 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPL: Multiple Programming Languages with Large Language Models for Information Extraction
May 22, 2025Recent research in information extraction (IE) focuses on utilizing code-style inputs to enhance structured output generation. The intuition behind this is that the programming languages (PLs) inherently exhibit greater structural organization than natural languages (NLs). This structural advantage makes PLs particularly suited for IE tasks. Nevertheless, existing research primarily focuses on Python for code-style simulation, overlooking the potential of other widely-used PLs (e.g., C++ and Java) during the supervised fine-tuning (SFT) phase. In this research, we propose \textbf{M}ultiple \textbf{P}rogramming \textbf{L}anguages with large language models for information extraction (abbreviated as \textbf{MPL}), a novel framework that explores the potential of incorporating different PLs in the SFT phase. Additionally, we introduce \texttt{function-prompt} with virtual running to simulate code-style inputs more effectively and efficiently. Experimental results on a wide range of datasets demonstrate the effectiveness of MPL. Furthermore, we conduct extensive experiments to provide a comprehensive analysis. We have released our code for future research.
HaWoR: World-Space Hand Motion Reconstruction from Egocentric Videos
Jan 06, 2025Despite the advent in 3D hand pose estimation, current methods predominantly focus on single-image 3D hand reconstruction in the camera frame, overlooking the world-space motion of the hands. Such limitation prohibits their direct use in egocentric video settings, where hands and camera are continuously in motion. In this work, we propose HaWoR, a high-fidelity method for hand motion reconstruction in world coordinates from egocentric videos. We propose to decouple the task by reconstructing the hand motion in the camera space and estimating the camera trajectory in the world coordinate system. To achieve precise camera trajectory estimation, we propose an adaptive egocentric SLAM framework that addresses the shortcomings of traditional SLAM methods, providing robust performance under challenging camera dynamics. To ensure robust hand motion trajectories, even when the hands move out of view frustum, we devise a novel motion infiller network that effectively completes the missing frames of the sequence. Through extensive quantitative and qualitative evaluations, we demonstrate that HaWoR achieves state-of-the-art performance on both hand motion reconstruction and world-frame camera trajectory estimation under different egocentric benchmark datasets. Code and models are available on https://hawor-project.github.io/ .
Relational Contrastive Learning and Masked Image Modeling for Scene Text Recognition
Nov 19, 2024



Context-aware methods have achieved remarkable advancements in supervised scene text recognition by leveraging semantic priors from words. Considering the heterogeneity of text and background in STR, we propose that such contextual priors can be reinterpreted as the relations between textual elements, serving as effective self-supervised labels for representation learning. However, textual relations are restricted to the finite size of the dataset due to lexical dependencies, which causes over-fitting problem, thus compromising the representation quality. To address this, our work introduces a unified framework of Relational Contrastive Learning and Masked Image Modeling for STR (RCMSTR), which explicitly models the enriched textual relations. For the RCL branch, we first introduce the relational rearrangement module to cultivate new relations on the fly. Based on this, we further conduct relational contrastive learning to model the intra- and inter-hierarchical relations for frames, sub-words and words. On the other hand, MIM can naturally boost the context information via masking, where we find that the block masking strategy is more effective for STR. For the effective integration of RCL and MIM, we also introduce a novel decoupling design aimed at mitigating the impact of masked images on contrastive learning. Additionally, to enhance the compatibility of MIM with CNNs, we propose the adoption of sparse convolutions and directly sharing the weights with dense convolutions in training. The proposed RCMSTR demonstrates superior performance in various evaluation protocols for different STR-related downstream tasks, outperforming the existing state-of-the-art self-supervised STR techniques. Ablation studies and qualitative experimental results further validate the effectiveness of our method. The code and pre-trained models will be available at https://github.com/ThunderVVV/RCMSTR .
Relational Contrastive Learning for Scene Text Recognition
Aug 01, 2023Context-aware methods achieved great success in supervised scene text recognition via incorporating semantic priors from words. We argue that such prior contextual information can be interpreted as the relations of textual primitives due to the heterogeneous text and background, which can provide effective self-supervised labels for representation learning. However, textual relations are restricted to the finite size of dataset due to lexical dependencies, which causes the problem of over-fitting and compromises representation robustness. To this end, we propose to enrich the textual relations via rearrangement, hierarchy and interaction, and design a unified framework called RCLSTR: Relational Contrastive Learning for Scene Text Recognition. Based on causality, we theoretically explain that three modules suppress the bias caused by the contextual prior and thus guarantee representation robustness. Experiments on representation quality show that our method outperforms state-of-the-art self-supervised STR methods. Code is available at https://github.com/ThunderVVV/RCLSTR.
Sequence Generation with Label Augmentation for Relation Extraction
Dec 29, 2022



