 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLine Search-Based Feature Transformation for Fast, Stable, and Tunable Content-Style Control in Photorealistic Style Transfer
Oct 12, 2022
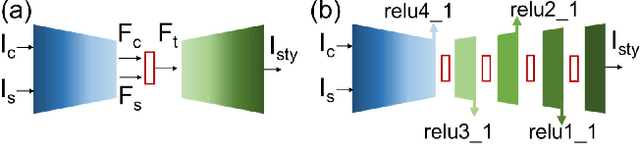
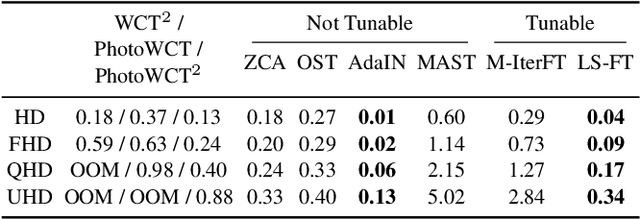

Photorealistic style transfer is the task of synthesizing a realistic-looking image when adapting the content from one image to appear in the style of another image. Modern models commonly embed a transformation that fuses features describing the content image and style image and then decodes the resulting feature into a stylized image. We introduce a general-purpose transformation that enables controlling the balance between how much content is preserved and the strength of the infused style. We offer the first experiments that demonstrate the performance of existing transformations across different style transfer models and demonstrate how our transformation performs better in its ability to simultaneously run fast, produce consistently reasonable results, and control the balance between content and style in different models. To support reproducing our method and models, we share the code at https://github.com/chiutaiyin/LS-FT.
PCA-Based Knowledge Distillation Towards Lightweight and Content-Style Balanced Photorealistic Style Transfer Models
Mar 25, 2022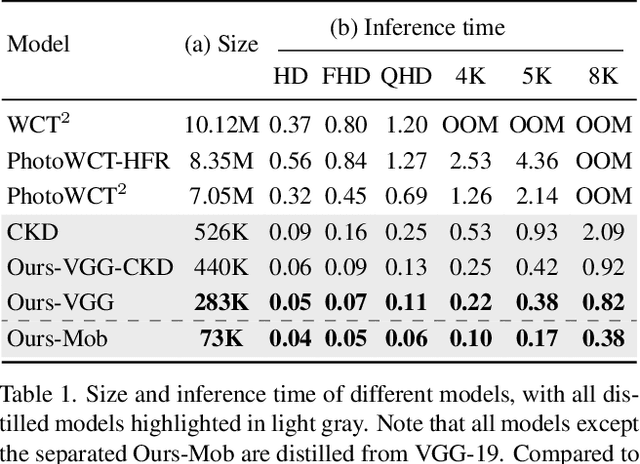
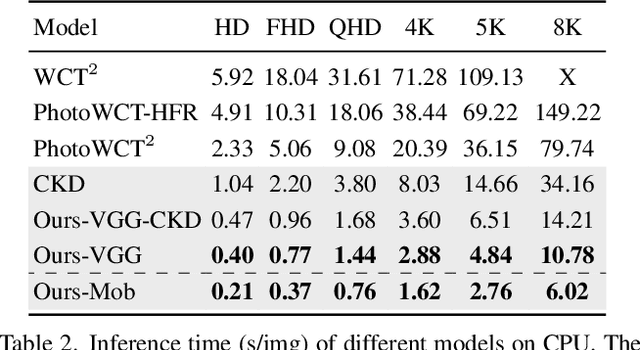
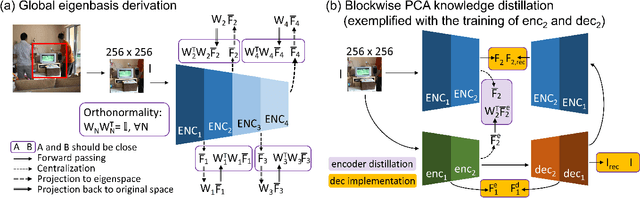
Photorealistic style transfer entails transferring the style of a reference image to another image so the result seems like a plausible photo. Our work is inspired by the observation that existing models are slow due to their large sizes. We introduce PCA-based knowledge distillation to distill lightweight models and show it is motivated by theory. To our knowledge, this is the first knowledge distillation method for photorealistic style transfer. Our experiments demonstrate its versatility for use with different backbone architectures, VGG and MobileNet, across six image resolutions. Compared to existing models, our top-performing model runs at speeds 5-20x faster using at most 1\% of the parameters. Additionally, our distilled models achieve a better balance between stylization strength and content preservation than existing models. To support reproducing our method and models, we share the code at \textit{https://github.com/chiutaiyin/PCA-Knowledge-Distillation}.
