 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Relational Concept Based Models
Aug 23, 2023
The design of interpretable deep learning models working in relational domains poses an open challenge: interpretable deep learning methods, such as Concept-Based Models (CBMs), are not designed to solve relational problems, while relational models are not as interpretable as CBMs. To address this problem, we propose Relational Concept-Based Models, a family of relational deep learning methods providing interpretable task predictions. Our experiments, ranging from image classification to link prediction in knowledge graphs, show that relational CBMs (i) match generalization performance of existing relational black-boxes (as opposed to non-relational CBMs), (ii) support the generation of quantified concept-based explanations, (iii) effectively respond to test-time interventions, and (iv) withstand demanding settings including out-of-distribution scenarios, limited training data regimes, and scarce concept supervisions.
InFusion: Inject and Attention Fusion for Multi Concept Zero-Shot Text-based Video Editing
Aug 10, 2023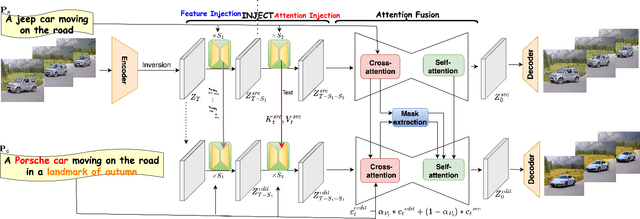
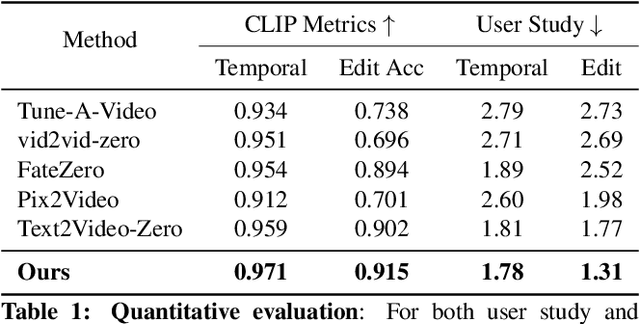
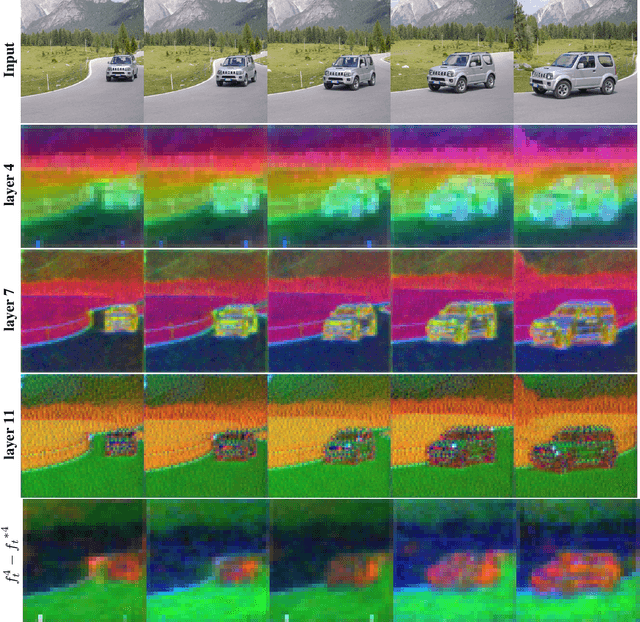
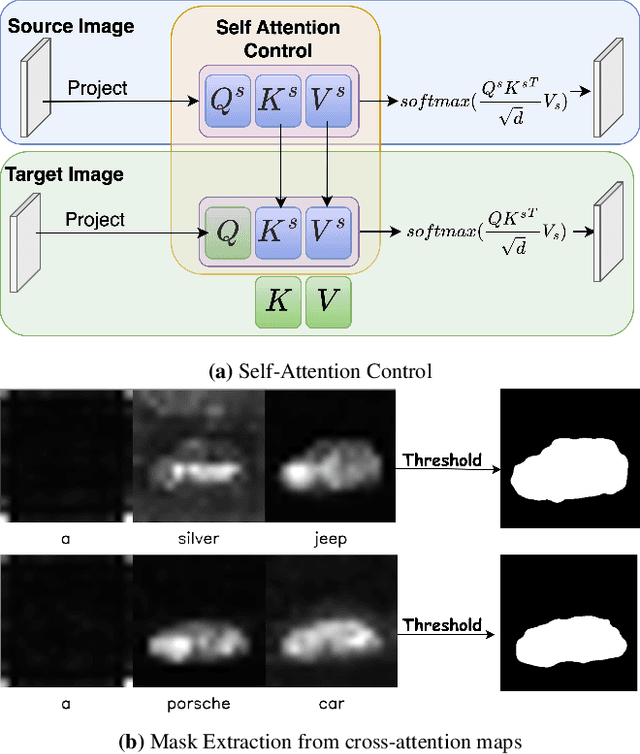
Large text-to-image diffusion models have achieved remarkable success in generating diverse, high-quality images. Additionally, these models have been successfully leveraged to edit input images by just changing the text prompt. But when these models are applied to videos, the main challenge is to ensure temporal consistency and coherence across frames. In this paper, we propose InFusion, a framework for zero-shot text-based video editing leveraging large pre-trained image diffusion models. Our framework specifically supports editing of multiple concepts with pixel-level control over diverse concepts mentioned in the editing prompt. Specifically, we inject the difference in features obtained with source and edit prompts from U-Net residual blocks of decoder layers. When these are combined with injected attention features, it becomes feasible to query the source contents and scale edited concepts along with the injection of unedited parts. The editing is further controlled in a fine-grained manner with mask extraction and attention fusion, which cut the edited part from the source and paste it into the denoising pipeline for the editing prompt. Our framework is a low-cost alternative to one-shot tuned models for editing since it does not require training. We demonstrated complex concept editing with a generalised image model (Stable Diffusion v1.5) using LoRA. Adaptation is compatible with all the existing image diffusion techniques. Extensive experimental results demonstrate the effectiveness of existing methods in rendering high-quality and temporally consistent videos.
