 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
Face Generation and Editing with StyleGAN: A Survey
Dec 18, 2022



Our goal with this survey is to provide an overview of the state of the art deep learning technologies for face generation and editing. We will cover popular latest architectures and discuss key ideas that make them work, such as inversion, latent representation, loss functions, training procedures, editing methods, and cross domain style transfer. We particularly focus on GAN-based architectures that have culminated in the StyleGAN approaches, which allow generation of high-quality face images and offer rich interfaces for controllable semantics editing and preserving photo quality. We aim to provide an entry point into the field for readers that have basic knowledge about the field of deep learning and are looking for an accessible introduction and overview.
StyleFlow For Content-Fixed Image to Image Translation
Jul 05, 2022

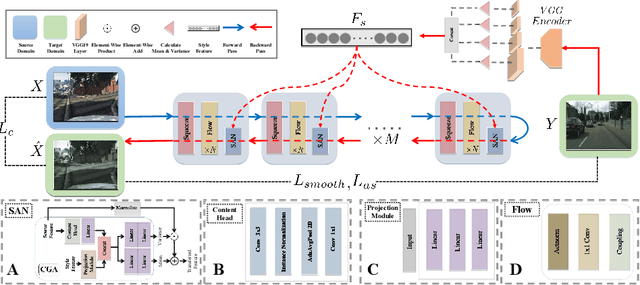

Image-to-image (I2I) translation is a challenging topic in computer vision. We divide this problem into three tasks: strongly constrained translation, normally constrained translation, and weakly constrained translation. The constraint here indicates the extent to which the content or semantic information in the original image is preserved. Although previous approaches have achieved good performance in weakly constrained tasks, they failed to fully preserve the content in both strongly and normally constrained tasks, including photo-realism synthesis, style transfer, and colorization, etc. To achieve content-preserving transfer in strongly constrained and normally constrained tasks, we propose StyleFlow, a new I2I translation model that consists of normalizing flows and a novel Style-Aware Normalization (SAN) module. With the invertible network structure, StyleFlow first projects input images into deep feature space in the forward pass, while the backward pass utilizes the SAN module to perform content-fixed feature transformation and then projects back to image space. Our model supports both image-guided translation and multi-modal synthesis. We evaluate our model in several I2I translation benchmarks, and the results show that the proposed model has advantages over previous methods in both strongly constrained and normally constrained tasks.
Generative Artisan: A Semantic-Aware and Controllable CLIPstyler
Jul 23, 2022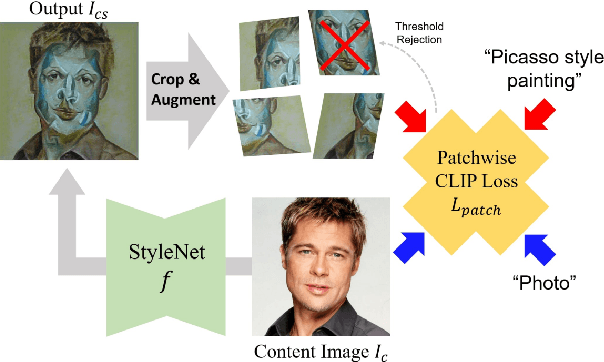
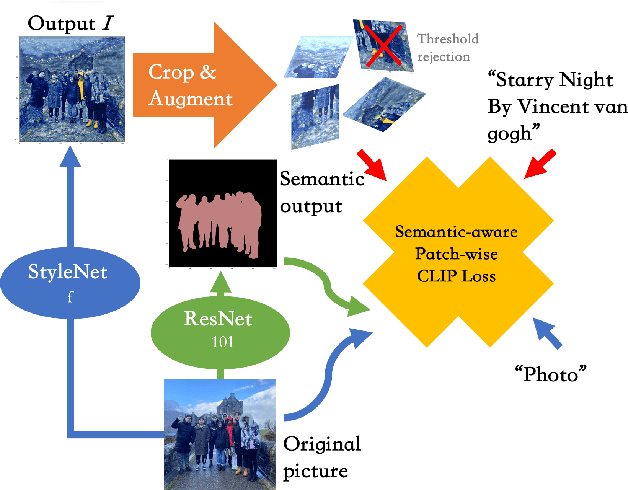
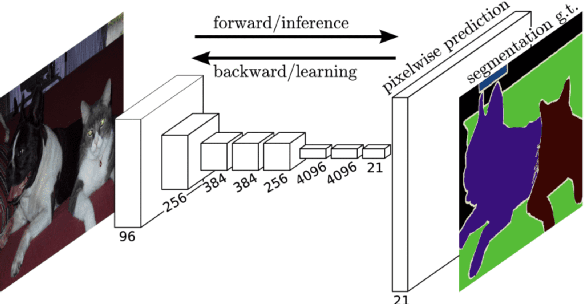
