 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Deep Learning Approach for Real-time Lane-based Arrival Curve Reconstruction at Intersection using License Plate Recognition Data
Nov 12, 2024



The acquisition of real-time and accurate traffic arrival information is of vital importance for proactive traffic control systems, especially in partially connected vehicle environments. License plate recognition (LPR) data that record both vehicle departures and identities are proven to be desirable in reconstructing lane-based arrival curves in previous works. Existing LPR databased methods are predominantly designed for reconstructing historical arrival curves. For real-time reconstruction of multi-lane urban roads, it is pivotal to determine the lane choice of real-time link-based arrivals, which has not been exploited in previous studies. In this study, we propose a Bayesian deep learning approach for real-time lane-based arrival curve reconstruction, in which the lane choice patterns and uncertainties of link-based arrivals are both characterized. Specifically, the learning process is designed to effectively capture the relationship between partially observed link-based arrivals and lane-based arrivals, which can be physically interpreted as lane choice proportion. Moreover, the lane choice uncertainties are characterized using Bayesian parameter inference techniques, minimizing arrival curve reconstruction uncertainties, especially in low LPR data matching rate conditions. Real-world experiment results conducted in multiple matching rate scenarios demonstrate the superiority and necessity of lane choice modeling in reconstructing arrival curves.
Learning Generalizable Human Motion Generator with Reinforcement Learning
May 24, 2024



Text-driven human motion generation, as one of the vital tasks in computer-aided content creation, has recently attracted increasing attention. While pioneering research has largely focused on improving numerical performance metrics on given datasets, practical applications reveal a common challenge: existing methods often overfit specific motion expressions in the training data, hindering their ability to generalize to novel descriptions like unseen combinations of motions. This limitation restricts their broader applicability. We argue that the aforementioned problem primarily arises from the scarcity of available motion-text pairs, given the many-to-many nature of text-driven motion generation. To tackle this problem, we formulate text-to-motion generation as a Markov decision process and present \textbf{InstructMotion}, which incorporate the trail and error paradigm in reinforcement learning for generalizable human motion generation. Leveraging contrastive pre-trained text and motion encoders, we delve into optimizing reward design to enable InstructMotion to operate effectively on both paired data, enhancing global semantic level text-motion alignment, and synthetic text-only data, facilitating better generalization to novel prompts without the need for ground-truth motion supervision. Extensive experiments on prevalent benchmarks and also our synthesized unpaired dataset demonstrate that the proposed InstructMotion achieves outstanding performance both quantitatively and qualitatively.
Asymmetric Feature Fusion for Image Retrieval
Mar 01, 2024



In asymmetric retrieval systems, models with different capacities are deployed on platforms with different computational and storage resources. Despite the great progress, existing approaches still suffer from a dilemma between retrieval efficiency and asymmetric accuracy due to the limited capacity of the lightweight query model. In this work, we propose an Asymmetric Feature Fusion (AFF) paradigm, which advances existing asymmetric retrieval systems by considering the complementarity among different features just at the gallery side. Specifically, it first embeds each gallery image into various features, e.g., local features and global features. Then, a dynamic mixer is introduced to aggregate these features into compact embedding for efficient search. On the query side, only a single lightweight model is deployed for feature extraction. The query model and dynamic mixer are jointly trained by sharing a momentum-updated classifier. Notably, the proposed paradigm boosts the accuracy of asymmetric retrieval without introducing any extra overhead to the query side. Exhaustive experiments on various landmark retrieval datasets demonstrate the superiority of our paradigm.
I$^2$MD: 3D Action Representation Learning with Inter- and Intra-modal Mutual Distillation
Oct 24, 2023



Recent progresses on self-supervised 3D human action representation learning are largely attributed to contrastive learning. However, in conventional contrastive frameworks, the rich complementarity between different skeleton modalities remains under-explored. Moreover, optimized with distinguishing self-augmented samples, models struggle with numerous similar positive instances in the case of limited action categories. In this work, we tackle the aforementioned problems by introducing a general Inter- and Intra-modal Mutual Distillation (I$^2$MD) framework. In I$^2$MD, we first re-formulate the cross-modal interaction as a Cross-modal Mutual Distillation (CMD) process. Different from existing distillation solutions that transfer the knowledge of a pre-trained and fixed teacher to the student, in CMD, the knowledge is continuously updated and bidirectionally distilled between modalities during pre-training. To alleviate the interference of similar samples and exploit their underlying contexts, we further design the Intra-modal Mutual Distillation (IMD) strategy, In IMD, the Dynamic Neighbors Aggregation (DNA) mechanism is first introduced, where an additional cluster-level discrimination branch is instantiated in each modality. It adaptively aggregates highly-correlated neighboring features, forming local cluster-level contrasting. Mutual distillation is then performed between the two branches for cross-level knowledge exchange. Extensive experiments on three datasets show that our approach sets a series of new records.
