 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes
Aug 20, 2019

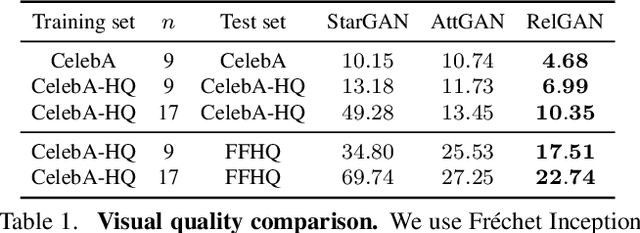
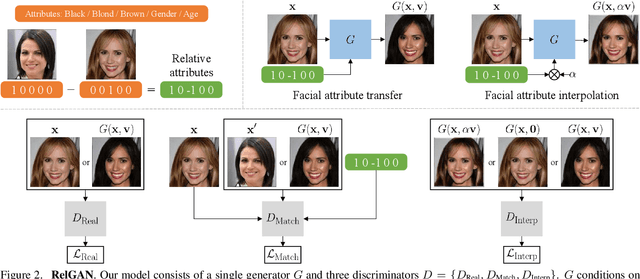
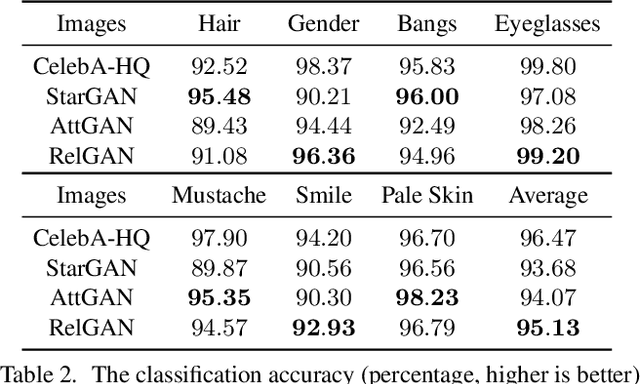
Multi-domain image-to-image translation has gained increasing attention recently. Previous methods take an image and some target attributes as inputs and generate an output image with the desired attributes. However, such methods have two limitations. First, these methods assume binary-valued attributes and thus cannot yield satisfactory results for fine-grained control. Second, these methods require specifying the entire set of target attributes, even if most of the attributes would not be changed. To address these limitations, we propose RelGAN, a new method for multi-domain image-to-image translation. The key idea is to use relative attributes, which describes the desired change on selected attributes. Our method is capable of modifying images by changing particular attributes of interest in a continuous manner while preserving the other attributes. Experimental results demonstrate both the quantitative and qualitative effectiveness of our method on the tasks of facial attribute transfer and interpolation.
An Efficient Multi-Domain Framework for Image-to-Image Translation
Nov 28, 2019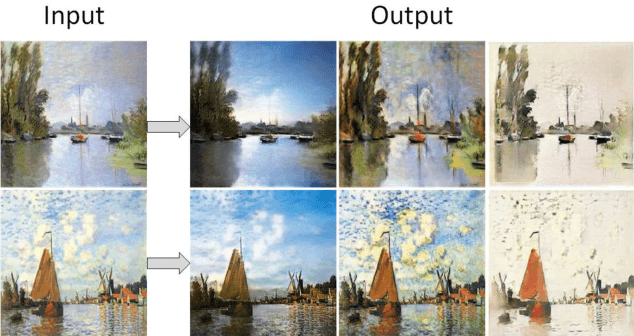
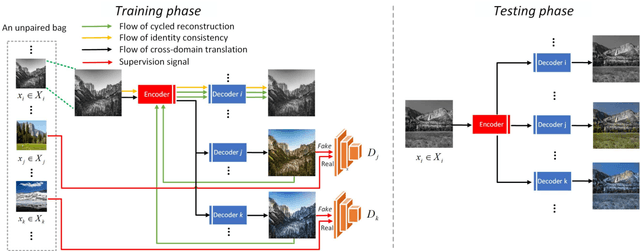
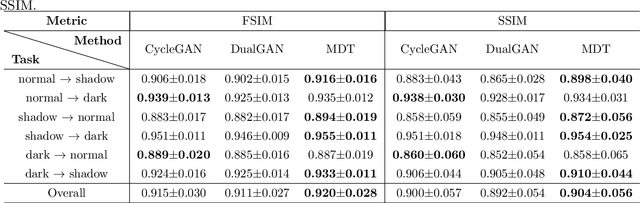
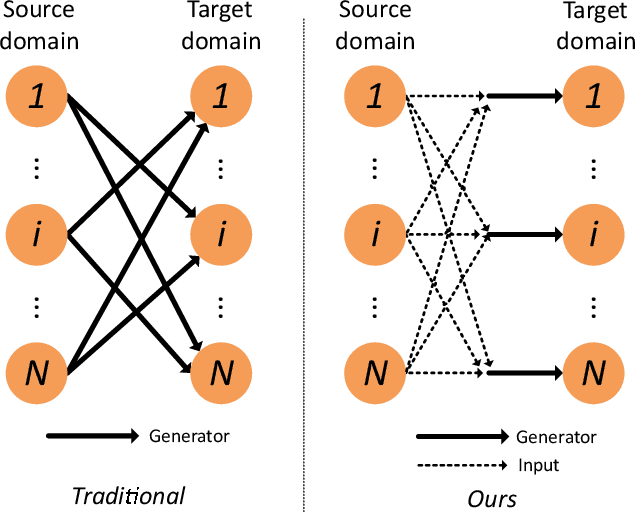