Recall that most of the current image style transfer methods require the user to give an image of a particular style and then extract that styling feature and texture to generate the style of an image, but there are still some problems: the user may not have a reference style image, or it may be difficult to summarise the desired style in mind with just one image. The recently proposed CLIPstyler has solved this problem, which is able to perform style transfer based only on the provided description of the style image. Although CLIPstyler can achieve good performance when landscapes or portraits appear alone, it can blur the people and lose the original semantics when people and landscapes coexist. Based on these issues, we demonstrate a novel framework that uses a pre-trained CLIP text-image embedding model and guides image style transfer through an FCN semantic segmentation network. Specifically, we solve the portrait over-styling problem for both selfies and real-world landscape with human subjects photos, enhance the contrast between the effect of style transfer in portrait and landscape, and make the degree of image style transfer in different semantic parts fully controllable. Our Generative Artisan resolve the failure case of CLIPstyler and yield both qualitative and quantitative methods to prove ours have much better results than CLIPstyler in both selfies and real-world landscape with human subjects photos. This improvement makes it possible to commercialize our framework for business scenarios such as retouching graphics software.
Unsupervised Coherent Video Cartoonization with Perceptual Motion Consistency
Apr 02, 2022
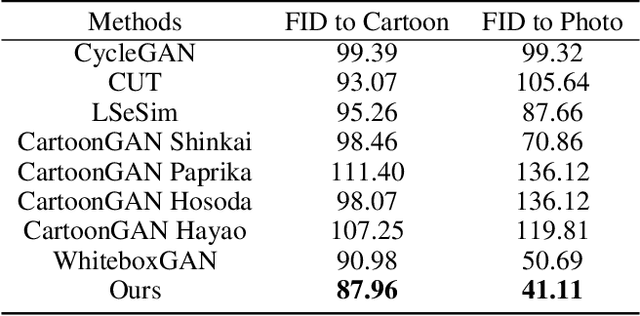

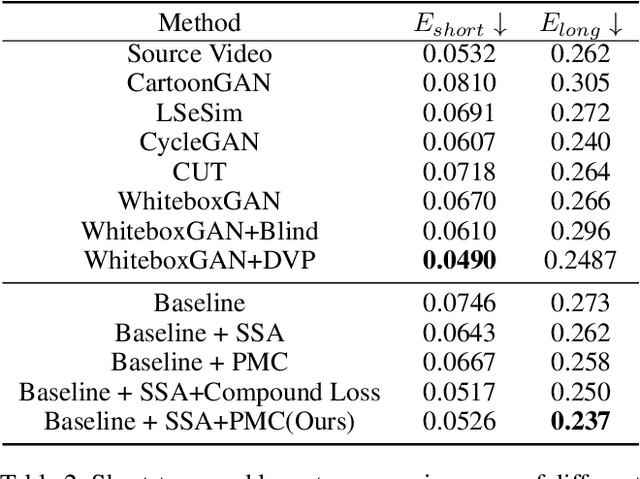
In recent years, creative content generations like style transfer and neural photo editing have attracted more and more attention. Among these, cartoonization of real-world scenes has promising applications in entertainment and industry. Different from image translations focusing on improving the style effect of generated images, video cartoonization has additional requirements on the temporal consistency. In this paper, we propose a spatially-adaptive semantic alignment framework with perceptual motion consistency for coherent video cartoonization in an unsupervised manner. The semantic alignment module is designed to restore deformation of semantic structure caused by spatial information lost in the encoder-decoder architecture. Furthermore, we devise the spatio-temporal correlative map as a style-independent, global-aware regularization on the perceptual motion consistency. Deriving from similarity measurement of high-level features in photo and cartoon frames, it captures global semantic information beyond raw pixel-value in optical flow. Besides, the similarity measurement disentangles temporal relationships from domain-specific style properties, which helps regularize the temporal consistency without hurting style effects of cartoon images. Qualitative and quantitative experiments demonstrate our method is able to generate highly stylistic and temporal consistent cartoon videos.
