 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial
Papers and Code
Multi-scale Attention-Guided Intrinsic Decomposition and Rendering Pass Prediction for Facial Images
Dec 18, 2025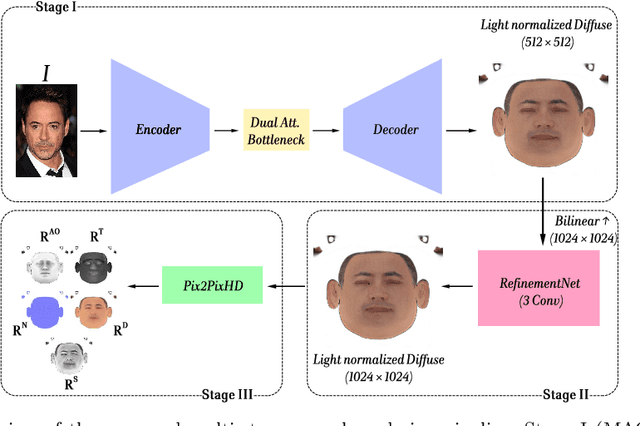

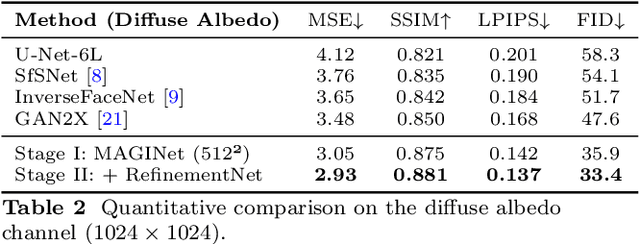
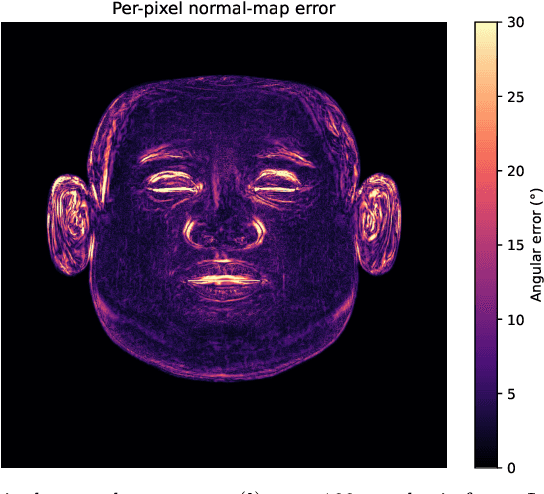
Accurate intrinsic decomposition of face images under unconstrained lighting is a prerequisite for photorealistic relighting, high-fidelity digital doubles, and augmented-reality effects. This paper introduces MAGINet, a Multi-scale Attention-Guided Intrinsics Network that predicts a $512\times512$ light-normalized diffuse albedo map from a single RGB portrait. MAGINet employs hierarchical residual encoding, spatial-and-channel attention in a bottleneck, and adaptive multi-scale feature fusion in the decoder, yielding sharper albedo boundaries and stronger lighting invariance than prior U-Net variants. The initial albedo prediction is upsampled to $1024\times1024$ and refined by a lightweight three-layer CNN (RefinementNet). Conditioned on this refined albedo, a Pix2PixHD-based translator then predicts a comprehensive set of five additional physically based rendering passes: ambient occlusion, surface normal, specular reflectance, translucency, and raw diffuse colour (with residual lighting). Together with the refined albedo, these six passes form the complete intrinsic decomposition. Trained with a combination of masked-MSE, VGG, edge, and patch-LPIPS losses on the FFHQ-UV-Intrinsics dataset, the full pipeline achieves state-of-the-art performance for diffuse albedo estimation and demonstrates significantly improved fidelity for the complete rendering stack compared to prior methods. The resulting passes enable high-quality relighting and material editing of real faces.
Using Gaussian Splats to Create High-Fidelity Facial Geometry and Texture
Dec 18, 2025