Existing approaches have been proposed to tackle unsupervised image-to-image translation in recent years. However, they mainly focus on one-to-one mappings, making it difficult to handle more general and practical problems such as multi-domain translations. To address issues like large cost of training time and resources in translation between any number of domains, we propose a general framework called multi-domain translator (MDT), which is extended from bi-directional image-to-image translation. MDT is designed to have only one domain-shared encoder for the consideration of efficiency, together with several domain-specified decoders to transform an image into multiple domains without knowing the input domain label. Moreover, we propose to employ two constraints, namely reconstruction loss and identity loss to further improve the generation. Experiments are conducted on different databases for several multi-domain translation tasks. Both qualitative and quantitative results demonstrate the effectiveness and efficiency performed by the proposed MDT against the state-of-the-art models.
Semi-supervised Learning for Few-shot Image-to-Image Translation
Apr 02, 2020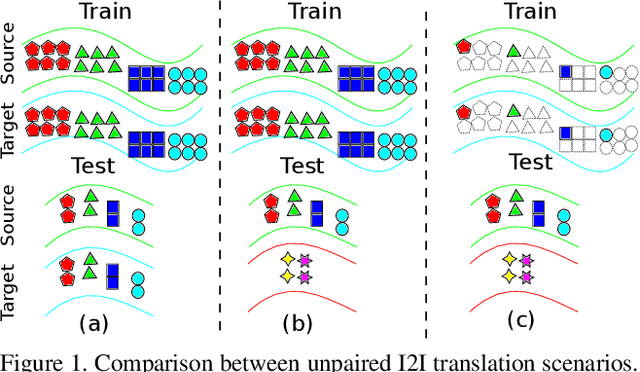
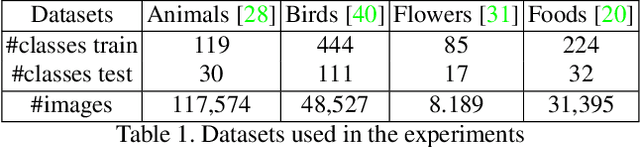
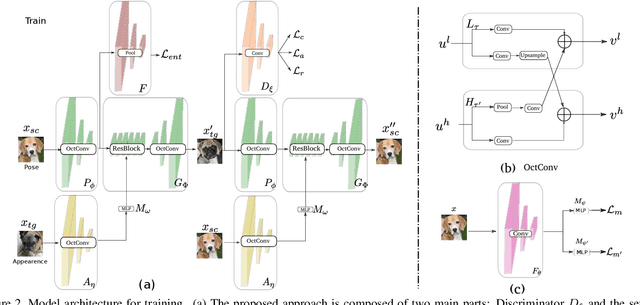
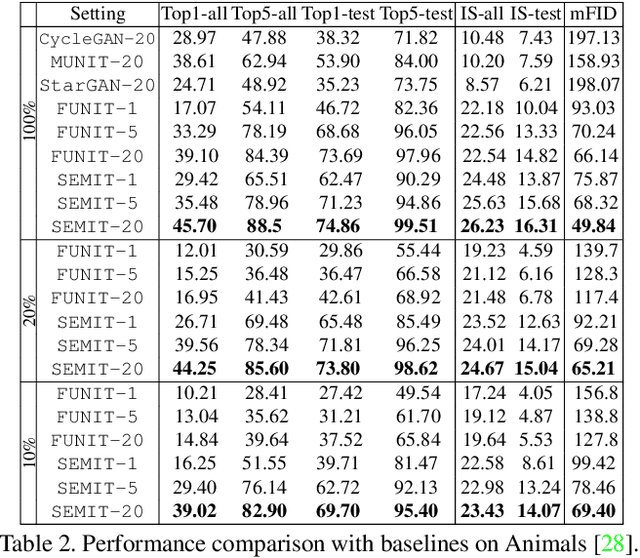
In the last few years, unpaired image-to-image translation has witnessed remarkable progress. Although the latest methods are able to generate realistic images, they crucially rely on a large number of labeled images. Recently, some methods have tackled the challenging setting of few-shot image-to-image translation, reducing the labeled data requirements for the target domain during inference. In this work, we go one step further and reduce the amount of required labeled data also from the source domain during training. To do so, we propose applying semi-supervised learning via a noise-tolerant