 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Centric ISAC for Exposure Control via Opportunistic Virtual Aperture Sensing
Feb 19, 2026Regulatory limits on Maximum Permissible Exposure (MPE) require handheld devices to reduce transmit power when operated near the user's body. Current proximity sensors provide only binary detection, triggering conservative power back-off that degrades link quality. If the device could measure its distance from the body, transmit power could be adjusted proportionally, improving throughput while maintaining compliance. This paper develops a device-centric integrated sensing and communication (ISAC) method for the device to measure this distance. The uplink communication waveform is exploited for sensing, and the natural motion of the user's hand creates a virtual aperture that provides the angular resolution necessary for localization. Virtual aperture processing requires precise knowledge of the device trajectory, which in this scenario is opportunistic and unknown. One can exploit onboard inertial sensors to estimate the device trajectory; however, the inertial sensors accuracy is not sufficient. To address this, we develop an autofocus algorithm based on extended Kalman filtering that jointly tracks the trajectory and compensates residual errors using phase observations from strong scatterers. The Bayesian Cramér-Rao bound for localization is derived under correlated inertial errors. Numerical results at 28GHz demonstrate centimeter-level accuracy with realistic sensor parameters.
Harli: SLO-Aware Co-location of LLM Inference and PEFT-based Finetuning on Model-as-a-Service Platforms
Nov 19, 2025Large language models (LLMs) are increasingly deployed under the Model-as-a-Service (MaaS) paradigm. To meet stringent quality-of-service (QoS) requirements, existing LLM serving systems disaggregate the prefill and decode phases of inference. However, decode instances often experience low GPU utilization due to their memory-bound nature and insufficient batching in dynamic workloads, leaving compute resources underutilized. We introduce Harli, a serving system that improves GPU utilization by co-locating parameter-efficient finetuning (PEFT) tasks with LLM decode instances. PEFT tasks are compute-bound and memory-efficient, making them ideal candidates for safe co-location. Specifically, Harli addresses key challenges--limited memory and unpredictable interference--using three components: a unified memory allocator for runtime memory reuse, a two-stage latency predictor for decode latency modeling, and a QoS-guaranteed throughput-maximizing scheduler for throughput maximization. Experimental results show that Harli improves the finetune throughput by 46.2% on average (up to 92.0%) over state-of-the-art serving systems, while maintaining strict QoS guarantees for inference decode.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025



The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
Discrete Codebook Design for Self-interference Suppression in mmWave ISAC
Apr 22, 2025



This paper presents discrete codebook synthesis methods for self-interference (SI) suppression in a mmWave device, designed to support FD ISAC. We formulate a SINR maximization problem that optimizes the RX and TX codewords, aimed at suppressing the near-field SI signal while maintaining the beamforming gain in the far-field sensing directions. The formulation considers the practical constraints of discrete RX and TX codebooks with quantized phase settings, as well as a TX beamforming gain requirement in the specified communication direction. Under an alternating optimization framework, the RX and TX codewords are iteratively optimized, with one fixed while the other is optimized. When the TX codeword is fixed, we show that the RX codeword optimization problem can be formulated as an integer quadratic fractional programming (IQFP) problem. Using Dinkelbach's algorithm, we transform the problem into a sequence of subproblems in which the numerator and the denominator of the objective function are decoupled. These subproblems, subject to discrete constraints, are then efficiently solved by the spherical search (SS) method. This overall approach is referred to as FP-SS. When the RX codeword is fixed, the TX codeword optimization problem can similarly be formulated as an IQFP problem, whereas an additional TX beamforming constraint for communication needs to be considered. The problem is solved through Dinkelbach's transformation followed by the constrained spherical search (CSS), and we refer to this approach as FP-CSS. Finally, we integrate the FP-SS and FP-CSS methods into a joint RX-TX codebook design approach. Simulations show that, the proposed FP-SS and FP-CSS achieve the same SI suppression performance as the corresponding exhaustive search method, but with much lower complexity. Furthermore, the alternating optimization framework achieved even better SI suppression performance.
UVEB: A Large-scale Benchmark and Baseline Towards Real-World Underwater Video Enhancement
Apr 27, 2024



