 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Gaussian Splats to Create High-Fidelity Facial Geometry and Texture
Dec 18, 2025



We leverage increasingly popular three-dimensional neural representations in order to construct a unified and consistent explanation of a collection of uncalibrated images of the human face. Our approach utilizes Gaussian Splatting, since it is more explicit and thus more amenable to constraints than NeRFs. We leverage segmentation annotations to align the semantic regions of the face, facilitating the reconstruction of a neutral pose from only 11 images (as opposed to requiring a long video). We soft constrain the Gaussians to an underlying triangulated surface in order to provide a more structured Gaussian Splat reconstruction, which in turn informs subsequent perturbations to increase the accuracy of the underlying triangulated surface. The resulting triangulated surface can then be used in a standard graphics pipeline. In addition, and perhaps most impactful, we show how accurate geometry enables the Gaussian Splats to be transformed into texture space where they can be treated as a view-dependent neural texture. This allows one to use high visual fidelity Gaussian Splatting on any asset in a scene without the need to modify any other asset or any other aspect (geometry, lighting, renderer, etc.) of the graphics pipeline. We utilize a relightable Gaussian model to disentangle texture from lighting in order to obtain a delit high-resolution albedo texture that is also readily usable in a standard graphics pipeline. The flexibility of our system allows for training with disparate images, even with incompatible lighting, facilitating robust regularization. Finally, we demonstrate the efficacy of our approach by illustrating its use in a text-driven asset creation pipeline.
Improving Facial Rig Semantics for Tracking and Retargeting
Aug 11, 2025In this paper, we consider retargeting a tracked facial performance to either another person or to a virtual character in a game or virtual reality (VR) environment. We remove the difficulties associated with identifying and retargeting the semantics of one rig framework to another by utilizing the same framework (3DMM, FLAME, MetaHuman, etc.) for both subjects. Although this does not constrain the choice of framework when retargeting from one person to another, it does force the tracker to use the game/VR character rig when retargeting to a game/VR character. We utilize volumetric morphing in order to fit facial rigs to both performers and targets; in addition, a carefully chosen set of Simon-Says expressions is used to calibrate each rig to the motion signatures of the relevant performer or target. Although a uniform set of Simon-Says expressions can likely be used for all person to person retargeting, we argue that person to game/VR character retargeting benefits from Simon-Says expressions that capture the distinct motion signature of the game/VR character rig. The Simon-Says calibrated rigs tend to produce the desired expressions when exercising animation controls (as expected). Unfortunately, these well-calibrated rigs still lead to undesirable controls when tracking a performance (a well-behaved function can have an arbitrarily ill-conditioned inverse), even though they typically produce acceptable geometry reconstructions. Thus, we propose a fine-tuning approach that modifies the rig used by the tracker in order to promote the output of more semantically meaningful animation controls, facilitating high efficacy retargeting. In order to better address real-world scenarios, the fine-tuning relies on implicit differentiation so that the tracker can be treated as a (potentially non-differentiable) black box.
HUMBI 1.0: HUman Multiview Behavioral Imaging Dataset
Dec 01, 2018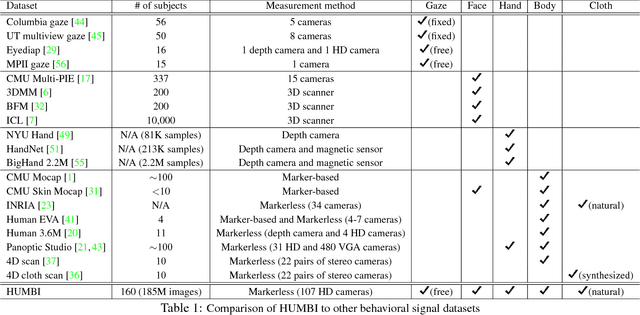



This paper presents a new dataset called HUMBI - a large corpus of high fidelity models of behavioral signals in 3D from a diverse population measured by a massive multi-camera system. With our novel design of a portable imaging system (consists of 107 HD cameras), we collect human behaviors from 164 subjects across gender, ethnicity, age, and physical condition at a public venue. Using the multiview image streams, we reconstruct high fidelity models of five elementary parts: gaze, face, hands, body, and cloth. As a byproduct, the 3D model provides geometrically consistent image annotation via 2D projection, e.g., body part segmentation. This dataset is a significant departure from the existing human datasets that suffers from subject diversity. We hope the HUMBI opens up a new opportunity for the development for behavioral imaging.