pseudo-labeling procedure. We also apply a cycle consistency constraint to further exploit the information from unlabeled images, either from the same dataset or external. Additionally, we propose several structural modifications to facilitate the image translation task under these circumstances. Our semi-supervised method for few-shot image translation, called SEMIT, achieves excellent results on four different datasets using as little as 10% of the source labels, and matches the performance of the main fully-supervised competitor using only 20% labeled data. Our code and models are made public at: https://github.com/yaxingwang/SEMIT.
Unsupervised Image to Image Translation for Multiple Retinal Pathology Synthesis in Optical Coherence Tomography Scans
Dec 11, 2021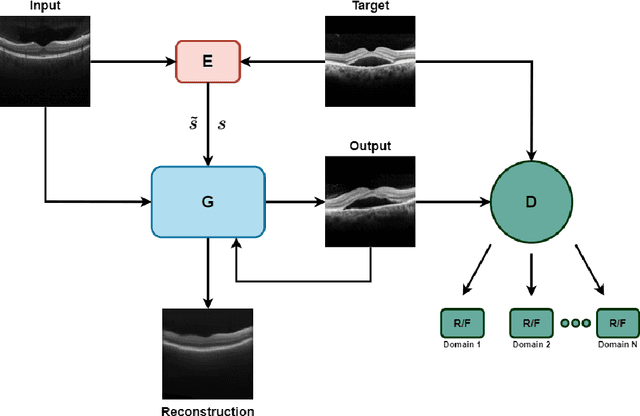
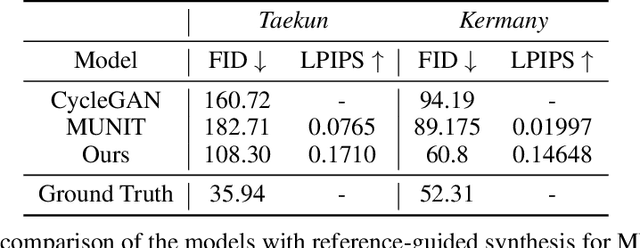
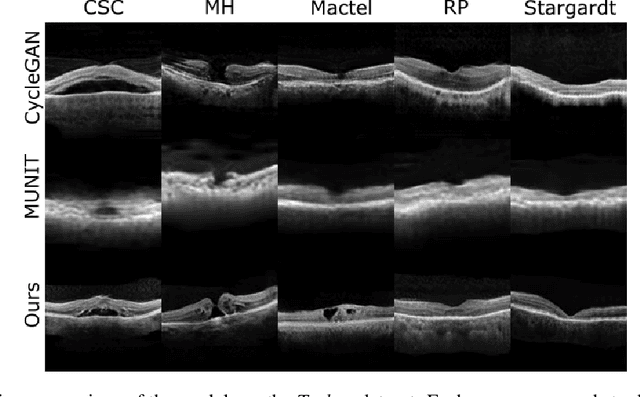
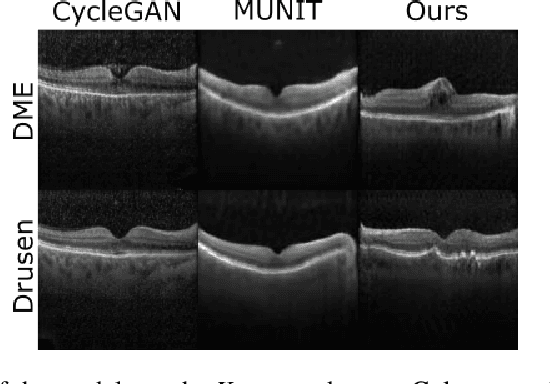
Image to Image Translation (I2I) is a challenging computer vision problem used in numerous domains for multiple tasks. Recently, ophthalmology became one of the major fields where the application of I2I is increasing rapidly. One such application is the generation of synthetic retinal optical coherence tomographic (OCT) scans. Existing I2I methods require training of multiple models to translate images from normal scans to a specific pathology: limiting the use of these models due to their complexity. To address this issue, we propose an unsupervised multi-domain I2I network with pre-trained style encoder that translates retinal OCT images in one domain to multiple domains. We assume that the image splits into domain-invariant content and domain-specific style codes, and pre-train these style codes. The performed experiments show that the proposed model outperforms state-of-the-art models like MUNIT and CycleGAN synthesizing diverse pathological scans.
