 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial recognition
Facial recognition is an AI-based technique for identifying or confirming an individual's identity using their face. It maps facial features from an image or video and then compares the information with a collection of known faces to find a match.
Papers and Code
A Deep Learning Approach for Facial Attribute Manipulation and Reconstruction in Surveillance and Reconnaissance
Jun 06, 2025



Surveillance systems play a critical role in security and reconnaissance, but their performance is often compromised by low-quality images and videos, leading to reduced accuracy in face recognition. Additionally, existing AI-based facial analysis models suffer from biases related to skin tone variations and partially occluded faces, further limiting their effectiveness in diverse real-world scenarios. These challenges are the results of data limitations and imbalances, where available training datasets lack sufficient diversity, resulting in unfair and unreliable facial recognition performance. To address these issues, we propose a data-driven platform that enhances surveillance capabilities by generating synthetic training data tailored to compensate for dataset biases. Our approach leverages deep learning-based facial attribute manipulation and reconstruction using autoencoders and Generative Adversarial Networks (GANs) to create diverse and high-quality facial datasets. Additionally, our system integrates an image enhancement module, improving the clarity of low-resolution or occluded faces in surveillance footage. We evaluate our approach using the CelebA dataset, demonstrating that the proposed platform enhances both training data diversity and model fairness. This work contributes to reducing bias in AI-based facial analysis and improving surveillance accuracy in challenging environments, leading to fairer and more reliable security applications.
SocialDF: Benchmark Dataset and Detection Model for Mitigating Harmful Deepfake Content on Social Media Platforms
Jun 05, 2025



The rapid advancement of deep generative models has significantly improved the realism of synthetic media, presenting both opportunities and security challenges. While deepfake technology has valuable applications in entertainment and accessibility, it has emerged as a potent vector for misinformation campaigns, particularly on social media. Existing detection frameworks struggle to distinguish between benign and adversarially generated deepfakes engineered to manipulate public perception. To address this challenge, we introduce SocialDF, a curated dataset reflecting real-world deepfake challenges on social media platforms. This dataset encompasses high-fidelity deepfakes sourced from various online ecosystems, ensuring broad coverage of manipulative techniques. We propose a novel LLM-based multi-factor detection approach that combines facial recognition, automated speech transcription, and a multi-agent LLM pipeline to cross-verify audio-visual cues. Our methodology emphasizes robust, multi-modal verification techniques that incorporate linguistic, behavioral, and contextual analysis to effectively discern synthetic media from authentic content.
ExpertGen: Training-Free Expert Guidance for Controllable Text-to-Face Generation
May 22, 2025Recent advances in diffusion models have significantly improved text-to-face generation, but achieving fine-grained control over facial features remains a challenge. Existing methods often require training additional modules to handle specific controls such as identity, attributes, or age, making them inflexible and resource-intensive. We propose ExpertGen, a training-free framework that leverages pre-trained expert models such as face recognition, facial attribute recognition, and age estimation networks to guide generation with fine control. Our approach uses a latent consistency model to ensure realistic and in-distribution predictions at each diffusion step, enabling accurate guidance signals to effectively steer the diffusion process. We show qualitatively and quantitatively that expert models can guide the generation process with high precision, and multiple experts can collaborate to enable simultaneous control over diverse facial aspects. By allowing direct integration of off-the-shelf expert models, our method transforms any such model into a plug-and-play component for controllable face generation.
Skeleton-based sign language recognition using a dual-stream spatio-temporal dynamic graph convolutional network
Sep 10, 2025Isolated Sign Language Recognition (ISLR) is challenged by gestures that are morphologically similar yet semantically distinct, a problem rooted in the complex interplay between hand shape and motion trajectory. Existing methods, often relying on a single reference frame, struggle to resolve this geometric ambiguity. This paper introduces Dual-SignLanguageNet (DSLNet), a dual-reference, dual-stream architecture that decouples and models gesture morphology and trajectory in separate, complementary coordinate systems. Our approach utilizes a wrist-centric frame for view-invariant shape analysis and a facial-centric frame for context-aware trajectory modeling. These streams are processed by specialized networks-a topology-aware graph convolution for shape and a Finsler geometry-based encoder for trajectory-and are integrated via a geometry-driven optimal transport fusion mechanism. DSLNet sets a new state-of-the-art, achieving 93.70%, 89.97% and 99.79% accuracy on the challenging WLASL-100, WLASL-300 and LSA64 datasets, respectively, with significantly fewer parameters than competing models.
Emotion Recognition from Skeleton Data: A Comprehensive Survey
Jul 24, 2025Emotion recognition through body movements has emerged as a compelling and privacy-preserving alternative to traditional methods that rely on facial expressions or physiological signals. Recent advancements in 3D skeleton acquisition technologies and pose estimation algorithms have significantly enhanced the feasibility of emotion recognition based on full-body motion. This survey provides a comprehensive and systematic review of skeleton-based emotion recognition techniques. First, we introduce psychological models of emotion and examine the relationship between bodily movements and emotional expression. Next, we summarize publicly available datasets, highlighting the differences in data acquisition methods and emotion labeling strategies. We then categorize existing methods into posture-based and gait-based approaches, analyzing them from both data-driven and technical perspectives. In particular, we propose a unified taxonomy that encompasses four primary technical paradigms: Traditional approaches, Feat2Net, FeatFusionNet, and End2EndNet. Representative works within each category are reviewed and compared, with benchmarking results across commonly used datasets. Finally, we explore the extended applications of emotion recognition in mental health assessment, such as detecting depression and autism, and discuss the open challenges and future research directions in this rapidly evolving field.
Using Vision Language Models to Detect Students' Academic Emotion through Facial Expressions
Jun 12, 2025Students' academic emotions significantly influence their social behavior and learning performance. Traditional approaches to automatically and accurately analyze these emotions have predominantly relied on supervised machine learning algorithms. However, these models often struggle to generalize across different contexts, necessitating repeated cycles of data collection, annotation, and training. The emergence of Vision-Language Models (VLMs) offers a promising alternative, enabling generalization across visual recognition tasks through zero-shot prompting without requiring fine-tuning. This study investigates the potential of VLMs to analyze students' academic emotions via facial expressions in an online learning environment. We employed two VLMs, Llama-3.2-11B-Vision-Instruct and Qwen2.5-VL-7B-Instruct, to analyze 5,000 images depicting confused, distracted, happy, neutral, and tired expressions using zero-shot prompting. Preliminary results indicate that both models demonstrate moderate performance in academic facial expression recognition, with Qwen2.5-VL-7B-Instruct outperforming Llama-3.2-11B-Vision-Instruct. Notably, both models excel in identifying students' happy emotions but fail to detect distracted behavior. Additionally, Qwen2.5-VL-7B-Instruct exhibits relatively high performance in recognizing students' confused expressions, highlighting its potential for practical applications in identifying content that causes student confusion.
Inverting Black-Box Face Recognition Systems via Zero-Order Optimization in Eigenface Space
Jun 11, 2025



