 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignSparK: Efficient Multilingual Sign Language Production via Sparse Keyframe Learning
Mar 12, 2026Generating natural and linguistically accurate sign language avatars remains a formidable challenge. Current Sign Language Production (SLP) frameworks face a stark trade-off: direct text-to-pose models suffer from regression-to-the-mean effects, while dictionary-retrieval methods produce robotic, disjointed transitions. To resolve this, we propose a novel training paradigm that leverages sparse keyframes to capture the true underlying kinematic distribution of human signing. By predicting dense motion from these discrete anchors, our approach mitigates regression-to-the-mean while ensuring fluid articulation. To realize this paradigm at scale, we first introduce FAST, an ultra-efficient sign segmentation model that automatically mines precise temporal boundaries. We then present SignSparK, a large-scale Conditional Flow Matching (CFM) framework that utilizes these extracted anchors to synthesize 3D signing sequences in SMPL-X and MANO spaces. This keyframe-driven formulation also uniquely unlocks Keyframe-to-Pose (KF2P) generation, making precise spatiotemporal editing of signing sequences possible. Furthermore, our adopted reconstruction-based CFM objective also enables high-fidelity synthesis in fewer than ten sampling steps; this allows SignSparK to scale across four distinct sign languages, establishing the largest multilingual SLP framework to date. Finally, by integrating 3D Gaussian Splatting for photorealistic rendering, we demonstrate through extensive evaluation that SignSparK establishes a new state-of-the-art across diverse SLP tasks and multilingual benchmarks.
Using Sign Language Production as Data Augmentation to enhance Sign Language Translation
Jun 11, 2025



Machine learning models fundamentally rely on large quantities of high-quality data. Collecting the necessary data for these models can be challenging due to cost, scarcity, and privacy restrictions. Signed languages are visual languages used by the deaf community and are considered low-resource languages. Sign language datasets are often orders of magnitude smaller than their spoken language counterparts. Sign Language Production is the task of generating sign language videos from spoken language sentences, while Sign Language Translation is the reverse translation task. Here, we propose leveraging recent advancements in Sign Language Production to augment existing sign language datasets and enhance the performance of Sign Language Translation models. For this, we utilize three techniques: a skeleton-based approach to production, sign stitching, and two photo-realistic generative models, SignGAN and SignSplat. We evaluate the effectiveness of these techniques in enhancing the performance of Sign Language Translation models by generating variation in the signer's appearance and the motion of the skeletal data. Our results demonstrate that the proposed methods can effectively augment existing datasets and enhance the performance of Sign Language Translation models by up to 19%, paving the way for more robust and accurate Sign Language Translation systems, even in resource-constrained environments.
HuGeDiff: 3D Human Generation via Diffusion with Gaussian Splatting
Jun 04, 2025



3D human generation is an important problem with a wide range of applications in computer vision and graphics. Despite recent progress in generative AI such as diffusion models or rendering methods like Neural Radiance Fields or Gaussian Splatting, controlling the generation of accurate 3D humans from text prompts remains an open challenge. Current methods struggle with fine detail, accurate rendering of hands and faces, human realism, and controlability over appearance. The lack of diversity, realism, and annotation in human image data also remains a challenge, hindering the development of a foundational 3D human model. We present a weakly supervised pipeline that tries to address these challenges. In the first step, we generate a photorealistic human image dataset with controllable attributes such as appearance, race, gender, etc using a state-of-the-art image diffusion model. Next, we propose an efficient mapping approach from image features to 3D point clouds using a transformer-based architecture. Finally, we close the loop by training a point-cloud diffusion model that is conditioned on the same text prompts used to generate the original samples. We demonstrate orders-of-magnitude speed-ups in 3D human generation compared to the state-of-the-art approaches, along with significantly improved text-prompt alignment, realism, and rendering quality. We will make the code and dataset available.
HandOcc: NeRF-based Hand Rendering with Occupancy Networks
May 04, 2025



We propose HandOcc, a novel framework for hand rendering based upon occupancy. Popular rendering methods such as NeRF are often combined with parametric meshes to provide deformable hand models. However, in doing so, such approaches present a trade-off between the fidelity of the mesh and the complexity and dimensionality of the parametric model. The simplicity of parametric mesh structures is appealing, but the underlying issue is that it binds methods to mesh initialization, making it unable to generalize to objects where a parametric model does not exist. It also means that estimation is tied to mesh resolution and the accuracy of mesh fitting. This paper presents a pipeline for meshless 3D rendering, which we apply to the hands. By providing only a 3D skeleton, the desired appearance is extracted via a convolutional model. We do this by exploiting a NeRF renderer conditioned upon an occupancy-based representation. The approach uses the hand occupancy to resolve hand-to-hand interactions further improving results, allowing fast rendering, and excellent hand appearance transfer. On the benchmark InterHand2.6M dataset, we achieved state-of-the-art results.
SignSplat: Rendering Sign Language via Gaussian Splatting
May 04, 2025