Story Visualization by Online Text Augmentation with Context Memory
Aug 15, 2023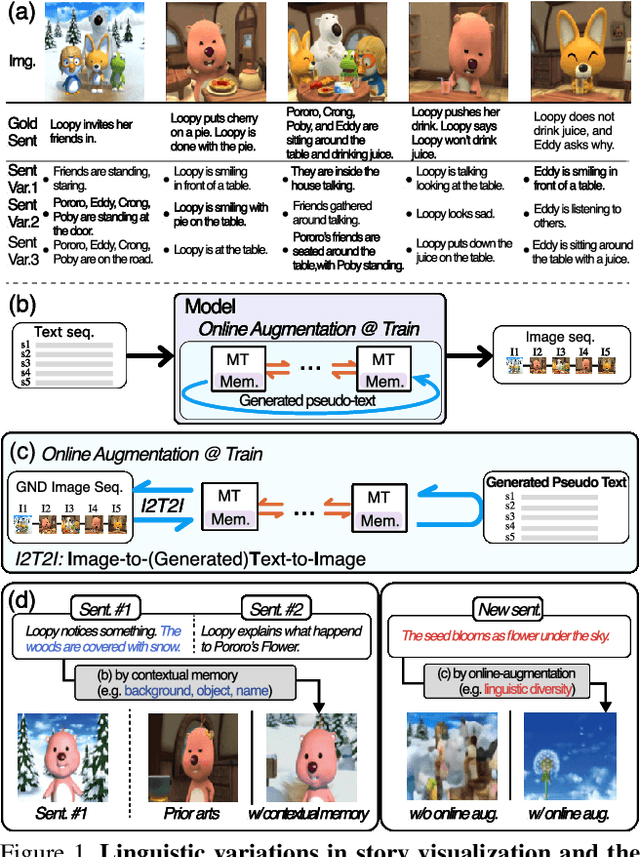
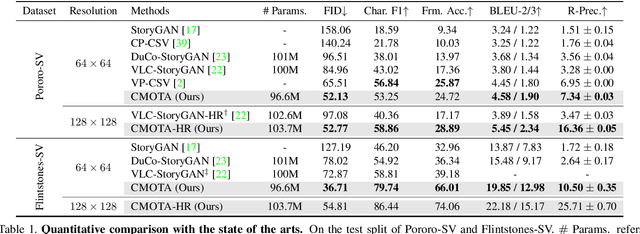
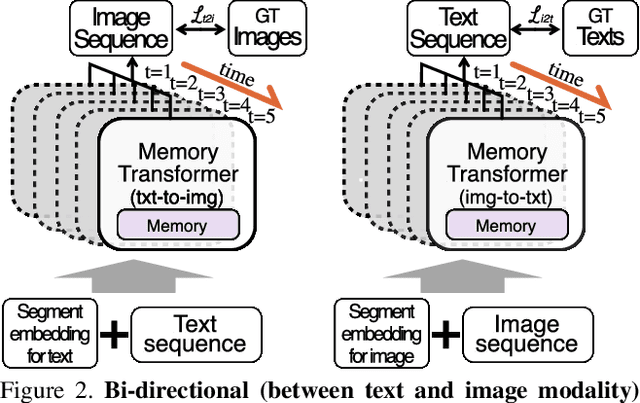
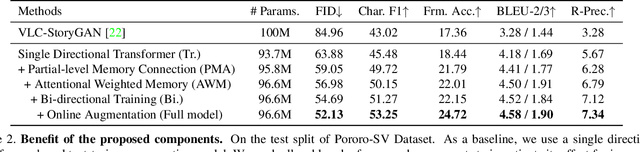
Story visualization (SV) is a challenging text-to-image generation task for the difficulty of not only rendering visual details from the text descriptions but also encoding a long-term context across multiple sentences. While prior efforts mostly focus on generating a semantically relevant image for each sentence, encoding a context spread across the given paragraph to generate contextually convincing images (e.g., with a correct character or with a proper background of the scene) remains a challenge. To this end, we propose a novel memory architecture for the Bi-directional Transformers with an online text augmentation that generates multiple pseudo-descriptions as supplementary supervision during training, for better generalization to the language variation at inference. In extensive experiments on the two popular SV benchmarks, i.e., the Pororo-SV and Flintstones-SV, the proposed method significantly outperforms the state of the arts in various evaluation metrics including FID, character F1, frame accuracy, BLEU-2/3, and R-precision with similar or less computational complexity.