Reconstructing facial images from black-box recognition models poses a significant privacy threat. While many methods require access to embeddings, we address the more challenging scenario of model inversion using only similarity scores. This paper introduces DarkerBB, a novel approach that reconstructs color faces by performing zero-order optimization within a PCA-derived eigenface space. Despite this highly limited information, experiments on LFW, AgeDB-30, and CFP-FP benchmarks demonstrate that DarkerBB achieves state-of-the-art verification accuracies in the similarity-only setting, with competitive query efficiency.
Pura: An Efficient Privacy-Preserving Solution for Face Recognition
May 21, 2025



Face recognition is an effective technology for identifying a target person by facial images. However, sensitive facial images raises privacy concerns. Although privacy-preserving face recognition is one of potential solutions, this solution neither fully addresses the privacy concerns nor is efficient enough. To this end, we propose an efficient privacy-preserving solution for face recognition, named Pura, which sufficiently protects facial privacy and supports face recognition over encrypted data efficiently. Specifically, we propose a privacy-preserving and non-interactive architecture for face recognition through the threshold Paillier cryptosystem. Additionally, we carefully design a suite of underlying secure computing protocols to enable efficient operations of face recognition over encrypted data directly. Furthermore, we introduce a parallel computing mechanism to enhance the performance of the proposed secure computing protocols. Privacy analysis demonstrates that Pura fully safeguards personal facial privacy. Experimental evaluations demonstrate that Pura achieves recognition speeds up to 16 times faster than the state-of-the-art.
Learning Personalised Human Internal Cognition from External Expressive Behaviours for Real Personality Recognition
Jul 31, 2025



Automatic real personality recognition (RPR) aims to evaluate human real personality traits from their expressive behaviours. However, most existing solutions generally act as external observers to infer observers' personality impressions based on target individuals' expressive behaviours, which significantly deviate from their real personalities and consistently lead to inferior recognition performance. Inspired by the association between real personality and human internal cognition underlying the generation of expressive behaviours, we propose a novel RPR approach that efficiently simulates personalised internal cognition from easy-accessible external short audio-visual behaviours expressed by the target individual. The simulated personalised cognition, represented as a set of network weights that enforce the personalised network to reproduce the individual-specific facial reactions, is further encoded as a novel graph containing two-dimensional node and edge feature matrices, with a novel 2D Graph Neural Network (2D-GNN) proposed for inferring real personality traits from it. To simulate real personality-related cognition, an end-to-end strategy is designed to jointly train our cognition simulation, 2D graph construction, and personality recognition modules.
MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution
Jun 17, 2025
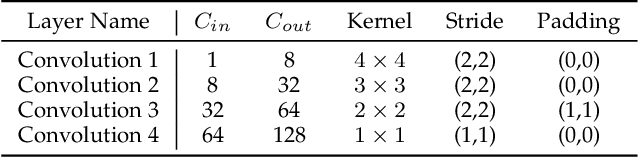


Facial micro-expression recognition (MER) is a challenging problem, due to transient and subtle micro-expression (ME) actions. Most existing methods depend on hand-crafted features, key frames like onset, apex, and offset frames, or deep networks limited by small-scale and low-diversity datasets. In this paper, we propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data. Extensive experiments demonstrate that our framework (i) outperforms the state-of-the-art MER methods on CASME II, SAMM, and SMIC benchmarks, (ii) works well for optical flow estimation and facial landmark detection, and (iii) can capture facial subtle muscle actions in local regions associated with MEs. The code is available at https://github.com/CYF-cuber/MOL.