 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard Thresholding Pursuit Algorithms for Least Absolute Deviations Problem
Jan 10, 2026Least absolute deviations (LAD) is a statistical optimality criterion widely utilized in scenarios where a minority of measurements are contaminated by outliers of arbitrary magnitudes. In this paper, we delve into the robustness of the variant of adaptive iterative hard thresholding to outliers, known as graded fast hard thresholding pursuit (GFHTP$_1$) algorithm. Unlike the majority of the state-of-the-art algorithms in this field, GFHTP$_1$ does not require prior information about the signal's sparsity. Moreover, its design is parameterless, which not only simplifies the implementation process but also removes the intricacies of parameter optimization. Numerical experiments reveal that the GFHTP$_1$ algorithm consistently outperforms competing algorithms in terms of both robustness and computational efficiency.
UVEB: A Large-scale Benchmark and Baseline Towards Real-World Underwater Video Enhancement
Apr 27, 2024



Learning-based underwater image enhancement (UIE) methods have made great progress. However, the lack of large-scale and high-quality paired training samples has become the main bottleneck hindering the development of UIE. The inter-frame information in underwater videos can accelerate or optimize the UIE process. Thus, we constructed the first large-scale high-resolution underwater video enhancement benchmark (UVEB) to promote the development of underwater vision.It contains 1,308 pairs of video sequences and more than 453,000 high-resolution with 38\% Ultra-High-Definition (UHD) 4K frame pairs. UVEB comes from multiple countries, containing various scenes and video degradation types to adapt to diverse and complex underwater environments. We also propose the first supervised underwater video enhancement method, UVE-Net. UVE-Net converts the current frame information into convolutional kernels and passes them to adjacent frames for efficient inter-frame information exchange. By fully utilizing the redundant degraded information of underwater videos, UVE-Net completes video enhancement better. Experiments show the effective network design and good performance of UVE-Net.
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Apr 21, 2024



With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
Generative Adversarial Network with Multi-Branch Discriminator for Cross-Species Image-to-Image Translation
Jan 24, 2019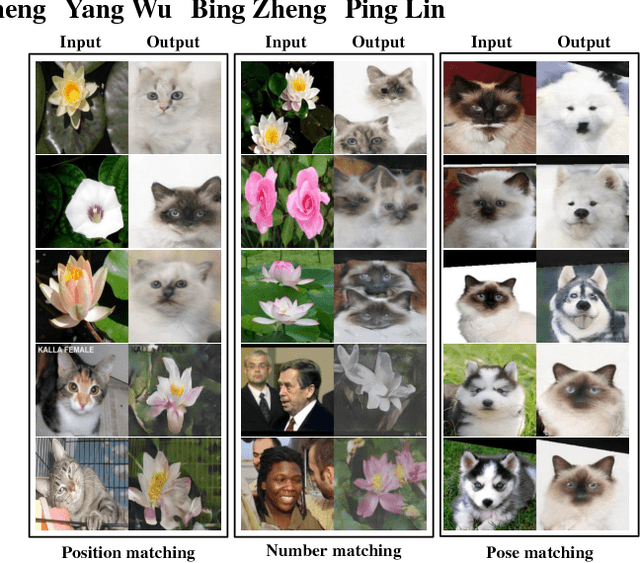
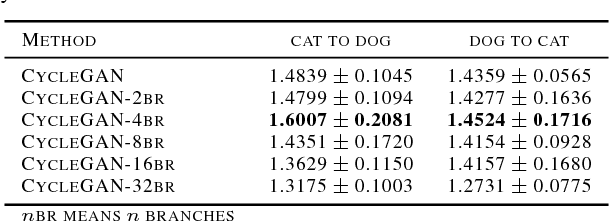
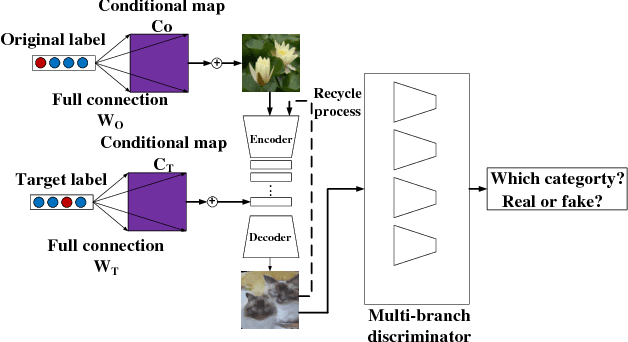

Current approaches have made great progress on image-to-image translation tasks benefiting from the success of image synthesis methods especially generative adversarial networks (GANs). However, existing methods are limited to handling translation tasks between two species while keeping the content matching on the semantic level. A more challenging task would be the translation among more than two species. To explore this new area, we propose a simple yet effective structure of a multi-branch discriminator for enhancing an arbitrary generative adversarial architecture (GAN), named GAN-MBD. It takes advantage of the boosting strategy to break a common discriminator into several smaller ones with fewer parameters, which can enhance the generation and synthesis abilities of GANs efficiently and effectively. Comprehensive experiments show that the proposed multi-branch discriminator can dramatically improve the performance of popular GANs on cross-species image-to-image translation tasks while reducing the number of parameters for computation. The code and some datasets are attached as supplementary materials for reference.