GeoDTR+: Toward generic cross-view geolocalization via geometric disentanglement
Aug 18, 2023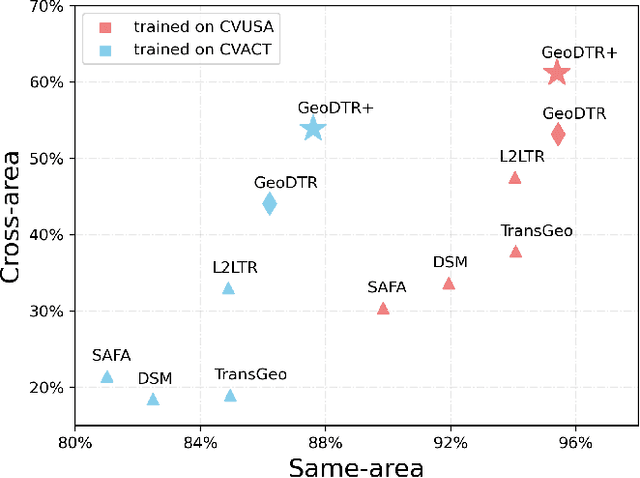
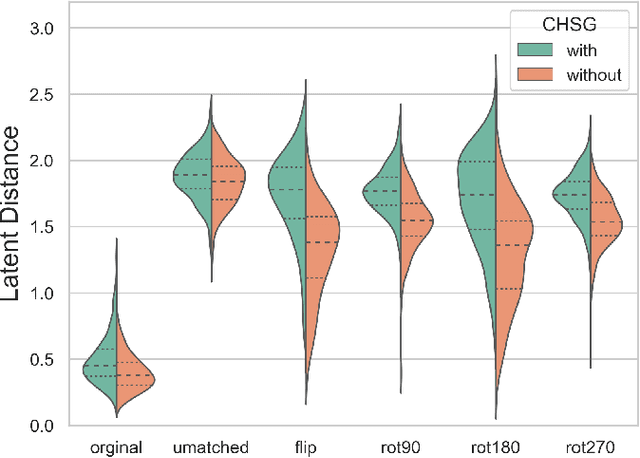
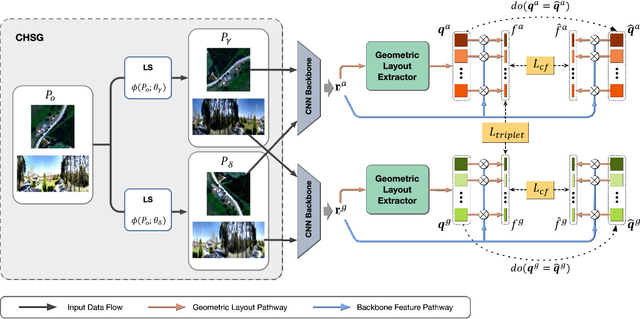
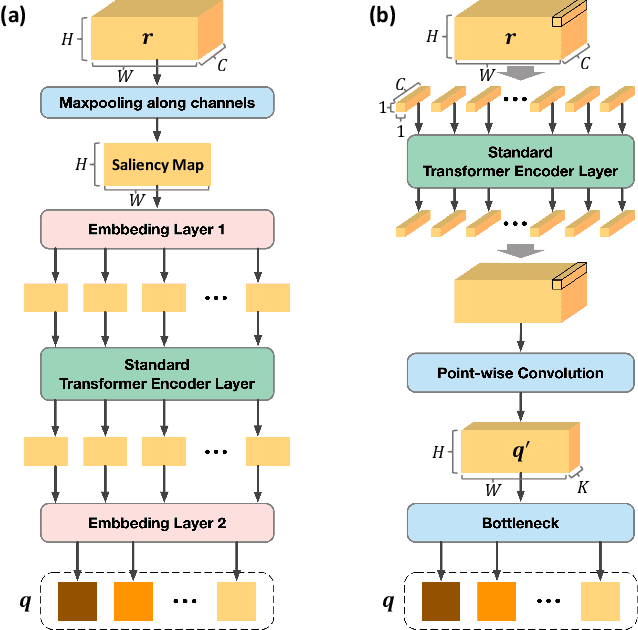
Cross-View Geo-Localization (CVGL) estimates the location of a ground image by matching it to a geo-tagged aerial image in a database. Recent works achieve outstanding progress on CVGL benchmarks. However, existing methods still suffer from poor performance in cross-area evaluation, in which the training and testing data are captured from completely distinct areas. We attribute this deficiency to the lack of ability to extract the geometric layout of visual features and models' overfitting to low-level details. Our preliminary work introduced a Geometric Layout Extractor (GLE) to capture the geometric layout from input features. However, the previous GLE does not fully exploit information in the input feature. In this work, we propose GeoDTR+ with an enhanced GLE module that better models the correlations among visual features. To fully explore the LS techniques from our preliminary work, we further propose Contrastive Hard Samples Generation (CHSG) to facilitate model training. Extensive experiments show that GeoDTR+ achieves state-of-the-art (SOTA) results in cross-area evaluation on CVUSA, CVACT, and VIGOR by a large margin ($16.44\%$, $22.71\%$, and $17.02\%$ without polar transformation) while keeping the same-area performance comparable to existing SOTA. Moreover, we provide detailed analyses of GeoDTR+.