Learning-based underwater image enhancement (UIE) methods have made great progress. However, the lack of large-scale and high-quality paired training samples has become the main bottleneck hindering the development of UIE. The inter-frame information in underwater videos can accelerate or optimize the UIE process. Thus, we constructed the first large-scale high-resolution underwater video enhancement benchmark (UVEB) to promote the development of underwater vision.It contains 1,308 pairs of video sequences and more than 453,000 high-resolution with 38\% Ultra-High-Definition (UHD) 4K frame pairs. UVEB comes from multiple countries, containing various scenes and video degradation types to adapt to diverse and complex underwater environments. We also propose the first supervised underwater video enhancement method, UVE-Net. UVE-Net converts the current frame information into convolutional kernels and passes them to adjacent frames for efficient inter-frame information exchange. By fully utilizing the redundant degraded information of underwater videos, UVE-Net completes video enhancement better. Experiments show the effective network design and good performance of UVE-Net.
Indoor Positioning based on Active Radar Sensing and Passive Reflectors: Concepts & Initial Results
Oct 06, 2023


To navigate reliably in indoor environments, an industrial autonomous vehicle must know its position. However, current indoor vehicle positioning technologies either lack accuracy, usability or are too expensive. Thus, we propose a novel concept called local reference point assisted active radar positioning, which is able to overcome these drawbacks. It is based on distributing passive retroreflectors in the indoor environment such that each position of the vehicle can be identified by a unique reflection characteristic regarding the reflectors. To observe these characteristics, the autonomous vehicle is equipped with an active radar system. On one hand, this paper presents the basic idea and concept of our new approach towards indoor vehicle positioning and especially focuses on the crucial placement of the reflectors. On the other hand, it also provides a proof of concept by conducting a full system simulation including the placement of the local reference points, the radar-based distance estimation and the comparison of two different positioning methods. It successfully demonstrates the feasibility of our proposed approach.
Channel Pruned YOLOv5-based Deep Learning Approach for Rapid and Accurate Outdoor Obstacles Detection
Apr 27, 2022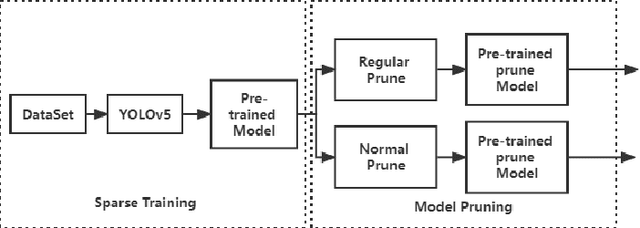

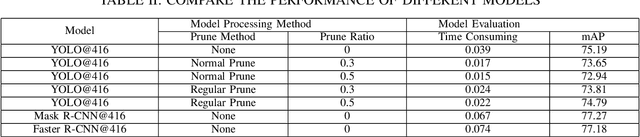
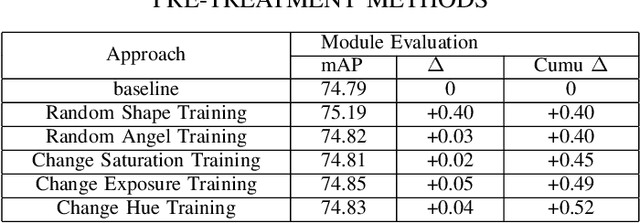
One-stage algorithm have been widely used in target detection systems that need to be trained with massive data. Most of them perform well both in real-time and accuracy. However, due to their convolutional structure, they need more computing power and greater memory consumption. Hence, we applied pruning strategy to target detection networks to reduce the number of parameters and the size of model. To demonstrate the practicality of the pruning method, we select the YOLOv5 model for experiments and provide a data set of outdoor obstacles to show the effect of model. In this specific data set, in the best circumstances, the volume of the network model is reduced by 49.7% compared with the original model, and the reasoning time is reduced by 52.5%. Meanwhile, it also uses data processing methods to compensate for the drop in accuracy caused by pruning.
Detecting Mitosis against Domain Shift using a Fused Detector and Deep Ensemble Classification Model for MIDOG Challenge
Aug 31, 2021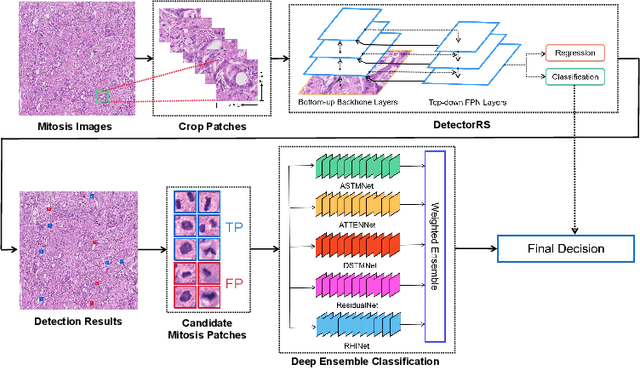