Sequence generation demonstrates promising performance in recent information extraction efforts, by incorporating large-scale pre-trained Seq2Seq models. This paper investigates the merits of employing sequence generation in relation extraction, finding that with relation names or synonyms as generation targets, their textual semantics and the correlation (in terms of word sequence pattern) among them affect model performance. We then propose Relation Extraction with Label Augmentation (RELA), a Seq2Seq model with automatic label augmentation for RE. By saying label augmentation, we mean prod semantically synonyms for each relation name as the generation target. Besides, we present an in-depth analysis of the Seq2Seq model's behavior when dealing with RE. Experimental results show that RELA achieves competitive results compared with previous methods on four RE datasets.
Reviewing Labels: Label Graph Network with Top-k Prediction Set for Relation Extraction
Dec 29, 2022



The typical way for relation extraction is fine-tuning large pre-trained language models on task-specific datasets, then selecting the label with the highest probability of the output distribution as the final prediction. However, the usage of the Top-k prediction set for a given sample is commonly overlooked. In this paper, we first reveal that the Top-k prediction set of a given sample contains useful information for predicting the correct label. To effectively utilizes the Top-k prediction set, we propose Label Graph Network with Top-k Prediction Set, termed as KLG. Specifically, for a given sample, we build a label graph to review candidate labels in the Top-k prediction set and learn the connections between them. We also design a dynamic $k$-selection mechanism to learn more powerful and discriminative relation representation. Our experiments show that KLG achieves the best performances on three relation extraction datasets. Moreover, we observe that KLG is more effective in dealing with long-tailed classes.
Leveraging Code Generation to Improve Code Retrieval and Summarization via Dual Learning
Feb 25, 2020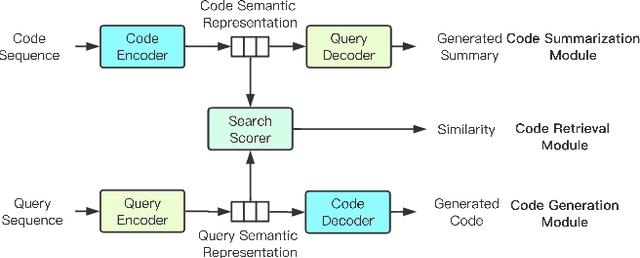
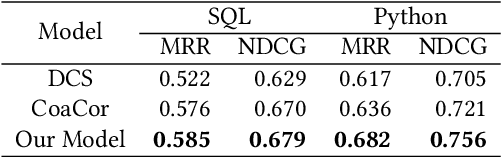
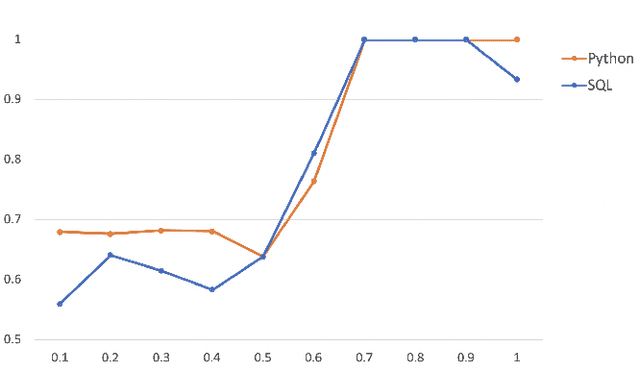
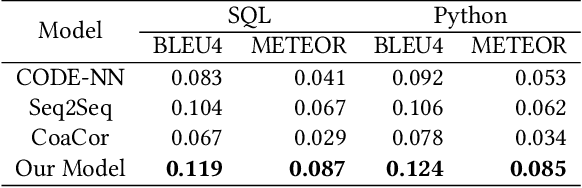
Code summarization generates brief natural language description given a source code snippet, while code retrieval fetches relevant source code given a natural language query. Since both tasks aim to model the association between natural language and programming language, recent studies have combined these two tasks to improve their performance. However, researchers have yet been able to effectively leverage the intrinsic connection between the two tasks as they train these tasks in a separate or pipeline manner, which means their performance can not be well balanced. In this paper, we propose a novel end-to-end model for the two tasks by introducing an additional code generation task. More specifically, we explicitly exploit the probabilistic correlation between code summarization and code generation with dual learning, and utilize the two encoders for code summarization and code generation to train the code retrieval task via multi-task learning. We have carried out extensive experiments on an existing dataset of SQL and Python, and results show that our model can significantly improve the results of the code retrieval task over the-state-of-art models, as well as achieve competitive performance in terms of BLEU score for the code summarization task.