Text-Only Training for Visual Storytelling
Aug 17, 2023



Visual storytelling aims to generate a narrative based on a sequence of images, necessitating both vision-language alignment and coherent story generation. Most existing solutions predominantly depend on paired image-text training data, which can be costly to collect and challenging to scale. To address this, we formulate visual storytelling as a visual-conditioned story generation problem and propose a text-only training method that separates the learning of cross-modality alignment and story generation. Our approach specifically leverages the cross-modality pre-trained CLIP model to integrate visual control into a story generator, trained exclusively on text data. Moreover, we devise a training-free visual condition planner that accounts for the temporal structure of the input image sequence while balancing global and local visual content. The distinctive advantage of requiring only text data for training enables our method to learn from external text story data, enhancing the generalization capability of visual storytelling. We conduct extensive experiments on the VIST benchmark, showcasing the effectiveness of our approach in both in-domain and cross-domain settings. Further evaluations on expression diversity and human assessment underscore the superiority of our method in terms of informativeness and robustness.
UDoc-GAN: Unpaired Document Illumination Correction with Background Light Prior
Oct 15, 2022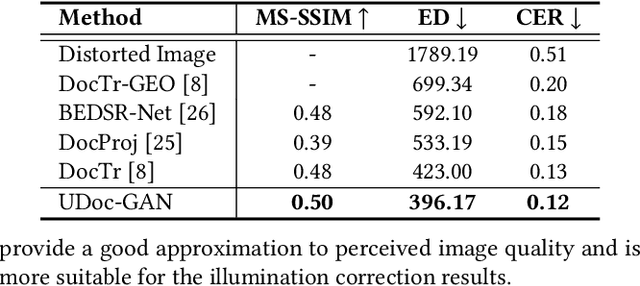
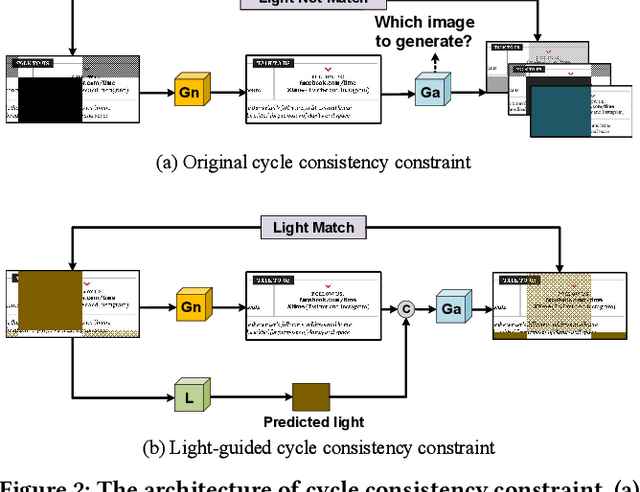
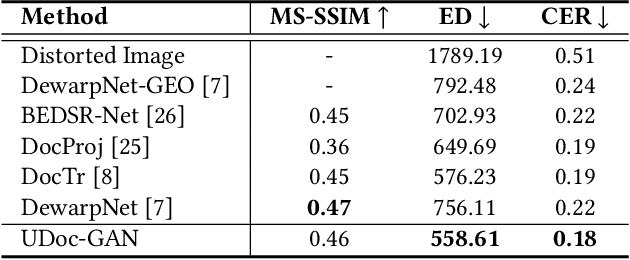
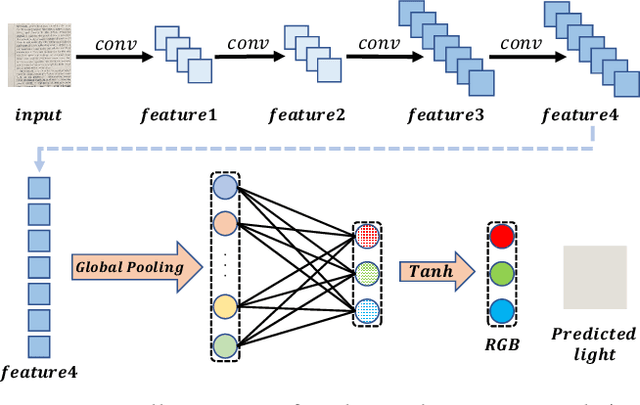
Document images captured by mobile devices are usually degraded by uncontrollable illumination, which hampers the clarity of document content. Recently, a series of research efforts have been devoted to correcting the uneven document illumination. However, existing methods rarely consider the use of ambient light information, and usually rely on paired samples including degraded and the corrected ground-truth images which are not always accessible. To this end, we propose UDoc-GAN, the first framework to address the problem of document illumination correction under the unpaired setting. Specifically, we first predict the ambient light features of the document. Then, according to the characteristics of different level of ambient lights, we re-formulate the cycle consistency constraint to learn the underlying relationship between normal and abnormal illumination domains. To prove the effectiveness of our approach, we conduct extensive experiments on DocProj dataset under the unpaired setting. Compared with the state-of-the-art approaches, our method demonstrates promising performance in terms of character error rate (CER) and edit distance (ED), together with better qualitative results for textual detail preservation. The source code is now publicly available at https://github.com/harrytea/UDoc-GAN.
