 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Speech To Text Translation
Papers and Code
RASST: Fast Cross-modal Retrieval-Augmented Simultaneous Speech Translation
Jan 30, 2026Simultaneous speech translation (SST) produces target text incrementally from partial speech input. Recent speech large language models (Speech LLMs) have substantially improved SST quality, yet they still struggle to correctly translate rare and domain-specific terminology. While retrieval augmentation has been effective for terminology translation in machine translation, bringing retrieval to SST is non-trivial: it requires fast and accurate cross-modal (speech-to-text) retrieval under partial, continually arriving input, and the model must decide whether and when to apply retrieved terms during incremental generation. We propose Retrieval-Augmented Simultaneous Speech Translation (RASST), which tightly integrates cross-modal retrieval into the SST pipeline. RASST trains a lightweight speech-text retriever and performs efficient sliding-window retrieval, providing chunkwise terminology hints to the Speech LLM. We further synthesize training data that teaches the Speech LLM to leverage retrieved terms precisely. Experiments on three language directions of the ACL 60/60 dev set show that RASST improves terminology translation accuracy by up to 16% and increases overall translation quality by up to 3 BLEU points, with ablations confirming the contribution of each component.
Corpus of Cross-lingual Dialogues with Minutes and Detection of Misunderstandings
Dec 23, 2025Speech processing and translation technology have the potential to facilitate meetings of individuals who do not share any common language. To evaluate automatic systems for such a task, a versatile and realistic evaluation corpus is needed. Therefore, we create and present a corpus of cross-lingual dialogues between individuals without a common language who were facilitated by automatic simultaneous speech translation. The corpus consists of 5 hours of speech recordings with ASR and gold transcripts in 12 original languages and automatic and corrected translations into English. For the purposes of research into cross-lingual summarization, our corpus also includes written summaries (minutes) of the meetings. Moreover, we propose automatic detection of misunderstandings. For an overview of this task and its complexity, we attempt to quantify misunderstandings in cross-lingual meetings. We annotate misunderstandings manually and also test the ability of current large language models to detect them automatically. The results show that the Gemini model is able to identify text spans with misunderstandings with recall of 77% and precision of 47%.
* 12 pages, 2 figures, 6 tables, published as a conference paper in Text, Speech, and Dialogue 28th International Conference, TSD 2025, Erlangen, Germany, August 25-28, 2025, Proceedings, Part II. This version published here on arXiv.org is before review comments and seedings of the TSD conference staff
Direct Simultaneous Translation Activation for Large Audio-Language Models
Sep 19, 2025



Simultaneous speech-to-text translation (Simul-S2TT) aims to translate speech into target text in real time, outputting translations while receiving source speech input, rather than waiting for the entire utterance to be spoken. Simul-S2TT research often modifies model architectures to implement read-write strategies. However, with the rise of large audio-language models (LALMs), a key challenge is how to directly activate Simul-S2TT capabilities in base models without additional architectural changes. In this paper, we introduce {\bf Simul}taneous {\bf S}elf-{\bf A}ugmentation ({\bf SimulSA}), a strategy that utilizes LALMs' inherent capabilities to obtain simultaneous data by randomly truncating speech and constructing partially aligned translation. By incorporating them into offline SFT data, SimulSA effectively bridges the distribution gap between offline translation during pretraining and simultaneous translation during inference. Experimental results demonstrate that augmenting only about {\bf 1\%} of the simultaneous data, compared to the full offline SFT data, can significantly activate LALMs' Simul-S2TT capabilities without modifications to model architecture or decoding strategy.
REINA: Regularized Entropy Information-Based Loss for Efficient Simultaneous Speech Translation
Aug 07, 2025



Simultaneous Speech Translation (SimulST) systems stream in audio while simultaneously emitting translated text or speech. Such systems face the significant challenge of balancing translation quality and latency. We introduce a strategy to optimize this tradeoff: wait for more input only if you gain information by doing so. Based on this strategy, we present Regularized Entropy INformation Adaptation (REINA), a novel loss to train an adaptive policy using an existing non-streaming translation model. We derive REINA from information theory principles and show that REINA helps push the reported Pareto frontier of the latency/quality tradeoff over prior works. Utilizing REINA, we train a SimulST model on French, Spanish and German, both from and into English. Training on only open source or synthetically generated data, we achieve state-of-the-art (SOTA) streaming results for models of comparable size. We also introduce a metric for streaming efficiency, quantitatively showing REINA improves the latency/quality trade-off by as much as 21% compared to prior approaches, normalized against non-streaming baseline BLEU scores.