State-of-the-art approaches for conditional human body rendering via Gaussian splatting typically focus on simple body motions captured from many views. This is often in the context of dancing or walking. However, for more complex use cases, such as sign language, we care less about large body motion and more about subtle and complex motions of the hands and face. The problems of building high fidelity models are compounded by the complexity of capturing multi-view data of sign. The solution is to make better use of sequence data, ensuring that we can overcome the limited information from only a few views by exploiting temporal variability. Nevertheless, learning from sequence-level data requires extremely accurate and consistent model fitting to ensure that appearance is consistent across complex motions. We focus on how to achieve this, constraining mesh parameters to build an accurate Gaussian splatting framework from few views capable of modelling subtle human motion. We leverage regularization techniques on the Gaussian parameters to mitigate overfitting and rendering artifacts. Additionally, we propose a new adaptive control method to densify Gaussians and prune splat points on the mesh surface. To demonstrate the accuracy of our approach, we render novel sequences of sign language video, building on neural machine translation approaches to sign stitching. On benchmark datasets, our approach achieves state-of-the-art performance; and on highly articulated and complex sign language motion, we significantly outperform competing approaches.
Two Hands Are Better Than One: Resolving Hand to Hand Intersections via Occupancy Networks
Apr 08, 2024



3D hand pose estimation from images has seen considerable interest from the literature, with new methods improving overall 3D accuracy. One current challenge is to address hand-to-hand interaction where self-occlusions and finger articulation pose a significant problem to estimation. Little work has applied physical constraints that minimize the hand intersections that occur as a result of noisy estimation. This work addresses the intersection of hands by exploiting an occupancy network that represents the hand's volume as a continuous manifold. This allows us to model the probability distribution of points being inside a hand. We designed an intersection loss function to minimize the likelihood of hand-to-point intersections. Moreover, we propose a new hand mesh parameterization that is superior to the commonly used MANO model in many respects including lower mesh complexity, underlying 3D skeleton extraction, watertightness, etc. On the benchmark InterHand2.6M dataset, the models trained using our intersection loss achieve better results than the state-of-the-art by significantly decreasing the number of hand intersections while lowering the mean per-joint positional error. Additionally, we demonstrate superior performance for 3D hand uplift on Re:InterHand and SMILE datasets and show reduced hand-to-hand intersections for complex domains such as sign-language pose estimation.
Improving 3D Pose Estimation for Sign Language
Aug 18, 2023



This work addresses 3D human pose reconstruction in single images. We present a method that combines Forward Kinematics (FK) with neural networks to ensure a fast and valid prediction of 3D pose. Pose is represented as a hierarchical tree/graph with nodes corresponding to human joints that model their physical limits. Given a 2D detection of keypoints in the image, we lift the skeleton to 3D using neural networks to predict both the joint rotations and bone lengths. These predictions are then combined with skeletal constraints using an FK layer implemented as a network layer in PyTorch. The result is a fast and accurate approach to the estimation of 3D skeletal pose. Through quantitative and qualitative evaluation, we demonstrate the method is significantly more accurate than MediaPipe in terms of both per joint positional error and visual appearance. Furthermore, we demonstrate generalization over different datasets. The implementation in PyTorch runs at between 100-200 milliseconds per image (including CNN detection) using CPU only.
Denoising Diffusion for 3D Hand Pose Estimation from Images
Aug 18, 2023