A Parameter-free Nonconvex Low-rank Tensor Completion Model for Spatiotemporal Traffic Data Recovery
Sep 28, 2022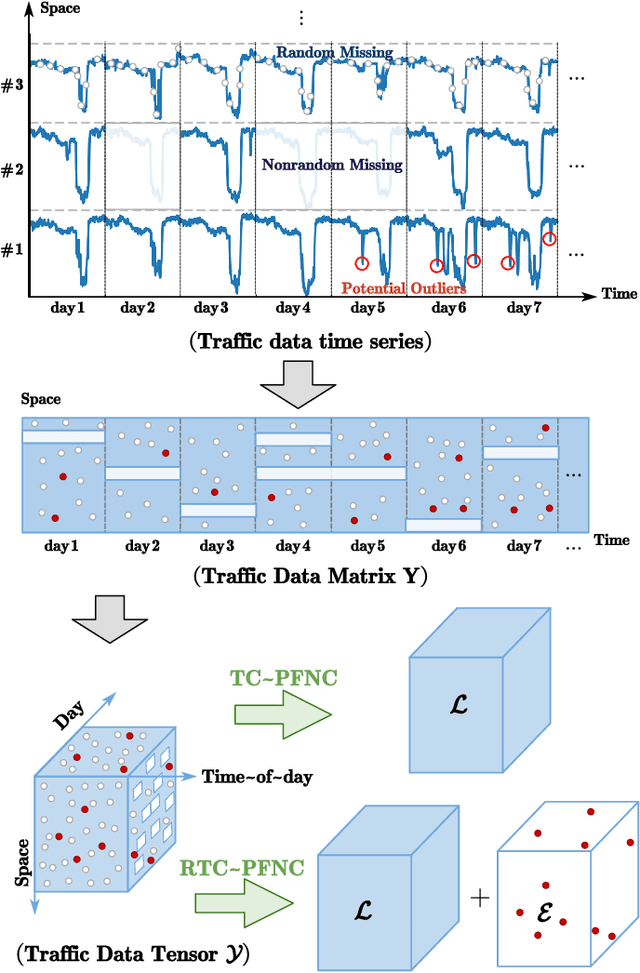
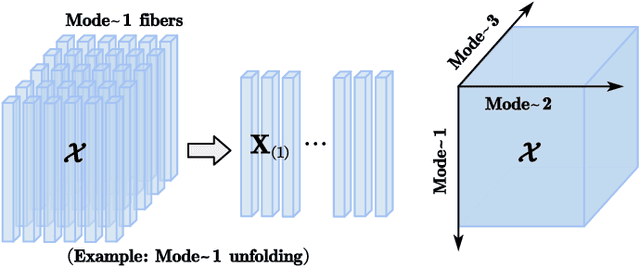
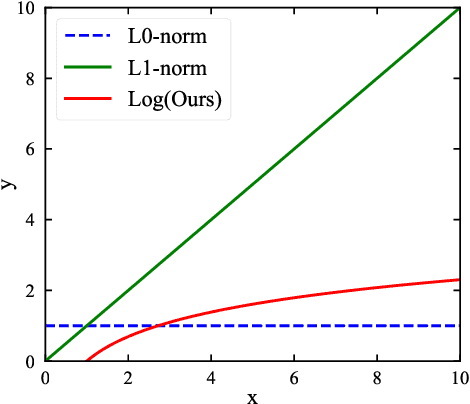
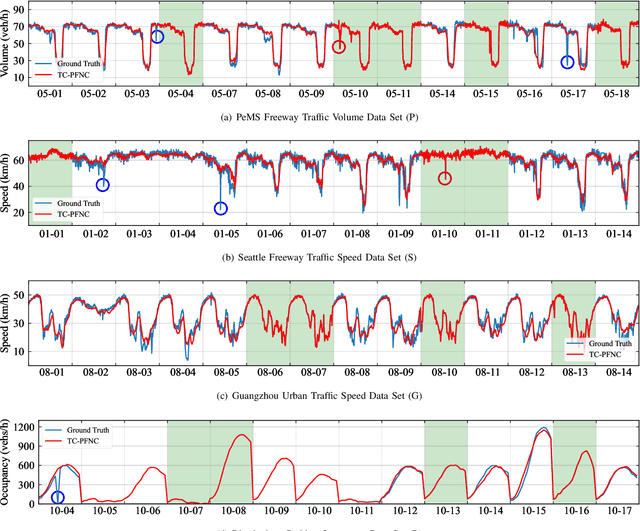
Traffic data chronically suffer from missing and corruption, leading to accuracy and utility reduction in subsequent Intelligent Transportation System (ITS) applications. Noticing the inherent low-rank property of traffic data, numerous studies formulated missing traffic data recovery as a low-rank tensor completion (LRTC) problem. Due to the non-convexity and discreteness of the rank minimization in LRTC, existing methods either replaced rank with convex surrogates that are quite far away from the rank function or approximated rank with nonconvex surrogates involving many parameters. In this study, we proposed a Parameter-Free Non-Convex Tensor Completion model (TC-PFNC) for traffic data recovery, in which a log-based relaxation term was designed to approximate tensor algebraic rank. Moreover, previous studies usually assumed the observations are reliable without any outliers. Therefore, we extended the TC-PFNC to a robust version (RTC-PFNC) by modeling potential traffic data outliers, which can recover the missing value from partial and corrupted observations and remove the anomalies in observations. The numerical solutions of TC-PFNC and RTC-PFNC were elaborated based on the alternating direction multiplier method (ADMM). The extensive experimental results conducted on four real-world traffic data sets demonstrated that the proposed methods outperform other state-of-the-art methods in both missing and corrupted data recovery. The code used in this paper is available at: https://github.com/YoungHe49/T-ITSPFNC.