FairFaceGAN: Fairness-aware Facial Image-to-Image Translation
Dec 02, 2020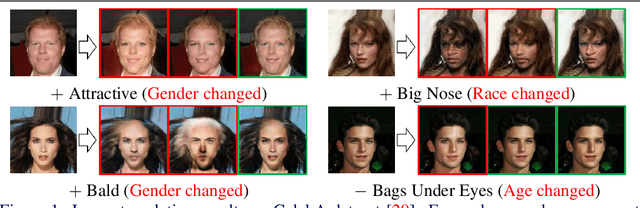
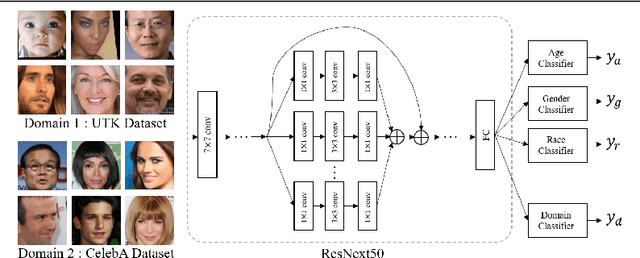

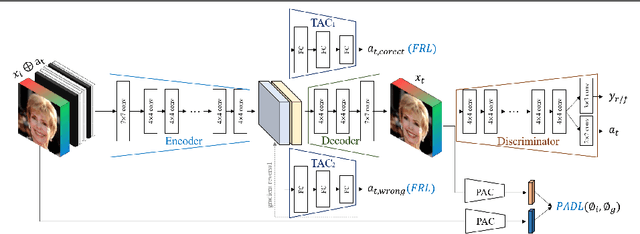
In this paper, we introduce FairFaceGAN, a fairness-aware facial Image-to-Image translation model, mitigating the problem of unwanted translation in protected attributes (e.g., gender, age, race) during facial attributes editing. Unlike existing models, FairFaceGAN learns fair representations with two separate latents - one related to the target attributes to translate, and the other unrelated to them. This strategy enables FairFaceGAN to separate the information about protected attributes and that of target attributes. It also prevents unwanted translation in protected attributes while target attributes editing. To evaluate the degree of fairness, we perform two types of experiments on CelebA dataset. First, we compare the fairness-aware classification performances when augmenting data by existing image translation methods and FairFaceGAN respectively. Moreover, we propose a new fairness metric, namely Frechet Protected Attribute Distance (FPAD), which measures how well protected attributes are preserved. Experimental results demonstrate that FairFaceGAN shows consistent improvements in terms of fairness over the existing image translation models. Further, we also evaluate image translation performances, where FairFaceGAN shows competitive results, compared to those of existing methods.
