 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Recognition
Scene text recognition is the process of identifying and transcribing text in natural scenes using computer vision techniques.
Papers and Code
ESTR-CoT: Towards Explainable and Accurate Event Stream based Scene Text Recognition with Chain-of-Thought Reasoning
Jul 02, 2025Event stream based scene text recognition is a newly arising research topic in recent years which performs better than the widely used RGB cameras in extremely challenging scenarios, especially the low illumination, fast motion. Existing works either adopt end-to-end encoder-decoder framework or large language models for enhanced recognition, however, they are still limited by the challenges of insufficient interpretability and weak contextual logical reasoning. In this work, we propose a novel chain-of-thought reasoning based event stream scene text recognition framework, termed ESTR-CoT. Specifically, we first adopt the vision encoder EVA-CLIP (ViT-G/14) to transform the input event stream into tokens and utilize a Llama tokenizer to encode the given generation prompt. A Q-former is used to align the vision token to the pre-trained large language model Vicuna-7B and output both the answer and chain-of-thought (CoT) reasoning process simultaneously. Our framework can be optimized using supervised fine-tuning in an end-to-end manner. In addition, we also propose a large-scale CoT dataset to train our framework via a three stage processing (i.e., generation, polish, and expert verification). This dataset provides a solid data foundation for the development of subsequent reasoning-based large models. Extensive experiments on three event stream STR benchmark datasets (i.e., EventSTR, WordArt*, IC15*) fully validated the effectiveness and interpretability of our proposed framework. The source code and pre-trained models will be released on https://github.com/Event-AHU/ESTR-CoT.
LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving
Aug 17, 2025
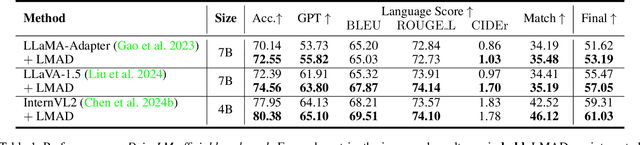

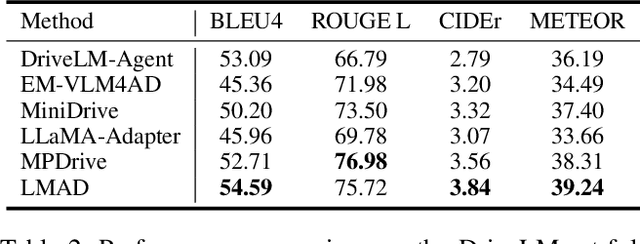
Large vision-language models (VLMs) have shown promising capabilities in scene understanding, enhancing the explainability of driving behaviors and interactivity with users. Existing methods primarily fine-tune VLMs on on-board multi-view images and scene reasoning text, but this approach often lacks the holistic and nuanced scene recognition and powerful spatial awareness required for autonomous driving, especially in complex situations. To address this gap, we propose a novel vision-language framework tailored for autonomous driving, called LMAD. Our framework emulates modern end-to-end driving paradigms by incorporating comprehensive scene understanding and a task-specialized structure with VLMs. In particular, we introduce preliminary scene interaction and specialized expert adapters within the same driving task structure, which better align VLMs with autonomous driving scenarios. Furthermore, our approach is designed to be fully compatible with existing VLMs while seamlessly integrating with planning-oriented driving systems. Extensive experiments on the DriveLM and nuScenes-QA datasets demonstrate that LMAD significantly boosts the performance of existing VLMs on driving reasoning tasks,setting a new standard in explainable autonomous driving.
Seeing the Signs: A Survey of Edge-Deployable OCR Models for Billboard Visibility Analysis
Jul 15, 2025



Outdoor advertisements remain a critical medium for modern marketing, yet accurately verifying billboard text visibility under real-world conditions is still challenging. Traditional Optical Character Recognition (OCR) pipelines excel at cropped text recognition but often struggle with complex outdoor scenes, varying fonts, and weather-induced visual noise. Recently, multimodal Vision-Language Models (VLMs) have emerged as promising alternatives, offering end-to-end scene understanding with no explicit detection step. This work systematically benchmarks representative VLMs - including Qwen 2.5 VL 3B, InternVL3, and SmolVLM2 - against a compact CNN-based OCR baseline (PaddleOCRv4) across two public datasets (ICDAR 2015 and SVT), augmented with synthetic weather distortions to simulate realistic degradation. Our results reveal that while selected VLMs excel at holistic scene reasoning, lightweight CNN pipelines still achieve competitive accuracy for cropped text at a fraction of the computational cost-an important consideration for edge deployment. To foster future research, we release our weather-augmented benchmark and evaluation code publicly.