Discriminative Region Proposal Adversarial Networks for High-Quality Image-to-Image Translation
Aug 06, 2018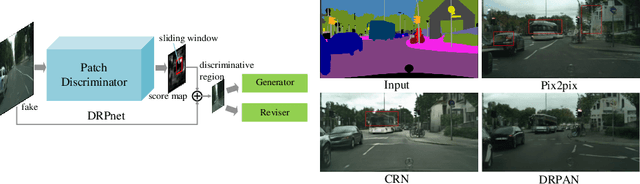
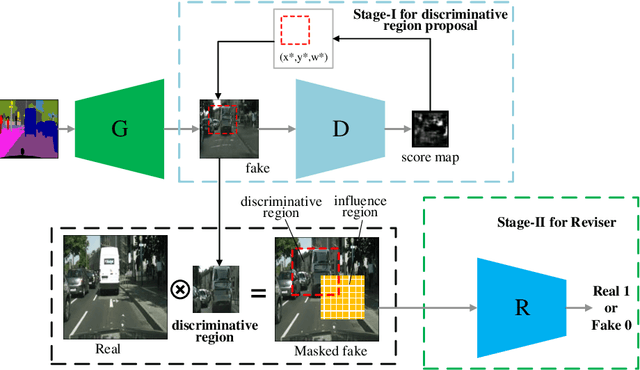
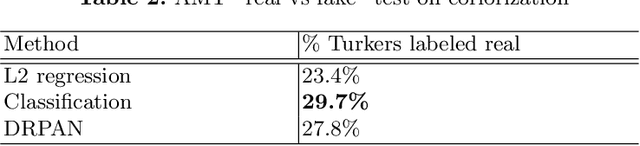
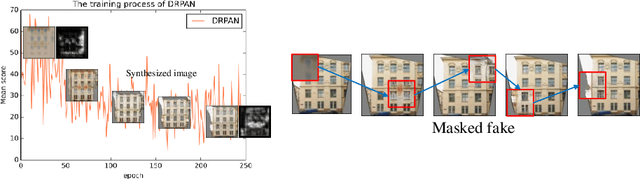
Image-to-image translation has been made much progress with embracing Generative Adversarial Networks (GANs). However, it's still very challenging for translation tasks that require high quality, especially at high-resolution and photorealism. In this paper, we present Discriminative Region Proposal Adversarial Networks (DRPAN) for high-quality image-to-image translation. We decompose the procedure of image-to-image translation task into three iterated steps, first is to generate an image with global structure but some local artifacts (via GAN), second is using our DRPnet to propose the most fake region from the generated image, and third is to implement "image inpainting" on the most fake region for more realistic result through a reviser, so that the system (DRPAN) can be gradually optimized to synthesize images with more attention on the most artifact local part. Experiments on a variety of image-to-image translation tasks and datasets validate that our method outperforms state-of-the-arts for producing high-quality translation results in terms of both human perceptual studies and automatic quantitative measures.
