 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCULTURESCORE: Evaluating Cultural Faithfulness in Video Generation Models
Jun 05, 2026As video generation models like Veo 3.1 and LTX-2 advance, their ability to accurately represent diverse global cultures remains a critical yet understudied frontier. Current metrics, such as VideoScore, only measure visual quality but offer no mechanism for assessing cultural faithfulness. Consequently, a model that replaces a Namaste with a handshake receives the same score as one that generates the gesture correctly. We propose CultureScore, a compositional evaluation framework that decomposes cultural faithfulness into three granular dimensions: Identity (who is represented), Context (culturally localized background), and Behavior (normative gestures and interactions). We operationalize this framework through an evaluation suite spanning 10 countries, yielding 6,180 generated videos across three state-of-the-art models. Our evaluation reveals that no current model achieves culturally faithful video generation: the best-performing model reaches only 56.8\% overall CultureScore, with Behavior the most challenging dimension, which remains below 52\% across all models. Furthermore, human preference rankings align directionally with CultureScore but are inverted relative to VideoScore; the highest-scoring model on visual quality was ranked last by annotators, underscoring that cultural faithfulness is an essential criterion for equitable video generation.
From Gaze to Guidance: Interpreting and Adapting to Users' Cognitive Needs with Multimodal Gaze-Aware AI Assistants
Apr 09, 2026Current LLM assistants are powerful at answering questions, but they have limited access to the behavioral context that reveals when and where a user is struggling. We present a gaze-grounded multimodal LLM assistant that uses egocentric video with gaze overlays to identify likely points of difficulty and target follow-up retrospective assistance. We instantiate this vision in a controlled study (n=36) comparing the gaze-aware AI assistant to a text-only LLM assistant. Compared to a conventional LLM assistant, the gaze-aware assistant was rated as significantly more accurate and personalized in its assessments of users' reading behavior and significantly improved people's ability to recall information. Users spoke significantly fewer words with the gaze-aware assistant, indicating more efficient interactions. Qualitative results underscored both perceived benefits in comprehension and challenges when interpretations of gaze behaviors were inaccurate. Our findings suggest that gaze-aware LLM assistants can reason about cognitive needs to improve cognitive outcomes of users.
Do Robots Need Body Language? Comparing Communication Modalities for Legible Motion Intent in Human-Shared Spaces
Apr 03, 2026Robots in shared spaces often move in ways that are difficult for people to interpret, placing the burden on humans to adapt. High-DoF robots exhibit motion that people read as expressive, intentionally or not, making it important to understand how such cues are perceived. We present an online video study evaluating how different signaling modalities, expressive motion, lights, text, and audio, shape people's ability to understand a quadruped robot's upcoming navigation actions (Boston Dynamics Spot). Across four common scenarios, we measure how each modality influences humans' (1) accuracy in predicting the robot's next navigation action, (2) confidence in that prediction, and (3) trust in the robot to act safely. The study tests how expressive motions compare to explicit channels, whether aligned multimodal cues enhance interpretability, and how conflicting cues affect user confidence and trust. We contribute initial evidence on the relative effectiveness of implicit versus explicit signaling strategies.
Visual Persuasion: What Influences Decisions of Vision-Language Models?
Feb 17, 2026The web is littered with images, once created for human consumption and now increasingly interpreted by agents using vision-language models (VLMs). These agents make visual decisions at scale, deciding what to click, recommend, or buy. Yet, we know little about the structure of their visual preferences. We introduce a framework for studying this by placing VLMs in controlled image-based choice tasks and systematically perturbing their inputs. Our key idea is to treat the agent's decision function as a latent visual utility that can be inferred through revealed preference: choices between systematically edited images. Starting from common images, such as product photos, we propose methods for visual prompt optimization, adapting text optimization methods to iteratively propose and apply visually plausible modifications using an image generation model (such as in composition, lighting, or background). We then evaluate which edits increase selection probability. Through large-scale experiments on frontier VLMs, we demonstrate that optimized edits significantly shift choice probabilities in head-to-head comparisons. We develop an automatic interpretability pipeline to explain these preferences, identifying consistent visual themes that drive selection. We argue that this approach offers a practical and efficient way to surface visual vulnerabilities, safety concerns that might otherwise be discovered implicitly in the wild, supporting more proactive auditing and governance of image-based AI agents.
