 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Diff-Oracle: Diffusion Model for Oracle Character Generation with Controllable Styles and Contents
Dec 21, 2023
Deciphering the oracle bone script plays a significant role in Chinese archaeology and philology. However, it is significantly challenging due to the scarcity of oracle character images. To overcome this issue, we propose Diff-Oracle, based on diffusion models (DMs), to generate sufficient controllable oracle characters. In contrast to most DMs that rely on text prompts, we incorporate a style encoder to control style information during the generation process. This encoder extracts style prompts from existing oracle character images, where style details are converted from a CLIP model into a text embedding format. Inspired by ControlNet, we introduce a content encoder to capture desired content information from content images, ensuring the fidelity of character glyphs. To train Diff-Oracle effectively, we propose to obtain pixel-level paired oracle character images (i.e., style and content images) by a pre-trained image-to-image translation model. Extensive qualitative and quantitative experiments conducted on two benchmark datasets, Oracle-241 and OBC306, demonstrate that our Diff-Oracle outperforms existing generative methods in terms of image generation, further enhancing recognition accuracy. Source codes will be available.
SDDM: Score-Decomposed Diffusion Models on Manifolds for Unpaired Image-to-Image Translation
Aug 04, 2023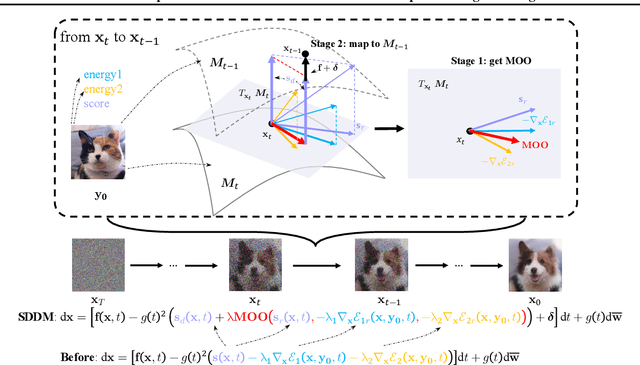
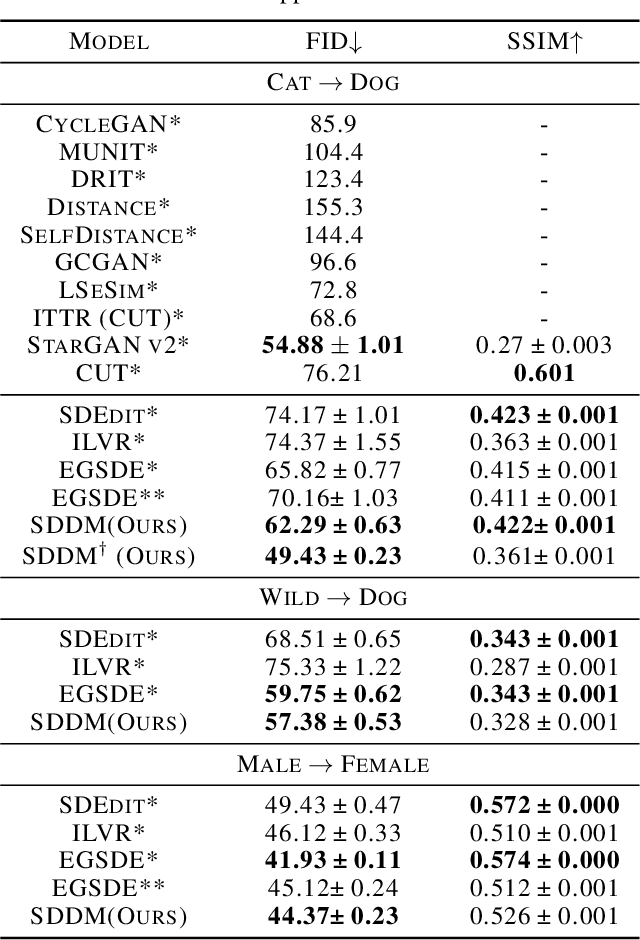
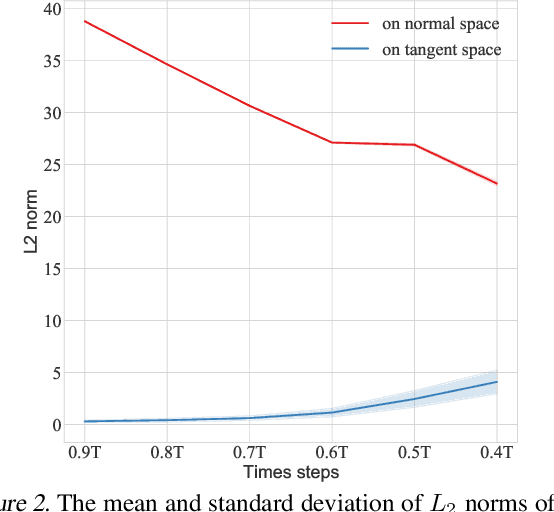

Recent score-based diffusion models (SBDMs) show promising results in unpaired image-to-image translation (I2I). However, existing methods, either energy-based or statistically-based, provide no explicit form of the interfered intermediate generative distributions. This work presents a new score-decomposed diffusion model (SDDM) on manifolds to explicitly optimize the tangled distributions during image generation. SDDM derives manifolds to make the distributions of adjacent time steps separable and decompose the score function or energy guidance into an image ``denoising" part and a content ``refinement" part. To refine the image in the same noise level, we equalize the refinement parts of the score function and energy guidance, which permits multi-objective optimization on the manifold. We also leverage the block adaptive instance normalization module to construct manifolds with lower dimensions but still concentrated with the perturbed reference image. SDDM outperforms existing SBDM-based methods with much fewer diffusion steps on several I2I benchmarks.