PhotoWCT$^2$: Compact Autoencoder for Photorealistic Style Transfer Resulting from Blockwise Training and Skip Connections of High-Frequency Residuals
Oct 22, 2021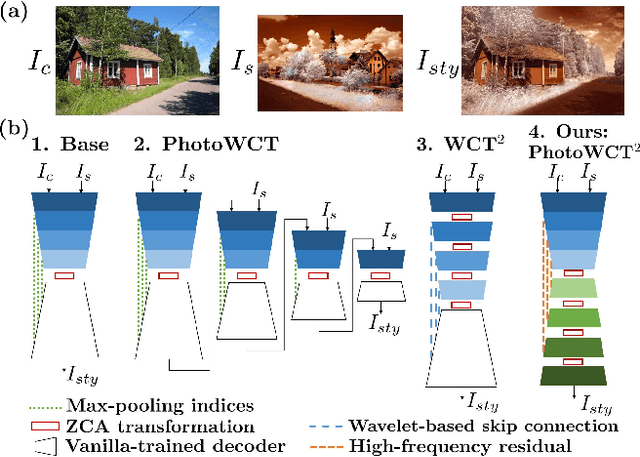

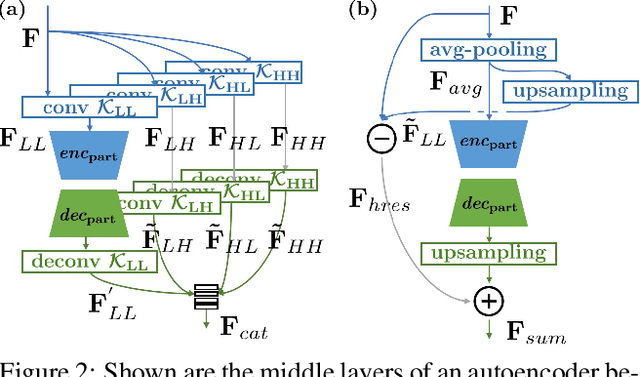
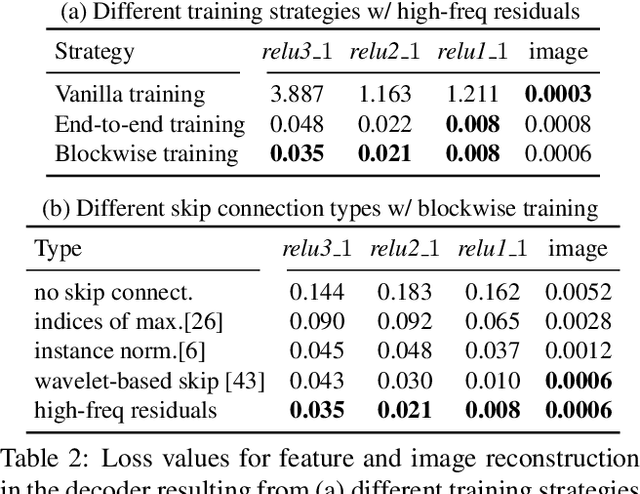
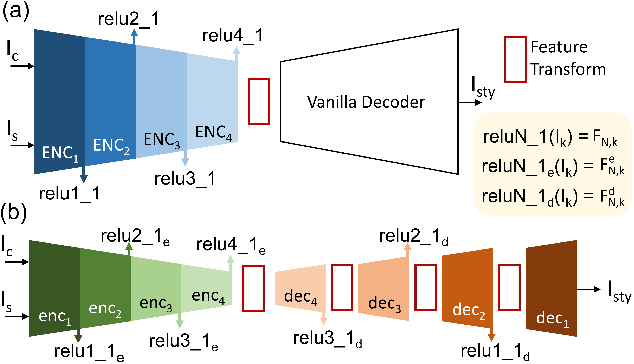
Photorealistic style transfer is an image editing task with the goal to modify an image to match the style of another image while ensuring the result looks like a real photograph. A limitation of existing models is that they have many parameters, which in turn prevents their use for larger image resolutions and leads to slower run-times. We introduce two mechanisms that enable our design of a more compact model that we call PhotoWCT$^2$, which preserves state-of-art stylization strength and photorealism. First, we introduce blockwise training to perform coarse-to-fine feature transformations that enable state-of-art stylization strength in a single autoencoder in place of the inefficient cascade of four autoencoders used in PhotoWCT. Second, we introduce skip connections of high-frequency residuals in order to preserve image quality when applying the sequential coarse-to-fine feature transformations. Our PhotoWCT$^2$ model requires fewer parameters (e.g., 30.3\% fewer) while supporting higher resolution images (e.g., 4K) and achieving faster stylization than existing models.
