 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideCAD: A Lightweight Multimodal Framework for 3D CAD Model Generation via Prefix Embedding
Jun 05, 2026Multi-modal approaches used for 3D CAD generation require substantial computational resources, necessitating efficient training. To address this, we propose GuideCAD, which leverages semantically rich visual-textual representations having only a small number of trainable parameters to generate 3D CAD models. Specifically, GuideCAD uses a mapping network that converts image embeddings into prefix embeddings, enabling a pretrained large language model to integrate visual and textual information. As a result, a transformer-based decoder predicts the construction sequence using the visual-textual embeddings in order to generate the 3D CAD model. For experimental evaluation, we construct a new dataset, referred to as GuideCAD, which consists of text-image pairs. Each pair includes a text prompt that represents a 3D CAD construction sequence and its corresponding 3D CAD image. Our experimental results show that GuideCAD generates comparably high-quality 3D CAD models while using approximately four times fewer parameters and achieving twice the training efficiency compared to fine-tuning approaches. We have released the source code and dataset for our method at: https://github.com/mskimS2/GuideCAD
SPARTA: Scalable and Principled Benchmark of Tree-Structured Multi-hop QA over Text and Tables
Feb 26, 2026Real-world Table-Text question answering (QA) tasks require models that can reason across long text and source tables, traversing multiple hops and executing complex operations such as aggregation. Yet existing benchmarks are small, manually curated - and therefore error-prone - and contain shallow questions that seldom demand more than two hops or invoke aggregations, grouping, or other advanced analytical operations expressible in natural-language queries. We present SPARTA, an end-to-end construction framework that automatically generates large-scale Table-Text QA benchmarks with lightweight human validation, requiring only one quarter of the annotation time of HybridQA. The framework first constructs a reference fact database by enriching each source table with grounding tables whose tuples are atomic facts automatically extracted from the accompanying unstructured passages, then synthesizes nested queries whose number of nested predicates matches the desired hop count. To ensure that every SQL statement is executable and that its verbalization yields a fluent, human-sounding question, we propose two novel techniques: provenance-based refinement, which rewrites any syntactically valid query that returns a non-empty result, and realistic-structure enforcement, which confines generation to post-order traversals of the query graph. The resulting pipeline produces thousands of high-fidelity question-answer pairs covering aggregations, grouping, and deep multi-hop reasoning across text and tables. On SPARTA, state-of-the-art models that reach over 70 F1 on HybridQA or over 50 F1 on OTT-QA drop by more than 30 F1 points, exposing fundamental weaknesses in current cross-modal reasoning. Our benchmark, construction code, and baseline models are available at https://github.com/pshlego/SPARTA/tree/main.
* 10 pages, 5 figures. Published as a conference paper at ICLR 2026. Project page: https://sparta-projectpage.github.io/
A Swap-Adversarial Framework for Improving Domain Generalization in Electroencephalography-Based Parkinson's Disease Prediction
Feb 11, 2026Electroencephalography (ECoG) offers a promising alternative to conventional electrocorticography (EEG) for the early prediction of Parkinson's disease (PD), providing higher spatial resolution and a broader frequency range. However, reproducible comparisons has been limited by ethical constraints in human studies and the lack of open benchmark datasets. To address this gap, we introduce a new dataset, the first reproducible benchmark for PD prediction. It is constructed from long-term ECoG recordings of 6-hydroxydopamine (6-OHDA)-induced rat models and annotated with neural responses measured before and after electrical stimulation. In addition, we propose a Swap-Adversarial Framework (SAF) that mitigates high inter-subject variability and the high-dimensional low-sample-size (HDLSS) problem in ECoG data, while achieving robust domain generalization across ECoG and EEG-based Brain-Computer Interface (BCI) datasets. The framework integrates (1) robust preprocessing, (2) Inter-Subject Balanced Channel Swap (ISBCS) for cross-subject augmentation, and (3) domain-adversarial training to suppress subject-specific bias. ISBCS randomly swaps channels between subjects to reduce inter-subject variability, and domain-adversarial training jointly encourages the model to learn task-relevant shared features. We validated the effectiveness of the proposed method through extensive experiments under cross-subject, cross-session, and cross-dataset settings. Our method consistently outperformed all baselines across all settings, showing the most significant improvements in highly variable environments. Furthermore, the proposed method achieved superior cross-dataset performance between public EEG benchmarks, demonstrating strong generalization capability not only within ECoG but to EEG data. The new dataset and source code will be made publicly available upon publication.