Hierarchical Conditional Semi-Paired Image-to-Image Translation For Multi-Task Image Defect Correction On Shopping Websites
Sep 12, 2023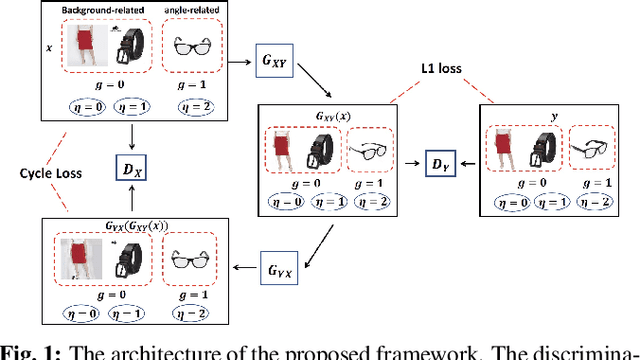
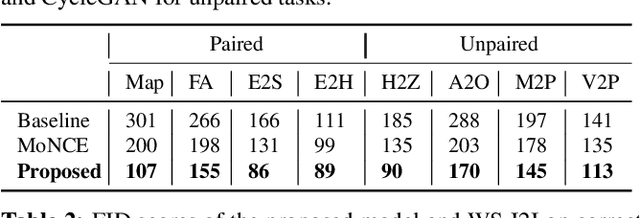
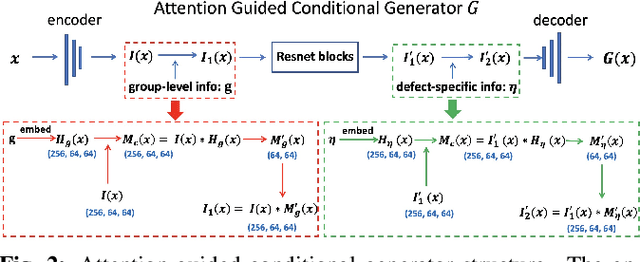
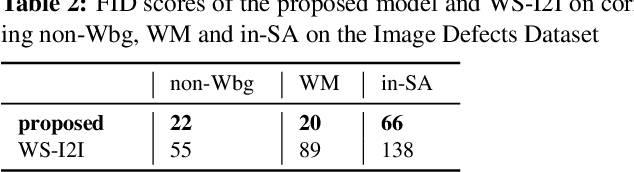
On shopping websites, product images of low quality negatively affect customer experience. Although there are plenty of work in detecting images with different defects, few efforts have been dedicated to correct those defects at scale. A major challenge is that there are thousands of product types and each has specific defects, therefore building defect specific models is unscalable. In this paper, we propose a unified Image-to-Image (I2I) translation model to correct multiple defects across different product types. Our model leverages an attention mechanism to hierarchically incorporate high-level defect groups and specific defect types to guide the network to focus on defect-related image regions. Evaluated on eight public datasets, our model reduces the Frechet Inception Distance (FID) by 24.6% in average compared with MoNCE, the state-of-the-art I2I method. Unlike public data, another practical challenge on shopping websites is that some paired images are of low quality. Therefore we design our model to be semi-paired by combining the L1 loss of paired data with the cycle loss of unpaired data. Tested on a shopping website dataset to correct three image defects, our model reduces (FID) by 63.2% in average compared with WS-I2I, the state-of-the art semi-paired I2I method.