Denoising Diffusion for 3D Hand Pose Estimation from Images
Aug 18, 2023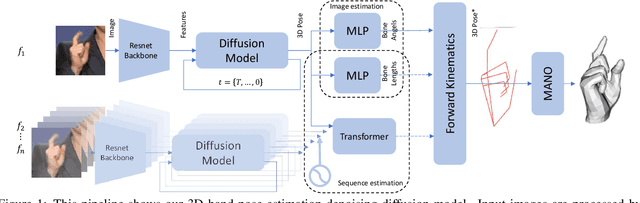
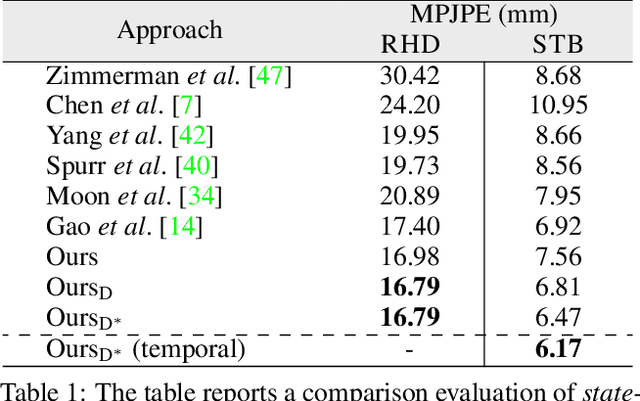
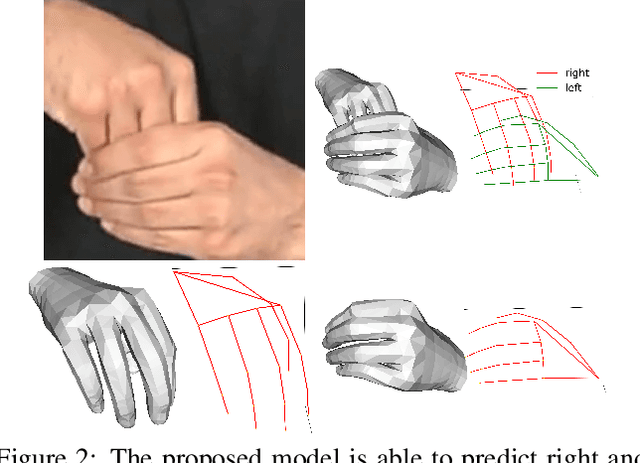
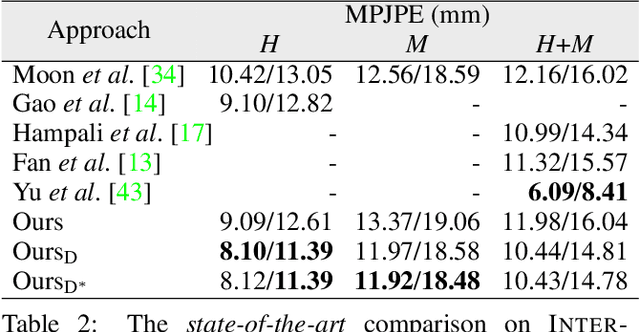
Hand pose estimation from a single image has many applications. However, approaches to full 3D body pose estimation are typically trained on day-to-day activities or actions. As such, detailed hand-to-hand interactions are poorly represented, especially during motion. We see this in the failure cases of techniques such as OpenPose or MediaPipe. However, accurate hand pose estimation is crucial for many applications where the global body motion is less important than accurate hand pose estimation. This paper addresses the problem of 3D hand pose estimation from monocular images or sequences. We present a novel end-to-end framework for 3D hand regression that employs diffusion models that have shown excellent ability to capture the distribution of data for generative purposes. Moreover, we enforce kinematic constraints to ensure realistic poses are generated by incorporating an explicit forward kinematic layer as part of the network. The proposed model provides state-of-the-art performance when lifting a 2D single-hand image to 3D. However, when sequence data is available, we add a Transformer module over a temporal window of consecutive frames to refine the results, overcoming jittering and further increasing accuracy. The method is quantitatively and qualitatively evaluated showing state-of-the-art robustness, generalization, and accuracy on several different datasets.