Discriminative Region Proposal Adversarial Networks for High-Quality Image-to-Image Translation
Aug 06, 2018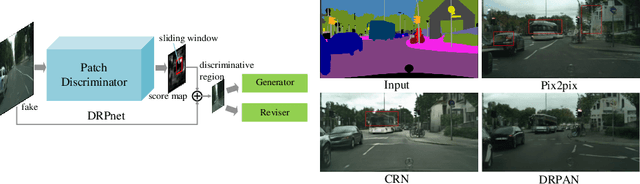
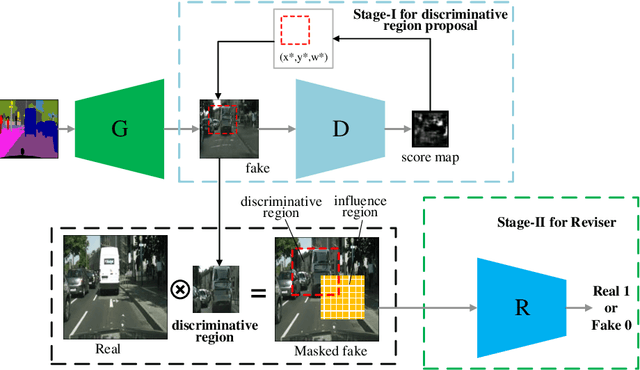
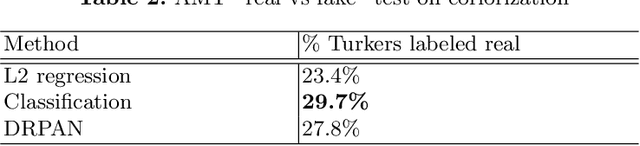
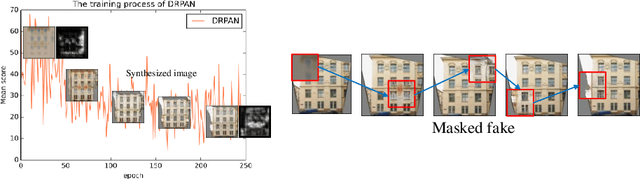
Image-to-image translation has been made much progress with embracing Generative Adversarial Networks (GANs). However, it's still very challenging for translation tasks that require high quality, especially at high-resolution and photorealism. In this paper, we present Discriminative Region Proposal Adversarial Networks (DRPAN) for high-quality image-to-image translation. We decompose the procedure of image-to-image translation task into three iterated steps, first is to generate an image with global structure but some local artifacts (via GAN), second is using our DRPnet to propose the most fake region from the generated image, and third is to implement "image inpainting" on the most fake region for more realistic result through a reviser, so that the system (DRPAN) can be gradually optimized to synthesize images with more attention on the most artifact local part. Experiments on a variety of image-to-image translation tasks and datasets validate that our method outperforms state-of-the-arts for producing high-quality translation results in terms of both human perceptual studies and automatic quantitative measures.