Multi-crop Contrastive Learning for Unsupervised Image-to-Image Translation
Apr 24, 2023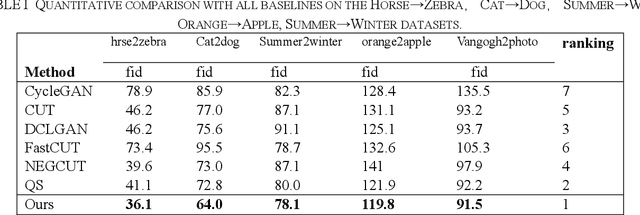
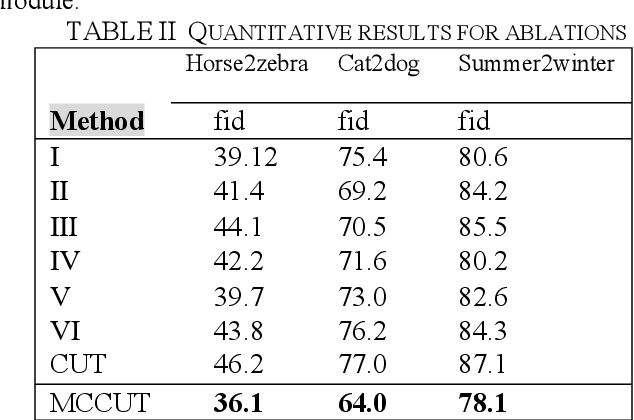
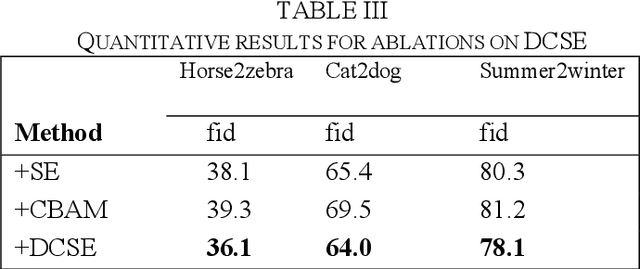
Recently, image-to-image translation methods based on contrastive learning achieved state-of-the-art results in many tasks. However, the negatives are sampled from the input feature spaces in the previous work, which makes the negatives lack diversity. Moreover, in the latent space of the embedings,the previous methods ignore domain consistency between the generated image and the real images of target domain. In this paper, we propose a novel contrastive learning framework for unpaired image-to-image translation, called MCCUT. We utilize the multi-crop views to generate the negatives via the center-crop and the random-crop, which can improve the diversity of negatives and meanwhile increase the quality of negatives. To constrain the embedings in the deep feature space,, we formulate a new domain consistency loss function, which encourages the generated images to be close to the real images in the embedding space of same domain. Furthermore, we present a dual coordinate channel attention network by embedding positional information into SENet, which called DCSE module. We employ the DCSE module in the design of generator, which makes the generator pays more attention to channels with greater weight. In many image-to-image translation tasks, our method achieves state-of-the-art results, and the advantages of our method have been proved through extensive comparison experiments and ablation research.
GP-UNIT: Generative Prior for Versatile Unsupervised Image-to-Image Translation
Jun 07, 2023

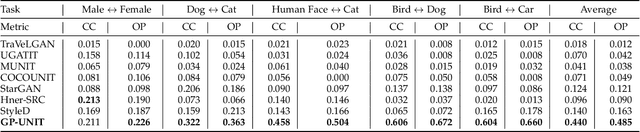

Recent advances in deep learning have witnessed many successful unsupervised image-to-image translation models that learn correspondences between two visual domains without paired data. However, it is still a great challenge to build robust mappings between various domains especially for those with drastic visual discrepancies. In this paper, we introduce a novel versatile framework, Generative Prior-guided UNsupervised Image-to-image Translation (GP-UNIT), that improves the quality, applicability and controllability of the existing translation models. The key idea of GP-UNIT is to distill the generative prior from pre-trained class-conditional GANs to build coarse-level cross-domain correspondences, and to apply the learned prior to adversarial translations to excavate fine-level correspondences. With the learned multi-level content correspondences, GP-UNIT is able to perform valid translations between both close domains and distant domains. For close domains, GP-UNIT can be conditioned on a parameter to determine the intensity of the content correspondences during translation, allowing users to balance between content and style consistency. For distant domains, semi-supervised learning is explored to guide GP-UNIT to discover accurate semantic correspondences that are hard to learn solely from the appearance. We validate the superiority of GP-UNIT over state-of-the-art translation models in robust, high-quality and diversified translations between various domains through extensive experiments.