CMD: Self-supervised 3D Action Representation Learning with Cross-modal Mutual Distillation
Aug 30, 2022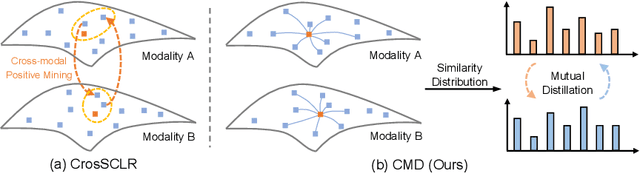
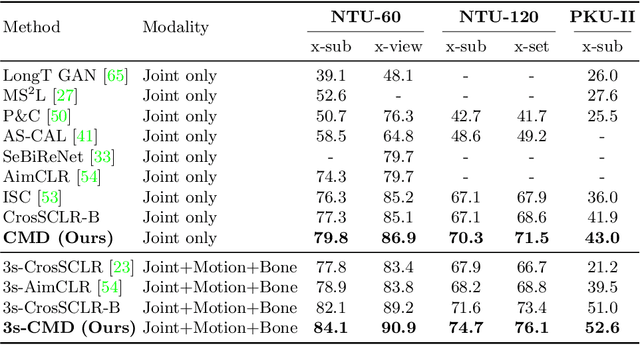
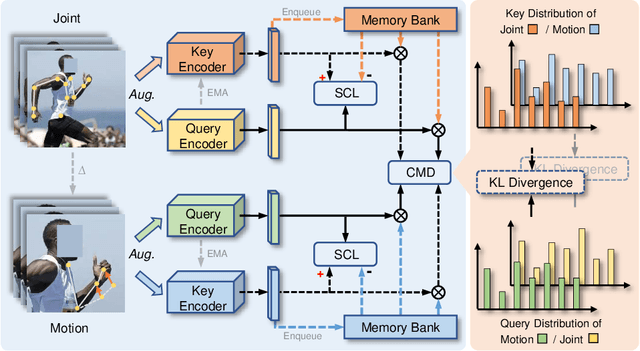
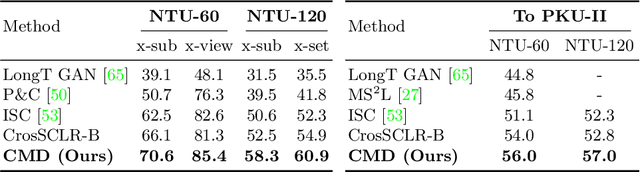
In 3D action recognition, there exists rich complementary information between skeleton modalities. Nevertheless, how to model and utilize this information remains a challenging problem for self-supervised 3D action representation learning. In this work, we formulate the cross-modal interaction as a bidirectional knowledge distillation problem. Different from classic distillation solutions that transfer the knowledge of a fixed and pre-trained teacher to the student, in this work, the knowledge is continuously updated and bidirectionally distilled between modalities. To this end, we propose a new Cross-modal Mutual Distillation (CMD) framework with the following designs. On the one hand, the neighboring similarity distribution is introduced to model the knowledge learned in each modality, where the relational information is naturally suitable for the contrastive frameworks. On the other hand, asymmetrical configurations are used for teacher and student to stabilize the distillation process and to transfer high-confidence information between modalities. By derivation, we find that the cross-modal