Dual Generator Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Jan 14, 2019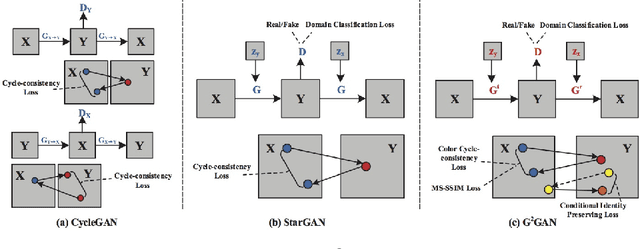
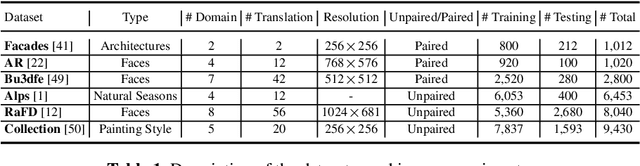
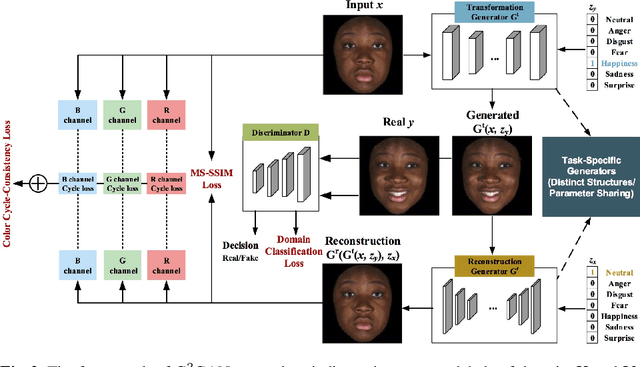

State-of-the-art methods for image-to-image translation with Generative Adversarial Networks (GANs) can learn a mapping from one domain to another domain using unpaired image data. However, these methods require the training of one specific model for every pair of image domains, which limits the scalability in dealing with more than two image domains. In addition, the training stage of these methods has the common problem of model collapse that degrades the quality of the generated images. To tackle these issues, we propose a Dual Generator Generative Adversarial Network (G$^2$GAN), which is a robust and scalable approach allowing to perform unpaired image-to-image translation for multiple domains using only dual generators within a single model. Moreover, we explore different optimization losses for better training of G$^2$GAN, and thus make unpaired image-to-image translation with higher consistency and better stability. Extensive experiments on six publicly available datasets with different scenarios, i.e., architectural buildings, seasons, landscape and human faces, demonstrate that the proposed G$^2$GAN achieves superior model capacity and better generation performance comparing with existing image-to-image translation GAN models.
GAIT: Gradient Adjusted Unsupervised Image-to-Image Translation
Sep 02, 2020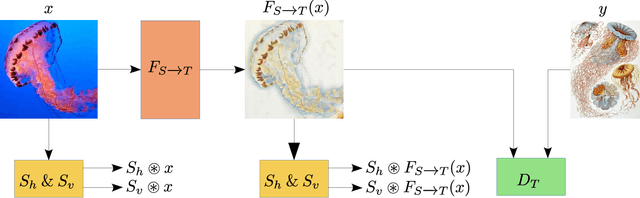
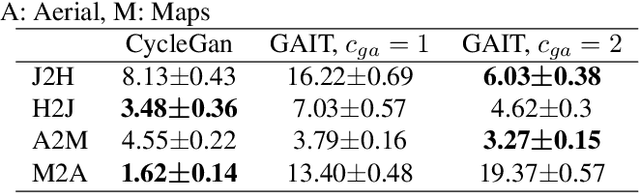


Image-to-image translation (IIT) has made much progress recently with the development of adversarial learning. In most of the recent work, an adversarial loss is utilized to match the distributions of the translated and target image sets. However, this may create artifacts if two domains have different marginal distributions, for example, in uniform areas. In this work, we propose an unsupervised IIT method that preserves the uniform regions after the translation. The gradient adjustment loss, which is the L2 norm between the Sobel response of the target image and the adjusted Sobel response of the source images, is utilized. The proposed method is validated on the jellyfish-to-Haeckel dataset, which is prepared to demonstrate the mentioned problem, which contains images with different background distributions. We demonstrate that our method obtained a performance gain compared to the baseline method qualitatively and quantitatively, showing the effectiveness of the proposed method.