CMU's IWSLT 2025 Simultaneous Speech Translation System
Jun 16, 2025This paper presents CMU's submission to the IWSLT 2025 Simultaneous Speech Translation (SST) task for translating unsegmented English speech into Chinese and German text in a streaming manner. Our end-to-end speech-to-text system integrates a chunkwise causal Wav2Vec 2.0 speech encoder, an adapter, and the Qwen2.5-7B-Instruct as the decoder. We use a two-stage simultaneous training procedure on robust speech segments curated from LibriSpeech, CommonVoice, and VoxPopuli datasets, utilizing standard cross-entropy loss. Our model supports adjustable latency through a configurable latency multiplier. Experimental results demonstrate that our system achieves 44.3 BLEU for English-to-Chinese and 25.1 BLEU for English-to-German translations on the ACL60/60 development set, with computation-aware latencies of 2.7 seconds and 2.3 seconds, and theoretical latencies of 2.2 and 1.7 seconds, respectively.
BeaverTalk: Oregon State University's IWSLT 2025 Simultaneous Speech Translation System
May 29, 2025This paper discusses the construction, fine-tuning, and deployment of BeaverTalk, a cascaded system for speech-to-text translation as part of the IWSLT 2025 simultaneous translation task. The system architecture employs a VAD segmenter for breaking a speech stream into segments, Whisper Large V2 for automatic speech recognition (ASR), and Gemma 3 12B for simultaneous translation. Regarding the simultaneous translation LLM, it is fine-tuned via low-rank adaptors (LoRAs) for a conversational prompting strategy that leverages a single prior-sentence memory bank from the source language as context. The cascaded system participated in the English$\rightarrow$German and English$\rightarrow$Chinese language directions for both the low and high latency regimes. In particular, on the English$\rightarrow$German task, the system achieves a BLEU of 24.64 and 27.83 at a StreamLAAL of 1837.86 and 3343.73, respectively. Then, on the English$\rightarrow$Chinese task, the system achieves a BLEU of 34.07 and 37.23 at a StreamLAAL of 2216.99 and 3521.35, respectively.
MockConf: A Student Interpretation Dataset: Analysis, Word- and Span-level Alignment and Baselines
Jun 05, 2025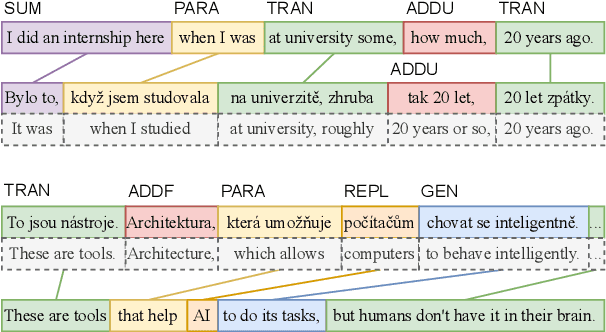
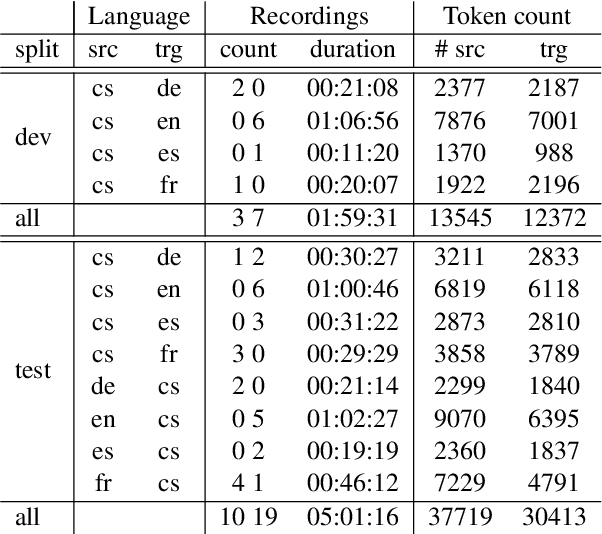
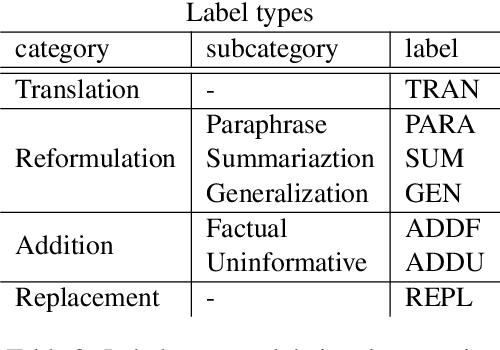
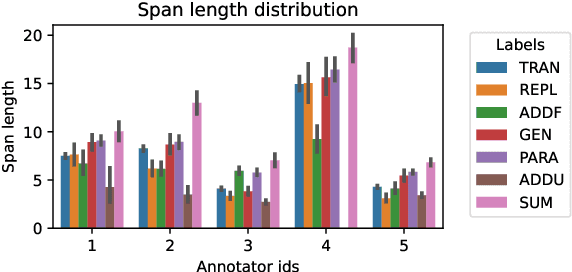
In simultaneous interpreting, an interpreter renders a source speech into another language with a very short lag, much sooner than sentences are finished. In order to understand and later reproduce this dynamic and complex task automatically, we need dedicated datasets and tools for analysis, monitoring, and evaluation, such as parallel speech corpora, and tools for their automatic annotation. Existing parallel corpora of translated texts and associated alignment algorithms hardly fill this gap, as they fail to model long-range interactions between speech segments or specific types of divergences (e.g., shortening, simplification, functional generalization) between the original and interpreted speeches. In this work, we introduce MockConf, a student interpreting dataset that was collected from Mock Conferences run as part of the students' curriculum. This dataset contains 7 hours of recordings in 5 European languages, transcribed and aligned at the level of spans and words. We further implement and release InterAlign, a modern web-based annotation tool for parallel word and span annotations on long inputs, suitable for aligning simultaneous interpreting. We propose metrics for the evaluation and a baseline for automatic alignment. Dataset and tools are released to the community.