APRNet: Attention-based Pixel-wise Rendering Network for Photo-Realistic Text Image Generation
Mar 15, 2022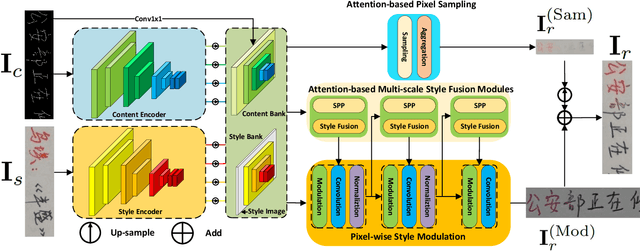

Style-guided text image generation tries to synthesize text image by imitating reference image's appearance while keeping text content unaltered. The text image appearance includes many aspects. In this paper, we focus on transferring style image's background and foreground color patterns to the content image to generate photo-realistic text image. To achieve this goal, we propose 1) a content-style cross attention based pixel sampling approach to roughly mimicking the style text image's background; 2) a pixel-wise style modulation technique to transfer varying color patterns of the style image to the content image spatial-adaptively; 3) a cross attention based multi-scale style fusion approach to solving text foreground misalignment issue between style and content images; 4) an image patch shuffling strategy to create style, content and ground truth image tuples for training. Experimental results on Chinese handwriting text image synthesis with SCUT-HCCDoc and CASIA-OLHWDB datasets demonstrate that the proposed method can improve the quality of synthetic text images and make them more photo-realistic.
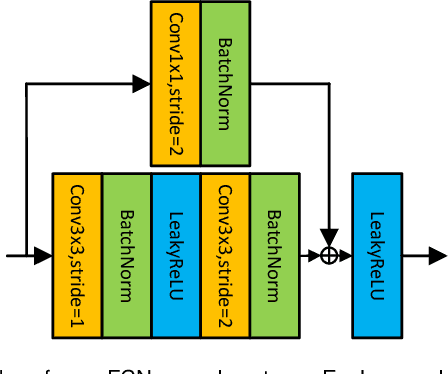