Detecting Reading-Induced Confusion Using EEG and Eye Tracking
Aug 20, 2025


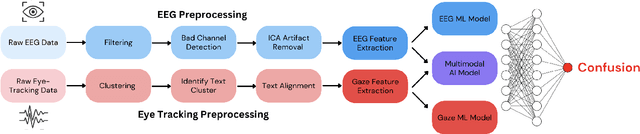
Humans regularly navigate an overwhelming amount of information via text media, whether reading articles, browsing social media, or interacting with chatbots. Confusion naturally arises when new information conflicts with or exceeds a reader's comprehension or prior knowledge, posing a challenge for learning. In this study, we present a multimodal investigation of reading-induced confusion using EEG and eye tracking. We collected neural and gaze data from 11 adult participants as they read short paragraphs sampled from diverse, real-world sources. By isolating the N400 event-related potential (ERP), a well-established neural marker of semantic incongruence, and integrating behavioral markers from eye tracking, we provide a detailed analysis of the neural and behavioral correlates of confusion during naturalistic reading. Using machine learning, we show that multimodal (EEG + eye tracking) models improve classification accuracy by 4-22% over unimodal baselines, reaching an average weighted participant accuracy of 77.3% and a best accuracy of 89.6%. Our results highlight the dominance of the brain's temporal regions in these neural signatures of confusion, suggesting avenues for wearable, low-electrode brain-computer interfaces (BCI) for real-time monitoring. These findings lay the foundation for developing adaptive systems that dynamically detect and respond to user confusion, with potential applications in personalized learning, human-computer interaction, and accessibility.
Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task
Jun 10, 2025This study explores the neural and behavioral consequences of LLM-assisted essay writing. Participants were divided into three groups: LLM, Search Engine, and Brain-only (no tools). Each completed three sessions under the same condition. In a fourth session, LLM users were reassigned to Brain-only group (LLM-to-Brain), and Brain-only users were reassigned to LLM condition (Brain-to-LLM). A total of 54 participants took part in Sessions 1-3, with 18 completing session 4. We used electroencephalography (EEG) to assess cognitive load during essay writing, and analyzed essays using NLP, as well as scoring essays with the help from human teachers and an AI judge. Across groups, NERs, n-gram patterns, and topic ontology showed within-group homogeneity. EEG revealed significant differences in brain connectivity: Brain-only participants exhibited the strongest, most distributed networks; Search Engine users showed moderate engagement; and LLM users displayed the weakest connectivity. Cognitive activity scaled down in relation to external tool use. In session 4, LLM-to-Brain participants showed reduced alpha and beta connectivity, indicating under-engagement. Brain-to-LLM users exhibited higher memory recall and activation of occipito-parietal and prefrontal areas, similar to Search Engine users. Self-reported ownership of essays was the lowest in the LLM group and the highest in the Brain-only group. LLM users also struggled to accurately quote their own work. While LLMs offer immediate convenience, our findings highlight potential cognitive costs. Over four months, LLM users consistently underperformed at neural, linguistic, and behavioral levels. These results raise concerns about the long-term educational implications of LLM reliance and underscore the need for deeper inquiry into AI's role in learning.