Stable and Causal Inference for Discriminative Self-supervised Deep Visual Representations
Aug 16, 2023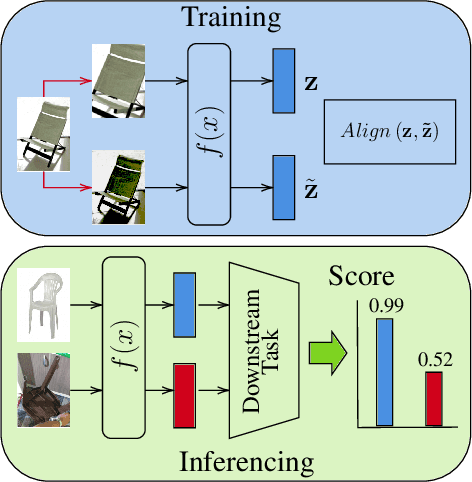
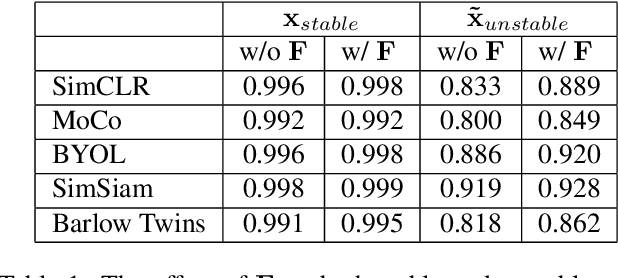
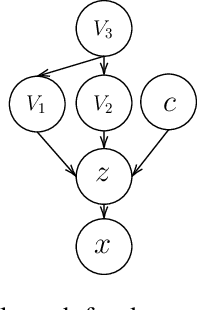
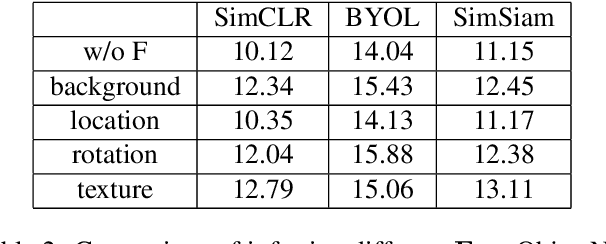
In recent years, discriminative self-supervised methods have made significant strides in advancing various visual tasks. The central idea of learning a data encoder that is robust to data distortions/augmentations is straightforward yet highly effective. Although many studies have demonstrated the empirical success of various learning methods, the resulting learned representations can exhibit instability and hinder downstream performance. In this study, we analyze discriminative self-supervised methods from a causal perspective to explain these unstable behaviors and propose solutions to overcome them. Our approach draws inspiration from prior works that empirically demonstrate the ability of discriminative self-supervised methods to demix ground truth causal sources to some extent. Unlike previous work on causality-empowered representation learning, we do not apply our solutions during the training process but rather during the inference process to improve time efficiency. Through experiments on both controlled image datasets and realistic image datasets, we show that our proposed solutions, which involve tempering a linear transformation with controlled synthetic data, are effective in addressing these issues.