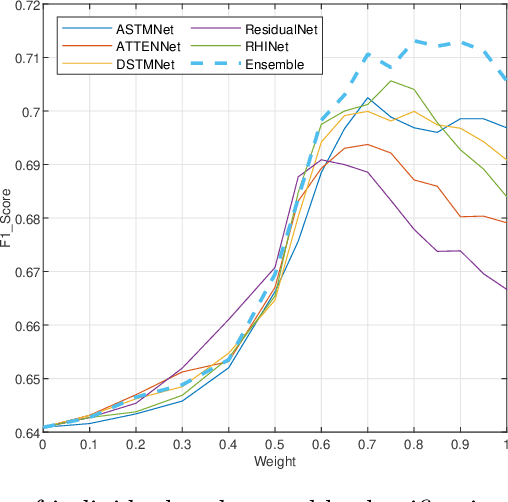
Mitotic figure count is an important marker of tumor proliferation and has been shown to be associated with patients' prognosis. Deep learning based mitotic figure detection methods have been utilized to automatically locate the cell in mitosis using hematoxylin \& eosin (H\&E) stained images. However, the model performance deteriorates due to the large variation of color tone and intensity in H\&E images. In this work, we proposed a two stage mitotic figure detection framework by fusing a detector and a deep ensemble classification model. To alleviate the impact of color variation in H\&E images, we utilize both stain normalization and data augmentation, aiding model to learn color irrelevant features. The proposed model obtains an F1 score of 0.7550 on the preliminary testing set released by the MIDOG challenge.
ReshapeGAN: Object Reshaping by Providing A Single Reference Image
May 16, 2019