ISF-GAN: An Implicit Style Function for High-Resolution Image-to-Image Translation
Sep 26, 2021



Recently, there has been an increasing interest in image editing methods that employ pre-trained unconditional image generators (e.g., StyleGAN). However, applying these methods to translate images to multiple visual domains remains challenging. Existing works do not often preserve the domain-invariant part of the image (e.g., the identity in human face translations), they do not usually handle multiple domains, or do not allow for multi-modal translations. This work proposes an implicit style function (ISF) to straightforwardly achieve multi-modal and multi-domain image-to-image translation from pre-trained unconditional generators. The ISF manipulates the semantics of an input latent code to make the image generated from it lying in the desired visual domain. Our results in human face and animal manipulations show significantly improved results over the baselines. Our model enables cost-effective multi-modal unsupervised image-to-image translations at high resolution using pre-trained unconditional GANs. The code and data are available at: \url{https://github.com/yhlleo/stylegan-mmuit}.
Asymmetric GAN for Unpaired Image-to-image Translation
Dec 25, 2019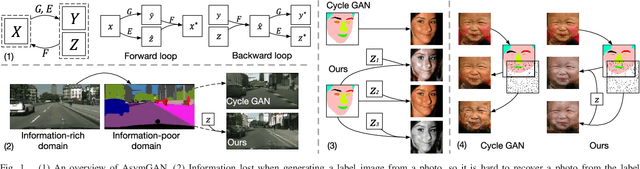
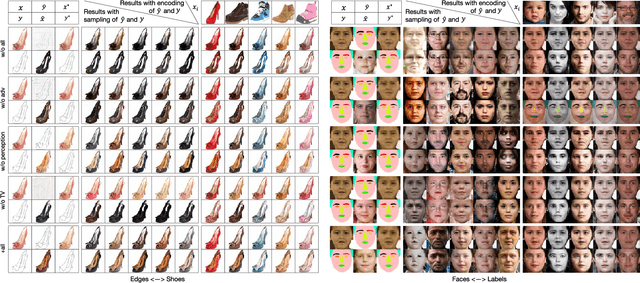


Unpaired image-to-image translation problem aims to model the mapping from one domain to another with unpaired training data. Current works like the well-acknowledged Cycle GAN provide a general solution for any two domains through modeling injective mappings with a symmetric structure. While in situations where two domains are asymmetric in complexity, i.e., the amount of information between two domains is different, these approaches pose problems of poor generation quality, mapping ambiguity, and model sensitivity. To address these issues, we propose Asymmetric GAN (AsymGAN) to adapt the asymmetric domains by introducing an auxiliary variable (aux) to learn the extra information for transferring from the information-poor domain to the information-rich domain, which improves the performance of state-of-the-art approaches in the following ways. First, aux better balances the information between two domains which benefits the quality of generation. Second, the imbalance of information commonly leads to mapping ambiguity, where we are able to model one-to-many mappings by tuning aux, and furthermore, our aux is controllable. Third, the training of Cycle GAN can easily make the generator pair sensitive to small disturbances and variations while our model decouples the ill-conditioned relevance of generators by injecting aux during training. We verify the effectiveness of our proposed method both qualitatively and quantitatively on asymmetric situation, label-photo task, on Cityscapes and Helen datasets, and show many applications of asymmetric image translations. In conclusion, our AsymGAN provides a better solution for unpaired image-to-image translation in asymmetric domains.
* Accepted by IEEE Transactions on Image Processing (TIP) 2019