MiDashengLM: Efficient Audio Understanding with General Audio Captions
Aug 06, 2025



Current approaches for large audio language models (LALMs) often rely on closed data sources or proprietary models, limiting their generalization and accessibility. This paper introduces MiDashengLM, a novel open audio-language model designed for efficient and comprehensive audio understanding through the use of general audio captions using our novel ACAVCaps training dataset. MiDashengLM exclusively relies on publicly available pretraining and supervised fine-tuning (SFT) datasets, ensuring full transparency and reproducibility. At its core, MiDashengLM integrates Dasheng, an open-source audio encoder, specifically engineered to process diverse auditory information effectively. Unlike previous works primarily focused on Automatic Speech Recognition (ASR) based audio-text alignment, our strategy centers on general audio captions, fusing speech, sound and music information into one textual representation, enabling a holistic textual representation of complex audio scenes. Lastly, MiDashengLM provides an up to 4x speedup in terms of time-to-first-token (TTFT) and up to 20x higher throughput than comparable models. Checkpoints are available online at https://huggingface.co/mispeech/midashenglm-7b and https://github.com/xiaomi-research/dasheng-lm.
TransLPRNet: Lite Vision-Language Network for Single/Dual-line Chinese License Plate Recognition
Jul 23, 2025License plate recognition in open environments is widely applicable across various domains; however, the diversity of license plate types and imaging conditions presents significant challenges. To address the limitations encountered by CNN and CRNN-based approaches in license plate recognition, this paper proposes a unified solution that integrates a lightweight visual encoder with a text decoder, within a pre-training framework tailored for single and double-line Chinese license plates. To mitigate the scarcity of double-line license plate datasets, we constructed a single/double-line license plate dataset by synthesizing images, applying texture mapping onto real scenes, and blending them with authentic license plate images. Furthermore, to enhance the system's recognition accuracy, we introduce a perspective correction network (PTN) that employs license plate corner coordinate regression as an implicit variable, supervised by license plate view classification information. This network offers improved stability, interpretability, and low annotation costs. The proposed algorithm achieves an average recognition accuracy of 99.34% on the corrected CCPD test set under coarse localization disturbance. When evaluated under fine localization disturbance, the accuracy further improves to 99.58%. On the double-line license plate test set, it achieves an average recognition accuracy of 98.70%, with processing speeds reaching up to 167 frames per second, indicating strong practical applicability.
Detecting Visual Information Manipulation Attacks in Augmented Reality: A Multimodal Semantic Reasoning Approach
Jul 27, 2025The virtual content in augmented reality (AR) can introduce misleading or harmful information, leading to semantic misunderstandings or user errors. In this work, we focus on visual information manipulation (VIM) attacks in AR where virtual content changes the meaning of real-world scenes in subtle but impactful ways. We introduce a taxonomy that categorizes these attacks into three formats: character, phrase, and pattern manipulation, and three purposes: information replacement, information obfuscation, and extra wrong information. Based on the taxonomy, we construct a dataset, AR-VIM. It consists of 452 raw-AR video pairs spanning 202 different scenes, each simulating a real-world AR scenario. To detect such attacks, we propose a multimodal semantic reasoning framework, VIM-Sense. It combines the language and visual understanding capabilities of vision-language models (VLMs) with optical character recognition (OCR)-based textual analysis. VIM-Sense achieves an attack detection accuracy of 88.94% on AR-VIM, consistently outperforming vision-only and text-only baselines. The system reaches an average attack detection latency of 7.07 seconds in a simulated video processing framework and 7.17 seconds in a real-world evaluation conducted on a mobile Android AR application.