We leverage increasingly popular three-dimensional neural representations in order to construct a unified and consistent explanation of a collection of uncalibrated images of the human face. Our approach utilizes Gaussian Splatting, since it is more explicit and thus more amenable to constraints than NeRFs. We leverage segmentation annotations to align the semantic regions of the face, facilitating the reconstruction of a neutral pose from only 11 images (as opposed to requiring a long video). We soft constrain the Gaussians to an underlying triangulated surface in order to provide a more structured Gaussian Splat reconstruction, which in turn informs subsequent perturbations to increase the accuracy of the underlying triangulated surface. The resulting triangulated surface can then be used in a standard graphics pipeline. In addition, and perhaps most impactful, we show how accurate geometry enables the Gaussian Splats to be transformed into texture space where they can be treated as a view-dependent neural texture. This allows one to use high visual fidelity Gaussian Splatting on any asset in a scene without the need to modify any other asset or any other aspect (geometry, lighting, renderer, etc.) of the graphics pipeline. We utilize a relightable Gaussian model to disentangle texture from lighting in order to obtain a delit high-resolution albedo texture that is also readily usable in a standard graphics pipeline. The flexibility of our system allows for training with disparate images, even with incompatible lighting, facilitating robust regularization. Finally, we demonstrate the efficacy of our approach by illustrating its use in a text-driven asset creation pipeline.
Instant Expressive Gaussian Head Avatar via 3D-Aware Expression Distillation
Dec 18, 2025Portrait animation has witnessed tremendous quality improvements thanks to recent advances in video diffusion models. However, these 2D methods often compromise 3D consistency and speed, limiting their applicability in real-world scenarios, such as digital twins or telepresence. In contrast, 3D-aware facial animation feedforward methods -- built upon explicit 3D representations, such as neural radiance fields or Gaussian splatting -- ensure 3D consistency and achieve faster inference speed, but come with inferior expression details. In this paper, we aim to combine their strengths by distilling knowledge from a 2D diffusion-based method into a feed-forward encoder, which instantly converts an in-the-wild single image into a 3D-consistent, fast yet expressive animatable representation. Our animation representation is decoupled from the face's 3D representation and learns motion implicitly from data, eliminating the dependency on pre-defined parametric models that often constrain animation capabilities. Unlike previous computationally intensive global fusion mechanisms (e.g., multiple attention layers) for fusing 3D structural and animation information, our design employs an efficient lightweight local fusion strategy to achieve high animation expressivity. As a result, our method runs at 107.31 FPS for animation and pose control while achieving comparable animation quality to the state-of-the-art, surpassing alternative designs that trade speed for quality or vice versa. Project website is https://research.nvidia.com/labs/amri/projects/instant4d
Real-Time Human-Robot Interaction Intent Detection Using RGB-based Pose and Emotion Cues with Cross-Camera Model Generalization
Dec 18, 2025



Service robots in public spaces require real-time understanding of human behavioral intentions for natural interaction. We present a practical multimodal framework for frame-accurate human-robot interaction intent detection that fuses camera-invariant 2D skeletal pose and facial emotion features extracted from monocular RGB video. Unlike prior methods requiring RGB-D sensors or GPU acceleration, our approach resource-constrained embedded hardware (Raspberry Pi 5, CPU-only). To address the severe class imbalance in natural human-robot interaction datasets, we introduce a novel approach to synthesize temporally coherent pose-emotion-label sequences for data re-balancing called MINT-RVAE (Multimodal Recurrent Variational Autoencoder for Intent Sequence Generation). Comprehensive offline evaluations under cross-subject and cross-scene protocols demonstrate strong generalization performance, achieving frame- and sequence-level AUROC of 0.95. Crucially, we validate real-world generalization through cross-camera evaluation on the MIRA robot head, which employs a different onboard RGB sensor and operates in uncontrolled environments not represented in the training data. Despite this domain shift, the deployed system achieves 91% accuracy and 100% recall across 32 live interaction trials. The close correspondence between offline and deployed performance confirms the cross-sensor and cross-environment robustness of the proposed multimodal approach, highlighting its suitability for ubiquitous multimedia-enabled social robots.
Smile on the Face, Sadness in the Eyes: Bridging the Emotion Gap with a Multimodal Dataset of Eye and Facial Behaviors
Dec 18, 2025Emotion Recognition (ER) is the process of analyzing and identifying human emotions from sensing data. Currently, the field heavily relies on facial expression recognition (FER) because visual channel conveys rich emotional cues. However, facial expressions are often used as social tools rather than manifestations of genuine inner emotions. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cue and construct an Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. To collect data with genuine emotions, spontaneous emotion induction paradigm is exploited with stimulus material, during which non-invasive eye behavior data, like eye movement sequences and eye fixation maps, is captured together with facial expression videos. To better illustrate the gap between ER and FER, multi-view emotion labels for mutimodal ER and FER are separately annotated. Furthermore, based on the new dataset, we design a simple yet effective Eye-behavior-aided MER Transformer (EMERT) that enhances ER by bridging the emotion gap. EMERT leverages modality-adversarial feature decoupling and a multitask Transformer to model eye behaviors as a strong complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance. Our EMER dataset and the trained EMERT models will be publicly available at https://github.com/kejun1/EMER.
DeX-Portrait: Disentangled and Expressive Portrait Animation via Explicit and Latent Motion Representations
Dec 17, 2025Portrait animation from a single source image and a driving video is a long-standing problem. Recent approaches tend to adopt diffusion-based image/video generation models for realistic and expressive animation. However, none of these diffusion models realizes high-fidelity disentangled control between the head pose and facial expression, hindering applications like expression-only or pose-only editing and animation. To address this, we propose DeX-Portrait, a novel approach capable of generating expressive portrait animation driven by disentangled pose and expression signals. Specifically, we represent the pose as an explicit global transformation and the expression as an implicit latent code. First, we design a powerful motion trainer to learn both pose and expression encoders for extracting precise and decomposed driving signals. Then we propose to inject the pose transformation into the diffusion model through a dual-branch conditioning mechanism, and the expression latent through cross attention. Finally, we design a progressive hybrid classifier-free guidance for more faithful identity consistency. Experiments show that our method outperforms state-of-the-art baselines on both animation quality and disentangled controllability.
FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision
Dec 17, 2025We introduce FlexAvatar, a method for creating high-quality and complete 3D head avatars from a single image. A core challenge lies in the limited availability of multi-view data and the tendency of monocular training to yield incomplete 3D head reconstructions. We identify the root cause of this issue as the entanglement between driving signal and target viewpoint when learning from monocular videos. To address this, we propose a transformer-based 3D portrait animation model with learnable data source tokens, so-called bias sinks, which enables unified training across monocular and multi-view datasets. This design leverages the strengths of both data sources during inference: strong generalization from monocular data and full 3D completeness from multi-view supervision. Furthermore, our training procedure yields a smooth latent avatar space that facilitates identity interpolation and flexible fitting to an arbitrary number of input observations. In extensive evaluations on single-view, few-shot, and monocular avatar creation tasks, we verify the efficacy of FlexAvatar. Many existing methods struggle with view extrapolation while FlexAvatar generates complete 3D head avatars with realistic facial animations. Website: https://tobias-kirschstein.github.io/flexavatar/
BLANKET: Anonymizing Faces in Infant Video Recordings
Dec 17, 2025