EmoSign: A Multimodal Dataset for Understanding Emotions in American Sign Language
May 20, 2025Unlike spoken languages where the use of prosodic features to convey emotion is well studied, indicators of emotion in sign language remain poorly understood, creating communication barriers in critical settings. Sign languages present unique challenges as facial expressions and hand movements simultaneously serve both grammatical and emotional functions. To address this gap, we introduce EmoSign, the first sign video dataset containing sentiment and emotion labels for 200 American Sign Language (ASL) videos. We also collect open-ended descriptions of emotion cues. Annotations were done by 3 Deaf ASL signers with professional interpretation experience. Alongside the annotations, we include baseline models for sentiment and emotion classification. This dataset not only addresses a critical gap in existing sign language research but also establishes a new benchmark for understanding model capabilities in multimodal emotion recognition for sign languages. The dataset is made available at https://huggingface.co/datasets/catfang/emosign.
LLM Agents Are Hypersensitive to Nudges
May 16, 2025LLMs are being set loose in complex, real-world environments involving sequential decision-making and tool use. Often, this involves making choices on behalf of human users. However, not much is known about the distribution of such choices, and how susceptible they are to different choice architectures. We perform a case study with a few such LLM models on a multi-attribute tabular decision-making problem, under canonical nudges such as the default option, suggestions, and information highlighting, as well as additional prompting strategies. We show that, despite superficial similarities to human choice distributions, such models differ in subtle but important ways. First, they show much higher susceptibility to the nudges. Second, they diverge in points earned, being affected by factors like the idiosyncrasy of available prizes. Third, they diverge in information acquisition strategies: e.g. incurring substantial cost to reveal too much information, or selecting without revealing any. Moreover, we show that simple prompt strategies like zero-shot chain of thought (CoT) can shift the choice distribution, and few-shot prompting with human data can induce greater alignment. Yet, none of these methods resolve the sensitivity of these models to nudges. Finally, we show how optimal nudges optimized with a human resource-rational model can similarly increase LLM performance for some models. All these findings suggest that behavioral tests are needed before deploying models as agents or assistants acting on behalf of users in complex environments.
Investigating Affective Use and Emotional Well-being on ChatGPT
Apr 04, 2025As AI chatbots see increased adoption and integration into everyday life, questions have been raised about the potential impact of human-like or anthropomorphic AI on users. In this work, we investigate the extent to which interactions with ChatGPT (with a focus on Advanced Voice Mode) may impact users' emotional well-being, behaviors and experiences through two parallel studies. To study the affective use of AI chatbots, we perform large-scale automated analysis of ChatGPT platform usage in a privacy-preserving manner, analyzing over 3 million conversations for affective cues and surveying over 4,000 users on their perceptions of ChatGPT. To investigate whether there is a relationship between model usage and emotional well-being, we conduct an Institutional Review Board (IRB)-approved randomized controlled trial (RCT) on close to 1,000 participants over 28 days, examining changes in their emotional well-being as they interact with ChatGPT under different experimental settings. In both on-platform data analysis and the RCT, we observe that very high usage correlates with increased self-reported indicators of dependence. From our RCT, we find that the impact of voice-based interactions on emotional well-being to be highly nuanced, and influenced by factors such as the user's initial emotional state and total usage duration. Overall, our analysis reveals that a small number of users are responsible for a disproportionate share of the most affective cues.
Resonance: Drawing from Memories to Imagine Positive Futures through AI-Augmented Journaling
Mar 31, 2025



People inherently use experiences of their past while imagining their future, a capability that plays a crucial role in mental health. Resonance is an AI-powered journaling tool designed to augment this ability by offering AI-generated, action-oriented suggestions for future activities based on the user's own past memories. Suggestions are offered when a new memory is logged and are followed by a prompt for the user to imagine carrying out the suggestion. In a two-week randomized controlled study (N=55), we found that using Resonance significantly improved mental health outcomes, reducing the users' PHQ8 scores, a measure of current depression, and increasing their daily positive affect, particularly when they would likely act on the suggestion. Notably, the effectiveness of the suggestions was higher when they were personal, novel, and referenced the user's logged memories. Finally, through open-ended feedback, we discuss the factors that encouraged or hindered the use of the tool.
* 17 pages, 13 figures