Efficient and Accurate Scene Text Recognition with Cascaded-Transformers
Mar 24, 2025In recent years, vision transformers with text decoder have demonstrated remarkable performance on Scene Text Recognition (STR) due to their ability to capture long-range dependencies and contextual relationships with high learning capacity. However, the computational and memory demands of these models are significant, limiting their deployment in resource-constrained applications. To address this challenge, we propose an efficient and accurate STR system. Specifically, we focus on improving the efficiency of encoder models by introducing a cascaded-transformers structure. This structure progressively reduces the vision token size during the encoding step, effectively eliminating redundant tokens and reducing computational cost. Our experimental results confirm that our STR system achieves comparable performance to state-of-the-art baselines while substantially decreasing computational requirements. In particular, for large-models, the accuracy remains same, 92.77 to 92.68, while computational complexity is almost halved with our structure.
Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation
Mar 20, 2025



Scaling architectures have been proven effective for improving Scene Text Recognition (STR), but the individual contribution of vision encoder and text decoder scaling remain under-explored. In this work, we present an in-depth empirical analysis and demonstrate that, contrary to previous observations, scaling the decoder yields significant performance gains, always exceeding those achieved by encoder scaling alone. We also identify label noise as a key challenge in STR, particularly in real-world data, which can limit the effectiveness of STR models. To address this, we propose Cloze Self-Distillation (CSD), a method that mitigates label noise by distilling a student model from context-aware soft predictions and pseudolabels generated by a teacher model. Additionally, we enhance the decoder architecture by introducing differential cross-attention for STR. Our methodology achieves state-of-the-art performance on 10 out of 11 benchmarks using only real data, while significantly reducing the parameter size and computational costs.
Linguistics-aware Masked Image Modeling for Self-supervised Scene Text Recognition
Mar 24, 2025Text images are unique in their dual nature, encompassing both visual and linguistic information. The visual component encompasses structural and appearance-based features, while the linguistic dimension incorporates contextual and semantic elements. In scenarios with degraded visual quality, linguistic patterns serve as crucial supplements for comprehension, highlighting the necessity of integrating both aspects for robust scene text recognition (STR). Contemporary STR approaches often use language models or semantic reasoning modules to capture linguistic features, typically requiring large-scale annotated datasets. Self-supervised learning, which lacks annotations, presents challenges in disentangling linguistic features related to the global context. Typically, sequence contrastive learning emphasizes the alignment of local features, while masked image modeling (MIM) tends to exploit local structures to reconstruct visual patterns, resulting in limited linguistic knowledge. In this paper, we propose a Linguistics-aware Masked Image Modeling (LMIM) approach, which channels the linguistic information into the decoding process of MIM through a separate branch. Specifically, we design a linguistics alignment module to extract vision-independent features as linguistic guidance using inputs with different visual appearances. As features extend beyond mere visual structures, LMIM must consider the global context to achieve reconstruction. Extensive experiments on various benchmarks quantitatively demonstrate our state-of-the-art performance, and attention visualizations qualitatively show the simultaneous capture of both visual and linguistic information.
Team RAS in 9th ABAW Competition: Multimodal Compound Expression Recognition Approach
Jul 02, 2025Compound Expression Recognition (CER), a subfield of affective computing, aims to detect complex emotional states formed by combinations of basic emotions. In this work, we present a novel zero-shot multimodal approach for CER that combines six heterogeneous modalities into a single pipeline: static and dynamic facial expressions, scene and label matching, scene context, audio, and text. Unlike previous approaches relying on task-specific training data, our approach uses zero-shot components, including Contrastive Language-Image Pretraining (CLIP)-based label matching and Qwen-VL for semantic scene understanding. We further introduce a Multi-Head Probability Fusion (MHPF) module that dynamically weights modality-specific predictions, followed by a Compound Expressions (CE) transformation module that uses Pair-Wise Probability Aggregation (PPA) and Pair-Wise Feature Similarity Aggregation (PFSA) methods to produce interpretable compound emotion outputs. Evaluated under multi-corpus training, the proposed approach shows F1 scores of 46.95% on AffWild2, 49.02% on Acted Facial Expressions in The Wild (AFEW), and 34.85% on C-EXPR-DB via zero-shot testing, which is comparable to the results of supervised approaches trained on target data. This demonstrates the effectiveness of the proposed approach for capturing CE without domain adaptation. The source code is publicly available.