Hierarchy Flow For High-Fidelity Image-to-Image Translation
Aug 14, 2023
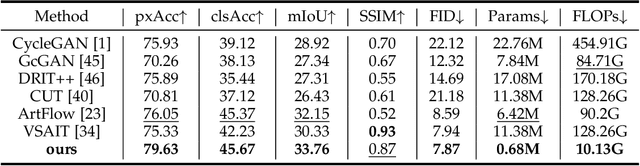
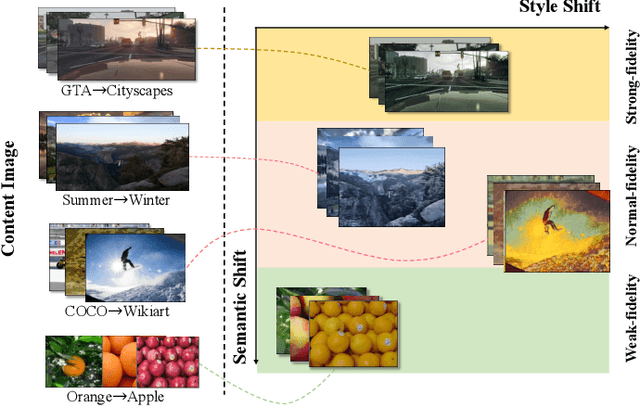
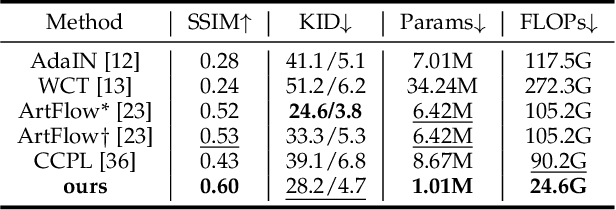
Image-to-image (I2I) translation comprises a wide spectrum of tasks. Here we divide this problem into three levels: strong-fidelity translation, normal-fidelity translation, and weak-fidelity translation, indicating the extent to which the content of the original image is preserved. Although existing methods achieve good performance in weak-fidelity translation, they fail to fully preserve the content in both strong- and normal-fidelity tasks, e.g. sim2real, style transfer and low-level vision. In this work, we propose Hierarchy Flow, a novel flow-based model to achieve better content preservation during translation. Specifically, 1) we first unveil the drawbacks of standard flow-based models when applied to I2I translation. 2) Next, we propose a new design, namely hierarchical coupling for reversible feature transformation and multi-scale modeling, to constitute Hierarchy Flow. 3) Finally, we present a dedicated aligned-style loss for a better trade-off between content preservation and stylization during translation. Extensive experiments on a wide range of I2I translation benchmarks demonstrate that our approach achieves state-of-the-art performance, with convincing advantages in both strong- and normal-fidelity tasks. Code and models will be at https://github.com/WeichenFan/HierarchyFlow.
Open-DDVM: A Reproduction and Extension of Diffusion Model for Optical Flow Estimation
Dec 04, 2023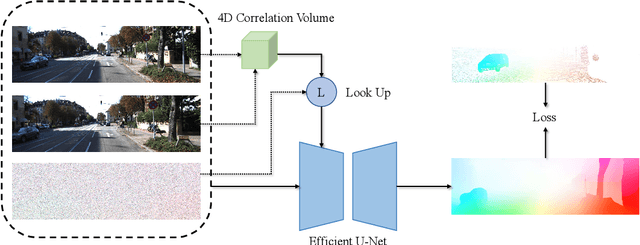

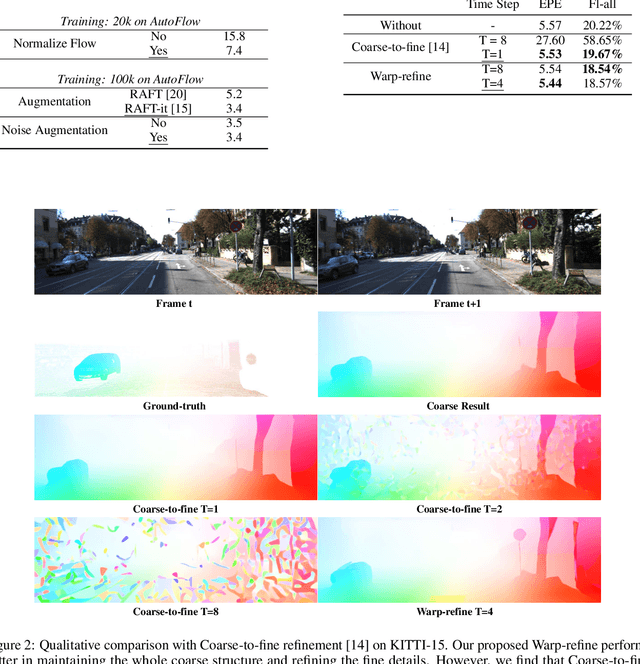

Recently, Google proposes DDVM which for the first time demonstrates that a general diffusion model for image-to-image translation task works impressively well on optical flow estimation task without any specific designs like RAFT. However, DDVM is still a closed-source model with the expensive and private Palette-style pretraining. In this technical report, we present the first open-source DDVM by reproducing it. We study several design choices and find those important ones. By training on 40k public data with 4 GPUs, our reproduction achieves comparable performance to the closed-source DDVM. The code and model have been released in https://github.com/DQiaole/FlowDiffusion_pytorch.