A Technical Report for Polyglot-Ko: Open-Source Large-Scale Korean Language Models
Jun 06, 2023Polyglot is a pioneering project aimed at enhancing the non-English language performance of multilingual language models. Despite the availability of various multilingual models such as mBERT (Devlin et al., 2019), XGLM (Lin et al., 2022), and BLOOM (Scao et al., 2022), researchers and developers often resort to building monolingual models in their respective languages due to the dissatisfaction with the current multilingual models non-English language capabilities. Addressing this gap, we seek to develop advanced multilingual language models that offer improved performance in non-English languages. In this paper, we introduce the Polyglot Korean models, which represent a specific focus rather than being multilingual in nature. In collaboration with TUNiB, our team collected 1.2TB of Korean data meticulously curated for our research journey. We made a deliberate decision to prioritize the development of Korean models before venturing into multilingual models. This choice was motivated by multiple factors: firstly, the Korean models facilitated performance comparisons with existing multilingual models; and finally, they catered to the specific needs of Korean companies and researchers. This paper presents our work in developing the Polyglot Korean models, which propose some steps towards addressing the non-English language performance gap in multilingual language models.
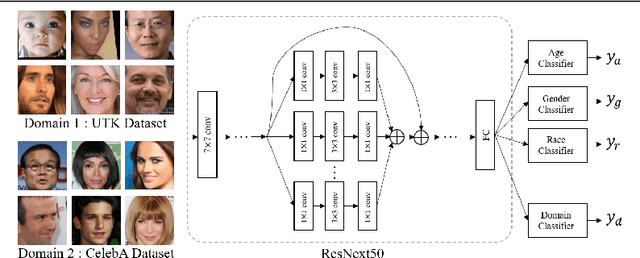
Fair Contrastive Learning for Facial Attribute Classification
Mar 30, 2022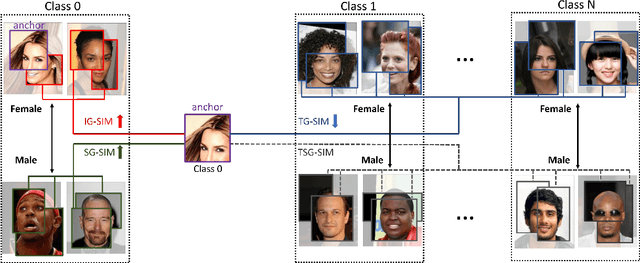
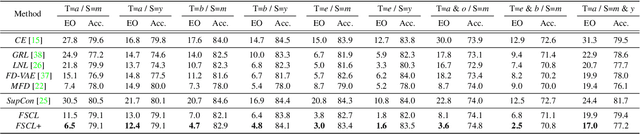
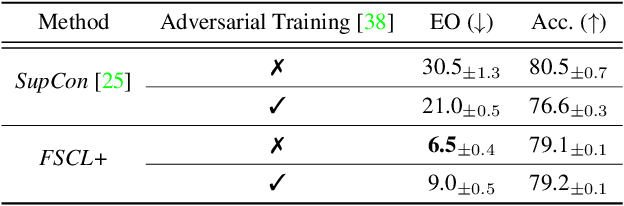
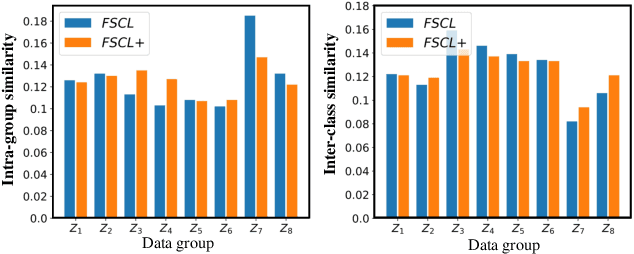
Learning visual representation of high quality is essential for image classification. Recently, a series of contrastive representation learning methods have achieved preeminent success. Particularly, SupCon outperformed the dominant methods based on cross-entropy loss in representation learning. However, we notice that there could be potential ethical risks in supervised contrastive learning. In this paper, we for the first time analyze unfairness caused by supervised contrastive learning and propose a new Fair Supervised Contrastive Loss (FSCL) for fair visual representation learning. Inheriting the philosophy of supervised contrastive learning, it encourages representation of the same class to be closer to each other than that of different classes, while ensuring fairness by penalizing the inclusion of sensitive attribute information in representation. In addition, we introduce a group-wise normalization to diminish the disparities of intra-group compactness and inter-class separability between demographic groups that arouse unfair classification. Through extensive experiments on CelebA and UTK Face, we validate that the proposed method significantly outperforms SupCon and existing state-of-the-art methods in terms of the trade-off between top-1 accuracy and fairness. Moreover, our method is robust to the intensity of data bias and effectively works in incomplete supervised settings. Our code is available at https://github.com/sungho-CoolG/FSCL.