positive mining in previous works can be regarded as a degenerated version of our CMD. We perform extensive experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD II datasets. Our approach outperforms existing self-supervised methods and sets a series of new records. The code is available at: https://github.com/maoyunyao/CMD
Simultaneous Double Q-learning with Conservative Advantage Learning for Actor-Critic Methods
May 08, 2022
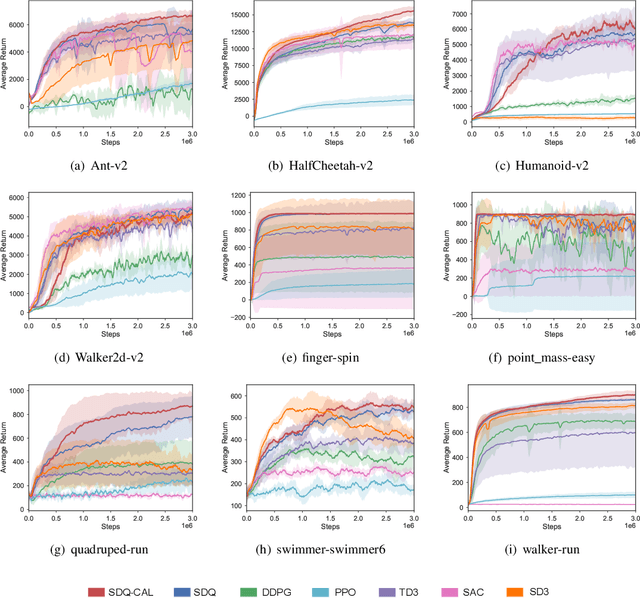
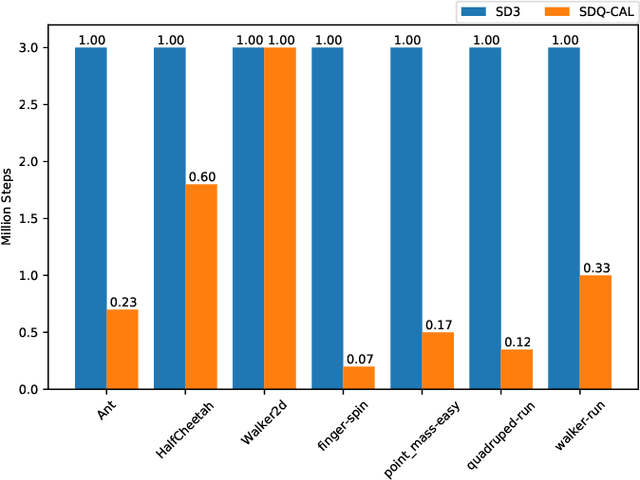
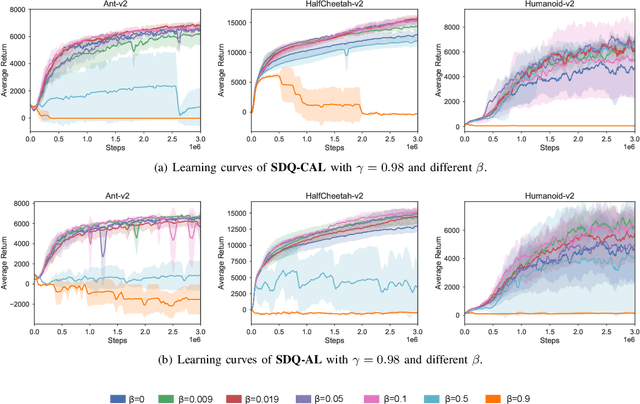
Actor-critic Reinforcement Learning (RL) algorithms have achieved impressive performance in continuous control tasks. However, they still suffer two nontrivial obstacles, i.e., low sample efficiency and overestimation bias. To this end, we propose Simultaneous Double Q-learning with Conservative Advantage Learning (SDQ-CAL). Our SDQ-CAL boosts the Double Q-learning for off-policy actor-critic RL based on a modification of the Bellman optimality operator with Advantage Learning. Specifically, SDQ-CAL improves sample efficiency by modifying the reward to facilitate the distinction from experience between the optimal actions and the others. Besides, it mitigates the overestimation issue by updating a pair of critics simultaneously upon double estimators. Extensive experiments reveal that our algorithm realizes less biased value estimation and achieves state-of-the-art performance in a range of continuous control benchmark tasks. We release the source code of our method at: \url{https://github.com/LQNew/SDQ-CAL}.