Assessing Image Quality Issues for Real-World Problems
Mar 30, 2020
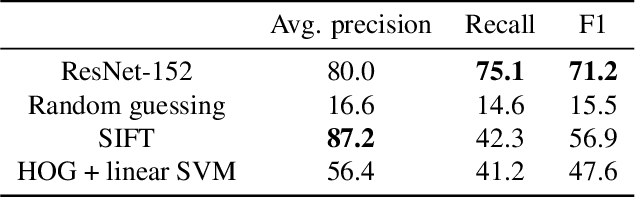
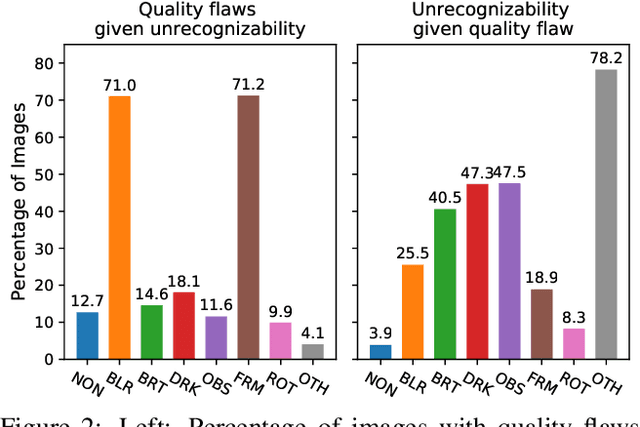
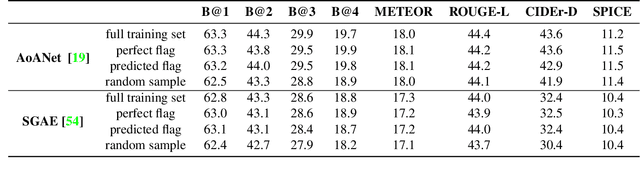
We introduce a new large-scale dataset that links the assessment of image quality issues to two practical vision tasks: image captioning and visual question answering. First, we identify for 39,181 images taken by people who are blind whether each is sufficient quality to recognize the content as well as what quality flaws are observed from six options. These labels serve as a critical foundation for us to make the following contributions: (1) a new problem and algorithms for deciding whether an image is insufficient quality to recognize the content and so not captionable, (2) a new problem and algorithms for deciding which of six quality flaws an image contains, (3) a new problem and algorithms for deciding whether a visual question is unanswerable due to unrecognizable content versus the content of interest being missing from the field of view, and (4) a novel application of more efficiently creating a large-scale image captioning dataset by automatically deciding whether an image is insufficient quality and so should not be captioned. We publicly-share our datasets and code to facilitate future extensions of this work: https://vizwiz.org.