Unpaired Photo-to-Caricature Translation on Faces in the Wild
Jul 25, 2018
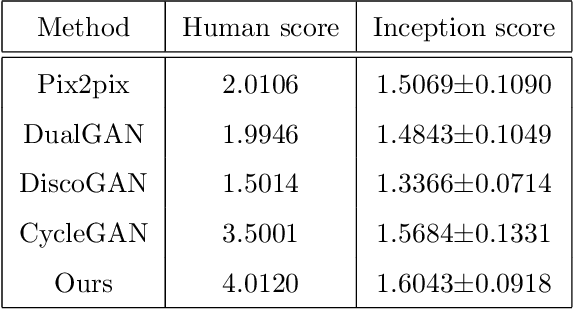
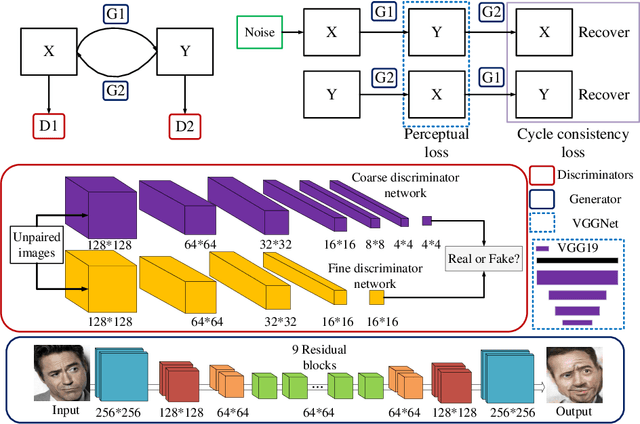
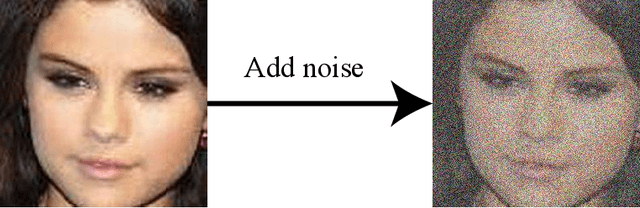
Recently, image-to-image translation has been made much progress owing to the success of conditional Generative Adversarial Networks (cGANs). And some unpaired methods based on cycle consistency loss such as DualGAN, CycleGAN and DiscoGAN are really popular. However, it's still very challenging for translation tasks with the requirement of high-level visual information conversion, such as photo-to-caricature translation that requires satire, exaggeration, lifelikeness and artistry. We present an approach for learning to translate faces in the wild from the source photo domain to the target caricature domain with different styles, which can also be used for other high-level image-to-image translation tasks. In order to capture global structure with local statistics while translation, we design a dual pathway model with one coarse discriminator and one fine discriminator. For generator, we provide one extra perceptual loss in association with adversarial loss and cycle consistency loss to achieve representation learning for two different domains. Also the style can be learned by the auxiliary noise input. Experiments on photo-to-caricature translation of faces in the wild show considerable performance gain of our proposed method over state-of-the-art translation methods as well as its potential real applications.
Peeking the Impact of Points of Interests on Didi
Apr 06, 2018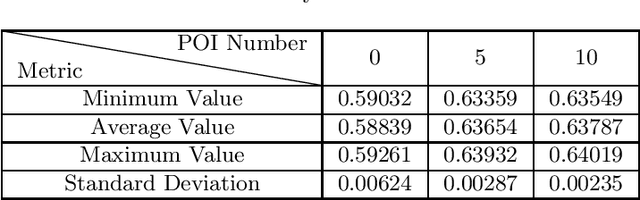
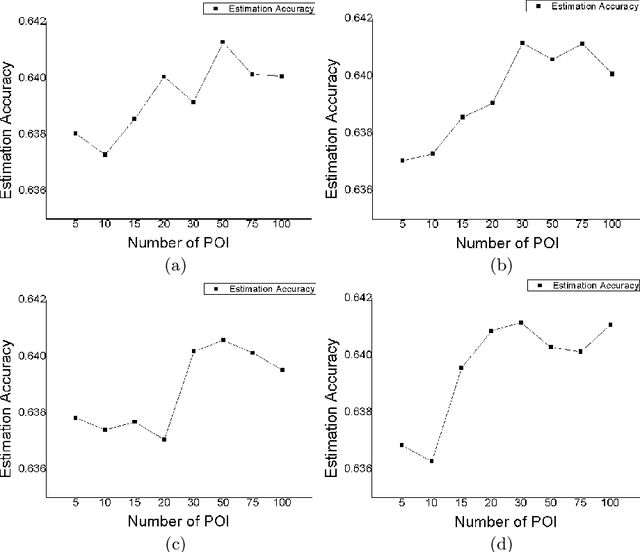
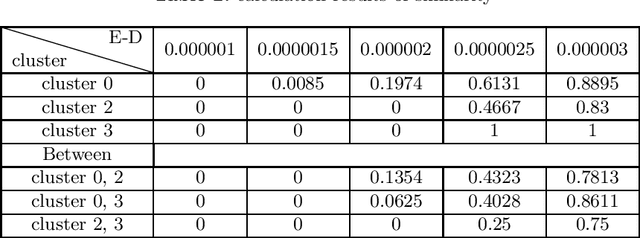
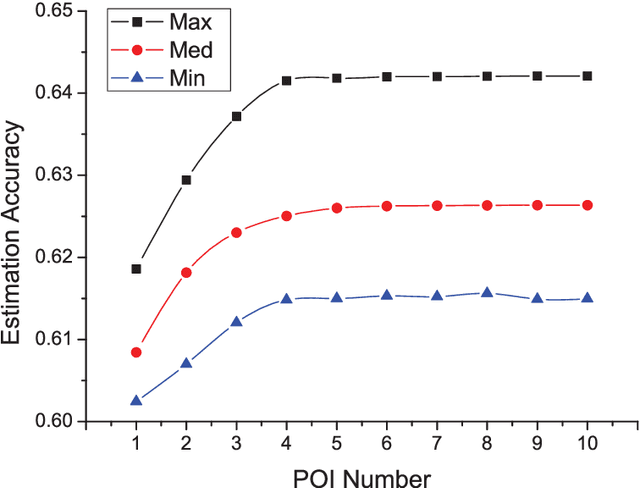