Coordinate-Aligned Multi-Camera Collaboration for Active Multi-Object Tracking
Feb 22, 2022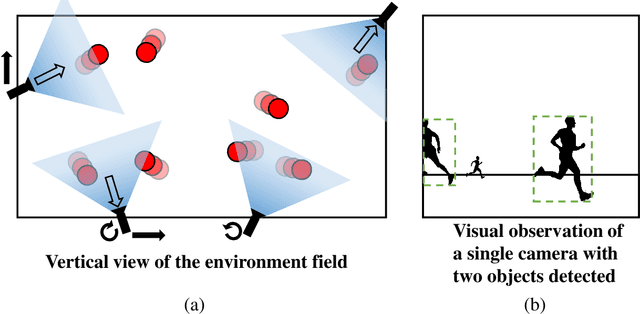
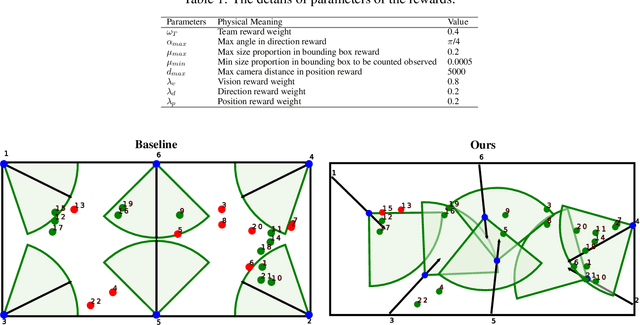
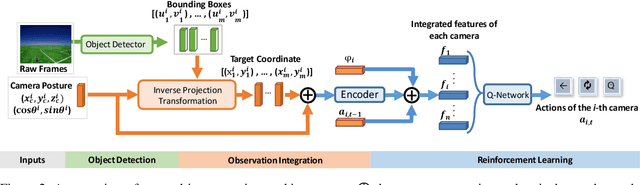

Active Multi-Object Tracking (AMOT) is a task where cameras are controlled by a centralized system to adjust their poses automatically and collaboratively so as to maximize the coverage of targets in their shared visual field. In AMOT, each camera only receives partial information from its observation, which may mislead cameras to take locally optimal action. Besides, the global goal, i.e., maximum coverage of objects, is hard to be directly optimized. To address the above issues, we propose a coordinate-aligned multi-camera collaboration system for AMOT. In our approach, we regard each camera as an agent and address AMOT with a multi-agent reinforcement learning solution. To represent the observation of each agent, we first identify the targets in the camera view with an image detector, and then align the coordinates of the targets in 3D environment. We define the reward of each agent based on both global coverage as well as four individual reward terms. The action policy of the agents is derived with a value-based Q-network. To the best of our knowledge, we are the first to study the AMOT task. To train and evaluate the efficacy of our system, we build a virtual yet credible 3D environment, named "Soccer Court", to mimic the real-world AMOT scenario. The experimental results show that our system achieves a coverage of 71.88%, outperforming the baseline method by 8.9%.