 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Mixture-of-Experts Specialization via Cluster-Aware Upcycling
Apr 15, 2026Sparse Upcycling provides an efficient way to initialize a Mixture-of-Experts (MoE) model from pretrained dense weights instead of training from scratch. However, since all experts start from identical weights and the router is randomly initialized, the model suffers from expert symmetry and limited early specialization. We propose Cluster-aware Upcycling, a strategy that incorporates semantic structure into MoE initialization. Our method first partitions the dense model's input activations into semantic clusters. Each expert is then initialized using the subspace representations of its corresponding cluster via truncated SVD, while setting the router's initial weights to the cluster centroids. This cluster-aware initialization breaks expert symmetry and encourages early specialization aligned with the data distribution. Furthermore, we introduce an expert-ensemble self-distillation loss that stabilizes training by providing reliable routing guidance using an ensemble teacher. When evaluated on CLIP ViT-B/32 and ViT-B/16, Cluster-aware Upcycling consistently outperforms existing methods across both zero-shot and few-shot benchmarks. The proposed method also produces more diverse and disentangled expert representations, reduces inter-expert similarity, and leads to more confident routing behavior.
Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
Jun 13, 2024



Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
Story Visualization by Online Text Augmentation with Context Memory
Aug 19, 2023



Story visualization (SV) is a challenging text-to-image generation task for the difficulty of not only rendering visual details from the text descriptions but also encoding a long-term context across multiple sentences. While prior efforts mostly focus on generating a semantically relevant image for each sentence, encoding a context spread across the given paragraph to generate contextually convincing images (e.g., with a correct character or with a proper background of the scene) remains a challenge. To this end, we propose a novel memory architecture for the Bi-directional Transformer framework with an online text augmentation that generates multiple pseudo-descriptions as supplementary supervision during training for better generalization to the language variation at inference. In extensive experiments on the two popular SV benchmarks, i.e., the Pororo-SV and Flintstones-SV, the proposed method significantly outperforms the state of the arts in various metrics including FID, character F1, frame accuracy, BLEU-2/3, and R-precision with similar or less computational complexity.
L-Verse: Bidirectional Generation Between Image and Text
Dec 03, 2021
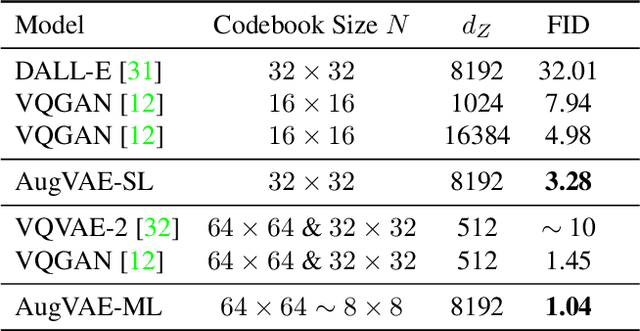
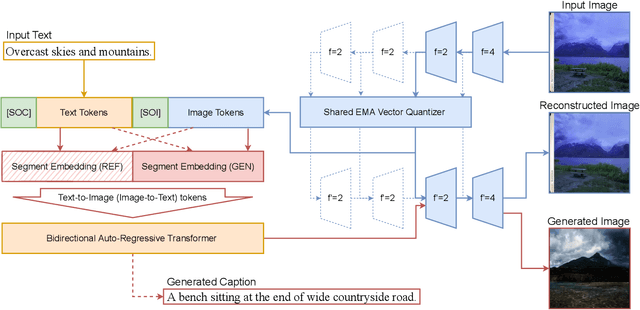
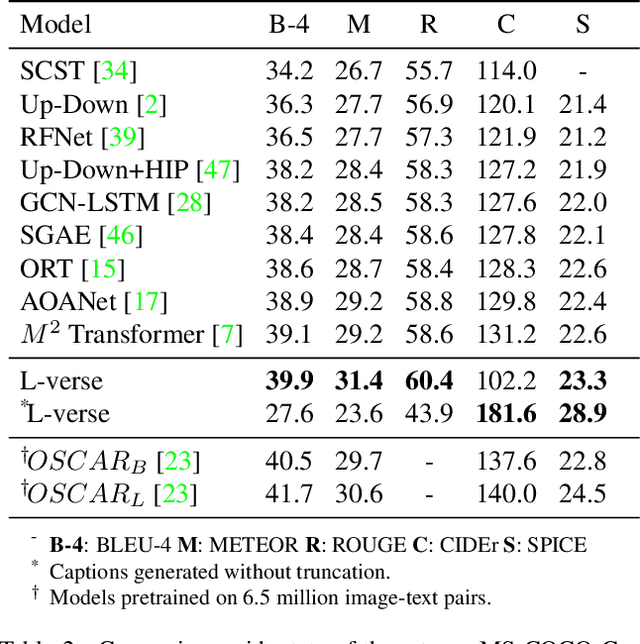
Far beyond learning long-range interactions of natural language, transformers are becoming the de-facto standard for many vision tasks with their power and scalabilty. Especially with cross-modal tasks between image and text, vector quantized variational autoencoders (VQ-VAEs) are widely used to make a raw RGB image into a sequence of feature vectors. To better leverage the correlation between image and text, we propose L-Verse, a novel architecture consisting of feature-augmented variational autoencoder (AugVAE) and bidirectional auto-regressive transformer (BiART) for text-to-image and image-to-text generation. Our AugVAE shows the state-of-the-art reconstruction performance on ImageNet1K validation set, along with the robustness to unseen images in the wild. Unlike other models, BiART can distinguish between image (or text) as a conditional reference and a generation target. L-Verse can be directly used for image-to-text or text-to-image generation tasks without any finetuning or extra object detection frameworks. In quantitative and qualitative experiments, L-Verse shows impressive results against previous methods in both image-to-text and text-to-image generation on MS-COCO Captions. We furthermore assess the scalability of L-Verse architecture on Conceptual Captions and present the initial results of bidirectional vision-language representation learning on general domain.