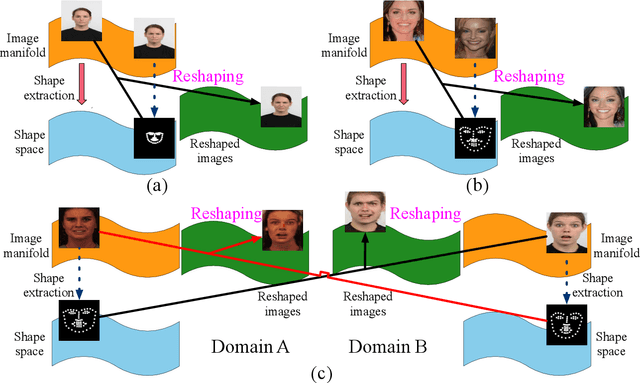
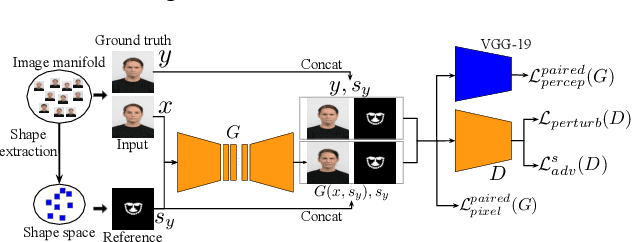
The aim of this work is learning to reshape the object in an input image to an arbitrary new shape, by just simply providing a single reference image with an object instance in the desired shape. We propose a new Generative Adversarial Network (GAN) architecture for such an object reshaping problem, named ReshapeGAN. The network can be tailored for handling all kinds of problem settings, including both within-domain (or single-dataset) reshaping and cross-domain (typically across mutiple datasets) reshaping, with paired or unpaired training data. The appearance of the input object is preserved in all cases, and thus it is still identifiable after reshaping, which has never been achieved as far as we are aware. We present the tailored models of the proposed ReshapeGAN for all the problem settings, and have them tested on 8 kinds of reshaping tasks with 13 different datasets, demonstrating the ability of ReshapeGAN on generating convincing and superior results for object reshaping. To the best of our knowledge, we are the first to be able to make one GAN framework work on all such object reshaping tasks, especially the cross-domain tasks on handling multiple diverse datasets. We present here both ablation studies on our proposed ReshapeGAN models and comparisons with the state-of-the-art models when they are made comparable, using all kinds of applicable metrics that we are aware of.
One-Shot Image-to-Image Translation via Part-Global Learning with a Multi-adversarial Framework
May 12, 2019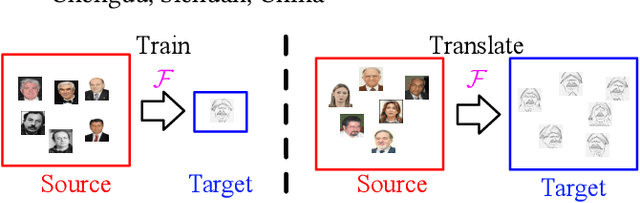
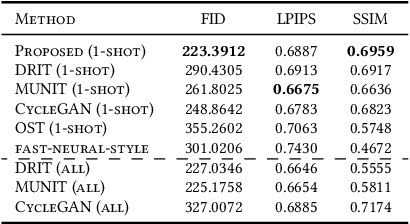
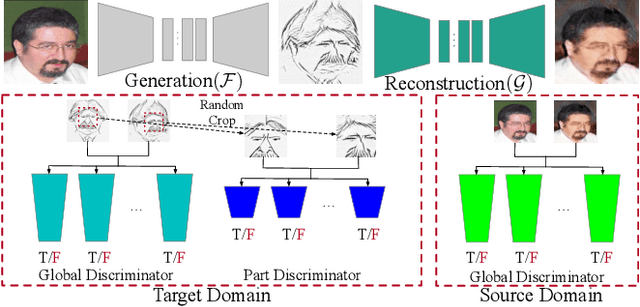
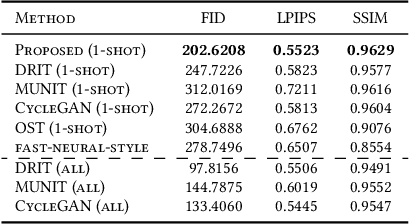
It is well known that humans can learn and recognize objects effectively from several limited image samples. However, learning from just a few images is still a tremendous challenge for existing main-stream deep neural networks. Inspired by analogical reasoning in the human mind, a feasible strategy is to translate the abundant images of a rich source domain to enrich the relevant yet different target domain with insufficient image data. To achieve this goal, we propose a novel, effective multi-adversarial framework (MA) based on part-global learning, which accomplishes one-shot cross-domain image-to-image translation. In specific, we first devise a part-global adversarial training scheme to provide an efficient way for feature extraction and prevent discriminators being over-fitted. Then, a multi-adversarial mechanism is employed to enhance the image-to-image translation ability to unearth the high-level semantic representation. Moreover, a balanced adversarial loss function is presented, which aims to balance the training data and stabilize the training process. Extensive experiments demonstrate that the proposed approach can obtain impressive results on various datasets between two extremely imbalanced image domains and outperform state-of-the-art methods on one-shot image-to-image translation.