Ensuring the ethical use of video data involving human subjects, particularly infants, requires robust anonymization methods. We propose BLANKET (Baby-face Landmark-preserving ANonymization with Keypoint dEtection consisTency), a novel approach designed to anonymize infant faces in video recordings while preserving essential facial attributes. Our method comprises two stages. First, a new random face, compatible with the original identity, is generated via inpainting using a diffusion model. Second, the new identity is seamlessly incorporated into each video frame through temporally consistent face swapping with authentic expression transfer. The method is evaluated on a dataset of short video recordings of babies and is compared to the popular anonymization method, DeepPrivacy2. Key metrics assessed include the level of de-identification, preservation of facial attributes, impact on human pose estimation (as an example of a downstream task), and presence of artifacts. Both methods alter the identity, and our method outperforms DeepPrivacy2 in all other respects. The code is available as an easy-to-use anonymization demo at https://github.com/ctu-vras/blanket-infant-face-anonym.
* Project website: https://github.com/ctu-vras/blanket-infant-face-anonym
Towards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conversational Head Dynamics
Dec 17, 2025



Human conversation involves continuous exchanges of speech and nonverbal cues such as head nods, gaze shifts, and facial expressions that convey attention and emotion. Modeling these bidirectional dynamics in 3D is essential for building expressive avatars and interactive robots. However, existing frameworks often treat talking and listening as independent processes or rely on non-causal full-sequence modeling, hindering temporal coherence across turns. We present TIMAR (Turn-level Interleaved Masked AutoRegression), a causal framework for 3D conversational head generation that models dialogue as interleaved audio-visual contexts. It fuses multimodal information within each turn and applies turn-level causal attention to accumulate conversational history, while a lightweight diffusion head predicts continuous 3D head dynamics that captures both coordination and expressive variability. Experiments on the DualTalk benchmark show that TIMAR reduces Fréchet Distance and MSE by 15-30% on the test set, and achieves similar gains on out-of-distribution data. The source code will be released in the GitHub repository https://github.com/CoderChen01/towards-seamleass-interaction.
Emotion Recognition in Signers
Dec 17, 2025Recognition of signers' emotions suffers from one theoretical challenge and one practical challenge, namely, the overlap between grammatical and affective facial expressions and the scarcity of data for model training. This paper addresses these two challenges in a cross-lingual setting using our eJSL dataset, a new benchmark dataset for emotion recognition in Japanese Sign Language signers, and BOBSL, a large British Sign Language dataset with subtitles. In eJSL, two signers expressed 78 distinct utterances with each of seven different emotional states, resulting in 1,092 video clips. We empirically demonstrate that 1) textual emotion recognition in spoken language mitigates data scarcity in sign language, 2) temporal segment selection has a significant impact, and 3) incorporating hand motion enhances emotion recognition in signers. Finally we establish a stronger baseline than spoken language LLMs.