Hand pose estimation from a single image has many applications. However, approaches to full 3D body pose estimation are typically trained on day-to-day activities or actions. As such, detailed hand-to-hand interactions are poorly represented, especially during motion. We see this in the failure cases of techniques such as OpenPose or MediaPipe. However, accurate hand pose estimation is crucial for many applications where the global body motion is less important than accurate hand pose estimation. This paper addresses the problem of 3D hand pose estimation from monocular images or sequences. We present a novel end-to-end framework for 3D hand regression that employs diffusion models that have shown excellent ability to capture the distribution of data for generative purposes. Moreover, we enforce kinematic constraints to ensure realistic poses are generated by incorporating an explicit forward kinematic layer as part of the network. The proposed model provides state-of-the-art performance when lifting a 2D single-hand image to 3D. However, when sequence data is available, we add a Transformer module over a temporal window of consecutive frames to refine the results, overcoming jittering and further increasing accuracy. The method is quantitatively and qualitatively evaluated showing state-of-the-art robustness, generalization, and accuracy on several different datasets.
VSAC: Efficient and Accurate Estimator for H and F
Jun 18, 2021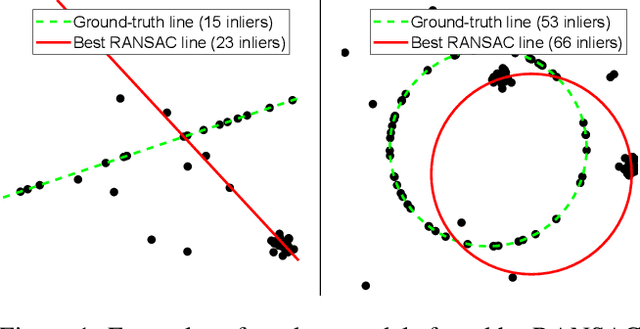
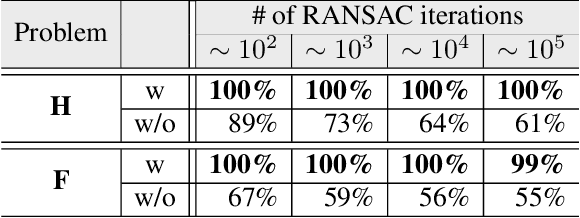
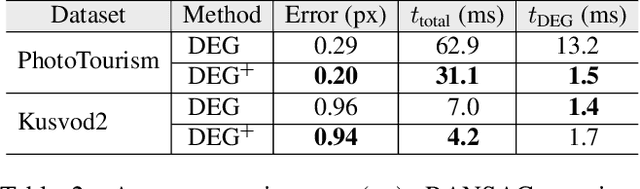
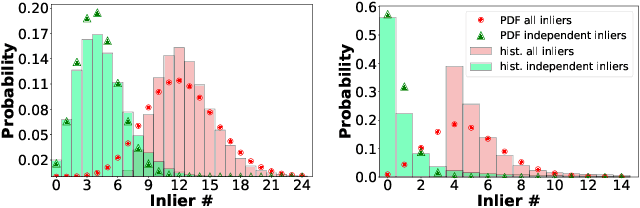
We present VSAC, a RANSAC-type robust estimator with a number of novelties. It benefits from the introduction of the concept of independent inliers that improves significantly the efficacy of the dominant plane handling and, also, allows near error-free rejection of incorrect models, without false positives. The local optimization process and its application is improved so that it is run on average only once. Further technical improvements include adaptive sequential hypothesis verification and efficient model estimation via Gaussian elimination. Experiments on four standard datasets show that VSAC is significantly faster than all its predecessors and runs on average in 1-2 ms, on a CPU. It is two orders of magnitude faster and yet as precise as MAGSAC++, the currently most accurate estimator of two-view geometry. In the repeated runs on EVD, HPatches, PhotoTourism, and Kusvod2 datasets, it never failed.
USACv20: robust essential, fundamental and homography matrix estimation
Apr 11, 2021

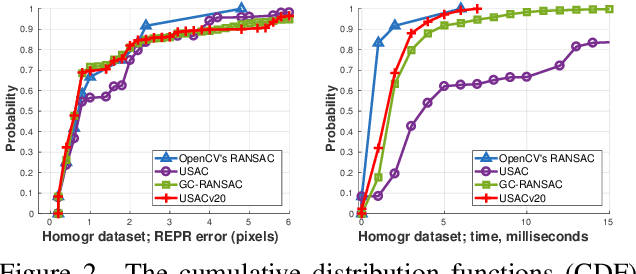

We review the most recent RANSAC-like hypothesize-and-verify robust estimators. The best performing ones are combined to create a state-of-the-art version of the Universal Sample Consensus (USAC) algorithm. A recent objective is to implement a modular and optimized framework, making future RANSAC modules easy to be included. The proposed method, USACv20, is tested on eight publicly available real-world datasets, estimating homographies, fundamental and essential matrices. On average, USACv20 leads to the most geometrically accurate models and it is the fastest in comparison to the state-of-the-art robust estimators. All reported properties improved performance of original USAC algorithm significantly. The pipeline will be made available after publication.