Pro-Cap: Leveraging a Frozen Vision-Language Model for Hateful Meme Detection
Aug 16, 2023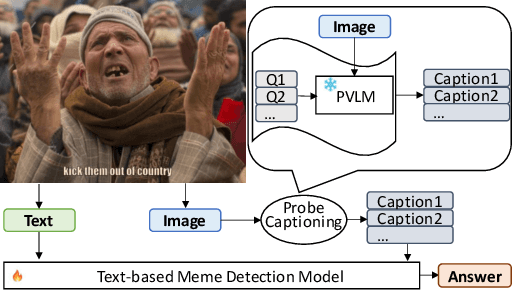
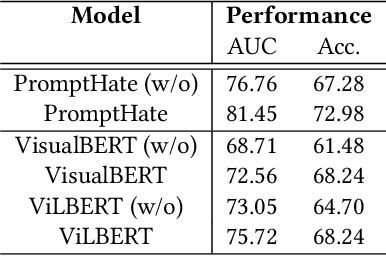

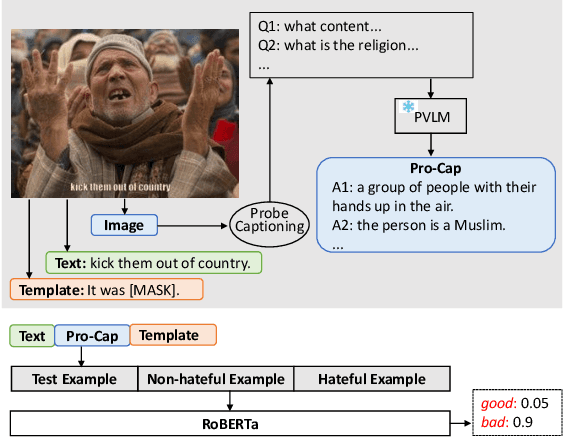
Hateful meme detection is a challenging multimodal task that requires comprehension of both vision and language, as well as cross-modal interactions. Recent studies have tried to fine-tune pre-trained vision-language models (PVLMs) for this task. However, with increasing model sizes, it becomes important to leverage powerful PVLMs more efficiently, rather than simply fine-tuning them. Recently, researchers have attempted to convert meme images into textual captions and prompt language models for predictions. This approach has shown good performance but suffers from non-informative image captions. Considering the two factors mentioned above, we propose a probing-based captioning approach to leverage PVLMs in a zero-shot visual question answering (VQA) manner. Specifically, we prompt a frozen PVLM by asking hateful content-related questions and use the answers as image captions (which we call Pro-Cap), so that the captions contain information critical for hateful content detection. The good performance of models with Pro-Cap on three benchmarks validates the effectiveness and generalization of the proposed method.
Text-Only Training for Visual Storytelling
Aug 17, 2023
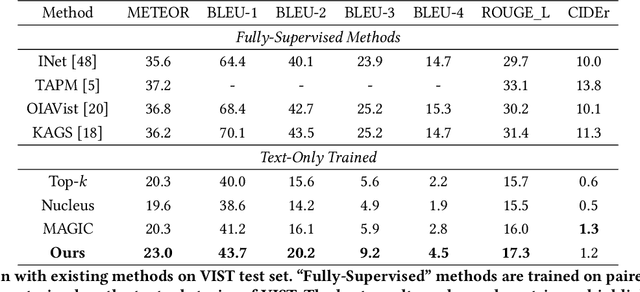
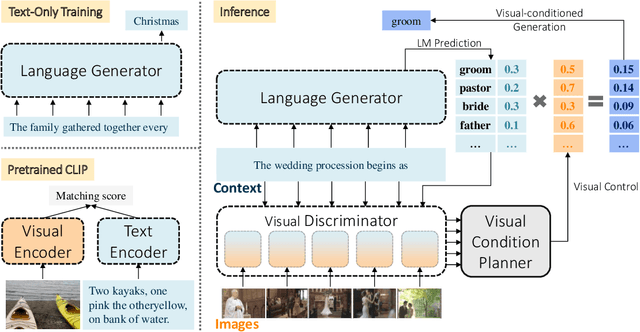
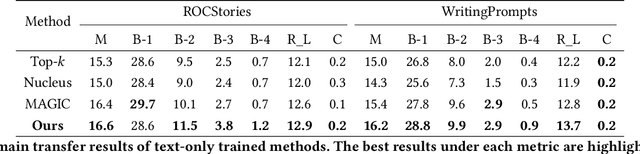
Visual storytelling aims to generate a narrative based on a sequence of images, necessitating both vision-language alignment and coherent story generation. Most existing solutions predominantly depend on paired image-text training data, which can be costly to collect and challenging to scale. To address this, we formulate visual storytelling as a visual-conditioned story generation problem and propose a text-only training method that separates the learning of cross-modality alignment and story generation. Our approach specifically leverages the cross-modality pre-trained CLIP model to integrate visual control into a story generator, trained exclusively on text data. Moreover, we devise a training-free visual condition planner that accounts for the temporal structure of the input image sequence while balancing global and local visual content. The distinctive advantage of requiring only text data for training enables our method to learn from external text story data, enhancing the generalization capability of visual storytelling. We conduct extensive experiments on the VIST benchmark, showcasing the effectiveness of our approach in both in-domain and cross-domain settings. Further evaluations on expression diversity and human assessment underscore the superiority of our method in terms of informativeness and robustness.