FairFaceGAN: Fairness-aware Facial Image-to-Image Translation
Dec 02, 2020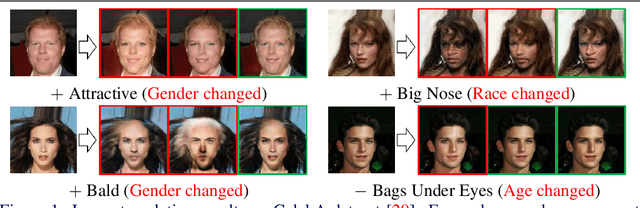

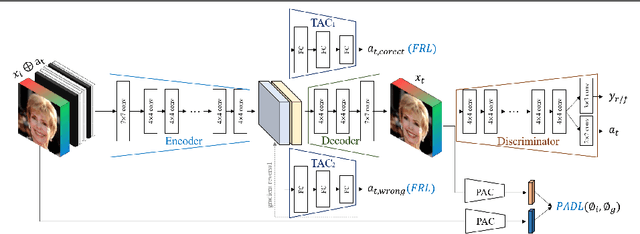
In this paper, we introduce FairFaceGAN, a fairness-aware facial Image-to-Image translation model, mitigating the problem of unwanted translation in protected attributes (e.g., gender, age, race) during facial attributes editing. Unlike existing models, FairFaceGAN learns fair representations with two separate latents - one related to the target attributes to translate, and the other unrelated to them. This strategy enables FairFaceGAN to separate the information about protected attributes and that of target attributes. It also prevents unwanted translation in protected attributes while target attributes editing. To evaluate the degree of fairness, we perform two types of experiments on CelebA dataset. First, we compare the fairness-aware classification performances when augmenting data by existing image translation methods and FairFaceGAN respectively. Moreover, we propose a new fairness metric, namely Frechet Protected Attribute Distance (FPAD), which measures how well protected attributes are preserved. Experimental results demonstrate that FairFaceGAN shows consistent improvements in terms of fairness over the existing image translation models. Further, we also evaluate image translation performances, where FairFaceGAN shows competitive results, compared to those of existing methods.
README: REpresentation learning by fairness-Aware Disentangling MEthod
Jul 07, 2020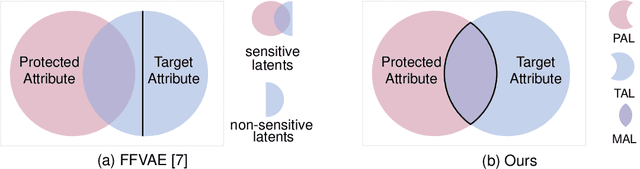

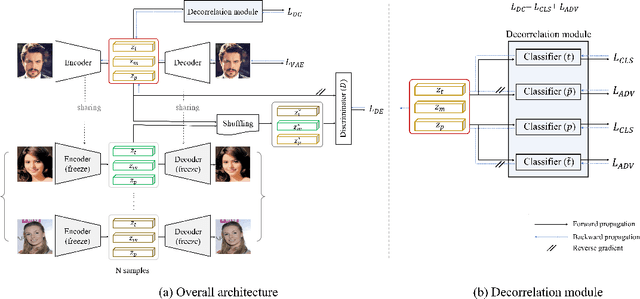
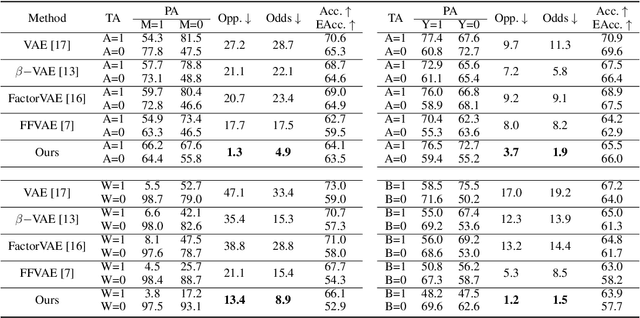
Fair representation learning aims to encode invariant representation with respect to the protected attribute, such as gender or age. In this paper, we design Fairness-aware Disentangling Variational AutoEncoder (FD-VAE) for fair representation learning. This network disentangles latent space into three subspaces with a decorrelation loss that encourages each subspace to contain independent information: 1) target attribute information, 2) protected attribute information, 3) mutual attribute information. After the representation learning, this disentangled representation is leveraged for fairer downstream classification by excluding the subspace with the protected attribute information. We demonstrate the effectiveness of our model through extensive experiments on CelebA and UTK Face datasets. Our method outperforms the previous state-of-the-art method by large margins in terms of equal opportunity and equalized odds.