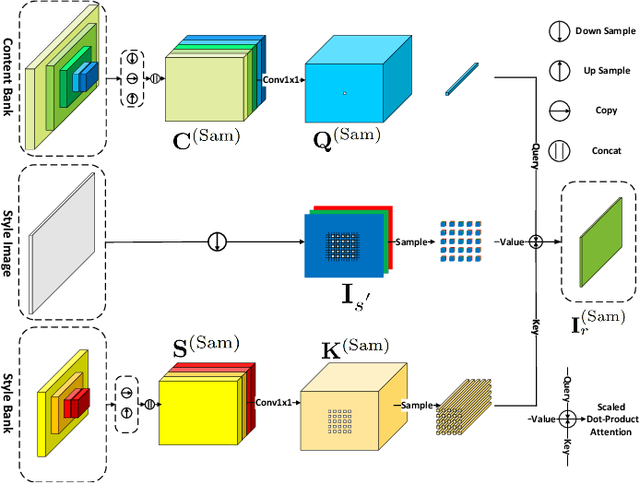
PCA-Based Knowledge Distillation Towards Lightweight and Content-Style Balanced Photorealistic Style Transfer Models
Mar 25, 2022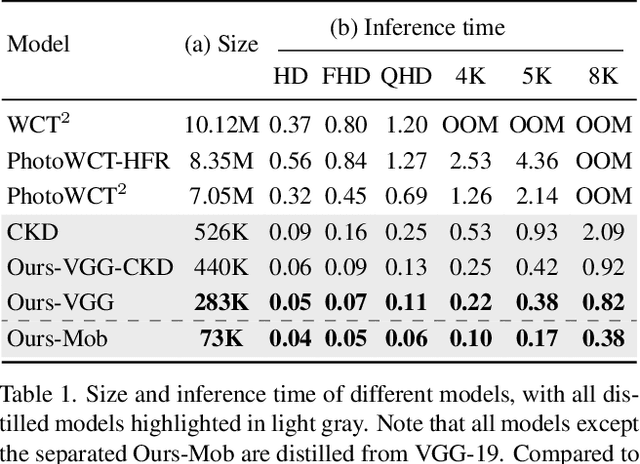
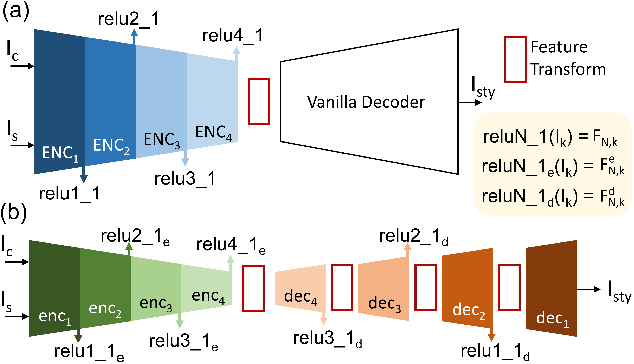
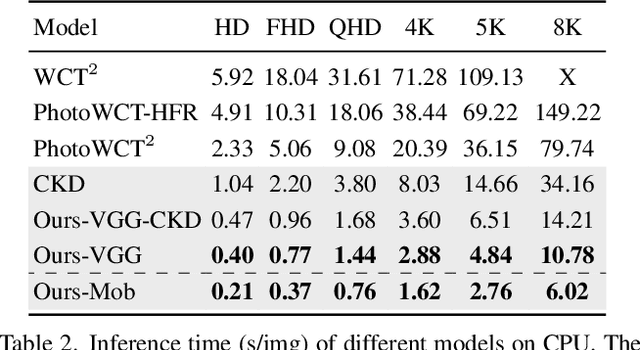
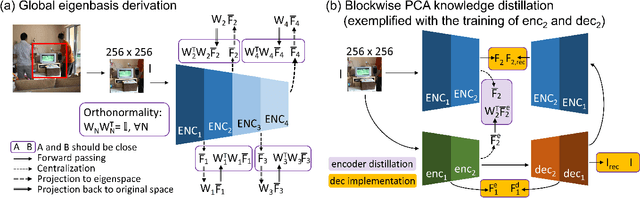
Photorealistic style transfer entails transferring the style of a reference image to another image so the result seems like a plausible photo. Our work is inspired by the observation that existing models are slow due to their large sizes. We introduce PCA-based knowledge distillation to distill lightweight models and show it is motivated by theory. To our knowledge, this is the first knowledge distillation method for photorealistic style transfer. Our experiments demonstrate its versatility for use with different backbone architectures, VGG and MobileNet, across six image resolutions. Compared to existing models, our top-performing model runs at speeds 5-20x faster using at most 1\% of the parameters. Additionally, our distilled models achieve a better balance between stylization strength and content preservation than existing models. To support reproducing our method and models, we share the code at \textit{https://github.com/chiutaiyin/PCA-Knowledge-Distillation}.