Introducing Language Guidance in Prompt-based Continual Learning
Aug 30, 2023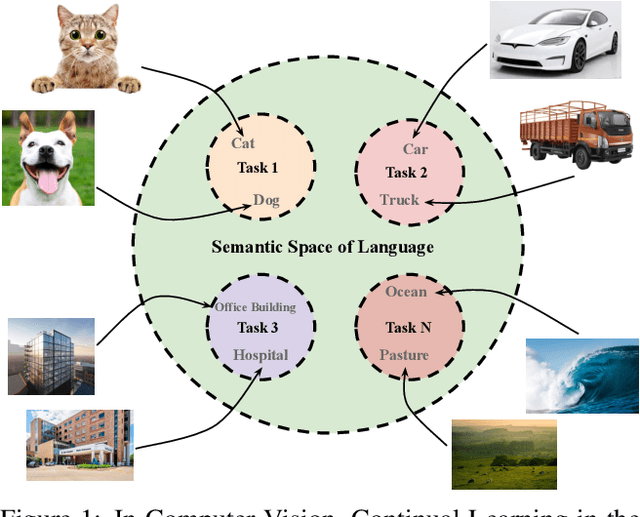
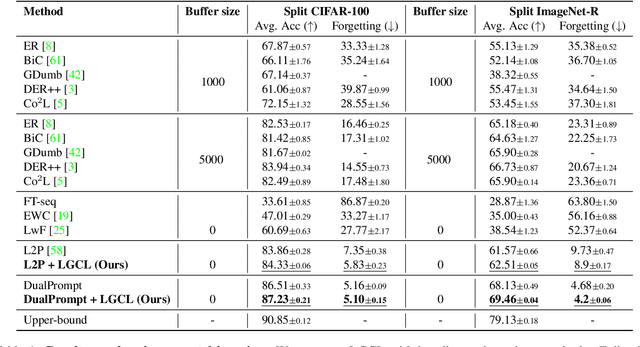
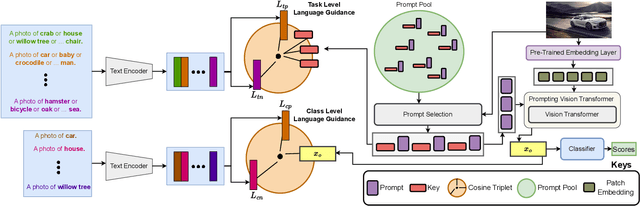
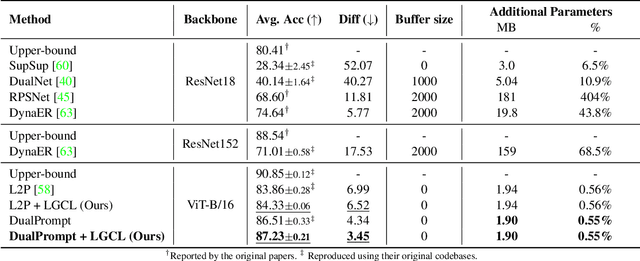
Continual Learning aims to learn a single model on a sequence of tasks without having access to data from previous tasks. The biggest challenge in the domain still remains catastrophic forgetting: a loss in performance on seen classes of earlier tasks. Some existing methods rely on an expensive replay buffer to store a chunk of data from previous tasks. This, while promising, becomes expensive when the number of tasks becomes large or data can not be stored for privacy reasons. As an alternative, prompt-based methods have been proposed that store the task information in a learnable prompt pool. This prompt pool instructs a frozen image encoder on how to solve each task. While the model faces a disjoint set of classes in each task in this setting, we argue that these classes can be encoded to the same embedding space of a pre-trained language encoder. In this work, we propose Language Guidance for Prompt-based Continual Learning (LGCL) as a plug-in for prompt-based methods. LGCL is model agnostic and introduces language guidance at the task level in the prompt pool and at the class level on the output feature of the vision encoder. We show with extensive experimentation that LGCL consistently improves the performance of prompt-based continual learning methods to set a new state-of-the art. LGCL achieves these performance improvements without needing any additional learnable parameters.
