predicting representations from natural language task descriptions and from programs induced to generate such tasks guides them toward human-like inductive biases. Human-generated language descriptions and program induction with library learning both result in more human-like behavior in downstream meta-reinforcement learning agents than less abstract controls (synthetic language descriptions, program induction without library learning), suggesting that the abstraction supported by these representations is key.