3D Photo Stylization: Learning to Generate Stylized Novel Views from a Single Image
Dec 04, 2021
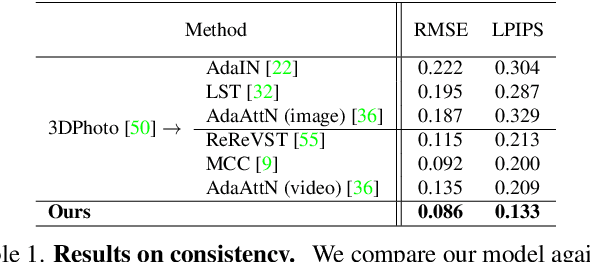

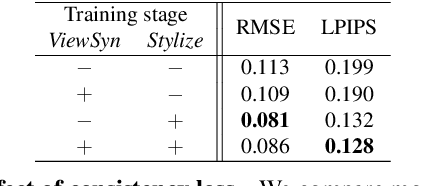
Visual content creation has spurred a soaring interest given its applications in mobile photography and AR / VR. Style transfer and single-image 3D photography as two representative tasks have so far evolved independently. In this paper, we make a connection between the two, and address the challenging task of 3D photo stylization - generating stylized novel views from a single image given an arbitrary style. Our key intuition is that style transfer and view synthesis have to be jointly modeled for this task. To this end, we propose a deep model that learns geometry-aware content features for stylization from a point cloud representation of the scene, resulting in high-quality stylized images that are consistent across views. Further, we introduce a novel training protocol to enable the learning using only 2D images. We demonstrate the superiority of our method via extensive qualitative and quantitative studies, and showcase key applications of our method in light of the growing demand for 3D content creation from 2D image assets.
DeepObjStyle: Deep Object-based Photo Style Transfer
Dec 11, 2020
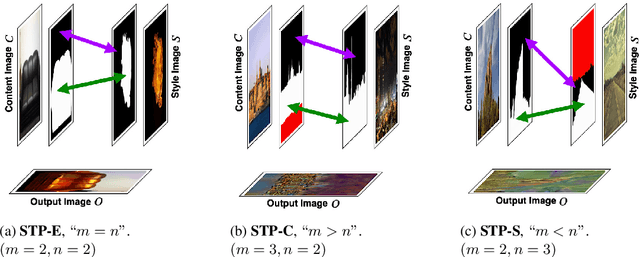


One of the major challenges of style transfer is the appropriate image features supervision between the output image and the input (style and content) images. An efficient strategy would be to define an object map between the objects of the style and the content images. However, such a mapping is not well established when there are semantic objects of different types and numbers in the style and the content images. It also leads to content mismatch in the style transfer output, which could reduce the visual quality of the results. We propose an object-based style transfer approach, called DeepObjStyle, for the style supervision in the training data-independent framework. DeepObjStyle preserves the semantics of the objects and achieves better style transfer in the challenging scenario when the style and the content images have a mismatch of image features. We also perform style transfer of images containing a word cloud to demonstrate that DeepObjStyle enables an appropriate image features supervision. We validate the results using quantitative comparisons and user studies.