Knowledge Detection by Relevant Question and Image Attributes in Visual Question Answering
Jun 08, 2023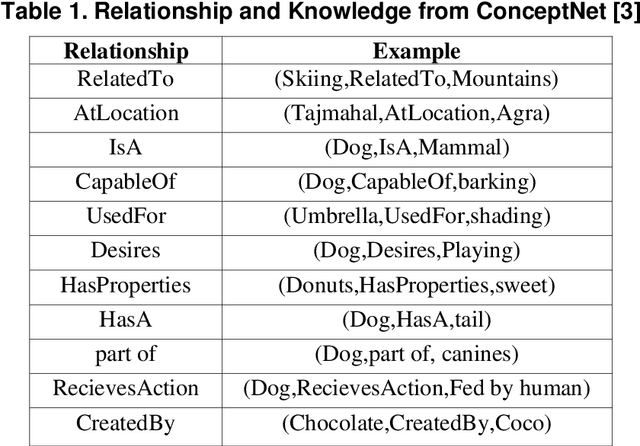
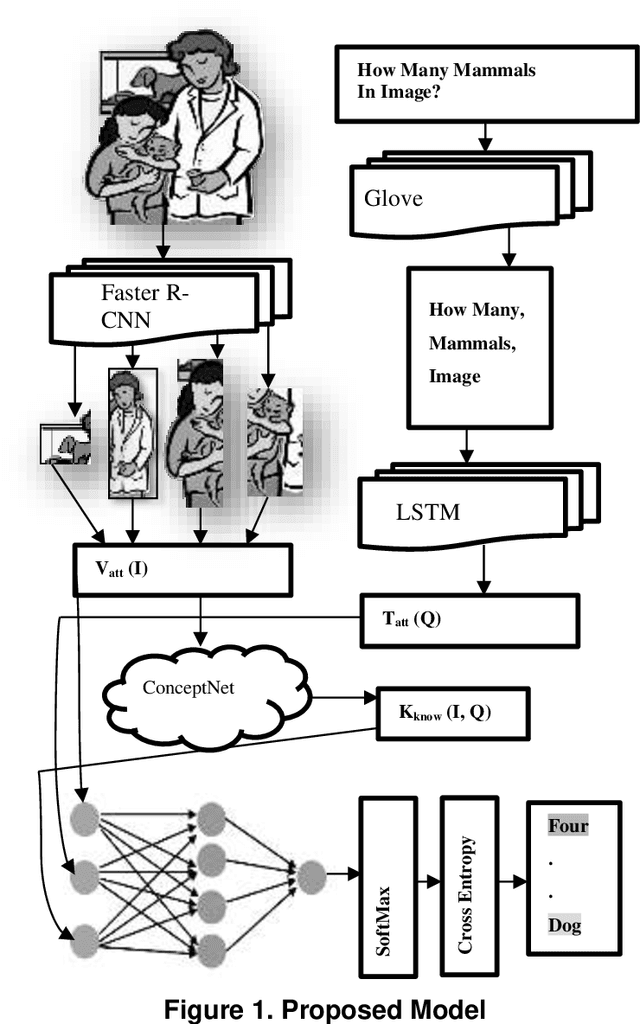
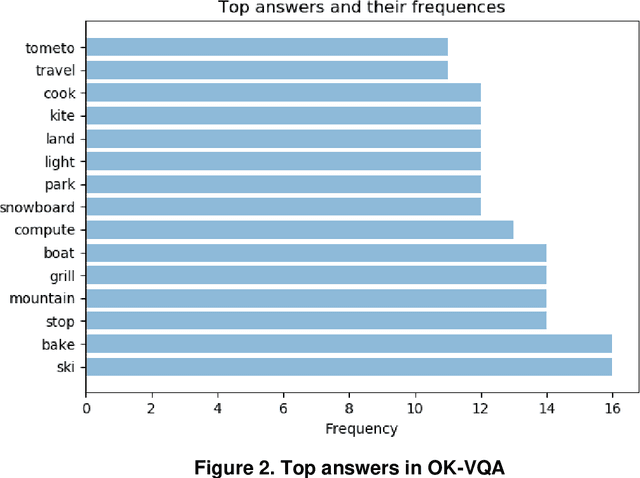
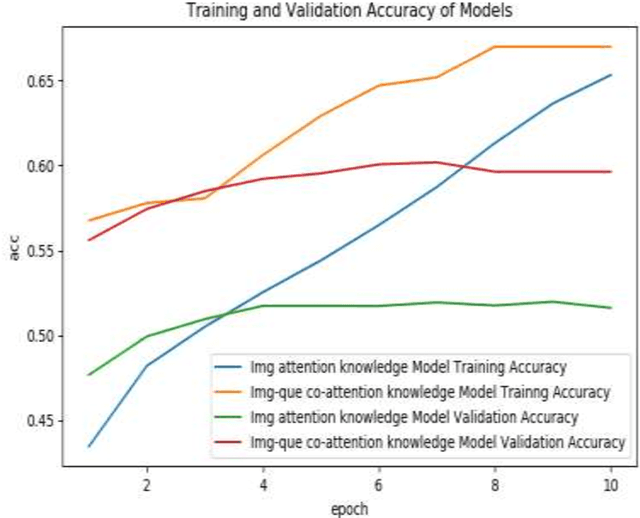
Visual question answering (VQA) is a Multidisciplinary research problem that pursued through practices of natural language processing and computer vision. Visual question answering automatically answers natural language questions according to the content of an image. Some testing questions require external knowledge to derive a solution. Such knowledge-based VQA uses various methods to retrieve features of image and text, and combine them to generate the answer. To generate knowledgebased answers either question dependent or image dependent knowledge retrieval methods are used. If knowledge about all the objects in the image is derived, then not all knowledge is relevant to the question. On other side only question related knowledge may lead to incorrect answers and over trained model that answers question that is irrelevant to image. Our proposed method takes image attributes and question features as input for knowledge derivation module and retrieves only question relevant knowledge about image objects which can provide accurate answers.