Recently, the online car-hailing service, Didi, has emerged as a leader in the sharing economy. Used by passengers and drivers extensive, it becomes increasingly important for the car-hailing service providers to minimize the waiting time of passengers and optimize the vehicle utilization, thus to improve the overall user experience. Therefore, the supply-demand estimation is an indispensable ingredient of an efficient online car-hailing service. To improve the accuracy of the estimation results, we analyze the implicit relationships between the points of Interest (POI) and the supply-demand gap in this paper. The different categories of POIs have positive or negative effects on the estimation, we propose a POI selection scheme and incorporate it into XGBoost [1] to achieve more accurate estimation results. Our experiment demonstrates our method provides more accurate estimation results and more stable estimation results than the existing methods.
Instance Map based Image Synthesis with a Denoising Generative Adversarial Network
Jan 10, 2018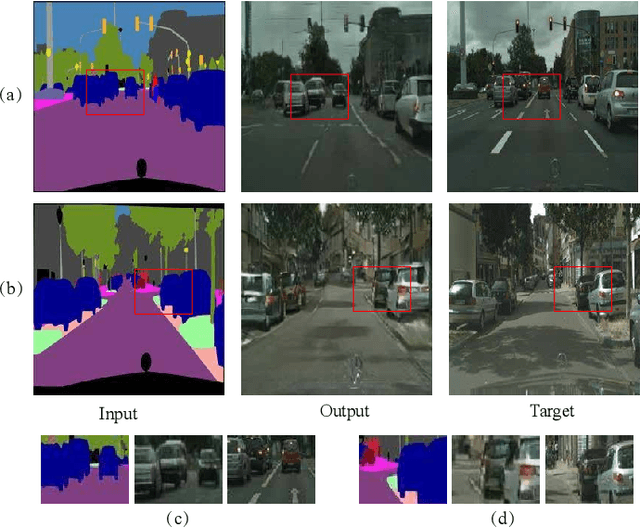



Semantic layouts based Image synthesizing, which has benefited from the success of Generative Adversarial Network (GAN), has drawn much attention in these days. How to enhance the synthesis image equality while keeping the stochasticity of the GAN is still a challenge. We propose a novel denoising framework to handle this problem. The overlapped objects generation is another challenging task when synthesizing images from a semantic layout to a realistic RGB photo. To overcome this deficiency, we include a one-hot semantic label map to force the generator paying more attention on the overlapped objects generation. Furthermore, we improve the loss function of the discriminator by considering perturb loss and cascade layer loss to guide the generation process. We applied our methods on the Cityscapes, Facades and NYU datasets and demonstrate the image generation ability of our model.