Using Phonemes in cascaded S2S translation pipeline
Apr 22, 2025This paper explores the idea of using phonemes as a textual representation within a conventional multilingual simultaneous speech-to-speech translation pipeline, as opposed to the traditional reliance on text-based language representations. To investigate this, we trained an open-source sequence-to-sequence model on the WMT17 dataset in two formats: one using standard textual representation and the other employing phonemic representation. The performance of both approaches was assessed using the BLEU metric. Our findings shows that the phonemic approach provides comparable quality but offers several advantages, including lower resource requirements or better suitability for low-resource languages.
SimulS2S-LLM: Unlocking Simultaneous Inference of Speech LLMs for Speech-to-Speech Translation
Apr 22, 2025



Simultaneous speech translation (SST) outputs translations in parallel with streaming speech input, balancing translation quality and latency. While large language models (LLMs) have been extended to handle the speech modality, streaming remains challenging as speech is prepended as a prompt for the entire generation process. To unlock LLM streaming capability, this paper proposes SimulS2S-LLM, which trains speech LLMs offline and employs a test-time policy to guide simultaneous inference. SimulS2S-LLM alleviates the mismatch between training and inference by extracting boundary-aware speech prompts that allows it to be better matched with text input data. SimulS2S-LLM achieves simultaneous speech-to-speech translation (Simul-S2ST) by predicting discrete output speech tokens and then synthesising output speech using a pre-trained vocoder. An incremental beam search is designed to expand the search space of speech token prediction without increasing latency. Experiments on the CVSS speech data show that SimulS2S-LLM offers a better translation quality-latency trade-off than existing methods that use the same training data, such as improving ASR-BLEU scores by 3 points at similar latency.
Leveraging Unit Language Guidance to Advance Speech Modeling in Textless Speech-to-Speech Translation
May 21, 2025



The success of building textless speech-to-speech translation (S2ST) models has attracted much attention. However, S2ST still faces two main challenges: 1) extracting linguistic features for various speech signals, called cross-modal (CM), and 2) learning alignment of difference languages in long sequences, called cross-lingual (CL). We propose the unit language to overcome the two modeling challenges. The unit language can be considered a text-like representation format, constructed using $n$-gram language modeling. We implement multi-task learning to utilize the unit language in guiding the speech modeling process. Our initial results reveal a conflict when applying source and target unit languages simultaneously. We propose task prompt modeling to mitigate this conflict. We conduct experiments on four languages of the Voxpupil dataset. Our method demonstrates significant improvements over a strong baseline and achieves performance comparable to models trained with text.