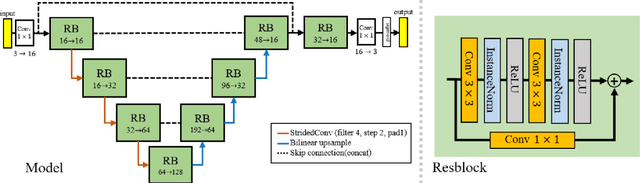
SinIR: Efficient General Image Manipulation with Single Image Reconstruction
Jun 14, 2021

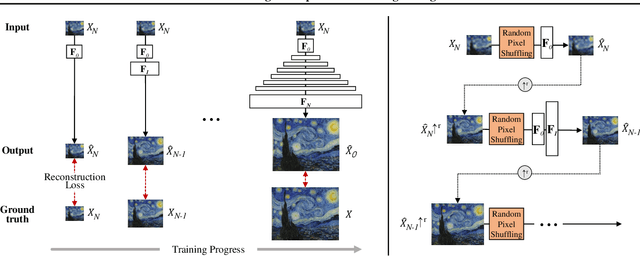
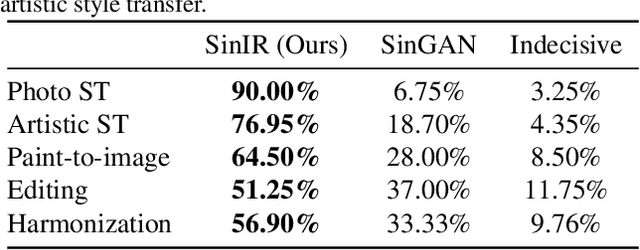
We propose SinIR, an efficient reconstruction-based framework trained on a single natural image for general image manipulation, including super-resolution, editing, harmonization, paint-to-image, photo-realistic style transfer, and artistic style transfer. We train our model on a single image with cascaded multi-scale learning, where each network at each scale is responsible for image reconstruction. This reconstruction objective greatly reduces the complexity and running time of training, compared to the GAN objective. However, the reconstruction objective also exacerbates the output quality. Therefore, to solve this problem, we further utilize simple random pixel shuffling, which also gives control over manipulation, inspired by the Denoising Autoencoder. With quantitative evaluation, we show that SinIR has competitive performance on various image manipulation tasks. Moreover, with a much simpler training objective (i.e., reconstruction), SinIR is trained 33.5 times faster than SinGAN (for 500 X 500 images) that solves similar tasks. Our code is publicly available at github.com/YooJiHyeong/SinIR.
DCT-Net: Domain-Calibrated Translation for Portrait Stylization
Jul 06, 2022
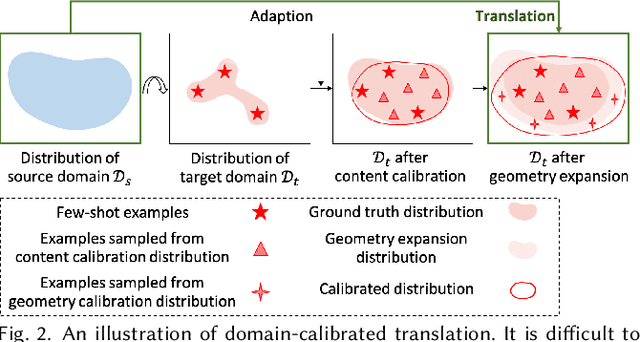
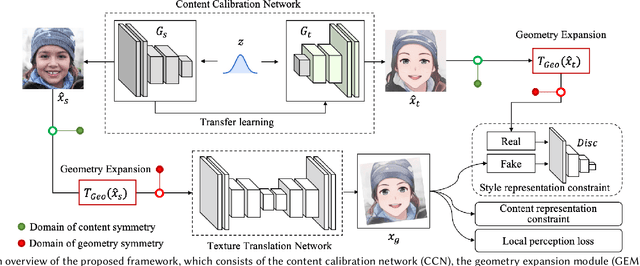
This paper introduces DCT-Net, a novel image translation architecture for few-shot portrait stylization. Given limited style exemplars ($\sim$100), the new architecture can produce high-quality style transfer results with advanced ability to synthesize high-fidelity contents and strong generality to handle complicated scenes (e.g., occlusions and accessories). Moreover, it enables full-body image translation via one elegant evaluation network trained by partial observations (i.e., stylized heads). Few-shot learning based style transfer is challenging since the learned model can easily become overfitted in the target domain, due to the biased distribution formed by only a few training examples. This paper aims to handle the challenge by adopting the key idea of "calibration first, translation later" and exploring the augmented global structure with locally-focused translation. Specifically, the proposed DCT-Net consists of three modules: a content adapter borrowing the powerful prior from source photos to calibrate the content distribution of target samples; a geometry expansion module using affine transformations to release spatially semantic constraints; and a texture translation module leveraging samples produced by the calibrated distribution to learn a fine-grained conversion. Experimental results demonstrate the proposed method's superiority over the state of the art in head stylization and its effectiveness on full image translation with adaptive deformations.