Contrastive Denoising Score for Text-guided Latent Diffusion Image Editing
Nov 30, 2023With the remarkable advent of text-to-image diffusion models, image editing methods have become more diverse and continue to evolve. A promising recent approach in this realm is Delta Denoising Score (DDS) - an image editing technique based on Score Distillation Sampling (SDS) framework that leverages the rich generative prior of text-to-image diffusion models. However, relying solely on the difference between scoring functions is insufficient for preserving specific structural elements from the original image, a crucial aspect of image editing. Inspired by the similarity and importance differences between DDS and the contrastive learning for unpaired image-to-image translation (CUT), here we present an embarrassingly simple yet very powerful modification of DDS, called Contrastive Denoising Score (CDS), for latent diffusion models (LDM). Specifically, to enforce structural correspondence between the input and output while maintaining the controllability of contents, we introduce a straightforward approach to regulate structural consistency using CUT loss within the DDS framework. To calculate this loss, instead of employing auxiliary networks, we utilize the intermediate features of LDM, in particular, those from the self-attention layers, which possesses rich spatial information. Our approach enables zero-shot image-to-image translation and neural radiance field (NeRF) editing, achieving a well-balanced interplay between maintaining the structural details and transforming content. Qualitative results and comparisons demonstrates the effectiveness of our proposed method. Project page with code is available at https://hyelinnam.github.io/CDS/.
Stable diffusion for Data Augmentation in COCO and Weed Datasets
Dec 11, 2023Generative models have increasingly impacted relative tasks, from computer vision to interior design and other fields. Stable diffusion is an outstanding diffusion model that paves the way for producing high-resolution images with thorough details from text prompts or reference images. It will be an interesting topic about gaining improvements for small datasets with image-sparse categories. This study utilized seven common categories and three widespread weed species to evaluate the efficiency of a stable diffusion model. In detail, Stable diffusion was used to generate synthetic images belonging to these classes; three techniques (i.e., Image-to-image translation, Dreambooth, and ControlNet) based on stable diffusion were leveraged for image generation with different focuses. Then, classification and detection tasks were conducted based on these synthetic images, whose performance was compared to the models trained on original images. Promising results have been achieved in some classes. This seminal study may expedite the adaption of stable diffusion models to different fields.
Unveiling Spaces: Architecturally meaningful semantic descriptions from images of interior spaces
Dec 19, 2023There has been a growing adoption of computer vision tools and technologies in architectural design workflows over the past decade. Notable use cases include point cloud generation, visual content analysis, and spatial awareness for robotic fabrication. Multiple image classification, object detection, and semantic pixel segmentation models have become popular for the extraction of high-level symbolic descriptions and semantic content from two-dimensional images and videos. However, a major challenge in this regard has been the extraction of high-level architectural structures (walls, floors, ceilings windows etc.) from diverse imagery where parts of these elements are occluded by furniture, people, or other non-architectural elements. This project aims to tackle this problem by proposing models that are capable of extracting architecturally meaningful semantic descriptions from two-dimensional scenes of populated interior spaces. 1000 virtual classrooms are parametrically generated, randomized along key spatial parameters such as length, width, height, and door/window positions. The positions of cameras, and non-architectural visual obstructions (furniture/objects) are also randomized. A Generative Adversarial Network (GAN) for image-to-image translation (Pix2Pix) is trained on synthetically generated rendered images of these enclosures, along with corresponding image abstractions representing high-level architectural structure. The model is then tested on unseen synthetic imagery of new enclosures, and outputs are compared to ground truth using pixel-wise comparison for evaluation. A similar model evaluation is also carried out on photographs of existing indoor enclosures, to measure its performance in real-world settings.